Introduction
The article introduces the Akka framework [1] applied to the graph intersection problem. We'll speak about actors, clustering and a map reduce approach to the problem.
Background
The problem
Given a set of graphs I = {G1,...,Gn} the graph intersection is the set O of common arches (ai,ak) in I. We want to find such set O.
The MapReduce approach
ob
The idea behind the MapReduce model is to split the computation over an input I in two phases:
- Map phase: is a function performed in each concurrent unit of computation. Each unit applies the function to a subset of I
- Reduce phase: it post process the outputs of Map phases and returns the final result
This approach is quite common in massive data structure computations, stream processing and big data queries. Solutions like Kafka and Apache Spark implement MapReduce under the hood.
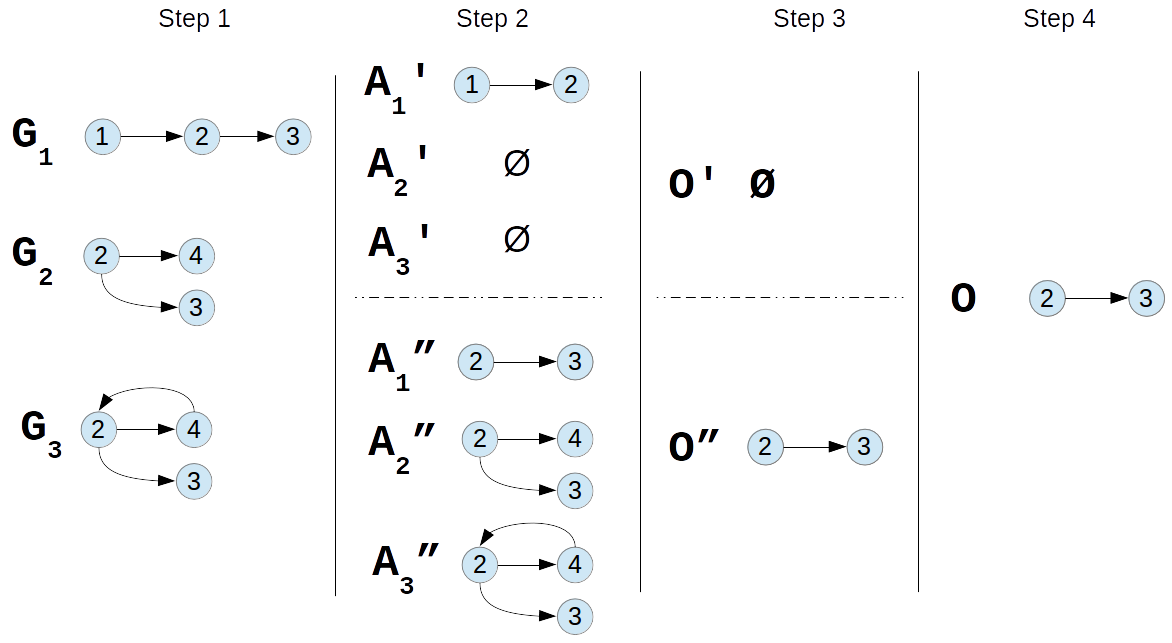
We want to solve the problem of graph intersection using this approach. The steps are:
- Given the input I = {G1,...,Gn} we say that a generic Gi has a set of arches Ai = {(al,a2),...,(am,am+1)}
- We prepare the Map inputs computing for each Gi a partition Ai = {Ai', Ai"} based on the parity of the first node value of the arch
- The Map phase: each of the two Map functions computes concurrently the intersection between the partition assigned. So the input of the first Map will be {A1',...,An'} and the input of the second Map will be {A1",...,An"}
- The Reduce phase: it gathers the partial intersections as the union set of Map results and returns O
Example:
Akka framework and libraries used
Akka is a framework to write reactive systems [2] so it is well suited for production-ready distributed computation. It's developed in both Java and Scala and in this article we'll cover only a sub set of the functionalities provided:
-
Actors: is the bulding block of an asynchronous, non-blocking and highly performant message-driven programming model. They are location transparent.
-
Akka cluster: it provides a peer-to-peer based cluster membership service with features to achieve fault-tolerance.
-
Spray framework: it allows to build REST-HTTP based functionalities over Akka framework.
Technical notes
The cluster is composed by a master machine M which exposes the REST api's and runs the Akka seed nodes as well as the reducer and 4 slaves machines Si which runs the map function. Of course, the following configuration is not intended to be the best configuration in every scenario, it should be considered as an easy, costless yet generic set-up in order to develop and run the code in a distributed scenario.
- machineM
- SO: Ubuntu 15.10, kernel 4.2.0-42-generic
- JDK: 4.2.0-42-generic
- SBT/Scala: 0.13.12/2.10.6
- slaves Si
- SO: Ubuntu 16.04 LTS, kernel 4.4.0-21-generic
- JDK: 4.2.0-42-generic
- SBT/Scala: 0.13.12/2.10.6
- Network notes
- M communicates with each Si over TCP/IP
Code overview
Highlights
application.conf
- remote.netty.tcp.hostname (the machine you want to run the actor system on)
- cluster.seed-nodes (the initial contact points of the cluster for the other nodes)
worker.conf
- remote.netty.tcp.hostname (the worker machine)
- contact-points (the initial contact points of the cluster)
Main.scala
- Here the entry point of the application. Through the args we'll start the WebServer, Master or Worker nodes depending by the current machine cluster role
object Main {
def main(args: Array[<span>String</span>]): Unit = {
WebServer.scala
- This actor exposes two services:
-
/random (it generates 5 random graphs, submits the work to the Master, waits for the result and replies back to the HttpRequest)
-
/submit (it unmarshals the HttpRequest payload in a work instance, submits it to the Master, wait for the result and reply back to the HttpRequest)
Master.scala
- It maintains a list of the current registered Workers to the cluster
- It accepts works from the WebServer, split them in subworks and redistribute to the Workers. Once all Workers have given back the result (Map function) it performs the Reduce phase and gives back to the WebServer the result
- It maintains the current state of the computation through a WorkState instance. So, for instance, it can resubmit a previous subwork due to a Worker computation failure
Worker.scala
- Every node machine runs an instance of this actor. Once initialized it joins the cluster and notifies the Master
- It waits for subworks from the Master, sends it to the WorkExecutor and gives back the Map function result
WorkExecutor.scala
- This actor communicates with a Worker and execute the Map function.
MasterWorkerProtocol.scala
- Defines the communication protocol between Master and Workers
Work.scala
- It describes and identifies the input of the graph intersection problem and the related subworks (partitions)
WorkState.scala
- Describes the state of the computation and it is maintained (as a singleton) by the Master
- It defines few data structures.
- worksPending: contains the Works received by the Master and not yet reduced
- worksAccepted: contains the Works and only related unprocessed subworks
- worksInProgress: contains the Works and only related subworks submitted and still executing by the Workers
- worksDone: contains the Works and only related subworks successfully executed by the Workers
- worksReduced: contains the Works and their reduced result. Once a Work is reduced it is removed from worksPending
Running the code
In this section we execute the code in the Cluster in different scenarios. The following schema shows the machines involved and where the actors introduced above execute. Disclaimer: remember to change application.config and worker.config accordly to the machine addresses/hostnames in which you are running the code

Empirical test 1 - A simple execution
Overview
After the setting up of the cluster is completed we call /submit with the graph above as the payload. Then we'll wait for the response (hopefully the arch (2,3) :-P)
Run the cluster
- Start Master in 192.168.1.30: copy the source code locally and run sbt 'run M1' in a bash
- Start WebServer in 192.168.1.30: copy the source code locally and run sbt 'run WS' in a bash
- Start a Worker/WorkExecutor in 192.168.1.53: copy the source code locally and run sbt run in a bash.
- Perform the following POST call http://192.168.1.30:8080/submit with payload
[["g1",[[1,2],[2,3]]],["g2",[[2,4],[2,3]]],["g3",[[2,3],[2,4],[4,2]]]
- Render the html returned by the service call. The last line shows the result and as we expected the intersection of the three graphs g1, g2 and g3 is [2,3]!
Conclusion
In this test we have familiarized with the problem and how we can submit an instance of the problem. Also is a good change to check out Spray implementation in order to consume/serve html/json contents over HTTP.
Empirical test 2 - Showing the load distribution above nodes
Run the cluster
-
Start Master in 192.168.1.30: copy the source code locally and run sbt 'run M1' in a bash
-
Start WebServer in 192.168.1.30: copy the source code locally and run sbt 'run WS' in a bash
-
Start a Worker/WorkExecutor in 192.168.1.53: copy the source code locally and run sbt run in a bash. For the sack of the example uncomment the line to add a workload (few seconds) in the Map phase.
package worker
...
class WorkExecutor extends Actor {
def receive = {
...
simulateWorkload(80000)
-
Scenario 1: Perform 15 /random service calls. This simulate 15 concurrent problem submission (5 random graphs of 10 arches each) to the cluster equipped with one slave node.
-
Add a Worker/WorkExecutor to the cluster: in 192.168.1.54 copy the source code locally and run sbt run in a bash.
-
Scenario 2: Perform 15 /random service calls. This simulate 15 concurrent problem submission (5 random graphs of 10 arches each) to the cluster equipped with 2 slaves node.
-
Add a Worker/WorkExecutor to the cluster: in 192.168.1.55 copy the source code locally and run sbt run in a bash.
-
Scenario 3: Perform 15 /random service calls. This simulate 15 concurrent problem submission (5 random graphs of 10 arches each) to the cluster equipped with 3 slaves node.
-
Add a Worker/WorkExecutor to the cluster: in 192.168.1.56 copy the source code locally and run sbt run in a bash.
-
Scenario 4: Perform 15 /random service calls. This simulate 15 concurrent problem submission (5 random graphs of 10 arches each) to the cluster equipped with 4 slaves node.
The following chart resumes the results.
Conclusion
This test shows how easy is adding (and removing) nodes to the cluster. Note that the Master is NOT aware about any physical location detail of any of the nodes. Pretty cool isn'it?!
Keen to discorver some other feature implemented? Try to shutdown a node while is computing or uncomment this to simulate a RuntimeException. The Master will be able to redistribute the computation failed calling other nodes!
package worker
...
class WorkExecutor extends Actor {
def receive = {
...
simulateRandomException()
Points of Interest
This programming experience let me to both discover some of emerging frameworks and languages and facing with the challenge of developing distributed algorithms. Here some considerations:
val (mainW, rest) = worksAccepted.filter(w => w._2.contains(work)).head
- The map reduce approach to parallelize computation is quite easy to understand and to model. Also, we can tune the parallelism factor acting in the partitioning phase before the Map (e.g. based by another criteria instead of parity)
- A great issue faced in developing and debugging a distribute system is to maintain the correctness after the a code modification. E.g. "I fixed that, is the Map phase still computing an intersection?". I found very useful the usage of assertions in the code for two reasons: you write the assertion when you are focused on that piece of code, in other words during the development and you are forced of thinking about what exactly you should expect in terms of pre-conditions and post-conditions splitting the responsibilities between the code. E.g.
case WorkCompleted(work, result) ⇒
...
require(subWCompleted.workId == work.workId, s"<span>WorkStarted expected workId ${work.workId} == ${subWCompleted.workId}"</span>)
require(!worksPending(mainW).filter(w => w == work).isEmpty, s<span>"</span>WorkId ${work.workId} was not expected to be ¬
in workPending")
require(!worksAccepted.contains(mainW) || worksAccepted(mainW).filter(w => w == work).isEmpty, "WorkId ${work.workId} was not expected ¬
to be in workIdsAccepted")
require(!worksDone.contains(mainW) || worksDone(mainW).filter(w => w == work).isEmpty, s<span>"</span>WorkId ${work.workId} was not expected to be ¬
in workIdsDone")
Future Improvements: just few ideas
Akka is a vast framework with many features not covered in this article. In this section I give a couple of ideas to improve scalability and robustness.
- using Akka Persistence we can store in a non volatile memory the state of an Actor. For instance, persisting the state of the WebServer actor we can restore the unsent messages to the Master avoiding a loss of client requests in case of temporary fail over
- using many Master and WebServer instances splitted in different machines we can achieve a more responsive, resilient and elastic system [2]
Have a good coding!
Download the code
Download akka-distributed-workers.tar.zip
References
[1] - http://doc.akka.io/docs/akka/2.4/scala.html
[2] - http://www.reactivemanifesto.org/

