Introduction
The main use of this is to generate a list of character blocks for use in regular expression character classes. Say, you want to match all the letters in any language on implementation that resolves "\w" to something like [-a-zA-Z_0-9]. This is problematic in two ways because it only matches English letters and it matches non letter characters (which is still a problem on Unicode aware engines...). Or you want to match letters, but only in certain languages, e.g. only in Latin, no Russian or Arab. This little utility will tell you what you need to use and help you test the result in no time by telling you which input characters match and which don't.
This can also be useful as a reference / learning tool to find out quickly the category a bunch of characters are in or what a local or category (combination) contains, as it can generate the list of characters for a block list, or tell you the Unicode position and the category of input characters.
Background
My original problem was simple: the JavaScript RegExp object doesn't support Unicode categories (e.g. /[p{Ll}]/). "No problem, I can always define them myself", I thought. So I started my quest trying to decipher the various official Unicode documents and doing searches... surely someone else has done this before! I stumbled upon this blog post with a C# snippet to do just that. The script wasn't a bad start (thanks to the author), except I quickly found a bug and needed to make sure there weren't more bugs and I also wanted to get a big picture of all the categories without looking at dozens of PDFs... So, I wrote this little app.
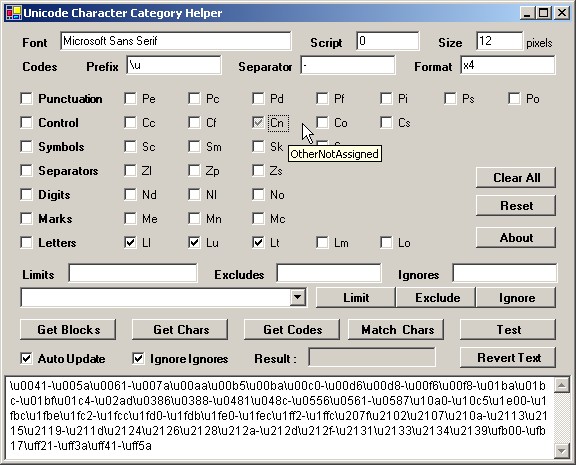
Using the GUI
The main thing to note is that by default, the block list will be updated every time you make a change. You can disable this by un-checking "Auto Update". In the same spirit, the config text boxes try to validate their data every time they change. If it's not valid, it will turn red and the last valid or default value is used. Once it becomes valid, it will turn back to black (or whatever) and become effective. Note that I wanted to write this quickly and nothing too fancy is done here... if the font is bad for example, it will revert to default font. If one range is invalid in the boundaries, none will be used, etc. Basically if a text box goes red; make it go black again before using the result or it might be wrong.
The first section is about some options on how the text will be displayed: changing the font and script (also known as codepage) might let you display more exotic characters, provided you have them correctly configured. The second row are options that affect how the block list is generated and should be left alone most of the time, except maybe for adding an extra "\" to the prefix as a means of escaping the slash meaning of the language so as to use it in a string literal, or maybe changing the format to "x2" so that characters can be specified with only 2 hex digits. Note the latter is the only text box that doesn't turn red when invalid... it should use "x4", but no check is done so be careful about changing that one.
Next are the categories... two letter codes are used to save space, but a tool tip will tell you the full name of each category. The first thing you'll want to do is select the categories you are interested in. Get Codes will work if none are checked. All the check boxes now have three states: indeterminate ("grey") means the category is "ignored"... the specifics are explained below.
Next is the "boundaries" section... a list of Unicode ranges (as 4 hexadecimal characters only) where low and high are separated by a dash ("-") and different ranges are optionally separated by a coma (",").
- Limits means that only characters within those boundaries will be included, even if they otherwise match a checked category.
- Excludes means that characters within those boundaries will not be included, even if they match other conditions.
- Ignores means that all else being equal, the generator will prefer a smaller block without the ignored characters, but will not break a block if only ignored characters separate matching characters. Setting a category to indeterminate has the same effect as putting the blocks for this category in Ignores. Ignoring unassigned characters (Cn, OtherNotAssigned) can greatly simplify the block list with some settings (a Ll, Lu, Lt combo goes from 735 to 389 characters) and this is the reason I have added this... Of course, it can't guarantee you that the blocks will correctly match future Unicode versions, but neither does ignoring them will (which guarantees newly assigned characters will not be matched).
There is also a combo box where you can input a Unicode range or select a predefined one (taken from the official list of block "locals", see Links section below) and click the appropriate button to add it to a boundary.
Get Blocks will do the same thing as changing any category or boundary does when Auto Update is checked: update the main text box with the block list according to the various options.
Get Chars will use the selected options (categories and boundaries) to generate a new block list and then set the main text box to a list of all characters that the blocks match. The Ignore Ignores check box determines if characters the blocks match but are set to ignore will be printed. Note that \u0000 (null character) is skipped if included as it can't be printed and it seems to prevent the rest from displaying.
Get Codes will only use the text box content. It will transform every character in the text box into a line containing the character, its Unicode value in hexadecimal and decimal and its category name. But before doing this, it will replace all the decimal entities (e.g. "$", or "&36;") and Unicode escapes (prefix ("\u" by default) + 2 to 4 hexadecimal digits, e.g. "\u0024" or "\u24") with their character equivalent ("$" for all the previous examples). This can be useful to run on both a block list and a character list, but is mostly meant as a quick reference to check the Unicode of a char or the reverse, or if you are unsure how to match the characters you are interested in...
Match Chars will generate a new block list from options and match it against the text box content. Run this on a sample to verify that you have selected the right options and the blocks contain everything you want and nothing more.
Test doesn't look at the text box at all. It generates a Regex from the blocks and matches every character against it to make sure all that's supposed to match does and nothing more. It helped me find a bug in the blocks generation logic. Go ahead and click on it before using the results, it'll make you feel better.
Revert Text will simply revert the text box to what it was before the last generated value (Revert Text counts). Use this if Auto Update gets in your way, or to quickly go from a view to another. User input doesn't affect this, use Ctrl-z to undo a manual change...
Using the blocks
Let's say you want to make sure something is a "word". A concept harder to define than it seems, but we'll take a simple example: a combo of "Ll", "Lu" and "Lt" (ignoring "Cn" for simplicity), used in JavaScript. Open up CharCatHelper and select the correct options. You should get the following list:
\u0041-\u005a\u0061-\u007a\u00aa\u00b5\u00ba\
u00c0-\u00d6\u00d8-\u00f6\u00f8-\u01ba\u01bc-\u01bf
\u01c4-\u02ad\u0386\u0388-\u0481\u048c-\u0556\
u0561-\u0587\u10a0-\u10c5\u1e00-\u1fbc\u1fbe\u1fc2-\u1fcc
\u1fd0-\u1fdb\u1fe0-\u1fec\u1ff2-\u1ffc\u207f\u2102\u2107\
u210a-\u2113\u2115\u2119-\u211d\u2124\u2126
\u2128\u212a-\u212d\u212f-\u2131\u2133\u2134\u2139\
ufb00-\ufb17\uff21-\uff3a\uff41-\uff5a
You could use this directly in a literal regular expression, but for reuse and to keep complex patterns readable, we'll define the group as a string constant and use the identifier in the RegExp instead. Add an extra "\" to the Code Prefix to escape the slash meaning of the JS engine.
const UNICODE_LETTERS =
"\\u0041-\\u005a\\u0061-\\u007a\\u00aa\
\\u00b5\\u00ba\\u00c0-\\u00d6\
\\u00d8-\\u00f6\\u00f8-\\u01ba\\u01bc-\\u01bf\
\\u01c4-\\u02ad\\u0386\\u0388-\\u0481\\u048c-\\u0556\
\\u0561-\\u0587\\u10a0-\\u10c5\\u1e00-\\u1fbc\\u1fbe\
\\u1fc2-\\u1fcc\\u1fd0-\\u1fdb\\u1fe0-\\u1fec\
\\u1ff2-\\u1ffc\\u207f\\u2102\\u2107\\u210a-\\u2113\
\\u2115\\u2119-\\u211d\\u2124\\u2126\\u2128\
\\u212a-\\u212d\\u212f-\\u2131\\u2133\\u2134\\u2139\
\\ufb00-\\ufb17\\uff21-\\uff3a\\uff41-\\uff5a";
var isWord = new RegExp("^[" + UNICODE_LETTERS + "]+$");
if (isWord.test("Официальный"))
alert("Официальный is a word !");
* The extra "\" at the end of the lines are only to escape the line break to keep the page from scrolling horizontally.*
Using the code
If you want to use the code outside this GUI, I have separated the code into regions and the block list functions are in the last one, "Block Generator": getBlock(), getBlocks() and isInBoundaries(). It's all pretty straightforward and looks like this:
bool isInBoundaries(int[] boundaries, int charNum)
{
if (boundaries == null)
return false;
for (int i=0; i < boundaries.Length; i+=2)
{
if (charNum >= boundaries[i] &&
harNum <= boundaries[i+1])
{
return true;
}
}
return false;
}
string getBlock(int blockStart, int blockEnd,
string prefix, string separator,
string format)
{
if (blockStart == blockEnd)
{
return prefix + blockStart.ToString(format);
}
else if (blockStart + 1 == blockEnd)
{
return prefix + blockStart.ToString(format) +
prefix + blockEnd.ToString(format);
}
else
{
return prefix + blockStart.ToString(format) +
separator + prefix +
blockEnd.ToString(format);
}
}
string getBlocks(string prefix, string separator,
string format, int[] boundaries,
int[] excludes, int[] ignores)
{
string blockList = "";
int blockStart = -1;
int blockEnd = -1;
int lastBlockEnd = -1;
for (int charNum = 0;
charNum <= char.MaxValue; charNum++)
{
char c = Convert.ToChar(charNum);
UnicodeCategory cat =
char.GetUnicodeCategory(c);
if (checkState(cat) == CheckState.Checked
&& (boundaries == null ||
isInBoundaries(boundaries, charNum))
&& (excludes == null ||
!isInBoundaries(excludes, charNum)))
{
if (blockStart == -1)
{
blockStart = charNum;
}
blockEnd = charNum;
}
else if (lastBlockEnd < blockEnd
&& (checkState(cat) !=
CheckState.Indeterminate
&& (ignores == null ||
!isInBoundaries(ignores, charNum))))
{
blockList += getBlock(blockStart, blockEnd,
prefix, separator, format);
lastBlockEnd = blockEnd;
blockStart = blockEnd = -1;
}
}
if (lastBlockEnd < blockEnd)
{
blockList += getBlock(blockStart, blockEnd,
prefix, separator, format);
}
return blockList;
}
Links
The list of locals is taken from UNIDATA/Blocks.txt (unicode.org), version 4.1.0 (as of UCCH 1.1).
History
- Version 1.1.1
- Version 1.1
- All category check boxes now have three states: Indeterminate means the category is ignored.
- Added Ignores blocks.
- Added a combo box with the Unicode 4.1.0. Block names and buttons to add them to any boundary.
- Added Revert button that will revert the main text box to the last (non-user) value.
- Characters print no longer tries to print \u0000 as it makes the whole thing fail...
- A boundary is now reset to null when it becomes invalid.
- Get Codes will first convert decimal entities and Unicode escapes to chars.
- Separated the code into regions and commented it a bit.
- A few other minor UI changes (e.g. result textbox can now be 'reset' by clicking on it).
I've already spent more time on this than I had planned and this is likely to be the last version, even though many more improvements could be made... but if you think something really doesn't work as it should, post your problem and I'll try to fix it. Hope someone finds this useful.

