Introduction
We, as developers, are often faced with converting data from one format to another. For a project at work, I needed a portable solution that was efficient, had minimal external requirements, and parsed delimited and fixed-width data. As shown below, the GenericParser is a good replacement for any Microsoft provided solution and provides some unique functionality. The code is well organized and easy to follow to allow modification as necessary.
Note: The project was built using Visual Studio 2010, but the code is designed for .NET 2.0.
Definitions
- Delimited data - Data whose columns are separated by a specific character (e.g., CSV - Comma Separated Values).
- Fixed-width data - Data whose columns are of a set number of characters wide.
Features
The GenericParser (and the derived GenericParserAdapter) contains the following features:
- Efficient - See Benchmarking below for more details.
- Time: Approximately 3 to 10 times faster than any Microsoft provided solution
- Memory: Approximately equal to or less than any Microsoft provided solution
- Supports delimited and fixed-width formats
- Supports a custom delimiter character (single character only)
- Supports comment rows (single character marker)
- Supports escape characters (single character only)
- Supports a custom text qualifier to allow column/row delimiters to be ignored (e.g., multi-line data)
- Supports escaped text qualifiers by doubling them up
- Supports ignoring/including rows that contain no characters
- Supports a header row
- Supports the ability to dynamically add more columns to match the data
- Supports the ability to enforce the number of columns to a specific number
- Supports the ability to enforce the number of columns based on the first row
- Supports trimming the strings of a column
- Supports stripping off control characters
- Supports reusing the same instance of the parser for different data sources
- Supports
TextReader and String (the file location) as data sources - Supports limiting the maximum number of rows to read
- Supports customizing the size of the internal buffer
- Supports skipping rows at the beginning of the data after the header row
- Supports XML configuration which can be loaded/saved in numerous formats
- Supports access to data via column name (when a header row is supplied)
- Supports Unicode encoding
GenericParserAdapter supports skipping rows at the end of the dataGenericParserAdapter supports adding a line number to each row of outputGenericParserAdapter supports the following outputs - XML, DataTable, and DataSet- Thorough unit testing - 91.94% code coverage (tests supplied in source download)
- Thorough XML documentation in code (including a .chm help file in the binary/source downloads)
Benchmarking
To benchmark the GenericParser, I chose to compare it to:
- Microsoft's Text Driver
- Microsoft's Text Field Parser
- Sebastien Lorion's
CsvReader 3.7 (CSV only - code found here[^]) GenericParser 1.0
To get a realistic datasource for benchmarking, I took 10 rows of data from the Northwind Database and replicated them for successively larger and larger sets of CSV and FixedWidth data. Using System.Diagnostics.Stopwatch to measure CPU usage, I executed each benchmark 10 times and averaged the results to minimize the amount of error in the instrumentation. For the memory usage, I used Visual Studio 2010's memory profiling and executed each benchmark only once.
I've tried to generate tests that exercise the code equally for each solution. As a caveat, these tests do not test every possible scenario - your mileage may vary. Please feel free to use my code as a basis (or create your own tests) to compare the code before you draw any conclusions.
For example, the tests below did not take into account escaped characters. In GenericParser 1.0, it allocated an additional buffer for escaped characters, which essentially doubled its memory requirements. In GenericParser 1.1, it reuses the existing buffer to unescape the column of data. You wouldn't see this benefit unless you specifically geared your tests to account for this.
Just because I know someone will comment about this, I am aware of FileHelpers[^], but I believe they fit into a different category which doesn't map easily for comparison to the above solutions. FileHelpers rely on a declarative definition of the file schema through attributes on concrete classes. My solution depends on defining the schema through properties or XML. You may feel free to compare them, if they fit into your problem space.
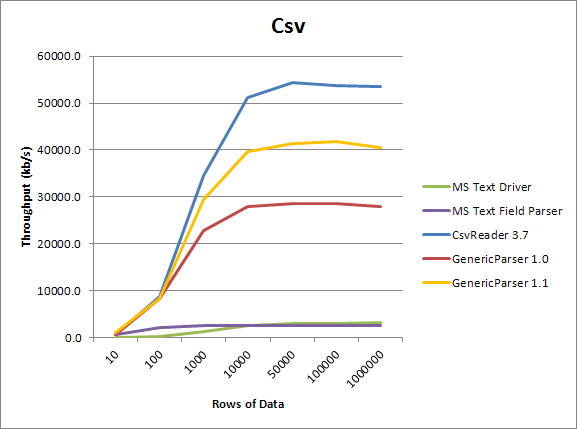
CPU Usage

Memory Usage
Note: Because profiling the memory was generating .vsp files upwards of 2 gigs and the memory usage seemed pretty stable, I only executed memory profiling for 10 to 10,000 rows of data.
Conclusion
As can be seen in the charts, GenericParser meets or exceeds anything Microsoft has put together in all areas. Furthermore, version 1.1 out performs version 1.0 in performance considerably, especially considering the bug fixes and the new features added.
As can be seen by the graphs, Sebastien Lorion's CsvReader is definitely the top contender for parsing delimited files. So, if you are looking at only parsing delimited files, I would highly recommend checking out his library. Otherwise, I find my library to be an effective implementation for being able to parse both formats.
In the source download, you can find all of my performance tests and results, including an Excel 2010 workbook that has all of the collected raw data together for charting purposes.
Using the Code
The code itself mimics most readers found within the .NET Framework, but the usage follows four basic steps:
- Set the data source through either the constructor or the
SetDataSource() method. - Configure the parser for the data source's format, either through properties, or by loading an XML CONFIG file via the
Load() method. - Call the
Read() method and access the columns of data underneath, or for the GenericParserAdapter - GetXml(), GetDataTable(), GetDataSet() to extract data. - Call
Close() or Dispose().
DataSet dsResult;
using (GenericParserAdapter parser = new GenericParserAdapter("MyData.txt"))
{
parser.Load("MyData.xml");
dsResult = parser.GetDataSet();
}
string strID, strName, strStatus;
using (GenericParser parser = new GenericParser())
{
parser.SetDataSource("MyData.txt");
parser.ColumnDelimiter = "\t".ToCharArray();
parser.FirstRowHasHeader = true;
parser.SkipStartingDataRows = 10;
parser.MaxBufferSize = 4096;
parser.MaxRows = 500;
parser.TextQualifier = '\"';
while (parser.Read())
{
strID = parser["ID"];
strName = parser["Name"];
strStatus = parser["Status"];
}
}
using (GenericParser parser = new GenericParser())
{
parser.SetDataSource("MyData.txt");
parser.ColumnWidths = new int[4] {10, 10, 10, 10};
parser.SkipStartingDataRows = 10;
parser.MaxRows = 500;
while (parser.Read())
{
strID = parser["ID"];
strName = parser["Name"];
strStatus = parser["Status"];
}
}
Acknowledgements
While I did not create a derivative of Sebastien Lorion's CsvReader, I did use some of his concepts of provided functionality in his CsvReader for the GenericParser.
Tools Used
History
- September 17, 2005 - 1.0 - First release
- June 20, 2010 - 1.1
- New features:
- Supports ignoring/including blank rows of data (no characters found in row)
- Supports the ability to enforce the number of columns based on the first row
- Supports stripping off control characters
GenericParserAdapter supports skipping rows at the end of the data- Reduced memory overhead when using escaped characters
- Support for specifying the data's encoding
- Bug fixes:
- Fixed a bug with parsing data with a header and no data
- Fixed a bug in not handling text qualifiers/escape/comment characters consistently
- Fixed a bug in reading a file across a high latency network
- Fixed a bug with text qualifiers being interpreted in the middle of the column (only works if at the start and end of a column)
- Fixed a bug with skipping row ends at the very end of the buffer
- Breaking changes:
- Fixed width parsing will no longer take text qualifiers or escape characters into account
- The following properties have been converted to a
char?:
ColumnDelimiterCommentCharacterEscapeCharacterTextQualifier
RowDelimiter has been removed, and the code automatically handles looking for '\n' or '\r' to indicate a new row (assuming '\r' is not a column delimiter). If one of these characters is found, it will skip the paired '\n' or '\r' (assuming '\r' is not a column delimiter).SkipDataRows has been renamed to SkipStartingDataRows- The
FixedWidth property has been replaced by a property called TextFieldType, which is of the enum type FieldType - Due to the changes in the properties listed above, the XML produced by version 1.0 will not be 100% compatible with version 1.1
Read() will return true if it parses a header row and no dataParserSetupException has been replaced by InvalidOperationException- Reworked the messages supplied in the exceptions to be more descriptive.
- June 26, 2010 - 1.1.1
- New features:
- Reworked benchmarking to be more representative of real world data and switched over testing to not use
DataSets - Slightly more efficient loading of configuration files
- February 5, 2012 - 1.1.2
- Bug fixes:
- Fixed an issue where an exception was being thrown for the
MaxBufferSize was too small, when it was indeed large enough (Reported by uberblue).
- March 16, 2012 - 1.1.3
- Bug fixes:
- Fixed an issue where control characters were being removed accidently (Reported by John Voelk).
- Fixed an issue where data at the end of the stream wasn't extracted properly (introduced in version 1.1.2).
- October 14, 2017 - 1.1.4
- Bug fixes:
- Fixed a minor issue with FileRowNumber when an exception was throw during parsing (Reported by webdevx).
- October 14, 2017 - 1.1.5
- Bug fixes:
- Minor update to resolve issue with GenericParserAdapter that prevented adding columns if no data rows were found. (Reported by tschlarm).

