Contents
Introduction
The C/C++ standard defines the specification of language elements, such as syntax and grammar, while it doesn't strictly indicate how to implement an operator or a statement. Every software manufacturer is free to use any implementation as long as it fits the C/C++ standard. However, an implementation is closely related to performance of executing a program at runtime. My previous article Something You May Not Know About the Switch Statement in C/C++ gives an example to analyze C/C++ switch statement behavior and efficiency with the assembly output.
This article will discuss some C/C++ operators, by analyzing their assembly output generated with Visual Studio in examples. First I'll show you how to understand conceptual difference between the bit-wise & and the logical && operators. The second is a specific sample for the left bit shift << and the right shift >> operators that let you see how they are implemented differently in Debug and Release build.
We’ll see what happens behind the Visual C/C++ code. We use Microsoft Visual Studio IDE, since it can generate the corresponding assembly listing on compiling. In order to read this article, a general understanding of Intel x86 assembly instructions and Microsoft MASM specifications is necessary. As you can see shortly, all discussions here are based on a kind of “reverse engineering” and then, the article is never an accurate description of compiler implementations; while it can be an additional study material in learning assembly language programming.
In order to generate an assembler output in Visual Studio, open a .CPP file Property dialog, choose All Configurations, and under left C/C++ dropdown, select the Output Files category. On the right pane, choose the Assembly With Source Code (/FAs) option as shown below for ShiftAndTest.cpp:
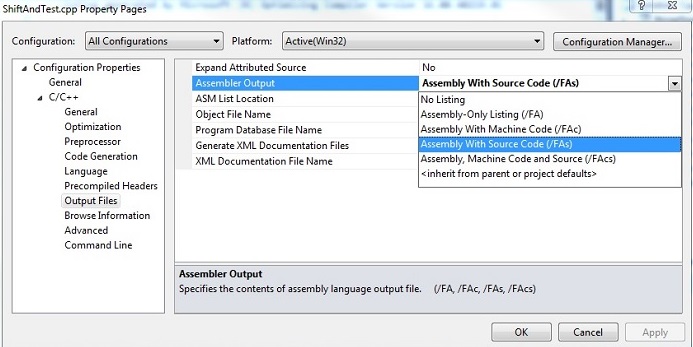
When you compile ShiftAndTest.cpp, an assembly file called ShiftAndTest.asm will be generated either in Debug or Release folder. Using this option, the assembly listing includes the original C++ code line numbered for your reference, which is commented by a semi-colon as you’ll see soon.
I use Visual Studio with MASM assembler on the Windows system just for academic convenience in the CSCI 241, Assembly Language Programming class. As assembly language programming is not potable, you can find similar tools on other platforms. A powerful online compiler (and Disassembler) can be found at gcc.godbolt.org for GCC/Clang with many useful options for either ARM or x86. You definitely can try that to generate assembly listing alike.
Bit-wise and Logical Operators
We all know the specification of operator & and && generally. Both are binary operators with two operands to perform Boolean AND logic as explained online at Cplusplus.com or Wikipedia,org. Also we understand the difference that the result of operator & is calculated by ANDing each bit (0 or 1) from two integers, while && only takes two operands as false and true represented by zero or non-zero.
Moreover, an operand of either operator & or && can be an expression that must be evaluated beforehand. In such a case, let’s consider the following code snippet for & and && with the same expression operands:
int i =5, j =3, k;
bool b;
k =7;
b = (i-5) & (k=i-j);
printf("Operator &, b=%d, k=%d\n", b, k);
k =7;
b = (i-5) && (k=i-j);
printf("Operator &&, b=%d, k=%d\n", b, k);
What’s the difference? You may be stuck a while. Here is the output:

It reminds you of the concept of short-circuit evaluation. To see what happens in the operator implementation, I generate the assembler output as below:
mov DWORD PTR _i$[ebp], 5
mov DWORD PTR _j$[ebp], 3
mov DWORD PTR _k$[ebp], 7
The code creates and initializes i, j, and k. Three local variables are easy to recognize, as denoted by the same name on the stack frame.
From the output, you can see that the & operator makes k=2, i.e., k= i-j. This means that the operator & performs full elevation of both expressions without using short-circuit, even the left i-5 is zero, the right side k=i-j still executed. The following code exposes details:
mov eax, DWORD PTR _i$[ebp]
sub eax, DWORD PTR _j$[ebp]
mov DWORD PTR _k$[ebp], eax
mov ecx, DWORD PTR _i$[ebp]
sub ecx, 5
and ecx, DWORD PTR _k$[ebp]
setne dl
mov BYTE PTR _b$[ebp], dl
The code simply does i – j in EAX to assign it to k. Then it goes to the second SUB for i – 5. The AND instruction is used to perform the Boolean bit-wise logic. Since we only need the logical result true or false for variable b, the code checks the zero flag by using SETNE via DL. Interestingly, even when changing the order of two expression, you still get the same assembly code:
b = (k=i-j) & (i-5);
Now let’s take a look at the output of operator && that results in k=7. It means k unchanged without doing i-j. The operator && performs short-circuit evaluation, because the left i-5 is zero, the right side k=i-j skipped. The following gives such an implementation:
mov DWORD PTR _k$[ebp], 7
mov eax, DWORD PTR _i$[ebp]
sub eax, 5
je SHORT $LN3@main
mov ecx, DWORD PTR _i$[ebp]
sub ecx, DWORD PTR _j$[ebp]
mov DWORD PTR _k$[ebp], ecx
je SHORT $LN3@main
mov DWORD PTR tv77[ebp], 1
jmp SHORT $LN4@main
$LN3@main:
mov DWORD PTR tv77[ebp], 0
$LN4@main:
mov dl, BYTE PTR tv77[ebp]
mov BYTE PTR _b$[ebp], dl
As && only for logical true or false, no bit-wise AND instruction needed. The code first does i – 5 and checks the zero flag with JE. If zero found, it jumps to the label $LN3@main to return zero as false. Otherwise, it falls through to the right operand evaluation of k=i-j and checks that second condition for the final result of variable b.
Also an interesting exercise is to change the conditions' order to verify both expressions evaluated in assembly output:
b = (k=i-j) && (i-5);
Now the similar comparison can be made between the bit-wise operator | and logical ||. See this example:
k =7;
b = (i-j) | ++k;
printf("Operator |, b=%d, k=%d\n", b, k);
k =7;
b = (i-j) || ++k;
printf("Operator ||, b=%d, k=%d\n", b, k);
The console output is
As for the bit-wise |, the code first does ++k unconditionally in EAX and saves it back to the variable k. Then i-j is calculated in ECX for the OR instruction:
mov DWORD PTR _k$[ebp], 7
mov eax, DWORD PTR _k$[ebp]
add eax, 1
mov DWORD PTR _k$[ebp], eax
mov ecx, DWORD PTR _i$[ebp]
sub ecx, DWORD PTR _j$[ebp]
or ecx, DWORD PTR _k$[ebp]
setne dl
mov BYTE PTR _b$[ebp], dl
For the logical ||, the left i-j is first calculated and checked non-zero. Only when JNE is not satisfied, will the right side ++k be calculated. In our test, i-j is non-zero and so ++k is ignored, as short-circuit implemented
mov DWORD PTR _k$[ebp], 7
mov eax, DWORD PTR _i$[ebp]
sub eax, DWORD PTR _j$[ebp]
jne SHORT $LN5@main
mov ecx, DWORD PTR _k$[ebp]
add ecx, 1
mov DWORD PTR _k$[ebp], ecx
jne SHORT $LN5@main
mov DWORD PTR tv128[ebp], 0
jmp SHORT $LN6@main
$LN5@main:
mov DWORD PTR tv128[ebp], 1
$LN6@main:
mov dl, BYTE PTR tv128[ebp]
mov BYTE PTR _b$[ebp], dl
In this example, I generated the above assembler output in Debug build. Usually, the code generated in Debug is more readable and understandable, but probably less efficient. The code generated from Release build is optimized to minimize speed or size. They are probably hard to read but more efficient.
Sometimes, the assembly listing generated is not completely to reflect the whole logic to implement high level language code, because some part of the logic could be implemented in preprocessing or elsewhere. A smart compiler may divide the responsibility that can happen in assembly time instead of at precious runtime. As an example, you can read the section of "Using Binary Search" in Something You May Not Know About the Switch Statement in C/C++ where I discussed such a scenario by one situation of the switch/case block.
Bit-wise Shift Operators
In this section, I use an example to reverse bytes in a DWORD, 32-bit unsigned integer, by calling a C function named ReverseBytes() as this:
printf("Reverse Bytes:\n");
int n = 0x12345678;
printf("1. 32-bit Hexadecimal: %Xh\n", n);
printf("2. Now Reverse Bytes: %Xh\n", n =ReverseBytes(n) );
printf("3. Again, Resume now: %Xh\n", ReverseBytes(n) );
As a byte taking two hexadecimal digits, the result formatted in hexadecimal can be
One solution is to simply use bit-wise right and left shift operators twice:
unsigned int ReverseBytes(unsigned x)
{
x = (x & 0xffff0000) >> 16 | (x & 0x0000ffff) << 16;
x = (x & 0xff00ff00) >> 8 | (x & 0x00ff00ff) << 8;
return x;
}
As for our test data 12345678h, the first statement shifting 16 bits makes this:
x = 00001234h | 56780000h = 56781234h
And the second statement shifting 8 bits makes the result:
x = 00560012h | 78003400h = 78563412h
The x86 instruction set provides powerful shifting and rotation instructions to implement logic of C bit-wise shift. Let’s take a first look at an assembly code generated from Debug build. To focus on our topic, I simply cut three lines of the C statement implementations without stack frame's prologue and epilogue here:
mov eax, DWORD PTR _x$[ebp]
and eax, -65536
shr eax, 16
mov ecx, DWORD PTR _x$[ebp]
and ecx, 65535
shl ecx, 16
or eax, ecx
mov DWORD PTR _x$[ebp], eax
mov eax, DWORD PTR _x$[ebp]
and eax, -16711936
shr eax, 8
mov ecx, DWORD PTR _x$[ebp]
and ecx, 16711935
shl ecx, 8
or eax, ecx
mov DWORD PTR _x$[ebp], eax
mov eax, DWORD PTR _x$[ebp]
Above two assembly blocks make a perfect mapping to the two C statements in logic. The SHR instruction is right shift for the >> operator and SHL is left shift for <<. Only variable x denoted by memory _x$[ebp] is moved to EAX and ECX to perform different shifting and then ORing them together in EAX that is saved back to _x$[ebp]. The difference of two blocks is just two specified masks for shifting either 16 or 8 bits.
The logic above is so clear and readable, which is helpful to understand how assembly instructions working step by step, since one C language statement corresponds multiple assembly instructions in details. However, the code might not be very efficient. Let’s turn to the assembly code generated from Release build as follows:
rol ecx, 16
mov eax, ecx
mov edx, ecx
shr eax, 8
shl edx, 8
xor eax, edx
and eax, 16711935
shl ecx, 8
xor eax, ecx
Surprisingly, at first, it doesn’t use x as a previous memory argument denoted by EBP. Directly using register ECX to represent x, is much faster. Next, it makes use of the rotation ROL that greatly simplifies the swap of 16 bits to obtain the middle result of 56781234h.
However, in the second block, the code right shifts 8 bits to have 00567812h in EAX and left shifts 8 bits to have 78123400h in EDX. The hard part for understanding is two XOR instructions. As a learning practice, you can trace the code to verify the result. Think of what they actually doing and how finally working out. When getting the result, the value 78563412h in EAX is exactly you expected to return.
Although the second block logic is not easy to understand, the first block 16-bit shift strategy is really great and heuristic. Could we get hint from this concise ROL instruction for an easy swap? Sure, see this:
12345678h => 12347856h => 78561234h =>78563412h
Wow, this idea is much simpler and more understandable, even better than that of the Release build. I created such a solution, just by three ROL instructions. Try this assuming EAX initialized as 12345678h:
rol ax, 8h
rol eax, 10h
rol ax, 8h
Actually, to swap bytes in a multi-byte intiger, a single instruction is just BSWAP in x86-64, so powerfuly compared to any high-level-language.
Summary
I talked about miscellaneous features in assembly language implementations interfaced with C operators. To understand these examples actually require a lot of your background knowledge with x86 instructions and MASM specifications. By scrutinizing assembler code listing, I exposed some interesting C/C++ code behavior at runtime. To analyze a C/C++ program in Visual Studio, we can have either static assembly listings generated by the compiler or dynamic executions with the VS debug Disassembler. Here in this article, I use the assembly listing, since I have to compare C/C++ code behavior in both Debug and Release assembler outputs. The downloadable zip file contains the project ShiftAndTest, including both .CPP source code and .ASM listings in VS 2010. The same listings can be generated by yourself with any recent VS IDE.
As we know, understanding correspondence between the high level language and the assembly language is an important topic in our classes to learn the lower level implementations based on one-to-many relationship. This is why we have to peek and detect C/C++ code behavior by digging deeper into assembler outputs for our education purpose. Assembly language is notable for its one-to-one correspondence between an instruction and its machine code. Via assembly code, you can get closer to the heart of the machine, investigating the instruction execution and performance. Assembly language programming plays an important role in both academic studies and industry developments. I hope this article could serve as some examples for student learning assemble programming and perhaps for developers as well. Any comments and suggestions are welcome.
History
- March 28, 2021 -- The third section removed
- April 14, 2017 -- Original version posted

