Introduction
If you or your organization is using the Confluence-Wiki Server product, and you would like to make programmatic changes to a specific page, you may' be interested in this article. Unfortunately, the code will not work unmodified for the subscription-based SAAS Confluence product. While there is a Command Line Program that allows you to make such updates, the CLI requires a paid plug in on the Confluence server. Fortunately, Confluence has a REST API that allows us to manipulate content on the server. Confluence also supports an old XMLRPC web standard, but today people tend to like working with REST.
Background
In my case, I was trying to implement a sort of automatic logging on Confluence. Why on Confluence? Confluence allows users to subscribe to specific pages they are interested in. If there's changed content, the users receive an email. This allows stakeholders to be kept informed. We have a procedure that all configuration changes to a certain IT system must be published. We want to know who made the change, what the change was and why. IT configuration changes sometimes have unintended consequences, so it is good for stakeholders to know that 'someone' made a change to the system.
At the risk of sounding like an advertorial (no I received no money for writing this) - Confluence is the tool that has had the most beneficial impact on our organization since we have introduced it. Pages are easy to author, screenshots, code snippets, diagrams -- all works really well, and the users seem to like it and contribute content.
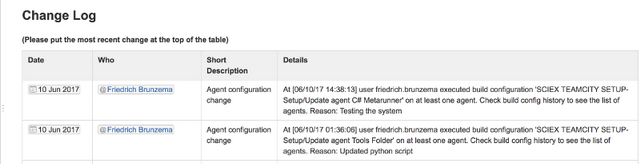
In our case, the IT system in question is TeamCity - a Continuous Integration / Build server. We're interested in keeping track of configuration changes made to build agents. The problem was that sometimes people would make changes - but would forget to document the changes on the confluence page. The page is just a simple table, with one row per change - with the most recent changes on the top. This makes it very easy for stakeholders to quickly scan the table and know who made the change, when the change was made, a short description and a full description of the changes. But if changes are not recorded, the log page is useless.
I wanted to write a program that could be launched every time a configuration change was initiated. A user would have to enter a reason for the configuration change. Then the program would kick in. It would download the "Change-Log" page, extract the HTML, add insert an extra row at the top of table #2 (there are two tables my page, and the log is the second one). The tool would then save the HTML, and upload the changes back to Confluence via Confluence's REST API. Sounds simple, right?
Why Python?
There are usually a number of ways to skin a cat, so why did I choose to use Python for this little project. The main reason is that Nick Hilton had already posted some python code to update a confluence page via REST. I had a choice to re-write, or just reuse. Most of my experience is with C#, but I had played around with Python before, so I thought this would be a good opportunity to learn some more - by actually doing something useful.
How Does Nick Hilton's Confluence Update Code Work?
If you look at the code below, updating a page via REST is a bit more complex than perhaps first anticipated. If you want to update a confluence page, you must usually be authenticated first, but then you also have to know the internal page ID number of the page that you are interested in. How do you get the page ID? I normally just visit the page on confluence in Firefox and right-click and choose View Page Info.

The page id shows up as the ajs-page-id property. The updating of the page happens in a few steps - first a REST call is made to get more information about the page - specifically, we're interested in the version number. Each confluence page is version controlled -- each time a save is made, another version is kept. This allows reverting to any previous version, and also compare different revisions of a page. Here, we have to compute the next version#, just the original incremented by one. This is needed when the call is made to save the page. Another call is made to get the "ancestors" object, which is cleaned up before doing calling to save the page. A JSON payload is constructed, with the updated HTML sitting under ['body']['storage']['value']. After the call is made, the page's HTML is replaced with what was passed in. Perfect!.
def get_page_ancestors(auth, pageid):
url = '{base}/{pageid}?expand=ancestors'.format(
base = BASE_URL,
pageid = pageid)
r = requests.get(url, auth = auth)
r.raise_for_status()
return r.json()['ancestors']
def get_page_info(auth, pageid):
url = '{base}/{pageid}'.format(
base = BASE_URL,
pageid = pageid)
r = requests.get(url, auth = auth)
r.raise_for_status()
return r.json()
def write_data(auth, html, pageid, title = None):
info = get_page_info(auth, pageid)
ver = int(info['version']['number']) + 1
ancestors = get_page_ancestors(auth, pageid)
anc = ancestors[-1]
del anc['_links']
del anc['_expandable']
del anc['extensions']
if title is not None:
info['title'] = title
data = {
'id' : str(pageid),
'type' : 'page',
'title' : info['title'],
'version' : {'number' : ver},
'ancestors' : [anc],
'body' : {
'storage' :
{
'representation' : 'storage',
'value' : str(html),
}
}
}
data = json.dumps(data)
url = '{base}/{pageid}'.format(base = BASE_URL, pageid = pageid)
r = requests.put(
url,
data = data,
auth = auth,
headers = { 'Content-Type' : 'application/json' }
)
r.raise_for_status()
print "Wrote '%s' version %d" % (info['title'], ver)
print "URL: %s%d" % (VIEW_URL, pageid)
Resolving the REST 400 Error
Nick's code actually works great for arbitrary HTML that I create. For things to work, the HTML has to be normal, valid HTML, with no special tags, macros. In my case, I needed round-tripping to work, that is I wanted to read the existing HTML from Confluence, make some changes, and upload the changed version. When I tried this, I consistently got a 400 error back - Bad Request. A look at the server logs was not helpful, and since the call worked fine with vanilla HTML, what could be the problem? Looking at the Confluence REST api documentation, I found the 'contentbody/convert/{to}' method. After scratching my head, it came to me. Confluence stores the pages in a storage format -- in that format links, macros and the like are not expanded. The HTML actually has elements, that make no sense as far as normal HTML is concerned. So to get HTML and make edits and save, one has to do the following:
- Read the page HTML - the HTML is in 'storage' format.
- Convert the HTML to 'view' format. In this format links, macros are expanded.
- Make edits to the HTML programmatically.
- Convert the 'view' HTML back to 'storage' HTML.
- Update the page with the edited 'storage' HTML.
Using that approach avoids the 400 error. Below, the python methods to do the conversions are shown:
def convert_db_to_view(auth2, html):
url = 'http://server/rest/api/contentbody/convert/view'
data2 = {
'value': html,
'representation': 'storage'
}
r = requests.post(url,
data=json.dumps(data2),
auth=auth2,
headers={'Content-Type': 'application/json'}
)
r.raise_for_status()
return r.json()
def convert_view_to_db(auth2, html):
url = 'http://server/rest/api/contentbody/convert/storage'
data2 = {
'value': html,
'representation': 'editor'
}
r = requests.post(url,
data=json.dumps(data2),
auth=auth2,
headers={'Content-Type': 'application/json'}
)
r.raise_for_status()
return r.json()
The HTML has to be extracted from the JSON response, not hard - but you need to know how to do it. The full code example shows how this is done.
HTML Editing Using the Python lxml Library
After solving the round-trip issue, I now needed to add one row to table #2 of the html. The new row needed to be added as the top row of the table. While this sort of thing can be done with normal text processing techniques - it is more robust to use an HTML parsing library. To use the lxml library for your script, you have to install it. this is usually done with:
pip install lxml
After that, the library is available. If you use an IDE like PyCharm, the IDE usually has facilities to import the required modules. In PyCharm, you would use Preferences...-> Project:[yourproj]->Project Interpreter, and click the small '+' under the list of packages. Many developers just use an editor for scripting languages, but I still prefer an environment that lets me step through the code. Note that the machine you will be running the script on has to have both Python as well as the dependent modules installed, otherwise things won't work.
def patch_html(auth, options):
json_text = read_data(auth, options.page_id, options.server).text
json2 = json.loads(json_text)
html_storage_txt = json2['body']['storage']['value']
html_display_json = convert_db_to_view(auth, html_storage_txt, options.server)
html_display_txt = html_display_json['value'].encode('utf-8')
html = lxml.html.fromstring(html_display_txt)
tables = html.findall('.//table')
table_body = tables[1].find('.//tbody')
insert_row_to_table(table_body, options)
html_string = lxml.html.tostring(html, pretty_print=True)
new_view = convert_view_to_db(auth, html_string, options.server)
new_view_string = new_view['value'].encode('utf-8')
return new_view_string
def insert_row_to_table(table_body, options):
from lxml import etree
row = etree.Element('tr')
c1 = get_td(options.column1)
c2 = get_td(options.column2)
c3 = get_td(options.column3)
c4 = get_td(options.column4)
row.append(c1)
row.append(c2)
row.append(c3)
row.append(c4)
table_body.insert(1, row)
return
Note how easy it is to navigate the HTML document using an XPath-like query. The Element class allows easy insertion of new elements, as can be seen in the code above.
How to Use the Script on Windows
- Install Python 2.7 When running the installer, tell it to put python 2.7 on the path (off by default)
- Run
pip install lxml - Download and extract the python edit_confluence.py from this article's download section.
- On your confluence server, find the
PageId (explained in the article above) of the page you wish to update. To work with the current code, the page should have two tables, the second table should have a header row and 4 columns. - Run
python edit_confluence.py -u [your confluence user id] -s [http://myconfluence.com] -1 "Column1 Text -2 "Column 2 text" -3 "Column3 Text" -4 "Column4 Text". If running for the first time, you will be prompted for your confluence password, which is stored encrypted in a keyring. - Hit F5 in your browser's confluence page to see the update.
Notes
The above article presents a solution to updating confluence that I find rather complex. If you find a simpler way to do such updates, please add a comment so that we can all learn! Since I'm new to Python, this code may be less pythonic than desired. The code could use a bit of refactoring, to use a class -- that way, fewer arguments would need to be passed around. The Atlassian Confluence REST API should really encapsulate many of the required details, and expose an additional REST API that makes updating pages much easier. Unfortunately, the cloud-based solution stores pages in a completely different way, so this program will not work for that use case.
History
- 15th June, 2017 - Initial revision

