This article will explain complete and describe detail by detail and step by step computational matters.
Requirement: Machine Learning
Sentiment Analysis
People have the tendency to want to know how others are thinking about them and their business, no matter what is it, whether it is a product such as a car, restaurant or it is a service. If you know how your customers are thinking about you, then you can keep or improve or even change your strategy to enhance customer satisfaction. It is possible by the aid of gathering their email which has been sent to you and use some methodology to categorize their opinion according to their words which they have used. Also, it has other applications in industry and science for researches.
- It reboots marketing.
- Categorization documents in office.
- Making recommendation list for customers or your firma.
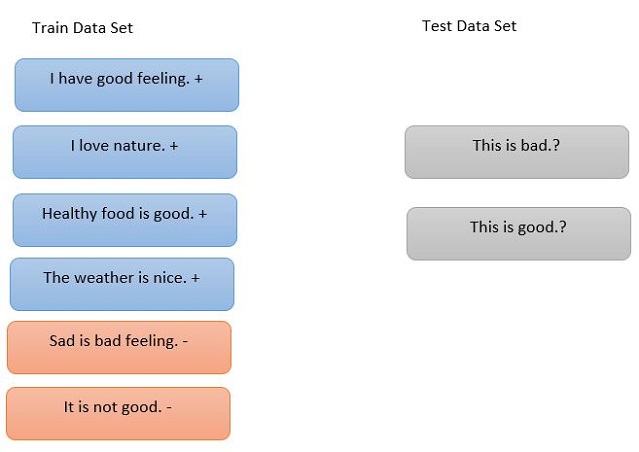
In the below figure, on the training set, there are samples about specific sentences and assign them positive or negative sign based on their content. Then we have on the right section test data which its positivity or negativity is ambiguous for us and should be computed by some methods such as naive Bayes classifier.
Text Mining in Scientific Research
A project at The University of Manchester to analyse 15,000 mouse studies, does not have their gender and age which has a bad influence on research result and output is ambiguous. But with the aid of text mining tools and scanning documents, it is now possible to fill this gap and improve research according to new information based on gender and age of mice. [*]
Opinion Mining
Different people have different reaction to one subject and you can measure how many people agree with a specific topic and how much. It is possible with natural language process solution. But there is another way with naive bayes classifier.

Naive Bayesian
Naive Bayesian is one of the most applicable data mining algorithms to classify and interpret data. This algorithm helps to statistical interpretation by giving probability for each occurrence.
Simple Definition: Finding the probability of happening of the sorts of the events (C1, C2, ..., Cn), based on happening some conditions (x1, x2, x3, …, xn) which have been happened sooner than specific C.
There is given training data set and it is categorized according to some factors. In the above example, there is text which determine their content into positive or negative. Then as a test data set, there are two sentences which their content direction into positive or negative is ambiguous. Our goal is to find their direction by studying the training set. The appropriate solution is to use naïve Bayesian classifier which is the most applicable in text and opinion mining.
To reach our purpose, we should know or review some concepts about statistical and probability science. There are some fundamental definitions which I explain as follows:
Probability
When an event happens, we look at it carefully, we count all of possibilities to happen for a specific event and call it Sample Space, then count how many times it can happen. If we throw one coin, our sample space is two, because we have S = {head, tail}, when we throw the coin, there is just one occurrence or event, either head or tail, in healthy conditions, coin just falls into one of these two. But when new throw dice there are six possibilities as sample space. S = {1, 2, 3, 4, 5, 6}, also in falling dice, there are just one happening. The probability would be computed from dividing count of event by total sample space, for instance, the probability of falling dice on number 1 is 1/6. There are other events which happen more than once. In the above table, you can see that there are 8 as sample space. The probability of happening event “positive” is 4/8=0.5 because positive happened 4 times in total 8 times, it is the same story for “negative”, it happened 4 times in 8 times and the probability of happening negative is equal to positive 0.5.
Conditional Probability
The probability of one event happening based on another event happening P(A|B) is called conditional probability, which is read as “The probability of A under the B”. For example, one patient firstly has high glucose which is “B” and then we measure the probability of happening diabetes disease which is “A”, so we measure P (A= diabetes | B= glucose). In the above example, how much is the probability of “good” happening under the “positive” condition.
In good column, there are three yes as blue color which is combination of good as positive and the positive in the last column happened four times, therefore three divided by four is 0.75.
Bayesian Theory
In some other problems, we have sort of events and also some different classes, which some specific sorts of events are belonged to specific class. Then after studying the past information, we want to classify new conditions into classes. In the above examples, there are different sentences which have positive or negative. Then we want to classify new sentence according to the previous categorization. P (new sentence | negative) or P (new sentence | positive) means that whether new sentence is positive or negative. Because sentence includes different words, it should be solved with naïve Bayesian classifier.
According to ten formulas in the below, I have proved how naïve Bayesian has been extracted from the conditional probability formula. Firstly, sentence should be divided by the different words, then once it should be computed, the probability according to positive and then negative state. Then have a comparison between two values rom negative and positive, whatever is greater so sentence belongs to that category. In the below example, “It is good” is 0.28 which is greater than 0.047 so it is a positive sentence.
In the above equation, c has high percentage to occur and is a subset of total hypothesis, because P(x) is independent from h and the existence of P(x) will diminish the , eventually we remove P(x).
Naïve Bayesian Classifier
This method is as practical as neural network and decision tree and is applicable to text categorization and medicine diagnosis. Naïve Bayesian is an approach when we have huge data samples but they pick finite value from set of features that are independent from each other and conjunction. Assume f is target function and x will pick range of value from , our goal is calculate the maximum probability.
Calculation Description
Code
Download Python
If you want to have a comfortable IDE and professional editor, without needing to install libraries, you can use Anaconda & Spider.
Then open Anaconda Navigator from star and select “Spider”:
Naive Bayes
Python Implementation For Naive Bayes Classifier
Step 1: Open "Anaconda Prompt"
Step 2: Install "textblob" for Having Necessary Library
Step 3: Download Corpora
Step 4: Import Important Libraries such as textblob and textblob.classifiers
from textblob.classifiers import NaiveBayesClassifier
from textblob import TextBlob
Step 5: Import Train and Test Set and Use Naive Bayes
train = [
('It is good', 'positive'),
('I feel good about it', 'positive'),
('It is bad', 'negative'),
('It is good', 'positive'),
('It is bad', 'negative'),
('I feel bad about it', 'negative'),
('I feel it is not bad about', 'positive'),
('I feel not good about', 'negative')
]
test = [
('It is good', 'positive'),
('I feel bad about it', 'negative')
]
NB = NaiveBayesClassifier(train)
Step 6: Accuracy Computation
print("Accuracy: {0}".format(NB.accuracy(test)))
Step 7: Test Algorithm With Different Sentences
print(NB.classify('I feel good about spring'))
print(NB.classify('I feel bad about dark'))
Step 8: Opinion Mining or Text Mining for One Document Instead of Sentence
blob = TextBlob("I feel bad about dark."
"I feel good about spring. "
"finally darkness is bad."
, classifier=NB)
print(blob)
print(blob.classify())
for sentence in blob.sentences:
print(sentence)
print(sentence.classify())
print(sentence.sentiment.polarity)
Conclusion
Bayesian Approach
- Gathering existence possible data and knowledge about specific knowledge for data set
- Assign to these data their probabilities, probability distribution, independent hypothesis
- We do the above steps without observing that unknown parameter and based on our judgment
- Collecting raw data from environment
- Observing data and comparing to data set
- Calculate secondary probability distribution
- Do prediction according to average of secondary probability
- Make decision for reduce error from result
Advantage
- Observation of each sample can be deviated our hypothesis accuracy
- Obtain new hypothesis by combination of previous knowledge and new sample
- Bayesian approaches are being able to predict situation in probability way
- Categorize new samples by weight synthetic to several hypothesis
- In some situation, if Bayesian approaches does not work, they are good scale for evaluation of other approaches
Disadvantage
- Prerequisite of almost complete data set (huge volume of data)
- In the absence of this training data set, we have to estimate probability
- This estimation is based on previous observation, experience …
- Making this approximation is very expensive
Feedback
Feel free to leave any feedback on this article; it is a pleasure to see your opinions and vote about this code. If you have any questions, please do not hesitate to ask me here.
History
- 21st July, 2017: Initial version

