Overview
In a previous article, I presented a maximum entropy modeling library called SharpEntropy, a C# port of a mature Java library called the MaxEnt toolkit. The Java MaxEnt library is used by another open source Java library, called OpenNLP, which provides a number of natural language processing tools based on maximum entropy models. This article shows you how to use my C# port of the OpenNLP library to generate parse trees for English language sentences, as well as explores some of the other features of the OpenNLP code. Please note that because the original Java OpenNLP library is published under the LGPL license, the source code to the C# OpenNLP library available to download with this article is also released under the LGPL license. This means, it can freely be used in software that is released under any sort of license, but if you make changes to the library itself and those changes are not for your private use, you must release the source code to those changes.
Introduction
OpenNLP is both the name of a group of open source projects related to natural language processing (NLP), and the name of a library of NLP tools written in Java by Jason Baldridge, Tom Morton, and Gann Bierner. My C# port is based upon the latest version (1.2.0) of the Java OpenNLP tools, released in April 2005. Development of the Java library is ongoing, and I hope to update the C# port as new developments occur.
Tools included in the C# port are: a sentence splitter, a tokenizer, a part-of-speech tagger, a chunker (used to "find non-recursive syntactic annotations such as noun phrase chunks"), a parser, and a name finder. The Java library also includes a tool for co-reference resolution, but the code for this feature is in flux and has not yet been ported to C#. All of these tools are driven by maximum entropy models processed by the SharpEntropy library.
Since this article was first written, the coreference tool has been ported to C# and is available, along with the latest version of the other tools, from the SharpNLP Project on CodePlex.
Setting up the OpenNLP library
Since this article was first written, the required binary data files have now been made available for download from the SharpNLP Project on CodePlex. Instead of downloading the Java-compatible files from Sourceforge and then converting them via the ModelConverter tool, you can download them directly in the required .nbin format.
The maximum entropy models that drive the OpenNLP library consist of a set of binary data files, totaling 123 MB. Because of their large size, it isn't possible to offer them for download from CodeProject. Unfortunately, this means that setting up the OpenNLP library on your machine requires more steps than simply downloading the Zip file, unpacking, and running the executables.
First, download the demo project Zip file and unzip its contents into a folder on your hard disk. Then, in your chosen folder, create a subfolder named "Models". Create two subfolders inside "Models", one called "Parser" and one called "NameFind".
Secondly, download the OpenNLP model files from the CVS repository belonging to the Java OpenNLP library project area on SourceForge. This can be done via a CVS client, or by using the web interface. Place the .bin files for the chunker (EnglishChunk.bin), the POS tagger (EnglishPOS.bin), the sentence splitter (EnglishSD.bin), and the tokenizer (EnglishTok.bin) in the Models folder you created in the first step. This screenshot shows the file arrangement required:

Place the .bin files for the name finder into the NameFind subfolder, like this:
Then, place the files required for the parser into the Parser subfolder. This includes the files called "tagdict" and "head_rules", as well as the four .bin files:
These models were created by the Java OpenNLP team in the original MaxEnt format. They must be converted into .NET format for them to work with the C# OpenNLP library. The article on SharpEntropy explains the different model formats understood by the SharpEntropy library and the reasons for using them.
The command line program ModelConverter.exe is provided as part of the demo project download for the purpose of converting the model files. Run it from the command prompt, specifying the location of the "Models" folder, and it will take each of the .bin files and create a new .nbin file from it. This process will typically take some time - several minutes or more, depending on your hardware configuration.
(This screenshot, like the folder screenshots above it, is taken from the Windows 98 virtual machine I used for testing. Of course, the code works on newer operating systems as well - my main development machine is Windows XP.)
Once the model converter has completed successfully, the demo executables should run correctly.
What does the demonstration project contain?
As well as the ModelConverter, the demonstration project provides two Windows Forms executables: ToolsExample.exe and ParseTree.exe. Both of these use OpenNLP.dll, which in turn relies on SharpEntropy.dll, the SharpEntropy library which I explored in my previous article. The Parse Tree demo also uses (a modified version of) the NetronProject's treeview control, called "Lithium", available from CodeProject here
The Tools Example provides a simple interface to showcase the various natural language processing tools provided by the OpenNLP library. The Parse Tree demo uses the modified Lithium control to provide a more graphical demonstration of the English sentence parsing achievable with OpenNLP.
Running the code in source
The source code is provided for the two Windows Forms executables, the ModelConverter program, and the OpenNLP library (which is LGPL licensed). Source code is also included for the modified Lithium control, though the changes to the original CodeProject version are minimal. Source code for the SharpEntropy library can be obtained from my SharpEntropy article.
The source code is written so that the EXEs look for the "Models" folder inside the folder they are running from. This means that if you are running the projects from the development environment, you will either need to place the "Models" subfolder inside the appropriate "bin" directory created when you compile the code, or change the source code to look for a different location. This is the relevant code, from the MainForm constructor:
mModelPath = System.IO.Path.GetDirectoryName(
System.Reflection.Assembly.GetExecutingAssembly().GetName().CodeBase);
mModelPath = new System.Uri(mModelPath).LocalPath + @"\Models\";
This could be replaced with your own scheme for calculating the location of the Models folder.
A note on performance
The OpenNLP code is set up to use a SharpEntropy.IO.IGisModelReader implementation that holds all of the model data in memory. This is unlikely to cause problems when using some of the simple tools, such as the sentence splitter or the tokenizer. More complex tools, such as the parser and name finder, use several large models. The maximum entropy model data for the English parser consumes approximately 250 MB of memory, so I would recommend that you use appropriately powerful hardware when running this code. If your PC runs out of physical memory and starts using the hard disk instead, you will obviously experience an extreme slowdown in performance.
Detecting the end of sentences
If we have a paragraph of text in a string variable input, a simple and limited way of dividing it into sentences would be to use input.Split('.') to obtain an array of strings. Extending this to input.Split('.', '!', '?') would handle more cases correctly. But while this is a reasonable list of punctuation characters that can end sentences, this technique does not recognize that they can appear in the middle of sentences too. Take the following simple paragraph:
Mr. Jones went shopping. His grocery bill came to $23.45.
Using the Split method on this input will result in an array with five elements, when we really want an array with only two. We can do this by treating each of the characters '.', '!', '?' as potential rather than definite end-of-sentence markers. We scan through the input text, and each time we come to one of these characters, we need a way of deciding whether or not it marks the end of a sentence. This is where the maximum entropy model comes in useful. A set of predicates related to the possible end-of-sentence positions is generated. Various features, relating to the characters before and after the possible end-of-sentence markers, are used to generate this set of predicates. This set of predicates is then evaluated against the MaxEnt model. If the best outcome indicates a sentence break, then the characters up to and including the position of the end-of-sentence marker are separated off into a new sentence.
All of this functionality is packaged into the classes in the OpenNLP.Tools.SentenceDetect namespace, so all that is necessary to perform intelligent sentence splitting is to instantiate an EnglishMaximumEntropySentenceDetector object and call its SentenceDetect method:
using OpenNLP.Tools.SentenceDetect;
EnglishMaximumEntropySentenceDetector sentenceDetector =
new EnglishMaximumEntropySentenceDetector(mModelPath + "EnglishSD.nbin");
string[] sentences = sentenceDetector.SentenceDetect(input);
The simplest EnglishMaximumEntropySentenceDetector constructor takes one argument, a string containing the file path to the sentence detection MaxEnt model file. If the text shown in the simple example above is passed into the SentenceDetect method, the result will be an array with two elements: "Mr. Jones went shopping." and "His grocery bill came to $23.45."
The Tools Example executable illustrates the sentence splitting capabilities of the OpenNLP library. Enter a paragraph of text into the top textbox, and click the "Split" button. The split sentences will appear in the lower textbox, each on a separate line.
Tokenizing sentences
Having isolated a sentence, we may wish to apply some NLP technique to it - part-of-speech tagging, or full parsing, perhaps. The first step in this process is to split the sentence into "tokens" - that is, words and punctuations. Again, the Split method alone is not adequate to achieve this accurately. Instead, we can use the Tokenize method of the EnglishMaximumEntropyTokenizer object. This class, and the related classes in the OpenNLP.Tools.Tokenize namespace, use the same method for tokenizing sentences as I described in the second half of the Sharpentropy article, which I won't repeat here. As with the sentence detection classes, using this functionality is as simple as instantiating a class and calling a single method:
using OpenNLP.Tools.Tokenize;
EnglishMaximumEntropyTokenizer tokenizer =
new EnglishMaximumEntropyTokenizer(mModelPath + "EnglishTok.nbin");
string[] tokens = tokenizer.Tokenize(sentence);
This tokenizer will split words that consist of contractions: for example, it will split "don't" into "do" and "n't", because it is designed to pass these tokens on to the other NLP tools, where "do" is recognized as a verb, and "n't" as a contraction of "not", an adverb modifying the preceding verb "do".
The "Tokenize" button in the Tools Example splits text in the top textbox into sentences, then tokenizes each sentence. The output, in the lower textbox, places pipe characters between the tokens.
Part-of-speech tagging
Part-of-speech tagging is the act of assigning a part of speech (sometimes abbreviated POS) to each word in a sentence. Having obtained an array of tokens from the tokenization process, we can feed that array to the part-of-speech tagger:
using OpenNLP.Tools.PosTagger;
EnglishMaximumEntropyPosTagger posTagger =
new EnglishMaximumEntropyPosTagger(mModelPath + "EnglishPOS.nbin");
string[] tags = mPosTagger.Tag(tokens);
The POS tags are returned in an array of the same length as the tokens array, where the tag at each index of the array matches the token found at the same index in the tokens array. The POS tags consist of coded abbreviations conforming to the scheme of the Penn Treebank, the linguistic corpus developed by the University of Pennsylvania. The list of possible tags can be obtained by calling the AllTags() method; here they are, followed by the Penn Treebank description:
CC Coordinating conjunction RP Particle
CD Cardinal number SYM Symbol
DT Determiner TO to
EX Existential there UH Interjection
FW Foreign word VB Verb, base form
IN Preposition/subordinate VBD Verb, past tense
conjunction
JJ Adjective VBG Verb, gerund/present participle
JJR Adjective, comparative VBN Verb, past participle
JJS Adjective, superlative VBP Verb, non-3rd ps. sing. present
LS List item marker VBZ Verb, 3rd ps. sing. present
MD Modal WDT wh-determiner
NN Noun, singular or mass WP wh-pronoun
NNP Proper noun, singular WP$ Possessive wh-pronoun
NNPS Proper noun, plural WRB wh-adverb
NNS Noun, plural `` Left open double quote
PDT Predeterminer , Comma
POS Possessive ending '' Right close double quote
PRP Personal pronoun . Sentence-final punctuation
PRP$ Possessive pronoun : Colon, semi-colon
RB Adverb $ Dollar sign
RBR Adverb, comparative # Pound sign
RBS Adverb, superlative -LRB- Left parenthesis *
-RRB- Right parenthesis *
* The Penn Treebank uses the ( and ) symbols,
but these are used elsewhere by the OpenNLP parser.
The maximum entropy model used for the POS tagger was trained using text from the Wall Street Journal and the Brown Corpus. It is possible to further control the POS tagger by providing it with a POS lookup list. There are two alternative EnglishMaximumEntropyPosTagger constructors that specify a POS lookup list, either by a filepath or by a PosLookupList object. The standard POS tagger does not use a lookup list, but the full parser does. The lookup list consists of a text file with a word and its possible POS tags on each line. This means that if a word in the sentence you are tagging is found in the lookup list, the POS tagger can restrict the list of possible POS tags to those specified in the lookup list, making it more likely to choose the correct tag.
The Tag method has two versions, one taking an array of strings and a second taking an ArrayList. In addition to these methods, the EnglishMaximumEntropyPosTagger also has a TagSentence method. This method bypasses the tokenizing step, taking in an entire sentence, and relying on a simple Split to find the tokens. It also produces the result of the POS tagging, with each token followed by a '/' and then its tag, a format often used for the display of the results of POS tagging algorithms.
The Tools Example application splits an input paragraph into sentences, tokenizes each sentence, and then POS tags that sentence by using the Tag method. Here, we see the results on the first few sentences of G. K. Chesterton's novel, The Man Who Was Thursday. Each token is followed by a '/' character, and then the tag assigned to it by the maximum entropy model as the most likely part of speech.
Finding phrases ("chunking")
The OpenNLP chunker tool will group the tokens of a sentence into larger chunks, each chunk corresponding to a syntactic unit such as a noun phrase or a verb phrase. This is the next step on the way to full parsing, but it could also be useful in itself when looking for units of meaning in a sentence larger than the individual words. To perform the chunking task, a POS tagged set of tokens is required.
The EnglishTreebankChunker class has a Chunk method that takes in the string array of tokens and the string array of POS tags that we generated by calling the POS tagger, and returns a third string array, again with one entry for each token. This array requires some interpretation for it to be of use. The strings it contains begin either with "B-", indicating that this token begins a chunk, or "I-", indicating that the token is inside a chunk but is not the beginning of it. After this prefix is a Penn Treebank tag indicating the type of chunk that the token belongs to:
ADJP Adjective Phrase PP Prepositional Phrase
ADVP Adverb Phrase PRT Particle
CONJP Conjunction Phrase SBAR Clause introduced by a subordinating conjunction
INTJ Interjection UCP Unlike Coordinated Phrase
LST List marker VP Verb Phrase
NP Noun Phrase
The EnglishTreebankChunker class also has a GetChunks method, which will return the whole sentence as a formatted string, with the chunks indicated by square brackets. This can be called as follows:
using OpenNLP.Tools.Chunker;
EnglishTreebankChunker chunker =
new EnglishTreebankChunker(mModelPath + "EnglishChunk.nbin");
string formattedSentence = chunker.GetChunks(tokens, tags);
The Tools Example application uses the POS-tagging code to generate the string arrays of tokens and tags, and then passes them to the chunker. The result shows the POS tags indicated as before, but with the chunks shown by square-bracketed sections in the output sentences.
Full parsing
Producing a full parse tree is a task that builds on the NLP algorithms we have covered up until now, but which goes further in grouping the chunked phrases into a tree diagram that illustrates the structure of the sentence. The full parse algorithms implemented by the OpenNLP library use the sentence splitting and tokenizing steps, but perform the POS-tagging and chunking as part of a separate but related procedure driven by the models in the "Parser" subfolder of the "Models" folder. The full parse POS-tagging step uses a tag lookup list, found in the tagdict file.
The full parser is invoked by creating an object from the EnglishTreebankParser class, and then calling the DoParse method:
using OpenNLP.Tools.Parser;
EnglishTreebankParser parser =
new EnglishTreebankParser(mModelPath, true, false);
Parse sentenceParse = parser.DoParse(sentence);
There are many constructors for the EnglishTreebankParser class, but one of the simplest takes three arguments: the path to the Models folder, and two boolean flags: the first to indicate if we are using the tag lookup list, and the second to indicate if the tag lookup list is case sensitive or not. The DoParse method also has a number of overloads, taking in either a single sentence, or a string array of sentences, and also optionally allowing you to request more than one of the top ranked parse trees (ranked with the most probable parse tree first). The simple version of the DoParse method takes in a single sentence, and returns an object of type OpenNLP.Tools.Parser.Parse. This object is the root in a tree of Parse objects representing the best guess parse of the sentence. The tree can be traversed by using the Parse object's GetChildren() method and the Parent property. The Penn Treebank tag of each parse node is found in the Type property, except for when the node represents one of the tokens in the sentence - in this case, the Type property will equal MaximumEntropyParser.TokenNode. The Span property indicates the section of the sentence to which the parse node corresponds. This property is of type OpenNLP.Tools.Util.Span, and has the Start and End properties indicating the characters of the portion of the sentence that the parse node represents.
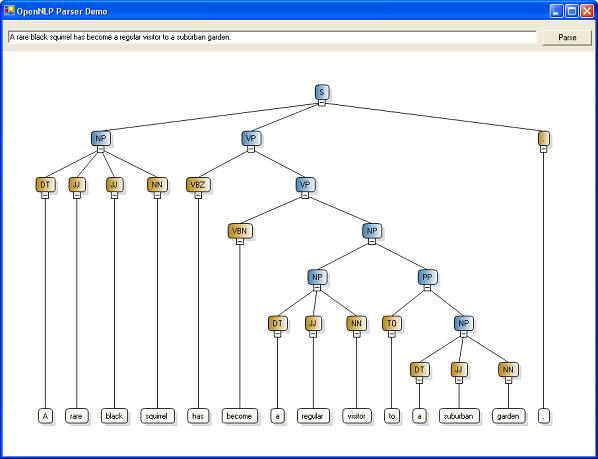
The Parse Tree demo application shows how this Parse structure can be traversed and mapped onto a Lithium graph control, generating a graphical representation of the parse tree. The work is kicked off by the ShowParse() method of the MainForm class. This calls the recursive AddChildNodes() method to build the graph.
The Tools Example, meanwhile, uses the built-in Show() method of the root Parse object to produce a textual representation of the parse graph:
Name finding
"Name finding" is the term used by the OpenNLP library to refer to the identification of classes of entities within the sentence - for example, people's names, locations, dates, and so on. The name finder can find up to seven different types of entities, represented by the seven maximum entropy model files in the NameFind subfolder - date, location, money, organization, percentage, person, and time. It would, of course, be possible to train new models using the SharpEntropy library, to find other classes of entities. Since this algorithm is dependent on the use of training data, and there are many, many tokens that might come into a category such as "person" or "location", it is far from foolproof.
The name finding function is invoked by first creating an object of type OpenNLP.Tools.NameFind.EnglishNameFinder, and then passing it the path to the NameFind subfolder containing the name finding maximum entropy models. Then, call the GetNames() method, passing in a string array of entity types to look for, and the input sentence.
using OpenNLP.Tools.NameFind;
EnglishNameFinder nameFinder =
new EnglishNameFinder(mModelPath + "namefind\\");
string[] models = new string[] {"date", "location", "money",
"organization", "percentage", "person", "time"};
string formattedSentence = mameFinder.GetNames(models, sentence);
The result is a formatted sentence with XML-like tags indicating where entities have been found.
It is also possible to pass a Parse object, the root of a parse tree structure generated by the EnglishTreebankParser, rather than a string sentence. This will insert tags into the parse structure showing the entities found by the Name Finder.
Conclusion
My C# conversion of the OpenNLP library provides a set of tools that make some important natural language processing tasks simple to perform. The demo applications illustrate how easy it is to invoke the library's classes and get good results quickly. The library does rely on holding large maximum entropy model data files in memory, so the more complicated NLP tasks (full parsing and name finding) are memory-intensive. On machines with plenty of memory, performance is impressive: a 3.4 Ghz Pentium IV machine with 2 GB of RAM loaded the parse data into memory in 12 seconds. Querying the model once loaded by passing sentence data to it produced almost instantaneous parse results.
Work on the Java OpenNLP library is ongoing. The C# version now has a coreference tool and its development is also active, at the SharpNLP Project on CodePlex. Investigations into speedy ways of retrieving MaxEnt model data from disk rather than holding data in memory also continue.
References
History
- Third version (13th December 2006. Added references to the SharpNLP Project on CodePlex.
- Second version (4th May 2006). Added .NET 2.0 versions of the code for download.
- Initial version (30th October 2005).

