In this post, you will get a basic idea of machine learning and Perceptron learning algorithm.
Machine learning is a term that people are talking about often in the software industry, and it is becoming even more popular day after day. Media is filled with many fancy machine learning related words: deep learning, OpenCV, TensorFlow, and more. Even people who are not in the software industry are trying to leverage the power of machine learning. It is not surprising that its application is becoming more widespread day by day in every business.
However, it is easy to neglect or just simply forget the fundamentals of machine learning when our minds are filled with so many amazing machine learning ideas and terminologies. This article aims not only to review the fundamentals of machine learning, but also to give a brief concept of machine learning for people who learn machine learning the first time, so they know what machine learning is, how it works, how to do it well, and realize that machine learning is not magic.
Hopefully, experienced readers can benefit from reviewing the fundamental concepts of machine learning, and newbies can get the basic idea of machine learning from this article.
What Is Machine Learning? What Can It Do?
Machine learning is a subfield of Artificial Intelligence. As its name applies, it tries to help machines ‘’learn’’ something from data. Recall how we learnt to recognize an animal, for instance, a dog, when we were little kids? We probably started from reading a book which contains dog pictures, i.e., the data, and then we know it is a dog when we encountered a dog after. That is the essence of machine learning: learning from data.
It is always easy to explain a concept with an example. This Kaggle Competition, Predict Grant Applications, in which I participated several years ago, awarded participants who can provide a model to help them simplify and accelerate the review process to reduce the cost.
The traditional way to determine if an applicant qualifies for the grant is that the academic reviewers spend their time to review applicants’ documents and make decisions. This process takes quite a lot of time; especially this school claims that majority of the applications end up with rejection. The valuable academic reviewers’ time is wasted.
Here is where machine learning can help. Machine learning approach can preliminarily filter the applications that the machine learning approach predicts have a high chance to succeed. Therefore, the review committee can spend their time on these candidates.
Therefore, the main goal of machine learning is to deduce the future or to make decisions by training mathematical models with context-related data.
How Does It Work?
Machine learning starts from the data. Before answering this question, let’s first look at the data. The following table depicts an excerpt of the Predict Grant Applications Data Set. This table demonstrates the common notations used in machine learning areas such as samples, features, and labels.
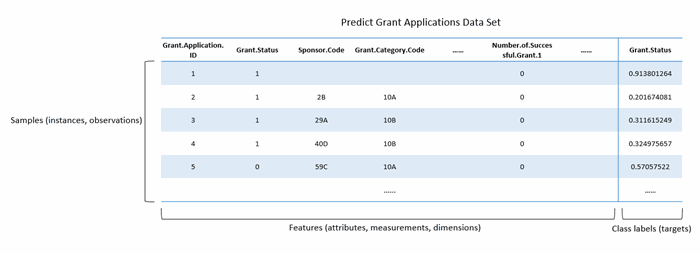
So, how does machine learning work? First of all, everybody would agree that some attributes have a heavier weight than others in the Predict Grant Applications example. As well as the review committee, during their reviewing, the academic reviewer may have the sense that some attributes are more important than others. For instance, the number of journal articles is probably more important than the application’s Person ID. This fact implies that a pattern of a successful application exists. Second, even if we know the pattern exists, it is impossible (or very hard) to write down a math formula to decide who would be granted. Otherwise, we would just write a program by using the math formula to solve this problem at once. Third, this school has a historical record of this program, i.e., they have data. These matters conclude the nature of using machine learning to solve a problem if the problem has the following characteristics:
- A pattern exists. (In this Predict Grant Applications example, the reviewers have a feeling that some attributes are more important than others.)
- No easy way to solve this problem by a math equation. (Probably this is the main reason why we need machine learning approach. A math formula solution is always better than machine learning solution, if we can find one.)
- We have data. (In this example, the University of Melbourne has historical records of applications; without data, there is nothing machine learning can do.)
Once a problem meets these three points, machine learning is ready to solve this problem. A basic machine learning approach has the following components.
- Target function: an unknown ideal function. It exists, but unknown
- Hypothesis set which contains all the possible functions. For example, Perceptron, Neural Network, Support Vector Machine, and so on.
- Learning algorithm to pick the optimal function from the hypothesis set based on the data. For instance, Perceptron Learning Algorithm, backpropagation, quadratic programming, and so forth.
- Learning model: Normally, the combination of hypothesis set and learning algorithm can be referred to as a learning.

There are many tools, i.e., learning models, to work on machine learning problems. Therefore, the first step is to pick up a learning model to start. Each learning model has its strength and weakness; some may be good at a certain problem; some maybe not. How to choose an appropriate learning model is out of the topic of this article, but, at least, we can always pick one as a starting point.
As soon as a learning model has been picked, we can start training the model by feeding data. Take the Predict Grant Application as an example again; this process starts with random factors, i.e., the weights of each attribute. Then turns these factors to make them more and more aligned with how the academic reviewers have reviewed the applications before by feeding the historical records until they are ultimately able to predict how reviewers determine if applicants are granted in general. This process is so called training model.
After the model is trained, the model can predict the results with feeding the new data. In the Predict Grant Application example, the new data could be the current year’s applications. The university can use this model to filter out the applications that unlikely succeed, so the review committee can focus on the applications that have a high chance to succeed.
A benefit of the machine learning approach is that it can be generalized to much larger datasets in many more dimensions. It is trivial when the problem is in a low number of dimensions, i.e., number of attributes. However, the reality is that the data set that University of Melbourne provided has 249 features, which makes this problem much harder (and almost impossible to pin it down to a simple math formula). Fortunately, the power of machine learning is that it can be straightforwardly applied and evaluated in the case of data with many more features.
The next section uses probably the simplest learning model to demonstrate the basic workflow of machine learning approach.
A Simple Example: Perceptron Learning Algorithm
This example uses a classic data set, Iris Data Set, which contains three classes of 50 instances each, where each class refers to a type of iris plant. The goal of this example is to use machine learning approach to build a program to classify the type of iris flowers.
Problem Setup
The Iris Data Set contains three classes (classes normally can be referred to labels as well): Iris Setosa, Iris Versicolour, and Iris Virginica.
Besides classes, each instance has following attributes:
- Sepal length in cm
- Sepal width in cm
- Petal length in cm
- Petal width in cm
Each instance, a.k.a., sample, of the Iris Data Set looks like (5.1, 3.5, 1.4, 0.2, Iris-setosa):
The learning model this example chooses is Perceptron and Perceptron Learning Algorithm.
Perceptron Learning Algorithm
Perceptron Learning Algorithm is the simplest form of artificial neural network, i.e., single-layer perceptron. A perceptron is an artificial neuron conceived as a model of biological neurons, which are the elementary units in an artificial neural network. An artificial neuron is a linear combination of certain (one or more) inputs and a corresponding weight vector. That is to say that a perceptron has the following definitions:
Given a data set which contains training data set and output labels , and can be formed as a matrix.
Each is one sample of ,
Each is the actual label and has a binary value: .
is the weight vector. Each has a correspoinding weight
Since a perceptron is a linear combination of and , it can be denoted as
For each neuron , the output is , where the is the transfer function:
For the sake of simplicity, can be treated as , where
Therefore, the linear combination of and can be rewritten as
The output of jth neuron is , where the is the transfer function:
The Learning Steps
Given the definition of Perception, the Perceptron Learning Algorithms works by the following steps:
- Initialize the weights to 0 or small random numbers.
- For each training sample, , perform the following sub steps:
- Compute , the linear combination of and , to get the predicted output, class label .
- Update the weights
- Record the number of misclassification
- If the number of misclassification is not 0 after training the whole set, , repeat steps 2 and start from the beginning of the training set, i.e., start from . Repeat this step until the number of misclassification is 0.
Note:
The output of 2.1 is the class predicted by the function.
In step 2.2, the update of each weight, , of follows the rule:
, where indicatees the step: means current step, and means next step. Therefore, indicates the current weight and indicates the weight after updated.
If no misclassify, or . In this case, . No update.
If misclassify, or . In this case, or . Weight updates.
In the step 2.3, the convergence of PLA is only guaranteed if the two classes are linearly separable. If they are not, the PLA never stops. One simple modification is Pocket Learning Algorithm, which will be discussed in a future post.
The Perceptron Learning Algorithm can be simply implemented as follows:
import numpy as np
class PerceptronClassifier:
'''Preceptron Binary Classifier uses Perceptron Learning Algorithm
to do classification with two classes.
Parameters
----------
number_of_attributes : int
The number of attributes of data set.
Attributes
----------
weights : list of float
The list of weights corresponding <
g class="gr_ gr_313 gr-alert gr_gramm gr_inline_cards gr_run_anim
Grammar multiReplace" id="313" data-gr-id="313">with&
lt;/g> input attributes.
errors_trend : list of int
The number of misclassification for each training sample.
'''
def __init__(self, number_of_attributes: int):
self.weights = np.zeros(number_of_attributes + 1)
self.misclassify_record = []
self._label_map = {}
self._reversed_label_map = {}
def _linear_combination(self, sample):
'''linear combination of sample and weights'''
return np.inner(sample, self.weights[1:])
def train(self, samples, labels, max_iterator=10):
'''Train the model
Parameters
----------
samples : two dimensions list
Training data set
labels : list of labels
Class labels. The labels can be anything as long as it has
only two types of labels.
max_iterator : int
The max iterator to stop the training process
in case the training data is not converaged.
'''
self._label_map = {1 : list(set(labels))[0], -1 : list(set(labels))[1]}
self._reversed_label_map = {value : key for key, value in self._label_map.items()}
transfered_labels = [self._reversed_label_map[index] for index in labels]
for _ in range(max_iterator):
misclassifies = 0
for sample, target in zip(samples, transfered_labels):
linear_combination = self._linear_combination(sample)
update = target - np.where(linear_combination >= 0.0, 1, -1)
self.weights[1:] += np.multiply(update, sample)
self.weights[0] += update
misclassifies += int(update != 0.0)
if misclassifies == 0:
break
self.misclassify_record.append(misclassifies)
def classify(self, new_data):
'''Classify the sample based on the trained weights
Parameters
----------
new_data : two dimensions list
New data to be classified
Return
------
List of int
The list of predicted class labels.
'''
predicted_result = np.where((self._linear_combination(new_data) +
self.weights[0]) >= 0.0, 1, -1)
return [self._label_map[item] for item in predicted_result]
Apply Perceptron Learning Algorithm onto Iris Data Set
Normally, the first step to apply machine learning algorithm to a data set is to transform the data set to something or format that the machine learning algorithm can recognize. This process may involve normalization, dimension reduction, and feature engineering. For example, most machine learning algorithms only accept numerical data. Therefore, a data set needs to transfer to a numerical format.
In the Iris Data Set, the attributes, sepal length, sepal width, petal length, and petal width, are a numerical value, but the class labels are not. Therefore, in the implementation of PerceptronClassifier, the train function transfers the class labels to a numerical format. A simple way is to use numbers to indicates these labels: , which means 0 indicates Setosa, 1 implies Versicolour, and 2 means Virginica. Then, the Iris Data Set can be viewed as the form below to feed into Perceptron Learning Algorithm.
Perceptron is a binary classifier. However, the Iris Data Set has three labels. There are two common ways to deal with multiclass problems: one-vs-all and one-vs-one. For this section, we use a simplified one-vs-one strategy to determinate the types of the iris plant.
One-vs-one approach trains a model for each pair of classes and determines the correct class by a majority vote. For example, the Iris Data Set has three classes. That means all the combinations of a pair of the three classes. That means .
Besides, machine learning is not restricted to use all features that the data set has. Instead, only important features are necessary. Here, we only consider the two features, Sepal width, and Petal width. In fact, choosing the right features is so important that there is a subject called Feature Engineering to deal with this problem.
import numpy as np
import pandas as pd
import urllib.request
from perceptronlib.perceptron_classifier import PerceptronClassifier
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
urllib.request.urlretrieve(url, 'iris.data')
IRIS_DATA = pd.read_csv('iris.data', header=None)
SETOSA_LABEL = IRIS_DATA.iloc[0:40, 4].values
VERSICOLOR_LABEL = IRIS_DATA.iloc[50:90, 4].values
VIRGINICA_LABEL = IRIS_DATA.iloc[100:140, 4].values
SETOSA_VERSICOLOR_TRAINING_LABEL = np.append(SETOSA_LABEL, VERSICOLOR_LABEL)
SETOSA_VIRGINICA_TRAINING_LABEL = np.append(SETOSA_LABEL, VIRGINICA_LABEL)
VERSICOLOR_VIRGINICA_TRAINING_LABEL = np.append(VERSICOLOR_LABEL, VIRGINICA_LABEL)
SETOSA_DATA = IRIS_DATA.iloc[0:40, [1, 3]].values
VERSICOLOR_DATA = IRIS_DATA.iloc[50:90, [1, 3]].values
VIRGINICA_DATA = IRIS_DATA.iloc[100:140, [1, 3]].values
SETOSA_VERSICOLOR_TRAINING_DATA = np.append(SETOSA_DATA, VERSICOLOR_DATA, axis=0)
SETOSA_VIRGINICA_TRAINING_DATA = np.append(SETOSA_DATA, VIRGINICA_DATA, axis=0)
VERSICOLOR_VIRGINICA_TRAINING_DATA = np.append(VERSICOLOR_DATA, VIRGINICA_DATA, axis=0)
SETOSA_TEST = IRIS_DATA.iloc[40:50, [1, 3]].values
VERSICOLOR_TEST = IRIS_DATA.iloc[90:100, [1, 3]].values
VIRGINICA_TEST = IRIS_DATA.iloc[140:150, [1, 3]].values
TEST = np.append(SETOSA_TEST, VERSICOLOR_TEST, axis=0)
TEST = np.append(TEST, VIRGINICA_TEST, axis=0)
SETOSA_VERIFY = IRIS_DATA.iloc[40:50, 4].values
VERSICOLOR_VERIFY = IRIS_DATA.iloc[90:100, 4].values
VIRGINICA_VERIFY = IRIS_DATA.iloc[140:150, 4].values
VERIFY = np.append(SETOSA_VERIFY, VERSICOLOR_VERIFY)
VERIFY = np.append(VERIFY, VIRGINICA_VERIFY)
perceptron_setosa_versicolor = PerceptronClassifier(2)
perceptron_setosa_versicolor.train(SETOSA_VERSICOLOR_TRAINING_DATA,
SETOSA_VERSICOLOR_TRAINING_LABEL)
perceptron_setosa_virginica = PerceptronClassifier(2)
perceptron_setosa_virginica.train(SETOSA_VIRGINICA_TRAINING_DATA,
SETOSA_VIRGINICA_TRAINING_LABEL)
perceptron_versicolor_virginica = PerceptronClassifier(2)
perceptron_versicolor_virginica.train(VERSICOLOR_VIRGINICA_TRAINING_DATA,
VERSICOLOR_VIRGINICA_TRAINING_LABEL)
predict_target_1 = perceptron_setosa_versicolor.classify(TEST)
predict_target_2 = perceptron_setosa_virginica.classify(TEST)
predict_target_3 = perceptron_versicolor_virginica.classify(TEST)
overall_predict_result = []
for item in zip(predict_target_1, predict_target_2, predict_target_3):
unique, counts = np.unique(item, return_counts=True)
temp_result = (zip(unique, counts))
overall_predict_result.append(sorted
(temp_result, reverse=True, key=lambda tup: tup[1])[0][0])
misclassifier = 0
for predict, verify in zip(overall_predict_result, VERIFY):
if predict != verify:
misclassifier += 1
print("The number of misclassifier: " + str(misclassifier))
The complete code can be found at https://github.com/burpeesDaily/ml-toybox/blob/main/mltoolbox/perceptron_classifier.py.
Is Learning Feasible?
Many people may see machine learning is magic. It is not. In fact, machine learning is all about math, especially probability and statistics.
Learning vs. Memorizing
To show if learning is feasible, we need to define what is learning? In the section, A Simple Example, the Perceptron Learning Algorithm eventually succeeds to classify all the iris flowers, but is it really learning? Or, it is just memorizing? To answer these questions, we define in-sample error and out-of-sample error. The in-sample error means the error rate within the sample. For example, in the end, the Perceptron learning model can classify all the iris flowers in the Iris Data Set. Its in-sample error is 0, i.e., no error at all. In contrast to in-sample error, the out-of-sample error means the error rate outside of the sample. In other words, it indicates the number of errors when the learning model sees new data. Take the same example, if we feed new data to the Perceptron learning model, the rate of misclassification is its out-of-sample error. Therefore, to say a learning model is real learning, not only the in-sample error has to be small, but also the out-of-sample error has to be small.
So, is Learning Feasible?
The simple answer is yes: the learning is feasible in the mathematical sense.
In probability and statistics, there are two important theories which can briefly show the learning is feasible: Central Limit Theorem and Law of Large Number. The Central limit theorem states that the distribution of the average of a large number of independent and identically distributed variables will be approximately normal distribution, regardless of the underlying distribution. Law of Large Numbers describes that as more sample are collected, the average of the results should be close to the expected value, and will tend to become closer as more trials are performed. The mathematical theory guarantees that a sample proportion or a difference in sample proportions will follow something that resembles a normal distribution as long as 1. Observations in the sample are independent. 2. The sample is large enough. In an oversimplified sense, the learning results we see in-sample should be seen in out-of-sample data. Therefore, learning is feasible.
Of course, this statement is oversimplified. The detail of theories to support the feasibility of machine learning is out of the topic of this article. There are many resources to address this topic. One resource I recommended is this book, Learning from Data, especially ch2 VC Dimension to generalization.
In short, to make learning feasible, the learning model has to achieve:
- In-sample error is small
- Out-of-sample error is close to the in-sample error
How Do We Know if We Learn Well?
The conclusion in the previous section addresses that if the in-sample error is small and the out-of-sample error is close to the in-sample error, then the learning model learns something. What does it mean the in-sample error is small and the out-sample error is close to the in-sample error? How small the in-sample error should be and how close the out-of-sample error could be? Of course, if both in-sample error and out-of-sample are zero, the learning model learns perfectly. Unfortunately, most of the real-world problems are not like it. In fact, the machine learning approach is not about finding the ideal target function; instead, the machine learning approach looks for a hypothesis function which approximates to the target function . (the target function is always unknown; otherwise, we would not bother to use machine learning approach.) In other words, the machine learning approach looks for a good enough solution which is close enough to . What does good enough means? To quantify how well close to , we need a way to define the distance between and . Usually, it is called error measure or error function (the error is also referred to as cost or risk).
Error Measure
In general, we define a non-negative error measure by taking two arguments, expected and predicted output, and computing a total error value over the whole dataset.
, where is a hypothesis and is the target function. is based on the errors on individual input . Therefore, we can define a pointwise error measure . The overall error then is the average value of this pointwise error.
The choice of an error measure affects the choice of the learning model. Even if the data set and the target function are the same, the meaning of error measure may vary depending on different problems. For example, an email spam classifier. There are two error outcomes of a learning model for this email spam problem: false positive and false negative. The former means an email is a spam but the learning model determines it is not; the latter indicates that the learning model says an email is spam, but it is not. Imagine two scenarios: our personal email account and working email account.
In the personal email account case, if the learning model fails to filter out spam emails, it is probably fine. Just annoying. On the other hand, if the learning model filters out some email which is not spam, for example, an email from friends or a credit card company. In this case, it probably fine too. We can use the table below to measure this case.
| | An email is a spam | An email is not spam |
| Classify an email is a spam | 0 | 1 |
| Classify an email is not spam | 1 | 0 |
If the learning model classifies an email correct, the cost of this error is 0. Otherwise, the cost is 1.
In the other case: working email account. Same as the personal account, if a learning model fails to filter out spam, it is annoying but fine. However, if the learning model classifies the emails from our boss as spam, and leads us to miss these email, then it is probably not fine. Therefore, in this case, the cost of false negative has a heavier weight than the previous example.
| | An email is a spam | An email is not spam |
| Classify an email is a spam | 0 | 10 |
| Classify an email is not spam | 1 | 0 |
Again, the error function (or cost function, risk function) really depends on different problems and should be defined by customers.
Overfitting and Underfitting
The conclusion of the section, Is Learning Feasible, shows that to make learning feasible, the learning model has to achieve that in-sample error is small and the out-of-sample error is close to the in-sample error. Normally, a training set is a representation of the global distribution, but it is not possible to contain all possible elements. Therefore, when training a model, it is necessary to try to fit the training data, i.e., keep the in-sample error small, but it is also necessary to try to keep the model able to generalize when the unseen input is presented, i.e., keep the out-of-sample error small. Unfortunately, this ideal condition is not easy to find, and it is important to be careful of these two phenomena: overfitting and underfitting.
The figure shows a normal classification on two classes data.
Underfitting means that the learning model is not able to capture the pattern shown by the training data set. The picture below demonstrates the case of underfitting.
Usually, underfitting is easy to be observed because the learning model does not fit the in-sample data well when it happens. In other words, when underfitting happens, the in-sample error is high.
Overfitting is the opposite of underfitting. It means that the learning model fits the training data very well, but too well to fits the out-of-sample data. That is to say, an overfitting learning model loses its generalization, so when the unknown input is presented, the corresponding prediction error can be very high.
Different than underfitting, overfitting is difficult to notice or prevent, because the in-sample error of an overfitting learning model is usually very low. We may think we train this model very well until the new data come, and the out-of-sample error is high. Then we realize that the model is overfitting.
Overfitting usually happens in case the learning model is more complex than is necessary to represent the target function. In short, the overfitting issue can be summarized as follows:
- The number of data points increases, the chance of overfitting decreases.
- If the data set has much noise, the chance of overfitting is high.
- The more complex the model is, the easier overfitting happens.
Types of Learning
Based on the type of data and problems we want to solve, we can roughly categorize learning problem into three groups: supervised learning, unsupervised learing, and reinforcement learning.
Supervised Learning
Supervised Learning is probably the most well-studied learning problem. Essentially, in supervised learning, each sample contains the input data and explicit output, i.e., correct output. In other words, supervised learning can be formed as (input, correct output).
The Iris Data Set is a typical supervised learning. The data set has five attributes as input: sepal length, sepal width, petal length, petal width, and correct output, types of the iris plant. We can visualize the supervised learning by plotting the Iris Data Set. For the sake of simplicity, we plot a 2-D picture by taking sepal length and petal length as input and using different colors and symbols to indicate each class.
The sample code can be found at https://github.com/burpeesDaily/formosa1544/blob/main/machine-learning-basics-and-perceptron-learning-algorithm/supervised.py.
The main goal of supervised learning is to learn a model from data which has correct labels to make predictions on unseen or future data. Common supervised learning problems include: Classification for predicting class labels and regression for predicting continuous outcomes, for example, spam detection, pattern detection instance, natural language processing.
Unsupervised Learning
In contrast to supervised learning, the data set of unsupervised does not contain correct output, and can be formed as (input, ?)
If we do not plot the type as different colors, the Iris Data Set became an example of unsupervised learning.
The sample code can be found at https://github.com/burpeesDaily/formosa1544/blob/main/machine-learning-basics-and-perceptron-learning-algorithm/unsupervised.py.
In many cases, a data set only has input but does not contain a correct output, like the picture above. Then, how can we learn something from unsupervised learning problems? Fortunately, although there is no correct output, it is possible to learn something from the input. For example, in the picture above, each ellipse represents a cluster and all the points inside its area can be labeled in the same way. (Of course, we knew the Iris Data Set has three class, here we just pretend we did not know that Iris Data Set has three classes). Using unsupervised learning techniques, we can explore the structure of a data set to extract meaningful information without having any prior knowledge of their group. Because unsupervised learning problems do not come with labels, it deals with problems like discovering hidden structures with unsupervised learning, finding subgroups with clustering, and dimensionality reduction for data compression.
Reinforcement Learning
Different from supervised learning which has output, and unsupervised learning which contains no correct output, the data set of reinforcement learning contains input and some grade of output, and can be formed as (input, some output with grade).
One good example of reinforcement learning is playing games such as chess and go. The determination of the next step is based on the feedback of current state. Once the decision of the new step made, a grade of this step observed. The goal of reinforcement learning is to find out the sequence of most useful actions, so the reinforcement learning model can always make the best decision.
Online vs. Offline
Learning problems can also be viewed by the way how to train models.
Online Learning
The data set is given to the algorithm one example at a time. Online learning happens when we have streaming data that the algorithm has to process ‘’on the run’’.
Offline Learning
Instead, give the algorithm one example at a time, we have many data to train the algorithm in the beginning. The Iris Data Set example is offline learning.
Both online and offline learning can be applied to supervised, unsupervised, and reinforcement.
Challenges in Machine Learning
With the development of machine learning (ML) and artificial intelligence (AI), many AI/ML powered tools and programs have shown unlimited potential in many fields. However, machine learning is not that powerful as many people thought. Instead, it has many significant weaknesses that many researchers are eager to solve. Following are some challenges machine learning industry faces today.
First of all, there is no easy way to transfer a learned model from one learning problem to another. As a human, when we are good at one thing, say playing go, chances are we are also good at similar games such as playing chase, bridge, or, at least, easy to learn those. Unfortunately, for machine learning, it needs to start over the learning process for every single problem even if the problem is similar to others. For example, the Perceptron learning model that we trained to classify iris plant in the previous section, what it can do is to classify iris plant, no more. If we want to classify different flowers, we have to train a new learning model from scratch.
The second challenge is that there is no smart way to label data. Machine learning can do many things and can learn from all kinds of data. Nevertheless, it does not know how to label data. Yes, we can train a learning model to recognize an animal, say cats, by feeding many cat pictures. However, in the beginning, someone, a human, needs to label the pictures if it is a cat picture or not. Even if unsupervised learning can help us group data, it still does not know if a group of pictures is a cat or not. Today, labeling data still requires human involvement.
Third, even the creator of a machine learning solution does not know why the machine learning solution makes this decision. The essence of machine learning is learning from data. We feed data to a learning model, and it predicts the results. In the Perceptron Learning Algorithm example, the weights of the final hypothesis may look likes [ -4.0, -8.6, 14.2], but it is not easy to explain why the learning model gave us these weights. Even the simplest learning algorithm, Perceptron, we are not able to explain why. Needless to say, it is almost impossible to explain how more sophisticated learning algorithms work. This issue may lead to serious consequences. Especially, for learning problems that have a high cost of error, for example, self-driving car, if the thing goes wrong and we do not know how does it go wrong, how do we fix it.
These three challenges are just the tip of the iceberg. Although machine learning seems to have unlimited potential, it still has a long way to go.

