As an example of performing the actual sorting, I will implement a sample program that performs sorting of an array, each element of which is an object that stores two variables of either a key or its value. Also, by using this program, I will evaluate the overall performance of the stable sort being implemented, comparing it to the performance of the conventional qsort( ... ) or std::sort( ... ) functions.
Note: Optionally, you can evaluate the program, that performs the fast parallel sort, discussed in this article, by using the virtual machine environment with CentOS 64-bit and parallel sort executable pre-installed, available for download here. (login: root passwd: intel)
Introduction
In the previous article, I discussed about the implementation of an efficient parallel three-way quicksort used for sorting the arrays of elements having fundamental data types, such as integers or floating-point values. Although, this kind of sort is rarely used. Typically, we sort arrays of elements that have more complex data types, so that each element of an array is an object of a user-defined abstract data type (ADT). In turn, an object is a collection of multiple values, each one having a particular fundamental data type.
Obviously, that, we need to do a more complex sort to re-order arrays of objects, mentioned above. For that purpose, we normally use "stable" sorting algorithms that allow us to sort the arrays of objects by more than one value. The using of the most of existing "stable" sorting algorithms is not efficient due to a typically huge computational complexity, while the existing variations of the "quicksort'' are simply not "stable" by its nature.
In this article, I will introduce an approach that allows to perform the efficient "stable" three-way quicksort. Specifically, I will formulate an algorithm for re-ordering the data stored in more complex data structures, performing the parallel stable sort. The entire process of the stable sort, being discussed, is much similar to performing the GROUP BY operation in SQL, in which the data is sorted by the value of more than one variable.
As well, I will discuss how to deliver the modern code, using Intel C++ Compiler and OpenMP 4.5 library, that implements the parallel "stable" three-way quicksort, based on the parallel code that has already been discussed in the previous article.
As an example of performing the actual sorting, I will implement a sample program that performs sorting of an array, each element of which is an object that stores two variables of either a "key" or its "value". Also, by using this program, I will evaluate the overall performance of the stable sort being implemented, comparing it to the performance of the conventional qsort( ... ) or std::sort( ... ) functions.
Why the Efficient Three-Way Quicksort is Not "Stable" ...
The quicksort algorithm, as well as the heapsort, is said to be "unstable", since, while sorting an array of objects by the value of the first variable, it does not maintain a relative order of objects by the value of the second variable. In most cases, the objects ordered by the key are swapped based on the value of pivot and the specific order of the objects with an equal key is simply ignored.
Specifically, it's impossible to perform the "stable" sorting by solely using the either internal::parallel_sort( ... ) or the regular std::sort( ... ) functions, such as:
std::sort(v.begin(), v.end(), [&](const ITEM& iteml, const ITEM& item2) {
return (iteml.key == item2.key) && (iteml.value < item2.value);
});
std::parallel_sort(v.begin(), v.end(), [&](const ITEM& iteml, const ITEM& item2) {
return (iteml.key == item2.key) && (iteml.value < item2.value);
});
The basic outcomes of performing the improper or inconsistent sorting are caused by the nature of the quicksort and heapsort algorithms, itself. Also, the known implementations of the fast quicksort are not providing an ability to perform the more complex, "stable" sort.
That's actually why, I will introduce and formulate an algorithm that allows to perform a stable sort via the array partitioning and the number of simple sorts, by using the same internal::parallel_sort( ... ) or std::sort( ... ) functions.
The "Stable" Sorting Algorithm
The entire process of the stable sorting is rather intuitively simple and can be formulated as the following algorithm:
- Sort all objects in an array by a specific key;
- Partition the array into k-subsets of objects with an equal key;
- Sort each subset of objects by its value, independently;
First, we select one of the object's variables, which is said to be a "key" and sort an entire array of objects by the key, using the std::sort( ... ) or intemal::parallel_sort( ... ) functions, the way we've already done it while sorting arrays of values having the fundamental data types.
Since, all objects in the array have been re-ordered by the key, then, we need to split up an entire array being sorted into the number of kpartitions, each one consisting of objects having an equal key. To partition an array, the following algorithm is applied:
- Let
arr[O .. N] - an array objects sorted by the "key", N - the number of objects in the array; - Initialize the First and Last variables as the index of the first object (First= Last= O);
- Initialize the variable
i as the index of the first object (i = O); - For each i-th object in the array (
i < (N - 1 )), do the following:
Compare the key of the i-th object arr[i].key to the key of the succeeding object arr[i+1].key, in the array being partitioned:
- If the keys of these objects are not equal (
arr[i].key != arr[i + 1].key),
then assign the index (i + 1) to the variable Last (Last = i + 1 ); - Sort all objects in the range of
arr[First..Last] by its value; - Assign the value of the variable
Last to the variable First (First = Last);
The main goal of the following algorithm is to find the indices of the first and last object within each partition, and, then, sort all objects in the range of arr[First..Last] by its value. This algorithm is mainly based on the idea of sequentially finding those partitions, so that the index of the last object in the current partition exactly matches the index of the first object within the next partition. It maintains two indices of the first and last object, respectively. Initially, these variables are assigned to the index of the first object in the array. Then, it iterates through each object, performing a simple linear search to find two adjacent objects, which keys are not equal. If such objects have been found, it assigns the index (i + 1) to the variable Last and finally sorts all objects in the current partition, which indices belong to the interval from First to Last, by its value. After that, the value of the index variable First is updated with the specific value of the variable Last and the partitioning proceeds with finding the index of the last object within the next partition to be sorted, and so on.
The code in C++11 listed below implements the partitioning algorithm being discussed:
template<class BidirIt, class _CompKey, class _CompVals>
void sequential_stable_sort(BidirIt _First, BidirIt _Last,
_CompKey comp_key, _CompVals comp_vals)
{
std::sort(_First, _Last, comp_key);
BidirIt _First_p = _First, _Last_p = _First_p;
for (BidirIt _FwdIt = _First + 1; _FwdIt != _Last; _FwdIt++)
{
if ((comp_key(*_FwdIt, *(_FwdIt - 1)) || (comp_key(*(_FwdIt - 1), *_FwdIt))))
{
_Last_p = _FwdIt;
if (_First_p < _Last_p)
{
std::sort(_First_p, _Last_p, comp_vals);
_First_p = _Last_p;
}
}
}
std::sort(_First_p, _Last, comp_vals);
}
The following approach combines the steps 2 and 3 of the stable sorting algorithm, introduced above. The computational complexity of the sequential partitioning is always O(n), but its performance can be drastically improved via several parallel optimizations, using Intel C++ Compiler and OpenMP 4.5 library.
Running the "Stable" Quicksort in Parallel
In the parallel version of the code implementing the stable three-way quicksort, we first re-order the array of objects by the key selected. This is typically done by spawning a separate OpenMP task using #pragma omp task untied mergeable {} directive, that invokes the intemal::parallel_sort( ... ) function:
#pragma omp task mergeable untied
internal::parallel_sort(_First, _Last, comp_key);
After the array of objects has been successfully sorted by the key, it launches the partitioning in parallel. Unlike the sequential variant of the partitioning algorithm, it no longer maintains the corresponding First and Last indices, since it normally incurs the data flow dependency issue and thus, the process of partitioning cannot be run in parallel. Instead, it performs a simple linear search to find the indices of all adjacent objects in the array for which the key is not equal. It executes a single loop, during each iteration of which it verifies if the keys of the current i-th and the adjacent (i+1 )-th objects are not equal. If so, it simply appends the index (i + 1) to the vector std::vector<std::size_t> pv:
#pragma omp parallel for
for (BidirIt _FwdIt = _First + 1; _FwdIt != _Last; _FwdIt++)
if ((comp_key(*_FwdIt, *(_FwdIt - 1)) || (comp_key(*(_FwdIt - 1), *_FwdIt))))
{
omp_set_lock(&lock);
pv.push_back(std::distance(_First, _FwdIt));
omp_unset_lock(&lock);
}
The parallel modification of this algorithm normally requires an extra space, such as O(k), where k - the number of partitions to be sorted. Since, this variant of the algorithm does not incur the data flow dependency, each iteration of the following loop is executed in parallel by its own thread, using #pragma omp parallel for directive construct. Then, the vector of indices pv is sorted using the internal::parallel_sort( ... ) function, to preserve the order of each partition index:
internal::parallel_sort(pv.begin(), pv.end(),
[&](const std::size_t item1, const std::size_t item2) { return item1 < item2; });
In this case, the using of std::vector<std::size_t> is obviously not thread-safe. That's actually why, we need to provide a proper synchronization using omp_set_lock( ... ) and omp_unset_lock( ... ) functions, implemented as a part of the OpenMP library. In case when the two adjacent objects meet the condition, mentioned above, it sets a lock, ensuring that the appending of a specific index to the vector pv is performed by only one thread at a time. After an index has been appended to the vector pv, it unsets the following lock and proceeds with the next parallel iteration of the loop. This technique is just similar to using the critical sections for synchronizing a parallel code execution:
omp_set_lock(&lock);
pv.push_back(std::distance(_First, _FwdIt));
omp_unset_lock(&lock);
Finally, to sort the entire array of objects by its value, it executes another parallel loop, during each iteration of which it fetches a pair of indices from the vector pv. The first index exactly corresponds to the index of the first object in the current partition, while the second one - the index of the last object, respectively. After that, it independently sorts all objects in the array which indices belong to the interval from the first to last by using the same internal::parallel_sort( ... ) function:
#pragma omp parallel for
for (auto _FwdIt = pv.begin(); _FwdIt != pv.end() - 1; _FwdIt++)
internal::parallel_sort(_First + *_FwdIt, _First + *(_FwdIt + 1), comp_vals);
The parallel_stable_sort( ... ) function is invoked as it's shown in the code listed below:
internal::parallel_stable_sort(array_copy.begin(), array_copy.end(),
[&](const gen::ITEM& item1, const gen::ITEM& item2) { return item1.key < item2.key; },
[&](const gen::ITEM& item1, const gen::ITEM& item2) { return item1.value < item2.value; });
Unlike the conventional std::sort or internal::parallel_sort, the following function accepts two lambda-functions as its arguments. The first lambda function is used for sorting an array of objects by the key and the second one to perform the sorting by each object's value, respectively.
Evaluating the Parallel Stable Sort
After delivering this modem parallel code, I've run the series of aggressive evaluation tests. Specifically, I've examined the performance efficiency of the code introduced by using Intel V-Tune Amplifier XE 2019 tool:
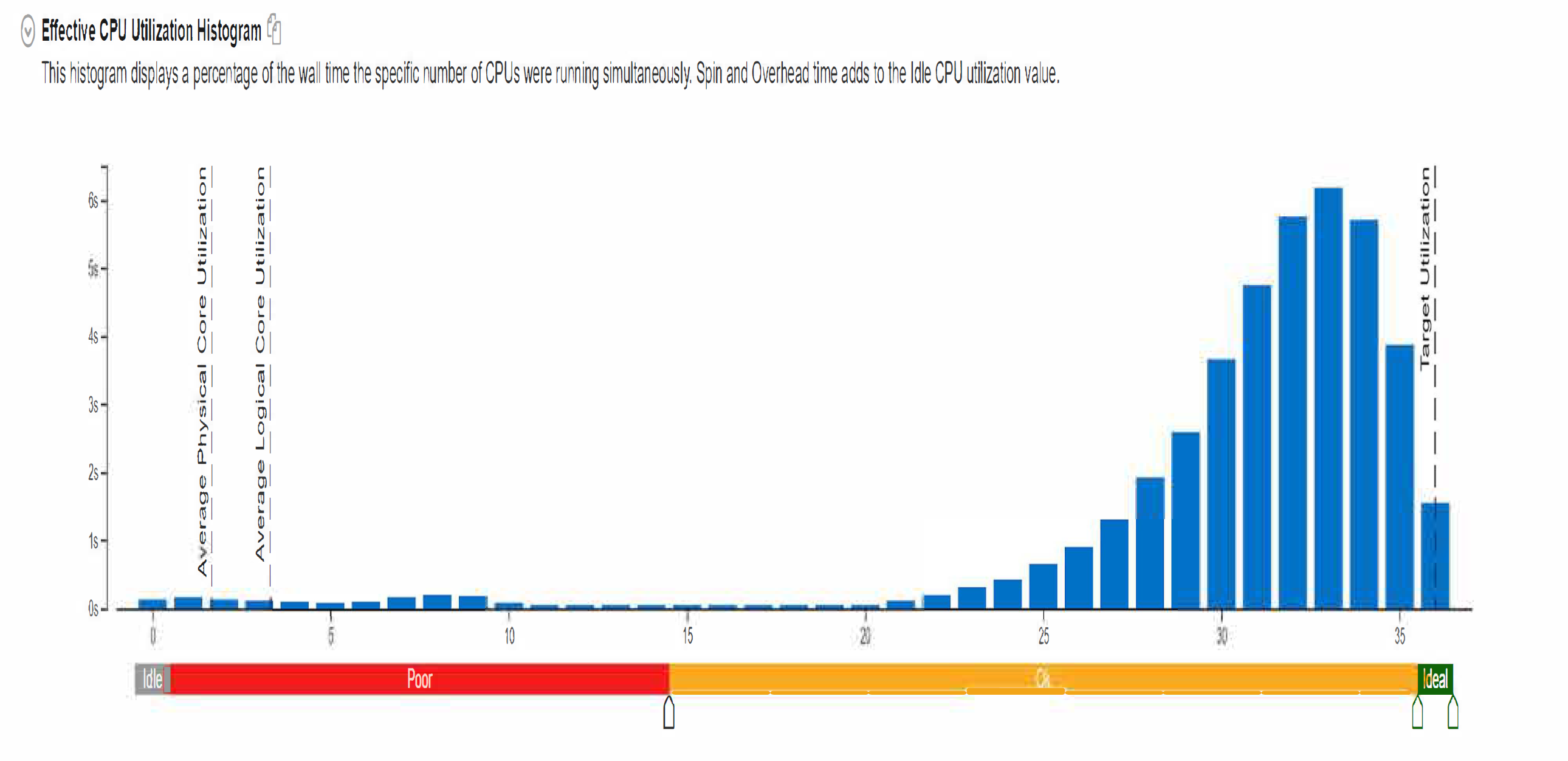
As you can see from the figure above, the following modem code almost perfectly scales when running it in the machines with the symmetric many-core Intel's CPUs, providing the efficiency of performing the parallel "stable" sort, itself. Also, the process of an array partitioning, when run in parallel, does not actually affect the overall performance of the sort, which is still 2x-6x times faster compared to the using of the conventional std::sort( ... ) or the internal::parallel_sort( ... ), discussed in the previous article.
Points of Interest
The fast and efficient parallel sort introduced in this article can be much more faster if we've used the other multithreaded libraries and packages along with OpenMP performance library discussed in this article. For example, in this case, we can also use Intel® Threading Building Blocks to provide performance speed-up of the code introduced in this article. To do this, we can develop a code wrapper based on using tbb:parallel_for template function similar to the implementation of tbb::parallel_sort, and then use the code that performs the parallel fast sorting discussed in this article, instead of using std::sort C++ template function, to provide more performance speed-up of the process of sorting.
History
- 19th November, 2017 - Published final revision of this article

