Amazed by the results of the Vizdoom competition, I decided to implement my own simple Doom AI from scratch. Having no practical knowledge of Deep Learning, I decided to share my journey from an empty Python project to an (at least decently) working Doom AI.
Prerequisites
First of all, I want to cover this topic more from an engineering than a Data Science background, so don’t expect any deep elaborations on the theory behind Neural Networks. A great introduction to this topic is the Artificial Intelligence A-Z course on Udemy. If you prefer books, check out the Hands-On Machine Learning with Scikit-Learn and TensorFlow book on Amazon.
Additionally, feel free to check out the following papers:
Software
To train the Doom agent, we will use the Pytorch library. Since we have to move a lot of data through the Artificial Neural Network (ANN) we are going to create, training on a GPU is mandatory. To set up your PC, check out Tuatinis amazing blog post on setting up an environment for deep learning.
Besides that, you will need Python and the pip package manager as well as Vizdoom to play the game and interact with the ANN. To install Vizdoom, please follow the instructions on their githubpage.
Setting Up the Project
To run pre-configured scenarios for training an AI, Vizdoom provides a bunch of .cfg files we can use right away. To make use of them, I copied the Vizdoom scenarios directory into an empty Python project. Among these scenarios are some fairly easy (Basic, Deadly Corridor) and some more challenging ones (My way home, Deathmatch). We will try to create a generic model so we can easily switch between all these scenarios.
Next, I created a src directory, that will contain all source code for the project. In there, I split up the project into three further parts: doom, which contains our client for Vizdoom and at the same time provides an interface to be used by our AI. Besides that, I created a models directory, which will contain the different Deep learning models, as well as a utils directory for logging, argument-parsing and preprocessing.
In the src directory itself, we will need an empty __init.py__ and a main.py file as a starting point for our project.
If you followed along until this point, you should have a project structure that looks like this:
You can also clone the full repository from doom-ai.
Playing the Game
Before we start creating our AI, let’s get used to the Vizdoom API. To do so, we’ll create a simple client that allows us to play the game ourselves! To keep our interface to the Vizdoom API in one place, I created a doom_trainer.py file inside the doom directory:
import torch
from utils.image_preprocessing import scale
from vizdoom.vizdoom import DoomGame, Mode
def create_actions(scenario):
pass
class DoomTrainer:
def __init__(self, params):
self.game = DoomGame()
self.game.load_config("../scenarios/" + params.scenario + ".cfg")
if params.model == 'human':
self.game.set_mode(Mode.SPECTATOR)
else:
self.actions = create_actions(params.scenario)
def play_human(self):
episodes = 10
for i in range(episodes):
print("Episode #" + str(i + 1))
self.game.new_episode()
while not self.game.is_episode_finished():
self.game.get_state()
self.game.advance_action()
self.game.get_last_action()
self.game.get_last_reward()
def start_game(self):
self.game.init()
def set_seed(self, seed):
self.game.set_seed(seed)
def new_episode(self):
self.game.new_episode()
def get_screen(self):
return torch.from_numpy(scale(self.game.get_state().screen_buffer, 160, 120, True))
def make_action(self, action):
reward = self.game.make_action(self.actions[action])
done = self.game.is_episode_finished()
return reward, done
def num_actions(self):
return len(self.actions)
The create_actions method will later be used to generate all the actions our AI can choose from. To play the game ourselves, we can leave this method empty for now. The DoomTrainer class contains methods to initialize Vizdoom, play as human, create new episodes and to let our AI make actions. I will go into more detail about these methods later. For now, let’s focus on the __init__ and play_human methods:
__init__ takes a params object that contains all information required to train the AI. The first two lines of this method create a new DoomGame instance and load the scenario based on the path from the params object. Then, if we pass the ‘human’ model, we set the game mode to Mode.SPECTATOR, which will hand all control to the game to the player.- The
play_human method sets up a loop that retrieves all user input and forwards it to Vizdoom.
To use these new methods and hook up our future AI with the doom_trainer, let’s add a new game.py file and add a play method to it:
import ...
def play(parameters):
dtype = torch.cuda.FloatTensor
torch.set_default_tensor_type('torch.cuda.FloatTensor')
if parameters.model == 'human':
play_human(parameters)
elif parameters.model == 'a3c':
play_a3c(parameters)
The first two lines will initialize Pytorch to run on our GPU. After that, we check the provided model from the provided parameters and then call the according method. Beside the human model we will implement now, I added a model for A3C. We will look at that later.
With that said, let’s implement the play_human method, so we can finally start interacting with Vizdoom:
def play_human(params):
trainer = DoomTrainer(params)
trainer.start_game()
trainer.play_human()
That’s all the code we need! We instantiate our new class and call its start_game and play_human methods.
We will call this new method from a new main.py file defined in the root directory of the project:
from doom.game import play
from utils.args import parse_arguments
import argparse
def parse_arguments():
parser = argparse.ArgumentParser(description='Doom parameters')
parser.add_argument
("--scenario", type=str, default="deadly_corridor", help="Doom scenario")
parser.add_argument("--lr", type=float, default=0.0001, help="Loss reduction")
parser.add_argument("--gamma", type=float, default=0.099, help="Gamma")
parser.add_argument("--tau", type=float, default=1, help="Tau")
parser.add_argument("--seed", type=float, default=1, help="Seed")
parser.add_argument("--num_processes", type=int, default=6,
help="Number of processes for parallel algorithms")
parser.add_argument("--num_steps", type=int, default=20, help="Steps for training")
parser.add_argument
("--max_episode_length", type=int, default=10000, help="Maximum episode length")
parser.add_argument("--num_actions", type=int, default=7, help="Number of actions")
parser.add_argument
("--model", type=str, default='human', help="Model to use for training the AI")
parser.add_argument("--num_updates", type=int, default=100, help="Number of updates")
game_args, _ = parser.parse_known_args()
return game_args
if __name__ == '__main__':
game_args = parse_arguments()
play(game_args)
Here, we simply get the command line parameters via the parse_arguments method and pass them on to the play method we just created. Since we are playing ourselves, we only have to worry about the scenario and model parameter for now. As you can see, I set the model to “human” and the scenario to “deadly_corridor”.
If you run the main.py file, a screen should open with the deadly_corridor scenario loaded. The goal of this scenario is, to reach the green armor at the end of the corridor. Check out https://cheesyprogrammer.com/wp-content/uploads/2018/02/deadly_corridor_human.mp4 to see one of my attempts at solving this challenge.
If you want to challenge yourself, go to the scenarios directory and open the deadly_corridor.cfg file. In there, set the doom_skill = 5 for the most deadly enemies!!
Image Preprocessing
Before we can start to work on our AI, we have to consider the huge amount of image data we have to process. For each frame, we have to analyze three matrices (one for each RGB color) of the size 320×240 / 640×480 / … depending on the size of the screen. We can divide the amount of data by 3, simply by turning the input image into a gray-scale image. While we will lose some details with this method, I find it a good compromise between performance and effectiveness of the AI.
In addition to that, we can reduce the input size even further by scaling down the input images. For example, we can turn one 320×240 grayscale image into a 160×120 grayscale image and reduce the input size by 50%. Of course, this also results in some loss of data, so we have to carefully evaluate how practical this approach is.
Below, you can see the result of applying both of these “optimizations”. First, the colors are combined into one grayscale-image, then the size is reduced by 50%.
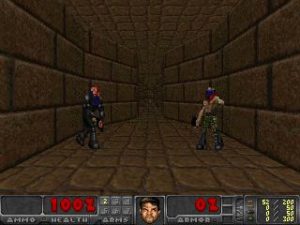
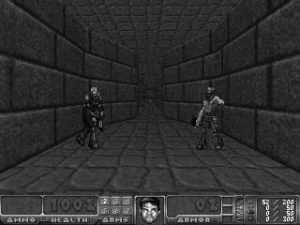
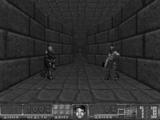
Using the imresize function from the scipy.misc package, implementing these transformations is very straightforward. In the utils directory, I created an image_preprocessing.py file that contains a single scale method:
from scipy.misc import imresize
import numpy as np
def scale(screen_buffer, width=None, height=None, gray=False):
processed_buffer = screen_buffer
if gray:
processed_buffer = screen_buffer.astype(np.float32).mean(axis=0)
if width is not None and height is not None:
return imresize(processed_buffer, (height, width))
return processed_buffer
It takes an input screen_buffer, the target width and height and a gray flag as parameters and applies the transformations accordingly.
As you have already seen above, we will use this method in the get_screen method of the DoomTrainer class:
...
def get_screen(self):
return torch.from_numpy(scale(self.game.get_state().screen_buffer, 160, 120, True))
Creating the AI
With that out of the way, it’s time to create our actual AI! There are a lot of different approaches to train an efficient AI using Reinforcement learning. Since it is one of the most recent and effective ones, I decided to start with the A3C algorithm. This utilizes the power of Deep Neural Networks (DNN) by running multiple agents for training at the same time. Each agent then shares its results with the other agents. Since every agent makes different decisions, this approach reduces the chance for the AI to run into a local minimum. Additionally, it drastically reduces the average training time required to perform decently well at any given task.
Besides the training agents, we will have one test agent that we use for evaluation and won’t touch the model’s parameters. We will heavily base our implementation on the pytorch-a3c project on GitHub, which is based on the Asynchronous Methods for Deep Reinforcement Learning research paper.
To implement the A3C model, inside the models directory, we will create four files:
- A3C.py
- optimizers.py
- test.py
- train.py
Let’s start with the A3c.py file:
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.set_default_tensor_type('torch.cuda.FloatTensor')
def normalized_columns_initializer(weights, std=1.0):
out = torch.randn(weights.size())
out *= std / torch.sqrt(out.pow(2).sum(1, True).expand_as(out))
return out
def init_weights(m):
class_name = m.__class__.__name__
if class_name.find('Conv') != -1:
weight_shape = list(m.weight.data.size())
fan_in = np.prod(weight_shape[1:4])
fan_out = np.prod(weight_shape[2:4]) * weight_shape[0]
w_bound = np.sqrt(6. / (fan_in + fan_out))
m.weight.data.uniform_(-w_bound, w_bound)
m.bias.data.fill_(0)
elif class_name.find('Linear') != -1:
weight_shape = list(m.weight.data.size())
fan_in = weight_shape[1]
fan_out = weight_shape[0]
w_bound = np.sqrt(6. / (fan_in + fan_out))
m.weight.data.uniform_(-w_bound, w_bound)
m.bias.data.fill_(0)
class A3C(torch.nn.Module):
def __init__(self, num_inputs, num_actions):
super(A3C, self).__init__()
self.conv1 = nn.Conv2d(num_inputs, 64, 8, stride=2, padding=1)
self.conv2 = nn.Conv2d(64, 64, 5, stride=2, padding=1)
self.conv3 = nn.Conv2d(64, 64, 3, stride=2, padding=1)
self.conv4 = nn.Conv2d(64, 32, 3, stride=2, padding=1)
self.lstm_size = 256
self.lstm = nn.LSTMCell(9600, self.lstm_size)
num_outputs = num_actions
self.critic_linear = nn.Linear(self.lstm_size, 1)
self.actor_linear = nn.Linear(self.lstm_size, num_outputs)
self.apply(init_weights)
self.actor_linear.weight.data = normalized_columns_initializer
(self.actor_linear.weight.data, 0.01)
self.actor_linear.bias.data.fill_(0)
self.critic_linear.weight.data = normalized_columns_initializer
(self.critic_linear.weight.data, 1.0)
self.critic_linear.bias.data.fill_(0)
self.lstm.bias_ih.data.fill_(0)
self.lstm.bias_hh.data.fill_(0)
self.train()
def forward(self, inputs):
inputs, (hx, cx) = inputs
x = F.elu(self.conv1(inputs.unsqueeze(0)))
x = F.elu(self.conv2(x))
x = F.elu(self.conv3(x))
x = F.elu(self.conv4(x))
x = x.view(x.size(0), -1)
hx, cx = self.lstm(x, (hx, cx))
x = hx
return self.critic_linear(x), self.actor_linear(x), (hx, cx)
This implementation is pretty much the same as in the one in the mentioned GitHub repository. The only differences are the parameters of the convolution layers, which yielded better results for me in the tested scenarios. As you can see, we are also using an LSTM layer, so our AI can memorize previous states and choose the optimal next action based on that.
The optimizers.py is identical to the one from the GitHub, repo, so I won’t go into any details about it here.
Next, let’s look at the train.py file:
import ...
def ensure_shared_grads(model, shared_model):
for param, shared_param in zip(model.parameters(), shared_model.parameters()):
if shared_param.grad is not None:
return
shared_param._grad = param.grad
def train(rank, params, shared_model, optimizer):
torch.manual_seed(params.seed + rank)
trainer = DoomTrainer(params)
trainer.set_seed(params.seed + rank)
trainer.start_game()
model = A3C(1, trainer.num_actions()).cuda()
trainer.new_episode()
state = trainer.get_screen()
done = True
episode_length = 0
while True:
episode_length += 1
model.load_state_dict(shared_model.state_dict())
if done:
cx = Variable(torch.zeros(1, 256)).cuda()
hx = Variable(torch.zeros(1, 256)).cuda()
else:
cx = Variable(cx.data).cuda()
hx = Variable(hx.data).cuda()
values = []
log_probs = []
rewards = []
entropies = []
for step in range(params.num_steps):
value, action_values, (hx, cx) = model((Variable(state.unsqueeze(0)).cuda(), (hx, cx)))
prob = F.softmax(action_values)
log_prob = F.log_softmax(action_values)
entropy = -(log_prob * prob).sum(1)
entropies.append(entropy)
action = prob.multinomial().data
log_prob = log_prob.gather(1, Variable(action))
values.append(value)
log_probs.append(log_prob)
reward, is_done = trainer.make_action(action[0][0])
done = is_done or episode_length >= params.max_episode_length
reward = max(min(reward, 1), -1)
if done:
episode_length = 0
trainer.new_episode()
state = trainer.get_screen()
rewards.append(reward)
if done:
break
R = torch.zeros(1, 1)
if not done:
value, _, _ = model((Variable(state.unsqueeze(0)).cuda(), (hx, cx)))
R = value.data
values.append(Variable(R))
policy_loss = 0
value_loss = 0
R = Variable(R)
gae = torch.zeros(1, 1)
for i in reversed(range(len(rewards))):
R = params.gamma * R + rewards[i]
advantage = R - values[i]
value_loss = value_loss + 0.5 * advantage.pow(2)
TD = rewards[i] + params.gamma * values[i + 1].data - values[i].data
gae = gae * params.gamma * params.tau + TD
policy_loss = policy_loss - log_probs[i] * Variable(gae) - 0.01 * entropies[i]
optimizer.zero_grad()
(policy_loss + 0.5 * value_loss).backward()
torch.nn.utils.clip_grad_norm(model.parameters(), 40)
ensure_shared_grads(model, shared_model)
optimizer.step()
Here, I had to replace all the calls to the envs / Atari API with our DoomTrainer class. I also added .cuda() to all torch variables. This ensures that our AI will run on the GPU instead of the CPU. The key part of this method is the inner for loop, which reads the hidden state from the LSTM layer and puts it into our model (together with the input screen received from the DoomTrainer class). The remaining lines are used to backpropagate through the DNN, calculate the loss and update the DNN parameters using the optimizer. Additionally, we update the shared state for the other agents running at the same time.
To tell the agent to make a particular action, we use the following code:
reward, is_done = trainer.make_action(action[0][0])
In our DoomTrainer class, this method is implemented like this:
def make_action(self, action):
reward = self.game.make_action(self.actions[action])
done = self.game.is_episode_finished()
return reward, done
To fill the self.actions array, we use the create_actions method, which we left out earlier:
def create_actions(scenario):
if scenario == 'basic':
move_left = [1, 0, 0]
move_right = [0, 1, 0]
shoot = [0, 0, 1]
return [move_left, move_right, shoot]
if scenario == 'deadly_corridor':
move_left = [1, 0, 0, 0, 0, 0, 0]
move_right = [0, 1, 0, 0, 0, 0, 0]
shoot = [0, 0, 1, 0, 0, 0 ,0]
back = [0, 0, 0, 1, 0, 0 ,0]
forward = [0, 0, 0, 0, 1, 0, 0]
turn_left = [0, 0, 0, 0, 0, 1, 0]
turn_right = [0, 0, 0, 0, 0, 0, 1]
return [move_left, move_right, shoot, back, forward, turn_left, turn_right]
if scenario == 'my_way_home':
turn_left = [1, 0, 0, 0, 0]
turn_right = [0, 1, 0, 0, 0]
forward = [0, 0, 1, 0, 0]
move_left = [0, 0, 0, 1, 0]
move_right = [0, 0, 0, 0, 1]
return [turn_left, turn_right, forward, move_left, move_right]
if scenario == 'defend_the_center':
turn_left = [1, 0, 0]
turn_right = [0, 1, 0]
shoot = [0, 0, 1]
return [turn_left, turn_right, shoot]
As you can see, we simply check the scenario passed by the caller and return an array of actions based on that. Passing this array to Vizdoom will trigger our agent to take that particular action and the game will continue on with the next frame. Back to the train method, we can check if the episode is done (the agent won or died) and based on that, either create a new episode or continue with the next screen:
if done:
episode_length = 0
trainer.new_episode()
state = trainer.get_screen()
rewards.append(reward)
if done:
break
With the hardest part covered, let’s take a look at the test.py file:
import ...
torch.set_default_tensor_type('torch.cuda.FloatTensor')
def test(rank, params, shared_model):
torch.manual_seed(params.seed + rank)
trainer = DoomTrainer(params)
trainer.set_seed(params.seed + rank)
trainer.start_game()
model = A3C(1, trainer.num_actions()).cuda()
model.eval()
trainer.new_episode()
state = trainer.get_screen()
reward_sum = 0
done = True
start_time = time.time()
episode_length = 0
while True:
episode_length += 1
if done:
model.load_state_dict(shared_model.state_dict())
cx = Variable(torch.zeros(1, 256), volatile=True).cuda()
hx = Variable(torch.zeros(1, 256), volatile=True).cuda()
else:
cx = Variable(cx.data, volatile=True).cuda()
hx = Variable(hx.data, volatile=True).cuda()
value, action_value, (hx, cx) = model((Variable(state.unsqueeze(0),
volatile=True).cuda(), (hx, cx)))
prob = F.softmax(action_value)
action = prob.max(1)[1].cpu().data.numpy()
reward, done = trainer.make_action(action[0])
reward_sum += reward
if done:
print("Time {}, episode reward {}, episode length {}".format
(time.strftime("%Hh %Mm %Ss", time.gmtime(time.time() - start_time)),
reward_sum, episode_length))
log_reward(reward_sum)
reward_sum = 0
episode_length = 0
actions.clear()
trainer.new_episode()
time.sleep(15)
state = trainer.get_screen()
Again, we instantiate our DoomTrainer and model classes and hook them up. Then, in the while loop, we run through our model and get the reward after each taken action. If we reach the if done: case, this means that our AI either succeeded, ran out of time or died from enemy fire. In that case, we will log the reward of that episode as well as the episode length, reset all variables and finally start to continue on with the next screen. The time.sleep(15) is used to allow the training agents to catch up.
Now, the last step before we can watch our AI learn to play Doom is to add a method in game.py to set up the training and test processes and run them asynchronously. To do so, I created the following play_a3c method:
def play_a3c(params):
trainer = DoomTrainer(params)
shared_model = A3C(1, trainer.num_actions()).cuda()
shared_model.share_memory()
optimizer = optimizers.SharedAdam(shared_model.parameters(), lr=params.lr)
optimizer.share_memory()
processes = []
process = mp.Process(target=test_a3c, args=(params.num_processes, params, shared_model))
process.start()
for rank in range(0, params.num_processes):
process = mp.Process(target=train_a3c, args=(rank, params, shared_model, optimizer))
process.start()
processes.append(process)
for p in processes:
p.join()
Here, we first create a new DoomTrainer instance and use it to create the A3C model that we will share the processes. Then we instantiate our shared optimizer which will be used for training the AI agents.
After that, we create one process that will run the test method and several others that will run the training method. For me, setting params.num_processes to 6 worked very well, anything more and I ran out of GPU memory.
Running the AI
If we have done everything right, we should now be able to finally run our AI agent! Before you start the program, make sure to set the screen resolution in the deadly_corridor.cfg file to 320×240:
screen_resolution = RES_320X240
Otherwise, we have to recalculate the input size of the LSTM layer. Set the input parameters so that model == “AC3” and scenario == “deadly_corridor”. You can leave the other values as they are for now. If you run the main.py file, you should see 7 windows popping up (they are on top of each other, so to see all of them, simply draw them apart). Six of them contain training agents, and one contains the test agent that also prints the reward of each episode. Take a look at https://cheesyprogrammer.com/wp-content/uploads/2018/02/a3c.mp4 to watch my AI learn.
On the left side, you see the six training agents and on the right side, the testing agent. Since it sleeps for 15s after each run, it is standing still most of the time. You can also see that, while all training agents behave a bit differently, the AI quickly figures out that the best way to reach the green armor is to run straight towards it. This works only because I set the difficulty to 4. If we set it to 5, the enemies will kill our agent before he reaches the armor, so it has to work much harder in that case. With the current approach, it didn’t manage to reach the goal even after 12 hours of training.
Results
While this model performs well for the easier Vizdoom challenges, it didn’t produce any decent results for the more advanced scenarios. This shows that there is a lot of potential for improvement and parameter tuning. It also shows that while frameworks like Pytorch make it very easy to train your own AI, you still need a lot of background knowledge and a deep understanding of Deep Learning to create efficient AIs for complex problems.
Further Resources
I hope I got you interested in the topic of Deep Learning and Reinforcement Learning. To dive deeper into both theoretical and technical applications of Machine Learning and Deep Learning, check out the following Udemy courses:
I also highly recommend the book Hands-On Machine Learning with Scikit-Learn and TensorFlow.
That’s it, I really hope you enjoyed this tutorial, let me know if you have any feedback, problems or questions!

