Introduction
This article doesn't give you an introduction to deep learning. You are supposed to know the basis of deep learning and a little of Python coding. The main objective of this article is to introduce you to the basis of Keras framework and use with another known library to make a quick experiment and take the first conclusions.
Background
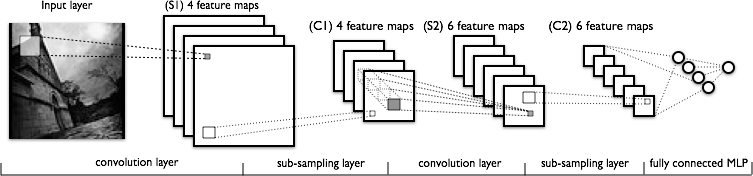
In the last article, we trained a simple neural net. This time, we will train a Convolutional Neural Network and compare it with the previous results.
All the experiments are done with educational purposes and the train process will be very quick and the results won't be perfect.
Using the Code
We want to train a simple Convolutional Neural Net. In the following link, you can view an introduction of what is a ConvNet compared to a regular or traditional neural net.
Keras gives all the tools for making a ConvNet easily. All the tools used to see the quality of the model are the same we used in the last article.
First Step: Load Libraries
Like the previous article, we need to load all the libraries we need: numpy, TensorFlow, Keras, Scikit Learn, Pandas... and more.
import numpy as np
from scipy import misc
from PIL import Image
import glob
import matplotlib.pyplot as plt
import scipy.misc
from matplotlib.pyplot import imshow
%matplotlib inline
from IPython.display import SVG
import cv2
import seaborn as sn
import pandas as pd
import pickle
from keras import layers
from keras.layers import Flatten, Input, Add, Dense, Activation, ZeroPadding2D,
BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D, Dropout
from keras.models import Sequential, Model, load_model
from keras.preprocessing import image
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.applications.imagenet_utils import decode_predictions
from keras.utils import layer_utils, np_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from keras.initializers import glorot_uniform
from keras import losses
import keras.backend as K
from keras.callbacks import ModelCheckpoint
from sklearn.metrics import confusion_matrix, classification_report
import tensorflow as tf
Set Up Datasets
We use the CIFAR-100 dataset. This dataset has been used for a long time. It has 600 images per class with a total of 100 classes. It has 500 images for training and 100 images for validation per each class. Every one of the 100 classes are grouped in 20 superclasses. Each image has one "fine" label (the main class) and a "coarse" label (its superclass).
Keras framework has the module for direct download:
from keras.datasets import cifar100
(x_train_original, y_train_original),
(x_test_original, y_test_original) = cifar100.load_data(label_mode='fine')
Actually, we have downloaded the train and test datasets. x_train_original and x_test_original have the train and test images respectively, whereas y_train_original and y_test_original have the labels.
Let's see the y_train_original:
array([[19], [29], [ 0], ..., [ 3], [ 7], [73]])
As you can see, it is an array where each number corresponds to a label. Then, the first thing we have to do is convert these arrays to the one-hot-encoding version (see wikipedia).
y_train = np_utils.to_categorical(y_train_original, 100)
y_test = np_utils.to_categorical(y_test_original, 100)
OK, now, let's see the train dataset (x_train_original):
array([[[255, 255, 255],
[255, 255, 255],
[255, 255, 255],
...,
[195, 205, 193],
[212, 224, 204],
[182, 194, 167]],
[[255, 255, 255],
[254, 254, 254],
[254, 254, 254],
...,
[170, 176, 150],
[161, 168, 130],
[146, 154, 113]],
[[255, 255, 255],
[254, 254, 254],
[255, 255, 255],
...,
[189, 199, 169],
[166, 178, 130],
[121, 133, 87]],
...,
[[148, 185, 79],
[142, 182, 57],
[140, 179, 60],
...,
[ 30, 17, 1],
[ 65, 62, 15],
[ 76, 77, 20]],
[[122, 157, 66],
[120, 155, 58],
[126, 160, 71],
...,
[ 22, 16, 3],
[ 97, 112, 56],
[141, 161, 87]],
...and more...
], dtype=uint8)
This dataset represents the 3 channels of 256 RGB pixels. Want to see it?
imgplot = plt.imshow(x_train_original[3]) plt.show()

Next, we have to normalize the images. That is, divide each element of the dataset by the total pixel number: 255. Once this is done, the array will have values between 0 and 1.
x_train = x_train_original/255
x_test = x_test_original/255
Setting Up the Training Environment
Before training, we have to set two parameters in Keras environment. First, we have to say Keras where in the array are the channels. In an image array, channels can be in the last index or in the first. This is known channels first or channels last. In our exercise, we will set to channel last.
K.set_image_data_format('channels_last')
And the second thing is to say in which phase Keras is. In our case, learning phase.
K.set_learning_phase(1)
In the next articles, we will not show these two sections because they are the same in all the articles.
Training the ConvNet
In this step, we will define the ConvNet model.
def create_simple_cnn():
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), input_shape=(32, 32, 3), activation='relu'))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(Conv2D(256, kernel_size=(3, 3), activation='relu'))
model.add(Conv2D(512, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(1024, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(100, activation='softmax'))
return model
As you can see in the code, Conv2D line introduces a convolutional layer and the MaxPooling line, the pooling layer (In this net, we have used max-pooling, but we could have used average pooling). For each convolutional layer, we use ReLu activation function. Another important instruction is Dropout, with that, we make a small regularization.
Once the model is defined, we compile setting the optimization function, the loss function and the metrics. As previous experiment, we use stochactic gradient descent, categorical cross entropy and, for the metrics, accuracy and mse (Mean Squared Errors).
scnn_model = create_simple_cnn()
scnn_model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['acc', 'mse'])
Ok, let's see the summary for this model.
scnn_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param
=================================================================
conv2d_7 (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
conv2d_8 (Conv2D) (None, 28, 28, 64) 18496
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 12, 12, 128) 73856
_________________________________________________________________
conv2d_10 (Conv2D) (None, 10, 10, 256) 295168
_________________________________________________________________
conv2d_11 (Conv2D) (None, 8, 8, 512) 1180160
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 4, 4, 512) 0
_________________________________________________________________
conv2d_12 (Conv2D) (None, 2, 2, 1024) 4719616
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 1, 1, 1024) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 1024) 0
_________________________________________________________________
dense_3 (Dense) (None, 500) 512500
_________________________________________________________________
dropout_4 (Dropout) (None, 500) 0
_________________________________________________________________
dense_4 (Dense) (None, 100) 50100
=================================================================
Total params: 6,850,792
Trainable params: 6,850,792
Non-trainable params: 0
_________________________________________________________________
We can see the number of params have doubled. Despite the double number of params, if we could use a regular network, the real number of params should be higher. With the convolution step, the net will extract the features of the images.
Then, the next step is to train the model.
scnn = scnn_model.fit(x=x_train, y=y_train, batch_size=32, epochs=10,
verbose=1, validation_data=(x_test, y_test), shuffle=True)
We will train this model in the same way as the last experiment. We will use batches of 32 (for memory reduction) and take 10 epochs. Results are stored in the scnn variable. As you can see, the instructions are the same.
Train on 50000 samples, validate on 10000 samples
Epoch 1/10
50000/50000 [==============================] - 59s 1ms/step - loss: 4.5980
- acc: 0.0136 - mean_squared_error: 0.0099 - val_loss: 4.5637 - val_acc: 0.0233
- val_mean_squared_error: 0.0099
Epoch 2/10
50000/50000 [==============================] - 58s 1ms/step - loss: 4.4183
- acc: 0.0302 - mean_squared_error: 0.0099 - val_loss: 4.3002 - val_acc: 0.0372
- val_mean_squared_error: 0.0098
Epoch 3/10
50000/50000 [==============================] - 58s 1ms/step - loss: 4.2146
- acc: 0.0549 - mean_squared_error: 0.0098 - val_loss: 4.1151 - val_acc: 0.0745
- val_mean_squared_error: 0.0097
Epoch 4/10
50000/50000 [==============================] - 58s 1ms/step - loss: 3.9989
- acc: 0.0889 - mean_squared_error: 0.0097 - val_loss: 3.9709 - val_acc: 0.0922
- val_mean_squared_error: 0.0096
Epoch 5/10
50000/50000 [==============================] - 58s 1ms/step - loss: 3.8207
- acc: 0.1175 - mean_squared_error: 0.0095 - val_loss: 3.8121 - val_acc: 0.1172
- val_mean_squared_error: 0.0095
Epoch 6/10
50000/50000 [==============================] - 58s 1ms/step - loss: 3.6638
- acc: 0.1444 - mean_squared_error: 0.0094 - val_loss: 3.6191 - val_acc: 0.1620
- val_mean_squared_error: 0.0093
Epoch 7/10
50000/50000 [==============================] - 58s 1ms/step - loss: 3.5202
- acc: 0.1695 - mean_squared_error: 0.0093 - val_loss: 3.5624 - val_acc: 0.1631
- val_mean_squared_error: 0.0093
Epoch 8/10
50000/50000 [==============================] - 58s 1ms/step - loss: 3.3970
- acc: 0.1940 - mean_squared_error: 0.0091 - val_loss: 3.5031 - val_acc: 0.1777
- val_mean_squared_error: 0.0092
Epoch 9/10
50000/50000 [==============================] - 58s 1ms/step - loss: 3.2684
- acc: 0.2160 - mean_squared_error: 0.0090 - val_loss: 3.3561 - val_acc: 0.2061
- val_mean_squared_error: 0.0090
Epoch 10/10
50000/50000 [==============================] - 58s 1ms/step - loss: 3.1532
- acc: 0.2383 - mean_squared_error: 0.0088 - val_loss: 3.2669 - val_acc: 0.2183
- val_mean_squared_error: 0.0089
Let's see the metrics for the train and test results graphically (using matplotlib library, of course).
plt.figure(0)
plt.plot(scnn.history['acc'],'r')
plt.plot(scnn.history['val_acc'],'g')
plt.xticks(np.arange(0, 11, 2.0))
plt.rcParams['figure.figsize'] = (8, 6)
plt.xlabel("Num of Epochs")
plt.ylabel("Accuracy")
plt.title("Training Accuracy vs Validation Accuracy")
plt.legend(['train','validation'])
plt.figure(1)
plt.plot(scnn.history['loss'],'r')
plt.plot(scnn.history['val_loss'],'g')
plt.xticks(np.arange(0, 11, 2.0))
plt.rcParams['figure.figsize'] = (8, 6)
plt.xlabel("Num of Epochs")
plt.ylabel("Loss")
plt.title("Training Loss vs Validation Loss")
plt.legend(['train','validation'])
plt.show()
In this case, the generalization is better than the regular network because, unlike 4% of the simple network, it has a 2%, which is not also a good result.
Confusion Matrix
Once we have trained our model, we want to see another metrics before taking any conclusion of the usability of the model we have been created. For this, we will create the confusion matrix and, from that, we will see the precision, recall y F1-score metrics (see wikipedia).
To create the confusion matrix, we need to make the predictions over the test set and then, we can create the confusion matrix and show that metrics.
scnn_pred = scnn_model.predict(x_test, batch_size=32, verbose=1)
scnn_predicted = np.argmax(scnn_pred, axis=1)
As we did in the previous chapter, each higher value of the array of predictions will be the real prediction. Really, the usual way is to take a bias value to discriminate if a prediction value can be positive.
The Scikit Learn library has the methods to make the confusion matrix.
scnn_cm = confusion_matrix(np.argmax(y_test, axis=1), scnn_predicted)
scnn_df_cm = pd.DataFrame(scnn_cm, range(100), range(100))
plt.figure(figsize = (20,14))
sn.set(font_scale=1.4)
sn.heatmap(scnn_df_cm, annot=True, annot_kws={"size": 12})
plt.show()
And the next step, show the metrics.
scnn_report = classification_report(np.argmax(y_test, axis=1), scnn_predicted)
print(scnn_report)
precision recall f1-score support
0 0.40 0.49 0.44 100
1 0.36 0.20 0.26 100
2 0.19 0.24 0.21 100
3 0.12 0.07 0.09 100
4 0.11 0.01 0.02 100
5 0.12 0.13 0.12 100
6 0.25 0.19 0.22 100
7 0.28 0.17 0.21 100
8 0.18 0.24 0.20 100
9 0.25 0.35 0.29 100
10 0.00 0.00 0.00 100
11 0.13 0.15 0.14 100
12 0.24 0.24 0.24 100
13 0.24 0.15 0.18 100
14 0.18 0.03 0.05 100
15 0.12 0.20 0.15 100
16 0.29 0.21 0.24 100
17 0.23 0.57 0.33 100
18 0.20 0.31 0.25 100
19 0.11 0.05 0.07 100
20 0.41 0.40 0.41 100
21 0.30 0.24 0.27 100
22 0.16 0.13 0.14 100
23 0.37 0.38 0.37 100
24 0.31 0.49 0.38 100
25 0.16 0.11 0.13 100
26 0.18 0.09 0.12 100
27 0.14 0.20 0.17 100
28 0.22 0.24 0.23 100
29 0.20 0.26 0.22 100
30 0.35 0.19 0.25 100
31 0.09 0.04 0.06 100
32 0.24 0.19 0.21 100
33 0.24 0.16 0.19 100
34 0.20 0.15 0.17 100
35 0.12 0.14 0.13 100
36 0.16 0.37 0.22 100
37 0.13 0.14 0.14 100
38 0.05 0.04 0.04 100
39 0.19 0.10 0.13 100
40 0.12 0.11 0.11 100
41 0.35 0.55 0.43 100
42 0.10 0.14 0.12 100
43 0.18 0.25 0.21 100
44 0.17 0.07 0.10 100
45 0.50 0.03 0.06 100
46 0.18 0.12 0.14 100
47 0.32 0.40 0.35 100
48 0.38 0.35 0.36 100
49 0.26 0.18 0.21 100
50 0.05 0.05 0.05 100
51 0.16 0.14 0.15 100
52 0.65 0.40 0.49 100
53 0.31 0.56 0.40 100
54 0.28 0.31 0.29 100
55 0.08 0.01 0.02 100
56 0.30 0.28 0.29 100
57 0.16 0.33 0.22 100
58 0.27 0.13 0.17 100
59 0.15 0.18 0.17 100
60 0.61 0.68 0.64 100
61 0.11 0.43 0.18 100
62 0.49 0.21 0.29 100
63 0.16 0.22 0.19 100
64 0.11 0.22 0.15 100
65 0.04 0.02 0.03 100
66 0.05 0.05 0.05 100
67 0.22 0.17 0.19 100
68 0.48 0.46 0.47 100
69 0.29 0.36 0.32 100
70 0.26 0.34 0.29 100
71 0.50 0.47 0.48 100
72 0.19 0.03 0.05 100
73 0.38 0.29 0.33 100
74 0.13 0.14 0.13 100
75 0.37 0.24 0.29 100
76 0.36 0.50 0.42 100
77 0.12 0.13 0.12 100
78 0.10 0.06 0.08 100
79 0.10 0.16 0.12 100
80 0.03 0.03 0.03 100
81 0.29 0.13 0.18 100
82 0.62 0.59 0.61 100
83 0.22 0.20 0.21 100
84 0.06 0.06 0.06 100
85 0.22 0.23 0.23 100
86 0.20 0.35 0.25 100
87 0.12 0.11 0.12 100
88 0.13 0.23 0.17 100
89 0.18 0.30 0.22 100
90 0.13 0.03 0.05 100
91 0.41 0.35 0.38 100
92 0.16 0.10 0.12 100
93 0.19 0.09 0.12 100
94 0.27 0.58 0.37 100
95 0.38 0.27 0.31 100
96 0.17 0.18 0.17 100
97 0.18 0.19 0.19 100
98 0.07 0.04 0.05 100
99 0.12 0.06 0.08 100
avg / total 0.22 0.22 0.21 10000
Well, not much different from the previous one. Let's see the ROC curve.
ROC Curve
The ROC curve is used by binary clasifiers because is a good tool to see the true positives rate versus false positives. Following lines show the code for the multiclass classification ROC curve. This code is from DloLogy, but you can go to the Scikit Learn documentation page.
from sklearn.datasets import make_classification
from sklearn.preprocessing import label_binarize
from scipy import interp
from itertools import cycle
n_classes = 100
from sklearn.metrics import roc_curve, auc
lw = 2
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], scnn_pred[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), scnn_pred.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
plt.figure(1)
plt.plot(fpr["micro"], tpr["micro"],
label='micro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["micro"]),
color='deeppink', linestyle=':', linewidth=4)
plt.plot(fpr["macro"], tpr["macro"],
label='macro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
colors = cycle(['aqua', 'darkorange', 'cornflowerblue'])
for i, color in zip(range(n_classes-97), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=lw,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Some extension of Receiver operating characteristic to multi-class')
plt.legend(loc="lower right")
plt.show()
plt.figure(2)
plt.xlim(0, 0.2)
plt.ylim(0.8, 1)
plt.plot(fpr["micro"], tpr["micro"],
label='micro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["micro"]),
color='deeppink', linestyle=':', linewidth=4)
plt.plot(fpr["macro"], tpr["macro"],
label='macro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
colors = cycle(['aqua', 'darkorange', 'cornflowerblue'])
for i, color in zip(range(3), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=lw,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Some extension of Receiver operating characteristic to multi-class')
plt.legend(loc="lower right")
plt.show()
Not bad. Let's see some prediction results.
imgplot = plt.imshow(x_train_original[0])
plt.show()
print('class for image 1: ' + str(np.argmax(y_test[0])))
print('predicted: ' + str(scnn_predicted[0]))
class for image 1: 49
predicted: 85
Another result.
imgplot = plt.imshow(x_train_original[3])
plt.show()
print('class for image 3: ' + str(np.argmax(y_test[3])))
print('predicted: ' + str(scnn_predicted[3]))
class for image 3: 51
predicted: 51
Then, we will save the train history results to future comparisons.
with open(path_base + '/scnn_history.txt', 'wb') as file_pi:
pickle.dump(scnn.history, file_pi)
Comparisons for the Metrics
The next step is compare the metrics of the previous experiment with this results. We will compare accuracy, loss and mean squared errors for both models (ConvNet and regular net). For this, we need to load the history results saved in previous chapters.
with open(path_base + '/simplenn_history.txt', 'rb') as f:
snn_history = pickle.load(f)
Now, we have the previous results in the snn_history variable. then, compare graphically.
plt.figure(0)
plt.plot(snn_history['val_acc'],'r')
plt.plot(scnn.history['val_acc'],'g')
plt.xticks(np.arange(0, 11, 2.0))
plt.rcParams['figure.figsize'] = (8, 6)
plt.xlabel("Num of Epochs")
plt.ylabel("Accuracy")
plt.title("Simple NN Accuracy vs simple CNN Accuracy")
plt.legend(['simple NN','CNN'])
plt.figure(0)
plt.plot(snn_history['val_loss'],'r')
plt.plot(scnn.history['val_loss'],'g')
plt.xticks(np.arange(0, 11, 2.0))
plt.rcParams['figure.figsize'] = (8, 6)
plt.xlabel("Num of Epochs")
plt.ylabel("Loss")
plt.title("Simple NN Loss vs simple CNN Loss")
plt.legend(['simple NN','CNN'])
plt.figure(0)
plt.plot(snn_history['val_mean_squared_error'],'r')
plt.plot(scnn.history['val_mean_squared_error'],'g')
plt.xticks(np.arange(0, 11, 2.0))
plt.rcParams['figure.figsize'] = (8, 6)
plt.xlabel("Num of Epochs")
plt.ylabel("Mean Squared Error")
plt.title("Simple NN MSE vs simple CNN MSE")
plt.legend(['simple NN','CNN'])
Final Conclusion
Unlike the previous model, the lines don't tend to become horizontal (the slope of the curve continues with a no near to zero value), so it is assumed that it is worthwhile to continue increasing the number of epochs to improve training. The convolutive network has allowed to improve the general accuracy and has generalized a little better than the regular neuronal network.
Points of Interest (but let's not be fooled...)
As everything that glitters is not gold, we have done the training of the model for 20 more epochs (from the already trained). If we see the results of the training, we will see the following:
Train on 50000 samples, validate on 10000 samples
Epoch 1/20
50000/50000 [==============================] - 58s 1ms/step - loss: 3.0416
- acc: 0.2552 - mean_squared_error: 0.0086 - val_loss: 3.2335 - val_acc: 0.2305
- val_mean_squared_error: 0.0089
Epoch 2/20
50000/50000 [==============================] - 58s 1ms/step - loss: 2.9324
- acc: 0.2783 - mean_squared_error: 0.0085 - val_loss: 3.1399 - val_acc: 0.2471
- val_mean_squared_error: 0.0087
Epoch 3/20
50000/50000 [==============================] - 58s 1ms/step - loss: 2.8245
- acc: 0.3031 - mean_squared_error: 0.0083 - val_loss: 3.1052 - val_acc: 0.2639
- val_mean_squared_error: 0.0086
Epoch 4/20
50000/50000 [==============================] - 58s 1ms/step - loss: 2.7177
- acc: 0.3186 - mean_squared_error: 0.0081 - val_loss: 3.0722 - val_acc: 0.2696 - val_mean_squared_error: 0.0086
Epoch 5/20
50000/50000 [==============================] - 58s 1ms/step - loss: 2.6060
- acc: 0.3416 - mean_squared_error: 0.0079 - val_loss: 2.9785 - val_acc: 0.2771 - val_mean_squared_error: 0.0084
Epoch 6/20
50000/50000 [==============================] - 59s 1ms/step - loss: 2.4995
- acc: 0.3613 - mean_squared_error: 0.0077 - val_loss: 3.0285 - val_acc: 0.2828 - val_mean_squared_error: 0.0085
Epoch 7/20
50000/50000 [==============================] - 59s 1ms/step - loss: 2.3825
- acc: 0.3873 - mean_squared_error: 0.0075 - val_loss: 3.0384 - val_acc: 0.2852 - val_mean_squared_error: 0.0085
Epoch 8/20
50000/50000 [==============================] - 59s 1ms/step - loss: 2.2569
- acc: 0.4119 - mean_squared_error: 0.0073 - val_loss: 3.1255 - val_acc: 0.2804 - val_mean_squared_error: 0.0086
Epoch 9/20
50000/50000 [==============================] - 59s 1ms/step - loss: 2.1328
- acc: 0.4352 - mean_squared_error: 0.0070 - val_loss: 3.0136 - val_acc: 0.2948 - val_mean_squared_error: 0.0084
Epoch 10/20
50000/50000 [==============================] - 59s 1ms/step - loss: 2.0036
- acc: 0.4689 - mean_squared_error: 0.0067 - val_loss: 3.0198 - val_acc: 0.2951 - val_mean_squared_error: 0.0085
Epoch 11/20
50000/50000 [==============================] - 59s 1ms/step - loss: 1.8671
- acc: 0.4922 - mean_squared_error: 0.0065 - val_loss: 3.1819 - val_acc: 0.2958 - val_mean_squared_error: 0.0086
Epoch 12/20
50000/50000 [==============================] - 59s 1ms/step - loss: 1.7304
- acc: 0.5227 - mean_squared_error: 0.0061 - val_loss: 3.2325 - val_acc: 0.3062 - val_mean_squared_error: 0.0087
Epoch 13/20
50000/50000 [==============================] - 59s 1ms/step - loss: 1.5885
- acc: 0.5527 - mean_squared_error: 0.0058 - val_loss: 3.2594 - val_acc: 0.3041
- val_mean_squared_error: 0.0087
Epoch 14/20
50000/50000 [==============================] - 59s 1ms/step - loss: 1.4592
- acc: 0.5861 - mean_squared_error: 0.0055 - val_loss: 3.3133 - val_acc: 0.2987
- val_mean_squared_error: 0.0088
Epoch 15/20
50000/50000 [==============================] - 59s 1ms/step - loss: 1.3199
- acc: 0.6170 - mean_squared_error: 0.0051 - val_loss: 3.5305 - val_acc: 0.3004
- val_mean_squared_error: 0.0090
Epoch 16/20
50000/50000 [==============================] - 59s 1ms/step - loss: 1.1907
- acc: 0.6491 - mean_squared_error: 0.0047 - val_loss: 3.6840 - val_acc: 0.3080
- val_mean_squared_error: 0.0091
Epoch 17/20
50000/50000 [==============================] - 59s 1ms/step - loss: 1.0791
- acc: 0.6787 - mean_squared_error: 0.0044 - val_loss: 3.8013 - val_acc: 0.2965
- val_mean_squared_error: 0.0093
Epoch 18/20
50000/50000 [==============================] - 59s 1ms/step - loss: 0.9594
- acc: 0.7100 - mean_squared_error: 0.0040 - val_loss: 3.8901 - val_acc: 0.2967
- val_mean_squared_error: 0.0094
Epoch 19/20
50000/50000 [==============================] - 59s 1ms/step - loss: 0.8585
- acc: 0.7362 - mean_squared_error: 0.0036 - val_loss: 4.0126 - val_acc: 0.2957
- val_mean_squared_error: 0.0095
Epoch 20/20
50000/50000 [==============================] - 59s 1ms/step - loss: 0.7647
- acc: 0.7643 - mean_squared_error: 0.0033 - val_loss: 4.3311 - val_acc: 0.2954
- val_mean_squared_error: 0.0099
What Happened?
If the rate of success has increased with respect to the first 10 epochs, it happens that as the number of trainings increased, it began to generalize less. It can be seen that the loss function in the validation data reaches a minimum when it reaches a value of 3 and, from there, it increases. In the graph of accuracy, it indicates that the algorithm does not improve of a value of 30%. From here, the options are to use methods to regularize or change to a better model.
In the following article, we will present the ResNET Until next time!
History
- 31st May, 2018: Initial version

