Note: Pulled from my tech blog - updating to include images.
Get all the source for this chapter at my public GitHub: https://github.com/raddevus/jsjqts
JavaScript (as we talk about it in this book) runs in the browser. However, to run JavaScript in the browser, it has to be loaded first. JavaScript is loaded by way of the HTML document.
That means the first thing we need to do is get a skeleton HTML document setup.
Here’s a basic HTML5 document.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Your title here</title>
</head>
<body>
Your content here
</body>
</html>
That’s all you need!
DocType
The first line tells the browser’s HTML interpreter (a separate interpreter from the JavaScript interpreter) to expect valid HTML.
Meta Charset
The meta tag sets up the character set that the browser will use so that we don’t run into problems where characters are interpreted differently (like the double-quotes problem I mentioned earlier).
Inline JavaScript
We can write our JavaScript code right inside our HTML and it will run.
To do that, we add two script elements (beginning and ending tags) and then type our JavaScript within those two elements.
For example, within the previous document, we could do something like the following:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Your title here</title>
</head>
<body>
Your content here
<script>
</body>
</html>
You may also see the script tag include the type attribute which explicitly sets the script as being JavaScript:
type="text/javascript"
However, that is not necessary because browsers will assume the code within the script tag is JavaScript.
HTML Loads Inline JavaScript
The challenge of inline JavaScript is that it will not have any knowledge of HTML elements which come after it. That’s because of the way that HTML loads in a browser and when JavaScript runs.
We’ll look at the idea of how the JavaScript loads as we move forward, but first let’s see a small script run.
Here’s the entire code listing including the HTML which you can find in the chpt002_001.htm file:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Your title here</title>
</head>
<body>
<div id="first">
Your content here
</div>
<script>
var el = document.getElementById("first");
el.innerText = "You are a JavaScript superstar!";
</script>
</body>
</html>
If you open that file in a browser, it will look something like the following:
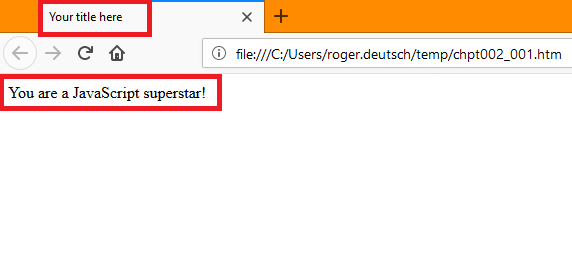
I’ve highlighted (with the red rectangles) the two important parts of the document to focus on.
The first one is the title text that comes from the title element in the head section of the HTML document.
The next one is the text that appears within the document’s body. It is actually the innerText of the div element with the id=”first”.
Here is what happened when you loaded the file in your browser.
- The browser fetches the chpt002_001.htm file and begins loading it.
- When the browser gets to the
script element, it loads the text and allows the internal JavaScript interpreter to take over. - The JavaScript interpreter finds the first valid statement (the first line inside the
script element) and attempts to run it. It calls a method named getElementById() on the document element (the object that represents the HTML document -- the DOM (Document Object Model). - The
getElementById() method takes one parameter which is a string that represents the id value of the element you are searching for. It returns the element as an object and that object is stored in a variable named el. - The element is a document node and contains a built-in property named
innerText which represents the text between the element’s tags: in our case, between <div id=”first”> and </div>. - Finally, the script sets the
innerText to “You are a JavaScript superstar!" - That is what the user sees on the screen in the client area (below the browser menu and navigation bar).
Of course, the HTML document contains different text in the div before the JavaScript runs.
It looks like:
<div id="first">
Your content here
</div>
But the user never sees that text because the document loads so fast and the JavaScript interpreter runs and alters the text before the user ever sees the original text.
However, the JavaScript only alters the div element in memory so there is a way to see the original text of the document.
Browser: View Source
You can view the source (HTML and JavaScript) of any document by right-clicking in the client area and selecting [View Page Source]* from the context menu that appears.
*Note: Some browsers have a menu item which is simply [View Source].

When you choose the menu item, the browser will retrieve the document from the server again but display it as HTML.
Since this is a view of the source the JavaScript interpreter does not run and the <div> element still displays its original content. This view also shows the content of the script tag so your JavaScript code is exposed to everyone. Normally, that isn’t really a problem but it is something to keep in mind since any user could view the JavaScript that you’ve written. It certainly means you’d never keep a secret password or value in your JavaScript.
This view can be very helpful for us as developers so we can take a look at page source and begin to determine why our code may not be working.
This was a very trivial example so the JavaScript is inline with the HTML. However, as soon as your code becomes a bit more complex, you are going to find that to make changes easier, it is far better to split your JavaScript into its own file.
Why Might You Split Out Your JavaScript?
One of the most obvious reasons to split it up is because you may create a script that you want to run on multiple pages. Maybe you have a function named FormatDivElements() and it is used to do work on all the divs on every page in your site. If you put the code inline, then you’ll have to copy the same code to every page that uses it. So if you have five HTML pages that have the FormatDivElements() function, then you’ll have to paste it into each of those files.
Then, what happens if you discover a bug in that function and want to fix it? You have to edit it on every page that uses the code.
But, if you separate out your JavaScript, you can load the JavaScript file in each page and when you need to change it, you’ll only have to edit that one JavaScript file and it will get updated on all the pages that use it.
Separation of Concerns
This idea also allows us to keep our different types (HTML, JavaScript) of code from being dependent upon each other and making things more difficult to change or extend later. You will hear this described as Separation of Concerns (SoC). Separation of Concerns just means keeping different things separate from each other and putting similar things together.
In our case, that means keeping your HTML file as pure HTML (as much as possible) and keeping your JavaScript as pure JavaScript. You will see that this also pertains to CSS (Cascading Style Sheets) which can also be placed inline in the HTML but is far better when it is separated into its own CSS file.
Here’s how easy it is to separate our JavaScript into its own file.
- Create a new file and name it main.js.
- Cut all the source code from the
script element (do not copy the script tags themselves, because JavaScript files do not use those tags). - Paste the code into the new file.
- Save the code in a file named chpt002_002.js in a sub-folder named \js (I’m going to save the HTML as chpt002_002.htm so you can download this example so I’m making the JS file match).
- Add the
src attribute to the script element in the HTML file. - Set the
src=”js\chpt002_002.js” so the HTML file knows where to load the JavaScript from.
Here’s what the HTML file looks like after we remove the code and add the src attribute.
You can see that I also collapsed the script element to one line since it doesn’t contain any code.
Now you can load chpt002_002.htm and the result will look just like chpt002_001.htm.
However, if you load the page and then right click it and [View Page Source], you will see that the JavaScript is no longer inline.
In most (if not all) browsers, you can now click the src link and the browser will load your JavaScript file and display it.
You can also see that I like to add a first line comment in my JS files that tells me which file I’m looking at.
JavaScript Comments
To add a line as a comment, you simply start the JavaScript line with two slash characters (//). Any text after that on the line will be ignored by the JavaScript interpreter as if it does not exist.
The next line will resume code as normal. If you want multiple lines of comments, you should add // to those lines also. There is an accepted multi-line comment but it is warned against because it can cause you problems when you comment out numerous lines of code by accident. The multi-line comment starts with /* and it ends with */ so that anything in between those two tokes will be seen as comments by the JavaScript interpreter.
Chapter Summary
That’s it for this chapter. Now you know the proper way to set up your HTML and JavaScript files. This is how all the code in the rest of our examples will look so it is important that you understand how this all works.
What’s Next?
Now that we have our working process, we can begin a much closer inspection of pure JavaScript. In the next chapter, we’ll take a look at the fundamentals of JavaScript such as data types, statements, control structures (if statements, for loops, etc). These are the nuts and bolts of JavaScript that allow you to build larger apps. In chapters that follow, we’ll look at functions and classes (including points about prototypal inheritance). I’ll also show you some of the commonly used built-in features like JavaScript timers and other features that will help you build apps.
All of this will set the table for you to easily learn jQuery and be able to see the huge benefits that jQuery can bring.
CodeProject

