Introduction
The Map/Reduce type of script is NetSuite's server-side script that can be used to handle substantial number of records. The Map/Reduce type of script is only available in SuiteScript 2.0. When the Map/Reduce script is executed, parallel processing across multiple queues kicks in unless the script was required to use one queue and therefore this type of script can be used for bulk processing or long running background processes.
The Map/Reduce scripting is an implementation of map/reduce paradigm where larger number of records are split into smaller units, smaller units are applied with processing needs and combined at the end for analysis. In this process, needed records are first identified for processing. This is done via searching in NetSuite either using saved search or defined search within the script. The searched records are structured into key/value pairs where each key-value pair is read in parallel and passed on to next step for processing. The steps are analogous to single reusable function on a processing pipeline. The pipeline in NetSuite is composed of five distinct stages that are executed in the order. The stages are basically functions that are invoked within a stage.
Each stage has own governance limits. When the governance limit is reached, the script automatically yields i.e., re-scheduled or re-reused. The yield limit can also be set by ‘Yield after minutes’ on deployment record for this script. Thus, the script yields either when the limit has reached or runs out of the time-limit. Because of automatic yielding, user does not need to worry much about governance limits and focus on efficient logic. Stages, description and the governance limit for each of the stages of Map/Reduce Script is described in Table 1.
Table 1. Governance Limit in the Map/Reduce SuiteScript 2.0
| Stage/Function | Description | Governance (Unit) |
| 1. getInputData()
| This is the first stage in which data is acquired. In this stage, search can be performed, records are read, and data can be packaged into data structure. For example, the function can return a search of NetSuite records by running a search. The key/value pairs would be the results of search. | 10,000 |
| 2. map()
| Passing of data into this stage happens automatically. In this stage, grouping of data occurs. Each key/value pair of data from getInputData() is passed per function invocation. If the script uses reduce function, then output data is sent to shuffle and then to reduce function. Otherwise, the output of map is sent directly to summarize stage, if present. Any pre-processing of data can happen at this stage. For example, we may like to edit some records as part of processing the key: value pair. | 1000 per call (10000 per Task |
| 3. shuffle()
| This function groups the values based on the keys. This function is provided by default. In this stage, the system sorts through any key/value pairs that were sent to the reduce stage, if defined. If map function was not used, then this stage gets data from getInputData stage. For example, suppose there are 12 key/value pairs coming from search and each key represents an item record, and each value represent the pricing data for that item. For simplicity, let's assume that there are only three items and one item has 3 pricing data, another has 5 pricing data and the last one has 4 pricing data returned by getInputData or map stage. Then the shuffle stage would provide three key/value pairs. Thus, we would have first item’s internal id with 3 pricing data records, second key with 5 pricing data records, and third key with 4 pricing records (see Table 2 and 3 for sample). | Not Applicable (NA) |
| 4. reduce()
| This stage gets data from shuffle stage. In this stage, values with the same key appear to be grouped together. This function evaluates data in each group where one group is passed every function invocation. | 1000 per call (10000 per Task) |
| 5. summarize()
| This function gets data from Reduce function. Logic can be built to do the final processes for the data. For example, updates or file/log writing can be done here. | 10,000 |
Not all the stages are required for map/reduce script to function. Distinct stages are applicable depending on the processing needs or logical reasons. Of the five stages, either map or reduce function can be omitted depending on processing needs. In addition, summarize stage can be completely omitted should there be no need for looking at summary or nothing to be done after completion of the previous stages.
For illustration, three entity types and two example cases are discussed in this blog. These entities are named Item, Pricing and Price Effective Date. The record type 'Item' includes attributes of id, name, and inactive. The 'Pricing' entity contains attributes of internalId, unitPricing, category, and item. The 'Price Effective Date' entity contains attributes of internalid, price, effectiveDate and item. The relationship is simple where item can have zero or more Pricing and Price Effective Date records. The attributes and relationship are shown an object-relational diagram in Figure 1.
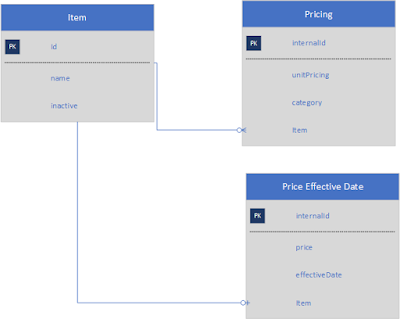
Figure 1. Example object relational map
The first example illustrates the use of map function and second example shows the use of map and reduce function. In both examples, getInputData is required and summarize is optional. The first example illustrates a case where price data for all the items matching certain criteria are deleted. The second example illustrates a case where ‘Price Effective Date’ records are created for items matching the search criteria. The Price Effective Date shares many of the attributes of price data and the requirement is that for each price data, there is a need to create new Price Effective Date records for each item after deleting the existing Price Effective Date records for that item.
In both the examples, there is a search built into the script returns item id and related pricing data for a defined criterion. Alternatively, the saved search can also be used. The example included with this blog uses defined search within the code. The search which is executed in getInputData() stage returns item id, pricing category, internalid of pricing data, and unitPrice of pricing data. Example records for illustrations are shown in Table 2.
Table 2. Example of Item Price Data.
| Id | Pricing category | internalId.pricing | unitPrice.pricing |
| 1001
| 1
| 101
| 10
|
| 1001
| 2
| 102
| 20
|
| 1001
|
| 103
| 30
|
| 1002
| 1
| 104
| 5
|
| 1002
| 2
| 105
| 10
|
| 1002
| 3
| 106
| 15
|
| 1002
| 4
| 107
| 5
|
| 1002
| 5
| 108
| 15
|
| 1003
| 1
| 109
| 1
|
| 1003
| 2
| 110
| 2
|
| 1003
| 3
| 111
| 3
|
| 1003
| 4
| 112
| 4
|
| …
|
|
|
|
Code listing for the first example is shown in Listing 1 which is written in SuiteScript 2.0 and uses Map/Reduce. When completed the script deletes existing pricing data for qualifying items where qualifying items are determined by defined search in getInputData stage. The script follows the following generalized algorithm:
- Read the items and price data in getInputdata
- In the map stage, delete the price data that was passed from getInputData stage
- In summery stage, write the audit log regarding uses and descriptive messages
Listing 1. Code Listing for Example 1
In the function above, the map function receives records as illustrated in Table 2 and the function gets hold of the internal id of pricing data and deletes the records. The context.write(///) function writes this information which is passed on to the next function (the summarize in this case) that can be used to summarize the number of records that were processed which of course is optional. In this process, the shuffle stage simply aggregates the keys with values and passes that data on to next stage. The main task of deleting records is done here and thus no reduce stage was needed.
The second example involves more than deleting the records. The objective is to read the pricing data and create additional records for Price Effective Date for the items. The number of Price Effective Date for an item must match the number of Pricing data for that item. The newly created Price Effective Date must have a different price and a different effective date. For simplicity, it is assumed that the price is going to be 2% more than the price reflected in [ricing data and the effective date is a constant value in this example. The code example is shown in Listing 2 which follows the following generalized algorithm:
- Read the items and price data in getinputdata
- In the map stage, create a data structure for where the key is itemid and value is price data.
- The shuffle stage would reduce the key: value to create a data structure where the key is item id and value is the list of price data for that item
- In reduce stage, item: [pricedata] is received.
- Delete Price Effective Date for Item
- For each PriceData in the item
- Create Price Effective Date
- In the summary stage, write the audit log regarding uses and descriptive messages
Listing 2. Code Listing for Example 2
For the second example case, the getInputData function remains the same which passes the data on item and price to the map stage. The map function is slightly different in which mapping of actual data occurs to create a data structure where the key is the item id and value is the pricing data. This data is written with context.write(...) function in this stage. The shuffle stage works behind the scene and data is aggregated and passed to reduce stage. The shuffle stage enumerates all the key: value pairs as they come and passes the resultant object to reduce stage. Between map and reduce stage, the data is reduced by unique item ids reduce stage receives one item with all the pricing data as one record.
Table 3 represents the result of mapping and shuffling where one item will have one record and all of the pricing data. The map/reduce was able to produce the mapped data from Table 2 to reduced data into Table 3. Therefore, in the reduce stage, one item is passed once. The code example shows how we can delete Price Effective Date records and create new Price Effective Date using two different functions.
Table 3. Example of Reduced Data
| Id | PriceData |
| 1000 | [
{priceLevel:101, price:10, item:1000},
{priceLevel:102, price:20, item:1000},
{priceLevel:103, price:30, item:1000},
]
|
| 1001 | [
{ priceLevel: 104, price: 5, item: 1001 },
{priceLevel:105, price:10, item:1001},
{priceLevel:106, price:15, item:1001},
]
|
There could be 1000s records returned by the search. However, within map/reduce paradigm in NetSuite, these records are passed from getInputData stage to map or reduce stage one record at a time. If the objective is to modify the pricing data (or delete a pricing data) as demonstrated by the first example, the record can be modified in the map stage or reduce stage for that matter. The use case would be as simple as calling a delete function by passing the id of the record to be deleted. We may need to load the records internalId.pricing and push the update. In reduce stage, multiple queues will pass one item and corresponding price data in parallel. The two examples show how Map/Reduce can be used in two different patterns.
The first example shows how to use multiple queues in processing a larger number of records. In this example, an individual record is passed to map stage from getInputData stage. Some level of processing can be done at Map stage. The individual records are processed as a sole process in map records. This pattern can be used to process simple records. For example, CRUD operation on records passed into the context can be done here and then summarize can be called by passing a key: value pair to the context. The second example uses reduce stage where a new set of key: value pair is created in the map stage for further processing and passed on for reduce stage.
In the second example, we first enumerated all the price data for an item, made one search call for identify price effective date records for one item and deleted those records before creating new price effective date records. In both the examples, NetSuite provided parallel processing support and aggregation or reduction support behind the scene and developers do not need to worry about handling multiple queues or reduction.
The code listing, I provided is not complete. I skipped several lines of error handling to make the script compact. Also using a constant for the effective date field and price field for Price Effective Date record was a decision to make things simpler. In some cases, we must rely on some repeatedly used objects. For example, if the price change is dependent on certain other business logic. In such case, instead of calling the search for all the items, we can make use of caching techniques that NetSuite provides. I am going to write a follow-up article on enhancing Map/Reduce performance using Caching.
In this article, I attempted to elaborate some real-world example of map/reduce function in NetSuite. I would love to hear reader’s comment or improvement ideas. I will update the blog as necessary. Thank you for reading this article and providing comments. The code and their versions are publicly available at my GitHub repository at https://github.com/benktesh/netsuite under Map Reduce Examples folder.

