In this article, we will discuss how to create and deploy a rule-based natural language processing (NLP) engine that can be actively used in the modern chatbot assistants and instant messengers.
To download the project, you can alternatively visit my GitHub repository at:
Also, you may try out the web-application by visiting:
Background
“The Internet: Transforming Society And Shaping The Future Through Chat…” –
Dave Barry, New York Times - Best Selling Author.
During the past few decades, we observe a drastically growing interest to various areas of IT, providing an ability of large businesses online to communicate to the world and audience of their customers via voice-, video- and textual messages, influencing the significant popularity of many cloud-based online messaging apps, including Google and IBM Watson/Bluemix Assistant, Facebook messenger, WhatsApp, Microsoft Bot Framework, Cisco Spark, Slack and other individual platforms and web-sites.
According to the latest surveys, above 90% of people are currently using the various online messaging services (or, simply, a ‘chat’) to communicate with the outside world. Many of these people are online shoppers, requiring assistance when purchasing specific products or services of interest. This, in turn, encouraged many existing large businesses to integrate their real-time customers assistance features with most of the existing online messengers, gaining an opportunity to effectively advertise and merchandise the products and digital content they offer. As you might already have known, about 40% of the most popular products and digital content are advertised and were completely sold out online, including the bestsellers of 2018. Every year, assistance messengers are becoming an integral part of any web-site advertising and selling specific products and services.
However, the still increasing audience of customers that post their inquiries about specific products and services via instant messengers gradually caused the enormously huge workloads and ‘bottlenecks’ on the channels providing specific help and assistance, interrupting the communication with their respective customers, requiring help.
Later, the businesses revealed that they no longer are able to improve their channels bandwidths and also to increase the actual number of messaging channels receiving and transmitting messages from or to its customers. In this case, the most efficient resolution of the following serious problem was to maintain and entrust the part of customer assistance process to the automated messaging assistants (or ‘chatbots’). This, in turn, allowed to effectively reduce the potential workloads on the messaging channels, providing answers to simple inquiries and frequently asked questions (FAQ). Nowadays, most of the existing online technical assistance and support messengers include chatbots as a permanent and integral feature.
A ‘chatbot’ (defined) – is a computer program or artificial intelligence (AI) that provides a text- or audio-based feature of conversation between businesses and the audience of its customers without an interaction with a human assistant. Itself, chatbots are specially designed to simulate understanding of inquiries and generate human speech when posting their replies. Most of the existing chatbots are capable of simulating a human conversational partner and therefore pass the famous Alan Turing’s intelligence criterion test. Today, chatbots are used for the two common purposes of either public messaging apps or companies’ internal platforms such as technical support, human resources or IoT.
There’re a various of known strategies that allow to create and deploy chatbots, intended to simulate the conversation. All of those strategies are mainly based on using natural language understanding (NLU), either rule-based or statistical.
The rule-based natural language processors were the very first, early, language processing systems. The entire process of natural language analysis basically relied on the hard-coded set of English grammar rules. The main problem with rule-based NLPs is that didn’t provide the desired quality of natural language understanding while analyzing arbitrary and not quite correct, according to the English grammar, cut phrases.
The statistics-based natural language processors is another kind of natural language understating feature, that was invented, later on, in early 1980s. The following type of language processors is mainly based on using artificial neural networks (ANN) and various machine learning (ML) algorithms. Most of those algorithms and patterns use statistical data model to automatically learn those English grammar rules based on corpus of documents and phrases posted to the chatbot by humans, in the past. The main disadvantage of the statistics-based approach is the typically long time during which an ANN-based natural language processor learns to reveal and recognize grammar rules. In this case, the corpus of documents must be typically huge and include lots of both correct and not correct phrases. Also, it’s really very difficult to find an already existing corpus of documents on a specific theme, containing phrases valid to be used for a new chat’s ANN-based natural language processor training purposes.
In today’s real world, while creating and deploying chat engines, we’ve basically dealt with a so-called “mixed” type of natural language processors (NLP) that rely on both rule-based and statistical methods of language processing.
In this article, we will thoroughly discuss how to create and deploy a smart custom chatbot based on Natural Language Processing (NLP) engine developed using Node.js. Specifically, we will demonstrate how to maintain an efficient human natural language recognition engine (NLU/NLRE) based on a semantic network and series of algorithms that allows to effectively find and recognize the intents and objectives within phrases and utterances sent as an inquiry to the automated assistance chatbot engine.
In particular, we will discuss how to properly and effectively build a chat’s knowledge base data model, based on the logic of a semantic graph (i.e., network), in which the most “useful” language concepts are arranged and associated with correct answers to the customers’ questions, posted to the technical assistance chat. Finally, the following approach allows to form a “finite” dictionary of concepts, which the process of the language understanding basically relies on.
The natural language processing algorithm, thoroughly discussed in this article, according to its nature, is an efficient rule-based algorithm that can be used to find all possible variants of intents and grammar predicates in a sentence passed to the inputs of natural language processing engine. The following algorithm allows us to find a general meaning of each human phrase by determining a relevance between each intent or grammar predicate, extracted from a sentence by a language parser, and set of various semantic concepts. It simply matches each intent retrieved from a sentence against each concept in the semantic knowledge base, mentioned above. The following process is actually called a ‘semantic parsing’ or ‘word-sense disambiguation’. For the most relevant intents and concepts, it makes suggestions of correct answers for the given inquiry.
Generally, the natural language processing engine, discussed in this article, compared to the other early rule-based methods and algorithms of the past, provides a high efficiency of natural language understanding and could be used as a good alternative to many existing statistics-based engines, especially those ones computing an overall confidence values for the topic of a document or provide a detailed statistics on the keywords frequently occurring in the document, only.
Background
The main purpose of this article is to introduce the number of aspects of automated chatbot assistant development to the readers. In the very first chapter of this article, we’re about to discuss the general chatbot assistant solution architecture, along with the development scenario that allows to quickly and easily create and deploy various chatbots relying on the rule-based natural language processing (NLP) engine and decision-making process formulated as a computer algorithm, rather than an artificial intelligence. In the succeeding chapters, we will discuss about the family of algorithms that can be used to maintain a rule-based natural language processing engine, capable of performing the analysis of text messages, submitted by a human. Specifically, we will introduce a semantic network of “useful” linguistic concepts, represented as the data model, which the entire process of natural language understanding (NLU) and decision-making basically relies on. Besides, we will formulate a decision-making algorithm for finding the suggestions of the correct answers for each particular inquiry, processed by NLP-engine, based on one or multiple specific criterions. In the final, “Using the Code” chapter, we will discuss about the development process itself, particularly, demonstrate how to create a chatbot assistant engine using Node.js, HTML5, Angular 2 and MySQL.
Modern Chatbots. Behind the Scenes…
In this chapter, we will discuss the integration scenario, very common to most of the existing chatbot assistants and other automated instant messengers (IM), being ever created and deployed. Specifically, we will delve into the chatbot assistant solution architecture, concentrating the discussion on each particular component, process or model within the entire chatbot solution, introduced in this article.
According to the main idea of the Internet and World-Wide-Web (WWW), chatbots are commonly built as Software-As-Service (SaaS) solutions, providing an ability of clients to communicate with chatbots using their devices, either desktop PCs or mobile and tablets.
In most cases, an automated chatbot is a software solution consisting of two main tiers. Specifically, a chatbot’s front-end web-application is the first tier, which is very simple and common to other services existing on the World-Wide-Web. In other words, the following tier is a middleware, providing a required interaction between users and the chatbot, respectively. The main application’s HTML web-page contains an embedded visual container, deployed a “widget”, providing an ability of clients to type-in and post their inquiries, and, also rendering the responses received from a chatbot assistant services. In fact, chatbot web-application’s background service pipelines the incoming requests between web-application available to the clients online and the second tier, discussed in the next paragraph.
The second tier is actually the chatbot assistant engine, which is more complex rather than the front-end web-application itself. It provides the basic functionality for receiving text message inquiries as the requests, from the specific web-application, at the first tier, and processing of these requests by performing the natural language analysis and making decisions about the suggestions of correct answers to these inquiries. This tier includes the following components and processes, such as chatbot assistant services, handling the incoming clients requests, natural language processing engine (NLP), performing the analysis of text messages arrived, decision-making process to find various of answers’ suggestions, as well as the semantic knowledge database (SK-DB), used to store the linguistic semantic data on the corpus of “useful” concepts, which the NLP-engine and decision-making process basically relies on. Further, we will provide a detailed description of each particular component or process within the architecture, being discussed. The chatbot architecture representation discussed in this article is much simpler, compared to many existing chatbot assistant services architectures. Just for simplicity, we’ve combined particular components and processes, such as natural language generation (NLG) and messaging back-ends (MBs) within NLP-engine and decision-making process.
Generally, a modern chatbot is a centralized multi-tier solution, including the following components and processes:
- Front-End Web-Application is intended to provide an interconnection between multiple of clients and background chatbot assistant services.
- Chatbot Assistant Services processes the incoming requests, containing specific text messages, forwarding them to the natural processing engine (NLP) and receiving data on the suggestions of the most correct answers from the decision-making process.
- Natural Language Processing Engine (NLP) accomplishes the most part of the inquiry request processing by performing an analysis of grammar predicates for each particular phrase within an incoming text message.
- Decision-Making Process receives the specific requests from NLP-engine, containing of the intents and terms, extracted by NLP-engine from the text message, and performs a search in the chatbot’s knowledge database to find the most appropriate suggestions of answers to each specific inquiry by a certain criterion.
- Semantic Knowledge Database (SK-DB) stores a linguistic semantic network, represented as the data on a corpus of “useful” concepts, used by the either natural processing engine or decision-making process to perform grammar predicates analysis and suggestions of correct answers finding.
The chatbot assistant architecture, discussed in this article, is illustrated on the Fig. 1a., shown below:
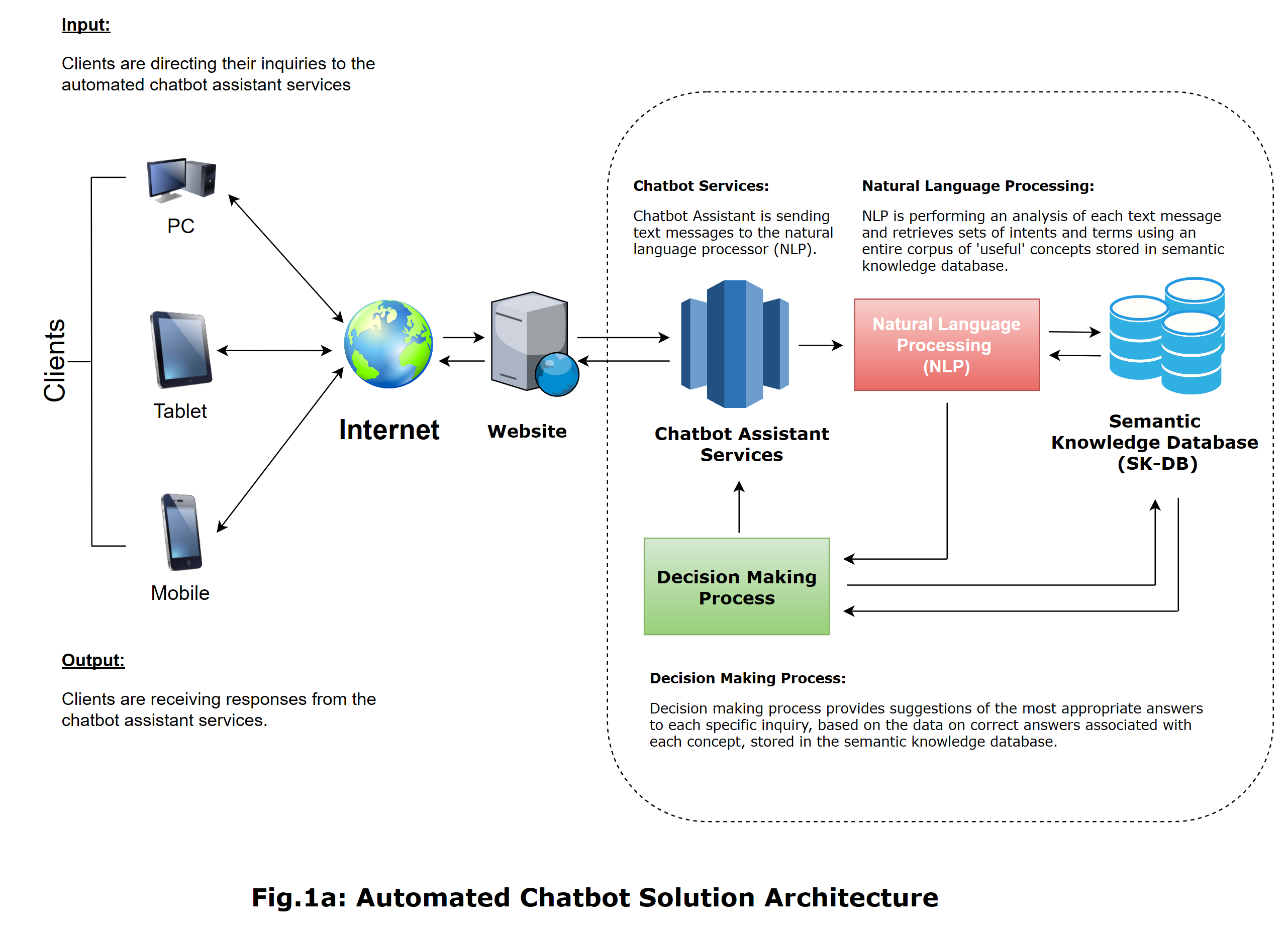
According to the architecture shown above, clients visit the chatbot assistant web-site with their local web-browsers. In the chatbot web-site’s main web-page, they type-in and post their inquiries, interacting with the chatbot messaging “widget”, that is directing their text messages entered to the web-site’s main application service. The messaging “widget”, itself, is a special feature, implemented as one of the parts of the web-site’s main page, typically an HTML and JavaScript embedded code fragment. This code basically retrieves the text message data from the web-page’s text-area controls and posts specific Ajax-requests containing these data to the application’s background service that accepts those requests and is simply forwarding them to the chatbot assistant services via the requests pipeline established.
Then, the chatbot assistant services redirect those requests to the NLP-engine, that is processing the new requests arrived by performing the rule-based analysis of text messages from the requests, determining and retrieving sets of intents and terms from each particular phrase, based on the corpus of “useful” concepts stored in the semantic knowledge database, discussed below. The NLP-engine basically relies on the process of matching each grammar predicate from the current phrase against the dataset of possible concepts from the semantic knowledge database. The following process is thoroughly discussed in one of the succeeding chapters of this article. Since, all possible intents and terms are successfully extracted from a phrase, the NLP-engine is forwarding the request containing the specific data to the decision-making process. In turn, the decision-making process receives those data as the requests and performs a search in the semantic knowledge database to find the suggestions of the most appropriate answers for each inquiry, based on a certain criterion.
Additionally, there’re various approaches for creating and deploying decision-making process, the either rule- or artificial neural networks (ANNs)-based. In this article, we will bound our discussion to the rule-based process only, fast and reliable.
Finally, the dataset of correct answers’ suggestions being found is forwarded back to the chatbot assistant services, which, subsequently, redirects them to the front-end web-application as the response to the specific Ajax-request. Since the Ajax-response with data on the correct answers’ suggestions has been received, the “widget” feature of the application’s main web-page is rendering the list of answers’ suggestions by executing a JavaScript code that dynamically handles specific text-area controls to display a list of response messages.
In the paragraphs above, we’ve thoroughly discussed about the basic chatbot assistant services functionality. However, the real architecture of many existing chatbots can be simplified by combining all of these components and processes into a single web-application, accomplishing all these tasks. The simplified representation of chatbot assistant architecture is shown in Fig. 1b. below.

Natural Language Processing Engine (NLP)
The Natural Language Understanding (NLP) engine is a central component of an automated chatbot assistant being created and deployed. The NLP-engine, discussed in this article, is a rule-based engine, basically relying on using the series of text message parsers, that perform the grammar predicates analysis in order to retrieve sets of intents and terms from a given text message. The entire process of natural language understanding, conducted by the NLP-engine can be logically divided into the number of stages, starting at the sentence tokenization and part-of-speech (POS) tagging, and ending specifically with language predicates parsing.
The NLP-engine receives a text message as a request and performs the initial text message normalization by performing a sentence tokenization based on several rules of splitting up an entire message text into a set of specific sentences. After that, a set of sentence tokens are passed into the engine performing part-of-speech (POS) tagging, which, as the result, returns sets of parts of speech tags, such as verbs, nouns, adjectives and adverbs, that persist in the input text message. These sets are further normalized using the data stored in semantic knowledge database. Additionally, during this stage, the stochastic grammar analysis is performed to retrieve the main persisting entities and compute the occurrence-based statistics of each of these entities. Finally, the NLP-engine performs an “aggressive” language predicates parsing and filtering to retrieve sets of intents and terms from the input text message, based on the array of sentences and the data from pos-tags dictionary. The result of performing natural language understanding (NLU) is the set of intents and terms retrieved from the input message, and forwarded to the decision-making process, as it has been previously mentioned above.
Sentence Tokenization
The very first stage of the NLP-processing is the sentence tokenization. During the development cycle, we will formulate and use the following sentence tokenization algorithm, based on the process of conditional string splitting:
- Split a text message string by each “punctuation” (‘.’,’,’,’!’,’?);
- Split a text message string by its “conjunctions” (‘and’,’or’,’nor’,’but’);
- Split a text message string by “pronouns” ('either', 'neither', 'also', 'as well', 'too');
- Split a text message string by “adverbs” ('also', 'as well', 'too');
- Split a text message string by “negatives” ('not', 'don’t', 'doesn’t', 'haven’t', …);
To perform the actual conditional splitting, we can normally use the generic framework routines, as well as our own custom splitter using the algorithm, that was implemented and discussed, further, in the “Using the Code” chapter of this article. As a result of performing the conditional splitting, we will obtain set of sentences, analyzed during the next stage of NLP-processing.
Most rule-based NLP-engines use the so-called “distance-based” parsing algorithm, the one issue of which is the “distance” problem. For example, suppose we’re having a text message consisting of two sentences: “I want to create a channel. Also, I’d like to delete workspace”. Obviously, that, the most common intents for this text fragment, when analyzing it without distance criterion”, are “create channel”, “create workspace”, “delete channel” and “delete workspace”, which is normally wrong results of the analysis, causing misunderstanding, and, thus, a poor quality of the NLP-processing, in general. Performing sentence tokenization allows us to effectively limit the distance between specific actions and entities, bounding the process of finding intents to each specific sentence separately, having a smaller distance measure. For example, if we’ve split up the entire text message above by the punctuations, we will obtain two sentences analyzed separately. In this case, we will get more appropriate results such as a set of the following intents: “create channel” and “delete workspace”, respectively, and so on. The sentence tokenization is a very important stage, affecting the quality of the entire NLP-process in general.
Part-Of-Speech (POS) Tagging
After performing the sentence tokenization and obtaining a set of sentences, according to the NLP-algorithm, discussed in this chapter, we basically need to perform the part-of-speech (POS) tagging of each particular sentence. During this process, we will basically perform the category classification of each word within a current sentence, determining its part of speech such as either verbs, nouns, adjectives or adverbs. The entire process of pos-tagging basically relies on various of linguistic solutions, the either local or cloud-based, providing a service of an online dictionary for a specific language. The most common example of the results of performing pos-tagging is as follows:
Input Phrase = “I want to create a channel…”
POS = { ‘nouns’: [‘I’, ‘channel’, ‘want’], ‘verbs’: [‘want’,’create’] }
Unlike the other NLP-solution, in this particular case, we basically perform the so-called pos-normalization by matching the final results of pos-tagging against the “nouns” (i.e. “entities”) and “verbs” (i.e. “actions”), existing in the semantic knowledge database. Specifically, our goal is to filter out all pos-tags that do not belong to any of the concepts within a corpus stored in semantic knowledge database. The main idea for performing such a normalization is that we need to eliminate all the pos-tags from the results, having actually nothing to do with the conversational theme. By doing this, we will receive the following results:
Input Phrase = “I want to create a channel…”
POS = { ‘nouns’: [‘channel’], ‘verbs’: [’create’] }
The other pos-tags are simply omitted due to being unrelated and thus redundant in this particular case. We will get back to the same discussion of this topic later on in the chapter describing the semantic knowledge database.
Stochastic Grammar
Another stage of the NLP-processing is the stochastic grammar analysis. During this analysis, we basically find the statistics on the occurrence of each particular pos-tag, excluding all parts of speech, but “nouns”. Stochastic grammar analysis is performed in order to filter all pos-tags (i.e., nouns) having the highest occurrence. This stage is very helpful in case when we’re attempting to use NLP-engine to analyze containing only nouns or a fuzzy speech fragments, hard to analyze. The algorithms for performing stochastic grammar analysis are very trivial and thoroughly discussed in the “Using the Code” chapter of this article.
Language Predicates Parsing
The language predicates parsing is the main stage of the natural language understanding performed by the NLP-engine. As we’ve already mentioned the number of times, the NLP-engine introduced in this article is the rule-based engine, accomplishing the analysis tasks relying solely on using the series of parsers, intended to extract various grammar predicates from each sentence obtained as the result of performing the preceding stages.
Specifically, in this chapter, we will introduce the NLP-engine that performs the analysis based on using three main textual data parsers. The analysis, itself, is the grammar predicates extraction process, used to find and these kinds of predicates:
- “verb” + “adjectives” + “noun” + “negative?”;
- “noun” + “adjectives” + “verb” + “negative?”;
- “noun” + “adjectives” + “noun” + “negative?”;
Practically, we’re parsing each particular sentence passed to the inputs of the NLP-engine by using three main parsers, attempting to locate and retrieve grammar predicates of those types listed above. Also, each particular sentence is split up into an array of words, delimited by a space-character, prior to performing the actual parsing.
The first one we’re about to discuss is the “verb” + “adjectives” + “noun” + “negative?” rule-based parser. The following parser can be formulated as an algorithm listed below:
- Given a set of token |D|={ w1,w2,w3,...,wn-1,wn };
- For the current token w(k) perform a check if this token is a “verb”;
- If not, proceed with the next token w(k+1) and return to step 1, otherwise proceed to the next step;
- Find a set of all “negatives” (if exists) in the subset of preceding tokens |D|[0,k-1];
- Pair each negative w(r) with the current verb w(k) and go to the next step;
- Find a set of all “nouns” in the subset of succeeding tokens |D|[k + 1, n];
- Pair each noun w(t) with the current verb w(k) and go to the next step;
- Proceed with the next token w(k + 1) and go to step 1;
- Generate a set of intents based on the pairs of “noun” + “verb” + “negative?”;
According to the algorithm listed above, the sets of intents are generated based on the following principle. First, for each “verb” token, we’re finding all negatives persisting in the array of tokens and generating specific pairs. Then we’re finding all “nouns” and associate each noun with each pair “verb” + “negative?”, obtaining the list of all possible grammar predicates, ever existing the input sentence.
Then, we’re performing the parsing of “noun” + “adjectives” + “verb” + “negative?” and “noun” + “adjectives” + “noun” + “negative?” grammar predicates, using a quite similar algorithm as the introduced above. Finally, we merge all various intents being found to the entire set of intents and pass the following data to the decision-making process for the further analysis. The example below illustrates the following process.
Suppose, we’re having a set of text message sentences such as “I want to create a workspace and channel”, “I don’t want to onboard my company yet”.
Sentence #1 = “I”, “want”, “to”, “create”, “a”, “workspace”, “and”, “channel”.
At this point, we’re aiming to find each “verb” in the sentence. Apparently, the word “want” is the first verb being found. After that, we’re performing a check if there’s no negatives in the subsets. Obviously, that, the following set of tokens doesn’t contain any of the negatives. Therefore, we’re proceeding with finding all “nouns” within the set. In this case, we’ve found the following set of “nouns”: [ “workspace”, “channel” ]. Finally, we’re pairing each current “verb” token with each of the “noun” tokens and end up with the following result:
‘action’: ‘want’, ‘entity’: ‘workspace’
‘action’: ‘want’, ‘entity’: ‘channel’
‘action’: ‘create’, ‘entity’: ‘workspace’
‘action’: ‘create’, ‘entity’: ‘channel’
These pairs listed above are actually the intents consisting of action and entity attributes exactly corresponding to each “verb” and “noun” being found.
Sentence #2 = “I”, “don’t”, “want”, “to”, “onboard”, “my”, “company”, “yet”
In this case, the following sentence contains of two “verbs”, the either “want” or “onboard”. At this point, we’re performing a check if there’s at least one “negative” preceding each “verb”. Obviously, that, there’s a single negative “don’t” in this sentence, which we’re going to pair with each particular “verb” being found:
‘negative’: ‘don’t’, ‘verb’: want,
‘negative’: ‘don’t’, ‘verb’: onboard
Then, obviously, we’re aiming to find all nouns in this sentence. Actually, the following set of tokens contains just one “noun” – “company”, which will be paired with each of the “negative” + “verb” pairs:
‘negative’: ‘don’t’, ‘verb’: want, ‘noun’: company
‘negative’: ‘don’t’, ‘verb’: onboard, ‘noun’: company
At this final point, the process of the NLP-analysis is over, and the sets of intents generated by using the algorithm, discussed in this chapter, are passed as the requests to the decision-making process.
Decision-Making Process
Decision-Making is the final stage of the NLP-analysis process, that performed based on the sets of intents and terms, retrieved from an input text message, and the data on corpus of “useful” concepts stored in semantic knowledge database. The main goal of the decision-making process is to find the suggestions of the most appropriate answers, based on the intents and terms data, received from the NLP-engine as the request. For that purpose, we will formulate and use the following algorithm:
- Given a set of intents |S|= { s1,s2,s3,…,sn-1,sn }, extracted from a text message and a corpus of concepts |P|={ p1,p2,p3,…,pm-1,pm }, stored in the semantic knowledge database;
- Take the current intent “action” + “entity” s(i); from the set |S|;
- Take the current concept p(j) from the corpus of concepts |P|;
- For the current pair of (s(i), p(j)) perform a check if the “action” and “entity” values are identical. Also, perform a check if both s(i) and p(j) have a negative attribute set. If the condition is “true”, move to the next step, otherwise proceed with step 5;
- Append an answer suggestion associated with the current concept to the set of answers suggestions;
- Proceed with the next concept p(j+1) and return to step 3;
- Proceed with the next intent s(i+1) and return to step 2;
According to the following algorithm, we are actually iterating through the set of intents and for each particular intent are performing a linear search to find the concepts with similar “action” and “entity”, as well as the similar negative attribute. For each concept satisfying the condition, we fetch a specific answer suggestion.
For instance, we’re having a set of intents found by the NLP-engine, in the previous example:
‘action’: ‘want’, ‘entity’: ‘workspace’
‘action’: ‘want’, ‘entity’: ‘channel’
‘action’: ‘create’, ‘entity’: ‘workspace’
‘action’: ‘create’, ‘entity’: ‘channel’
Also, we’re having a corpus of “useful” concepts, such as:
‘action’: ‘create’, ‘entity’: ‘workspace’, ‘answer’: ‘answer#1’
‘action’: ‘create’, ‘entity’: ‘channel’, ‘answer’: ‘answer#2’
‘action’: ‘delete’, ‘entity’: ‘channel’, ‘answer’: ‘answer#3’
‘action’: ‘migrate’, ‘entity’: ‘company’, ‘answer’: ‘answer#4’
Let’s take the first intent from the set of intents (e.g., ‘action’: ‘want’, ‘entity’: ‘workspace’). Then, let’s iterate through the set of concepts and for each concept, perform a check if it has ‘action’ and ‘entity’ value equal to the corresponding values of the current intent. In this case, these values are identical for the first concept in the set above. That’s why, we’re fetching the ‘answer’ value from the first concept and append it to the set of answers suggestions. Actually, we will do exactly the same with each intent and each concept in the sets. As a result, we will obtain the following set of answers suggestions:
Answers = { ‘answer#1’, ‘answer#2’ };
According to the distinctness and disambiguation restriction, discussed in the next chapter, the other answers in the set of concepts are simply omitted, since they’re unrelated to the topic of inquiry.
Semantic Knowledge Database
As we’ve previously discussed in the previous chapter, the entire decision-making mechanism basically relies on the data stored in the semantic knowledge database. In this case, this data is used to find a dataset of the most appropriate answers’ suggestions based on the criteria of similarity between the intents and terms retrieved from each text message by NLP-engine and pre-defined intent samples of the “useful” concepts stored in the semantic knowledge database.
In this chapter, we will discuss how to build a semantic knowledge data model which is a slightly different, compared to the most of existing semantic models, ever used in NLP/NLU-solutions. The term “semantic knowledge database” is very close by its meaning to another term such as “semantic knowledge base” or “semantic network”. To represent particular “concepts” in the regular semantic networks, we have used triples of (“noun” + “verb + “noun”), also known as grammar predicates, and, then, established all possible relations between specific concepts. Of course, this particular method is not perfect for those NLP-engines, commonly used for chatbot assistants and instant messengers.
Instead, we will discuss about the semantic data model, in which all “concepts” are represented by “tuples” such as either (“verb” + “adjective” + “noun”), (“noun” + “adjective” + “noun”), … Each of these tuples are another form of grammar predicate, representing so-called “intents”. The term “intent” basically refers to the commitment of a human to carry out some desired action to modify a state or, specifically, a subject or entity, itself. “Verbs” within each tuple typically map to a specific action, while “nouns” are the subjects or entities on which those actions are applied. For example: “create workspace”, “delete a shared channel”, “migrate company”, … A special case is the tuples consisting of two nouns, in which the first noun exactly matches a subject or entity and another one – the process of an action itself, and vice versa. For example: “workspace creation”, “onboarding company”, “adding a freeware application”, … Both these types of tuples might optionally contain “adjectives” in an arbitrary position, that describe a subject or entity, for example: “shared”, “freeware” are adjectives that describe a related subject or entity (e.g., “channel” and “application”). Also, there’re two types of tuples, either “positive” or “negative”. The negative tuples also might contain negation adverbs, in the most cases, describing an inability of action, such as “I cannot create a workspace”, “I’d like to create a channel and not onboard my company”, … The negativity in grammar predicates is commonly used to provide a negative sense of a phrase or a so-called “action failure” attribute, which benefits in a better understanding while troubleshooting an action. The semantic model being proposed is shown in Fig. 3. below.
As shown in the figure above, the “vertices” of the following semantic graph basically map to the either “actions” or “entities”, respectively. In turn, the “edges” of this graph normally represent relations between specific entities and actions. In the next paragraph, we will briefly discuss how to represent the following semantic graph in the form of “useful” concepts database.
According to the semantic model being introduced, each “concept” within the knowledge database basically consists of one or more sample “intents” along with “answers” or “responses”, associated with it. Each concept containing a sample “intent” + “answer” is the data used by decision-making process to find answers’ suggestions for the most similar intents from the knowledge base, based on the criterion of similarity measure between the intents retrieved by the NLP-engine from a human phrases and sample intents from the specific concepts in the existing knowledge base.
From Sematic Networks to Adaptive Knowledge Databases…
The approach discussed in this chapter allows us to transform the generic semantic model into a simpler one, quickly and easily deployed as a regular database, intended to store a dataset of “useful” concepts, rather than a semantic data arranged in a more complex multi-dimensional data structure. An example of a dataset of “useful” sample concepts is illustrated in Fig. 4., shown below.
As you can see from the following example above, the entire database consists of concepts, each one of which is having the number of attributes such as an action and entity, descriptive tags, negativity attribute, and, finally, answer associated with specific concept, as well as other miscellaneous attributes, such a reference URL. The “entity” is a “key” attribute of each concept, explicitly describing a “subject”, on which one or multiple actions could be applied. The data on the set of sample entities is used during stochastic grammar analysis, performed by the NLP-engine, to reveal the general meaning of a given phrase.
The set of distinct concepts based on the intents, consisting of each “action” and “entity” builds a so-called “lexicon” of the linguistic knowledge base, benefiting in better intents and terms’ disambiguation, during the language understanding process, performed by the NLP-engine. As we’ve already discussed, the NLP-engine, during part-of-speech (POS) tagging stage, creates a “dictionary” of all possible verbs and nouns, exactly corresponding to the specific “actions” and “entities”, in the knowledge base. This dictionary of verbs and nouns is used as a lexicon by the either NLP-engine and decision-making process, eliminating those cases, in which the NLP-engine cannot retrieve the specific intents and terms from a given phrase, as well as, is retrieving the unnecessary redundant speech fragments that are unrelated to the following conversational theme.
Suppose, we’re having a semantic knowledgebase shown in the figure above, and, a phrase such as “I want to create workspace, ride a horse and also delete a shared channel”. During the pos-tagging stage, the NLP-engine creates a dictionary of words (i.e., verbs and nouns) within a given phrase, filtering out those words, that don’t occur as an either “action” or “entity” in the following semantic knowledge base. The results of pos-tagging must be as follows:
Input Phrase = “I want to create workspace, ride a horse and also delete a shared channel”;
Dictionary = { ‘verbs’: [‘create’, ‘delete’], ‘nouns’: [‘workspace’, ‘channel’], ‘adj’: [‘shared’] };
As you can see from the example above, the words “ride” and “horse”, and also, “I”, “want”, “to”, “also”, “a” have been simply excluded from the dictionary, since these are the redundant words, having nothing common to the topic of the inquiry.
The “distinctness” of the semantic knowledgebase lexicon itself is very important aspect, having a large impact on the quality of language understanding performed by the NLP-engine in general.
Later on, in the “Using the Code” chapter, we will thoroughly discuss how to create and deploy a relational database to store the corpus of “useful” concepts, that we’ve thoroughly discussed in this chapter.
Using the Code
In this chapter, we will discuss about the development of web-application in Node.js, JavaScript/jQuery, HTML5, CSS, MDBootstrap4, Angular2 and MySQL performing the natural language processing (NLP) of the input text messages.
Front-End Web-Application
The main web-page of this application was designed to provide the interaction between users and the NLP-engine, running as the web-application’s background service. The following HTML-document was created by using HTML/CSS and MDBootstrap4. I’ve embedded the bootstrap’s powerful navigation bar to support navigation between two main tabs, rendering either an input text-area that allows to type-in and submit users’ inquiries, or a chart of the semantic knowledge database contents, that, in turn, provided an ability of users view, modify or remove the entries to the semantic knowledge database. Also, the main application’s HTML-document includes the number of modal dialog boxes, designed by using the CSS-bootstrap. These modals are used as sub-components or responsive UI-enhancements, supporting a user input while editing the contents of the semantic knowledge database. The complete HTML-code, implementing the web-application’s main page is listed below:
views/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<meta http-equiv="x-ua-compatible" content="ie=edge">
<title>NLP-Samurai@0.0.10 Demo</title>
<!--
<link rel="stylesheet" href="https://use.fontawesome.com/releases/v5.7.0/css/all.css">
<!--
<link href="mdb/css/bootstrap.min.css" rel="stylesheet">
<!--
<link href="mdb/css/mdb.min.css" rel="stylesheet">
<!--
<link href="stylesheets/main.css" rel="stylesheet">
<!--
<script type="text/javascript" src="mdb/js/jquery-3.3.1.min.js"></script>
<!--
<script src="https://ajax.googleapis.com/ajax/libs/angularjs/1.2.23/angular.min.js">
</script>
<script type="text/javascript">
var concepts = angular.module('concepts', []);
concepts.controller('conceptsViewCtrl', function ($scope, $http) {
$http.post("/")
.then(function (response) {
$scope.model = response.data['model'];
});
$scope.scrollIntoView = function (elem, ratio) {
var answ_render_offset =
$(elem).offset();
answ_render_offset.left -= ratio;
answ_render_offset.top -= ratio;
$('html, body').animate({
scrollTop: answ_render_offset.top,
scrollLeft: answ_render_offset.left
});
}
$('#navbarSupportedContent-7 a[data-toggle="tab"]').
bind('click', function (e) {
e.preventDefault();
if ($(this).attr("href") == "#smdb") {
$scope.scrollIntoView("#smdb_renderer", 20);
}
});
$scope.onSendInquiry = function (inquiry) {
if ($("#responses").display == "block") {
$("responses").hide();
}
$http.post('/inquiry',
{ 'inquiry': inquiry, 'model': $scope.model }).then((results) => {
$scope.model.responses =
results["data"]["intents"].map(function (obj) {
return {
'action': obj["intent"]["action"],
'entity': obj["intent"]["ent"],
'response': obj["response"]
};
});
$("#responses").show();
$scope.scrollIntoView("#answers_renderer", 0);
});
}
$scope.onAddConceptModal = function () {
$scope.add_concept = true;
}
$scope.onViewAnswer = function (answer, url) {
$scope.answer_show = true;
$scope.answer = answer; $scope.url = url;
}
$scope.onUpdateConceptModal = function (concept) {
$scope.concept = concept;
$scope.concept_orig =
angular.copy($scope.concept);
$scope.update_concept = true;
}
$scope.onConfirmRemovalModal = function (concept_id) {
$scope.concept_id = concept_id;
$scope.confirm_removal = true;
}
$scope.onRemoveConcept = function () {
$scope.model = $scope.model.filter(function (obj) {
return obj['id'] != $scope.concept_id;
});
}
});
concepts.directive('addNewConceptModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('add_concept', function (add_concept) {
element.find('.modal').modal(add_concept ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.concept = {};
scope.concept.negative = 'false';
scope.add_concept = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.model.push(scope.concept);
scope.add_concept = false;
});
});
},
templateUrl: '/concepts'
};
});
concepts.directive('answerViewModal', function () {
return {
restrict: 'E',
link: function (scope, element, attributes) {
scope.$watch('answer_show', function (answer_show) {
element.find('.modal').modal(answer_show ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.answer_show = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.answer_show = false;
});
});
},
templateUrl: '/answers'
};
});
concepts.directive('updateConceptModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('update_concept', function (update_concept) {
element.find('.modal').modal(update_concept ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.update_concept = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.update_concept = false;
scope.model[scope.concept_orig.entity].entity =
scope.concept.entity;
scope.model[scope.concept_orig.action].action =
scope.concept.action;
});
});
},
templateUrl: '/modify'
};
});
concepts.directive('confirmRemovalModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('confirm_removal', function (confirm_removal) {
element.find('.modal').modal(confirm_removal ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.confirm_removal = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
$scope.model.splice($scope.concept_id, 1);
scope.confirm_removal = false;
});
});
},
templateUrl: '/confirm'
};
});
</script>
</head>
<body ng-app="concepts" ng-controller="conceptsViewCtrl">
<header>
<!--
<nav class="navbar navbar-expand-lg navbar-dark fixed-top scrolling-navbar">
<div class="container">
<a class="navbar-brand" href="#">
<strong>NLP-Samurai@0.0.10 (Node.js Demo)</strong>
</a>
<button class="navbar-toggler" type="button" data-toggle="collapse"
data-target="#navbarSupportedContent-7"
aria-controls="navbarSupportedContent-7" aria-expanded="false"
aria-label="Toggle navigation">
<span class="navbar-toggler-icon"></span>
</button>
<div class="collapse navbar-collapse" id="navbarSupportedContent-7">
<ul class="nav navbar-nav mr-auto" id="myTab" role="tablist">
<li class="nav-item">
<a class="nav-link active" id="nlp-tab" data-toggle="tab"
href="#nlp" role="tab" aria-controls="nlp"
aria-selected="true">Natural Language Processing</a>
</li>
<li class="nav-item">
<a class="nav-link" id="smdb-tab" data-toggle="tab" href="#smdb"
role="tab" aria-controls="smdb"
aria-selected="false">Semantic Knowledge Database</a>
</li>
</ul>
</div>
</div>
</nav>
<!--
<div class="view" style="background-image: url('images/background.png');
background-repeat: no-repeat; background-size: cover;
background-position: center center;">
<!--
<div class="mask rgba-gradient d-flex justify-content-center align-items-center">
<!--
<div class="container">
<!--
<div class="row">
<!--
<div class="col-md-6 white-text text-center text-md-left mt-xl-5 mb-5
wow fadeInLeft" data-wow-delay="0.3s">
<h2 class="h2-responsive font-weight-bold mt-sm-5">
Natural Language Processing Engine</h2>
<hr class="hr-light">
<h6 class="mb-4">Introducing NLP-Samurai@0.0.10
Natural Language Processing Engine - a Node.js framework
that allows to find and recongize intents and grammar predicates
in human text messages, based on the corpus of 'useful' concepts
stored in sematic knowledge database, providing correct answers
to the most of frequently asked questions and other inquiries...
<br/><br/>Author: Arthur V. Ratz @ CodeProject (CPOL License)</h6><br>
</div>
<!--
<!--
<div class="col-md-6 col-xl-5 mt-xl-5 wow fadeInRight" data-wow-delay="0.3s">
<img src="./images/nlp.png" alt="" class="img-fluid">
</div>
<!--
</div>
<!--
</div>
<!--
</div>
<!--
</div>
<!--
</header>
<!--
<!--
<main>
<div id="smdb_renderer"></div>
<div class="container">
<div class="tab-content">
<div class="tab-pane active" id="nlp" role="tabpanel" aria-labelledby="">
<!--
<div class="row py-5">
<!--
<div class="col-md-12">
<h2>What would you like to know about Slack Hub?</h2><br />
<div class="md-form my-0">
<div class="input-group">
<input ng-model="inquiry" id="inquiry"
class="form-control mr-sm-2" type="text"
placeholder="Type In Your Inquiry Here..."
aria-label="Type In Your Inquiry Here..." autofocus>
<a data-ng-click="onSendInquiry(inquiry)">
<i class="fas fa-angle-double-right fa-2x"></i></a>
</div>
<p style="font-size:12px">For example:
"I want to create a workspace and channel,
and also to find out how to migrate company to Slack..."</p>
</div>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit,
sed do eiusmod tempor incididunt ut labore et dolore magna
aliqua. Ut enim ad minim veniam, quis nostrud exercitation
ullamco laboris nisi ut aliquip ex ea commodo consequat.
Duis aute irure dolor in reprehenderit in voluptate velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint
occaecat cupidatat non proident, sunt in culpa qui officia
deserunt mollit anim id est laborum.</p>
<div id="responses" style="display: none">
<table class="table">
<tr ng-repeat="resp in model.responses">
<td>
<div class="card">
<div class="card-body">
<h3><b>{{resp.action}} {{resp.entity}}</b></h3><br/>
{{resp.response.answer}} Visit:
<a href="{{resp.response.url}}" style="color: blue">
{{resp.response.url}}</a>
</div>
</div>
</td>
</tr>
</table>
</div>
<div id="answers_renderer"></div>
</div>
</div>
</div>
<div class="tab-pane" id="smdb" role="tabpanel" aria-labelledby="">
<div class="row py-5">
<!--
<div class="col-md-12">
<h2>Semantic Knowledge Database...</h2><br />
</div>
<div class="col-md-12 text-md-right">
<button data-ng-click="onAddConceptModal()"
type="button" class="btn btn-primary">Add A New Concept</button>
</div>
<div class="col-md-12">
<table class="table table-hover">
<thead>
<tr>
<th>#</th>
<th>Action</th>
<th>Entity</th>
<th>Description</th>
<th>Is Negative?</th>
<th> </th>
</tr>
</thead>
<tbody>
<tr ng-repeat="concept in model track by concept.id">
<td>{{ $index + 1 }}</td>
<td>{{ concept.action }}</td>
<td><b>{{ concept.entity }}</b></td>
<td>{{ concept.desc }}</td>
<td>{{ concept.negative }}</td>
<td>
<a data-ng-click="onViewAnswer
(concept.answer, concept.url)"
style="color:blue"><b>View Answer</b>
</a> |
<a data-ng-click="onUpdateConceptModal(concept)"
style="color:green"><b>Modify</b></a> |
<a data-ng-click="onConfirmRemovalModal(concept.id)"
style="color:red"><b>Remove</b></a>
</td>
</tbody>
</table>
<add-new-concept-modal></add-new-concept-modal>
<answer-view-modal></answer-view-modal>
<update-concept-modal></update-concept-modal>
<confirm-removal-modal></confirm-removal-modal>
</div>
</div>
</div>
</div>
</div>
</main>
<!--
<!--
<script type="text/javascript" src="mdb/js/popper.min.js"></script>
<!--
<script type="text/javascript" src="mdb/js/bootstrap.min.js"></script>
<!--
<script type="text/javascript" src="mdb/js/mdb.js"></script>
<!--
<script type="text/javascript" src="mdb/js/compiled-4.7.1.min.js">
</script><script type="text/javascript">(function runJS()
{new WOW().init();})();</script>
</body>
</html>
views/concepts.html:
<div class="modal fade" id="addConceptModal" tabindex="-1"
role="dialog" aria-labelledby="Add a new concept"
aria-hidden="true">
<div class="modal-dialog modal-side modal-bottom-right" role="document">
<div class="modal-content">
<div class="modal-header">
<h5 class="modal-title" id="addConceptModalLabel">
Add a new concept...</h5>
<button type="button" class="close" data-dismiss="modal"
aria-label="Close">
<span aria-hidden="true">×</span>
</button>
</div>
<div class="modal-body">
<input ng-model="concept.action" class="form-control mr-sm-2"
type="text" placeholder="Action" aria-label="Action" autofocus><br />
<input ng-model="concept.entity" class="form-control mr-sm-2"
type="text" placeholder="Entity" aria-label="Action" autofocus><br />
<input ng-model="concept.desc" class="form-control mr-sm-2"
type="text" placeholder="Description (i.e. Adjectives)"
aria-label="Description (i.e. Adjectives)" autofocus><br />
<textarea ng-model="concept.answer"
class="form-control rounded-0" id="answer" rows="6"
cols="6" placeholder="Answer"></textarea><br />
<textarea ng-model="concept.url"
class="form-control rounded-0" id="answerUrl"
rows="3" cols="6" placeholder="Url"></textarea><br />
<span>Is Negative? </span>
<select ng-model="concept.negative">
<option value="false" selected>No</option>
<option value="true">Yes</option>
</select>
</div>
<div class="modal-footer">
<button type="button" class="btn btn-secondary"
data-dismiss="modal">Close</button>
<button type="button" class="btn btn-primary"
data-dismiss="modal">Save changes</button>
</div>
</div>
</div>
</div>
views/answers.html
<div class="modal fade" id="answersViewModal" tabindex="-1"
role="dialog" aria-labelledby="Answer..." aria-hidden="true">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h5 class="modal-title" id="answerViewModalLabel">Answer...</h5>
<button type="button" class="close"
data-dismiss="modal" aria-label="Close">
<span aria-hidden="true">×</span>
</button>
</div>
<div class="modal-body">
<textarea class="form-control rounded-0"
id="answerContents" rows="6" cols="6">{{answer}}</textarea><br />
<textarea class="form-control rounded-0"
id="answerUrl" rows="3" cols="6">{{url}}</textarea>
</div>
<div class="modal-footer">
<button type="button" class="btn btn-secondary"
data-dismiss="modal">Close</button>
</div>
</div>
</div>
</div>
views/updates.html
<div class="modal fade" id="conceptEditModal" tabindex="-1"
role="dialog" aria-labelledby="Edit Concept" aria-hidden="true">
<div class="modal-dialog" role="document">
<div class="modal-content" ng-controller="conceptsViewCtrl">
<div class="modal-header">
<h5 class="modal-title" id="conceptEditViewModalLabel">
Edit Concept...</h5>
<button type="button" class="close" data-dismiss="modal"
aria-label="Close">
<span aria-hidden="true">×</span>
</button>
</div>
<div class="modal-body">
<input type="hidden" name="concept_id" value="{{concept.id}}" />
<input type="text" ng-model="concept.action"
class="form-control rounded-0" value="{{concept.action}}" /><br />
<input type="text" ng-model="concept.entity"
class="form-control rounded-0" value="{{concept.entity}}" /><br />
<input type="text" ng-model="concept.desc"
class="form-control rounded-0" id="desc" value="{{concept.desc}}"><br />
<textarea ng-model="concept.answer"
class="form-control rounded-0" id="answer" rows="6"
cols="6">{{ concept.answer }}</textarea><br />
<textarea ng-model="concept.url"
class="form-control rounded-0" id="answerUrl"
rows="3" cols="6">{{concept.url}}</textarea><br />
<span>Is Negative?</span>
<select ng-model="concept.negative">
<option value="false">No</option>
<option value="true">Yes</option>
</select>
</div>
<div class="modal-footer flex-center">
<button class="btn btn-outline-danger"
data-dismiss="modal">Save</button>
<button class="btn btn-danger waves-effect" data-dismiss="modal">
Cancel</button>
</div>
</div>
</div>
</div>
views/confirm.html
<div class="modal fade" id="confirmDeleteModal"
tabindex="-1" role="dialog" aria-labelledby="exampleModalLabel" aria-hidden="true">
<div class="modal-dialog modal-sm modal-notify modal-danger" role="document">
<!--
<div class="modal-content text-center">
<!--
<div class="modal-header d-flex justify-content-center">
<p class="heading">Are you sure?</p>
</div>
<!--
<div class="modal-body">
<i class="fas fa-times fa-4x animated rotateIn"></i>
</div>
<!--
<div class="modal-footer flex-center">
<button data-ng-click="onRemoveConcept()"
class="btn btn-outline-danger" data-dismiss="modal">Yes</button>
<button class="btn btn-danger waves-effect"
data-dismiss="modal">No</button>
</div>
</div>
<!--
</div>
</div>
In this, most of the event-handling tasks are performed by Angular.js controller, providing the responsiveness to the user inputs. This controller is implemented as multiple JavaScript functions in the following HTML-document’s scripts section.
When the page is loaded into the web-browser, it instantiates the angular module object by executing the following code: var concepts = angular.module('concepts', []). After that, we define a controller and a callback function, implementing the loading data model mechanism, as well as the number of functions for handling the specific events such as sending an inquiry, adding concepts, viewing an advanced content, updating or delete concepts. Specifically, the code performing an Ajax-request to the background web-app’s service to fetch the data from semantic knowledge database is implemented at the beginning of the controller’s callback function, as follows:
$http.post("/")
.then(function (response) {
$scope.model = response.data['model'];
});
In this case, the Ajax-request is sent every time when page is loaded, by invoking $http.post(…) jQuery’s function, and the response is passed as a parameter of specific callback. Then it’s copied into the global scope variable $scope.model, that holds the data fetched from the database.
Also, the controller’s callback function contains the implementation of the number of functions handling the users input events:
$scope.onSendInquiry = function (inquiry) {
if ($("#responses").display == "block") {
$("responses").hide();
}
$http.post('/inquiry', { 'inquiry': inquiry,
'model': $scope.model }).then((results) => {
$scope.model.responses =
results["data"]["intents"].map(function (obj) {
return {
'action': obj["intent"]["action"],
'entity': obj["intent"]["ent"],
'response': obj["response"]
};
});
$("#responses").show();
$scope.scrollIntoView("#answers_renderer", 0);
});
}
$scope.onAddConceptModal = function () {
$scope.add_concept = true;
}
$scope.onViewAnswer = function (answer, url) {
$scope.answer_show = true;
$scope.answer = answer; $scope.url = url;
}
$scope.onUpdateConceptModal = function (concept) {
$scope.concept = concept;
$scope.concept_orig =
angular.copy($scope.concept);
$scope.update_concept = true;
}
$scope.onConfirmRemovalModal = function (concept_id) {
$scope.concept_id = concept_id;
$scope.confirm_removal = true;
}
$scope.onRemoveConcept = function () {
$scope.model = $scope.model.filter(function (obj) {
return obj['id'] != $scope.concept_id;
});
}
These functions handle such events as viewing a concept advanced data, adding new concepts, updating existing concepts and remove specific concepts. Also, Angular.js code contains the number of directive functions, responsible for rendering specific modals and loaded model modification:
concepts.directive('addNewConceptModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('add_concept', function (add_concept) {
element.find('.modal').modal(add_concept ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.concept = {};
scope.concept.negative = 'false';
scope.add_concept = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.model.push(scope.concept);
scope.add_concept = false;
});
});
},
templateUrl: '/concepts'
};
});
concepts.directive('answerViewModal', function () {
return {
restrict: 'E',
link: function (scope, element, attributes) {
scope.$watch('answer_show', function (answer_show) {
element.find('.modal').modal(answer_show ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.answer_show = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.answer_show = false;
});
});
},
templateUrl: '/answers'
};
});
concepts.directive('updateConceptModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('update_concept', function (update_concept) {
element.find('.modal').modal(update_concept ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.update_concept = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
scope.update_concept = false;
scope.model[scope.concept_orig.entity].entity =
scope.concept.entity;
scope.model[scope.concept_orig.action].action =
scope.concept.action;
});
});
},
templateUrl: '/modify'
};
});
concepts.directive('confirmRemovalModal', function () {
return {
restrict: 'EA',
link: function (scope, element, attributes) {
scope.$watch('confirm_removal', function (confirm_removal) {
element.find('.modal').modal(confirm_removal ? 'show' : 'hide');
});
element.on('shown.bs.modal', function () {
scope.$apply(function () {
scope.confirm_removal = true;
});
});
element.on('hidden.bs.modal', function () {
scope.$apply(function () {
$scope.model.splice($scope.concept_id, 1);
scope.confirm_removal = false;
});
});
},
templateUrl: '/confirm'
};
});
The web-application's background service code is implemented in server.js file as follows:
server.js
'use strict';
var debug = require('debug');
var express = require('express');
var path = require('path');
var favicon = require('serve-favicon');
var logger = require('morgan');
var cookieParser = require('cookie-parser');
var bodyParser = require('body-parser');
var eventSource = require("eventsource");
var morgan = require('morgan');
var SqlString = require('sqlstring');
var db = require('./database');
var nlp_engine = require('./engine');
var con_db = db.createMySqlConnection(JSON.parse(
require('fs').readFileSync('./database.json')));
var routes = require('./routes/index');
var app = express();
app.engine('html', require('ejs').renderFile);
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'html');
app.use(logger('dev'));
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: false }));
app.use(cookieParser());
app.use(express.static(path.join(__dirname, 'public')));
app.use('/', routes);
app.post('/', function (req, res) {
let query = 'SELECT * FROM `nlp-samurai_db`.concepts_view';
db.execMySqlQuery(con_db, query).then((dataset) => {
var model_html = "\0", model = [];
dataset.forEach(function (data_obj) {
data_obj["negative"] =
(data_obj["negative"] == 0) ? "false" : "true";
data_obj["desc"] =
(data_obj["desc"] == 'NULL') ? "none" : data_obj["desc"];
model.push({
'id': data_obj["concept_id"],
'action': data_obj["action"],
'entity': data_obj["entity"],
'desc': data_obj["desc"],
'negative': data_obj["negative"],
'answer': Buffer.from(data_obj["answer"]).toString(),
'url': data_obj["url"]
});
});
if ((model != undefined) && (model.length > 0)) {
res.send(JSON.stringify({ 'model': model }));
}
});
});
app.post('/inquiry', function (req, res) {
var model_html = "\0", model = [];
req.body.model.forEach(function (data_obj) {
data_obj["negative"] =
(data_obj["negative"] == "false") ? 0 : 1;
model.push({
'intent': {
'action': data_obj["action"],
'ent': data_obj["entity"],
'desc': data_obj["desc"]
},
'response': {
'answer': Buffer.from(data_obj["answer"]).toString(),
'url': data_obj["url"]
}, 'negative': data_obj["negative"]
});
});
if ((model != undefined) && (model.length > 0)) {
nlp_engine.analyze(req.body.inquiry, model).then((results) => {
res.send(results);
});
}
});
app.use(function (req, res, next) {
var err = new Error('Not Found');
err.status = 404;
next(err);
});
if (app.get('env') === 'development') {
app.use(function (err, req, res, next) {
res.status(err.status || 500);
res.render('error', {
message: err.message,
error: err
});
});
}
app.use(function (err, req, res, next) {
res.status(err.status || 500);
res.render('error', {
message: err.message,
error: {}
});
});
app.set('port', process.env.PORT || 3000);
var server = app.listen(app.get('port'), function () {
debug('Express server listening on port ' + server.address().port);
});
The essential part of this code basically relies on the implementation of two functions, receiving Ajax-requests from the application's main web-page and triggering the NLP-engine to perform the analysis:
app.post('/', function (req, res) {
let query = 'SELECT * FROM `nlp-samurai_db`.concepts_view';
db.execMySqlQuery(con_db, query).then((dataset) => {
var model_html = "\0", model = [];
dataset.forEach(function (data_obj) {
data_obj["negative"] =
(data_obj["negative"] == 0) ? "false" : "true";
data_obj["desc"] =
(data_obj["desc"] == 'NULL') ? "none" : data_obj["desc"];
model.push({
'id': data_obj["concept_id"],
'action': data_obj["action"],
'entity': data_obj["entity"],
'desc': data_obj["desc"],
'negative': data_obj["negative"],
'answer': Buffer.from(data_obj["answer"]).toString(),
'url': data_obj["url"]
});
});
if ((model != undefined) && (model.length > 0)) {
res.send(JSON.stringify({ 'model': model }));
}
});
});
The following function simply perform fetching of the data from the nlp-samurai_db database, and sends as a response the data model in JSON-string format.
app.post('/inquiry', function (req, res) {
var model_html = "\0", model = [];
req.body.model.forEach(function (data_obj) {
data_obj["negative"] =
(data_obj["negative"] == "false") ? 0 : 1;
model.push({
'intent': {
'action': data_obj["action"],
'ent': data_obj["entity"],
'desc': data_obj["desc"]
},
'response': {
'answer': Buffer.from(data_obj["answer"]).toString(),
'url': data_obj["url"]
}, 'negative': data_obj["negative"]
});
});
if ((model != undefined) && (model.length > 0)) {
nlp_engine.analyze(req.body.inquiry, model).then((results) => {
res.send(results);
});
}
});
The following function listed above performs the NLP-engine triggering, receiving the Ajax-requests from the main app's web-page and invoking the specific nlp_engine.analyze(req.body.inquiry, model) that perfoms the NLP-analysis. After the result is returned from the NLP-engine, this function sends an Ajax-response to the specific Angular controller within the main web-page.
Natural Language Process (NLP) Engine
In this sub-section, we will discuss about several of the NLP-engine's routines implementing grammar predicates parsers. Specifically, we will learn how to perform the conditional splitting of textual messages, parsing grammar predicates and retrieve intens and terms from those message, maintain the decision-making process and create and deploy semantic knowledge database.
Splitting Texts into Sentences by a Condition
The first function that was written as part of the NLP-engine is split_by_condition(...) function listed below:
function split_by_conditions(tokens, callback) {
let index = 0, substrings = [];
while (index < tokens.length) {
if ((callback(tokens[index], index) == true) || (index == 0)) {
let prep_n = index, is_prep = false; index++;
while ((index < tokens.length) && (is_prep == false))
if (!callback(tokens[index], index)) index++;
else is_prep = true;
substrings.push(tokens.slice(prep_n, index));
}
}
if ((substrings != undefined)) {
return substrings.filter(function (sub) { return sub != ''; });
}
}
This function is using the following algorithm to perform the conditional splitting. It iterates through an array of tokens and for each token, executes a callback function passed as one of its arguments. Within the callback function, we're performing a conditional check if the current token satisfies a certain condition. If the result of condition checking is "true", then it finds another token satisfying the same condition, located at a certain position in the subset of suceeding tokens. Finally, the rest of tokens located between the first and second tokens satisfying the condition, are extracted and appended to the array.
Implementing Grammar Predicates Parsers
The entire NLP-analysis basically relies on performing the grammar predicates parsing as we've already discussed in the background chapter of this article. The code implementing these parsers is listed below:
async function parse_verb_plus_noun(features, pos, concepts) {
return new Promise(async (resolve, reject) => {
var nouns = pos['nouns'];
var verbs = pos['verbs'];
var negatives = get_negatives(features);
var intents = [];
for (let index = 0; index < features.length; index++) {
if ((verbs.includes(features[index]) == true) &&
(negatives.includes(features[index]) == false)) {
let noun_pos = index + 1;
while (noun_pos < features.length) {
if (nouns.includes(features[noun_pos]) == true) {
intents.push({
'pos': [index, noun_pos],
'intent': {
'action': features[index],
'ent': features[noun_pos],
'negative': false
}
});
}
noun_pos++
}
}
}
for (let index = 0; index < intents.length; index++) {
var neg_pos = intents[index]['pos'][0];
while ((neg_pos >= 0) && !negatives.includes(
features[neg_pos])) neg_pos--;
if ((neg_pos != -1)) {
intents[index]['intent']['negative'] = true;
}
}
if ((intents != undefined)) {
resolve(intents.map((obj) => { return obj['intent']; }));
} else reject(0);
});
}
async function parse_noun_plus_verb(features, pos, concepts) {
return new Promise(async (resolve, reject) => {
var nouns = pos['nouns'];
var verbs = pos['verbs'];
var negatives = get_negatives(features);
var intents = [];
for (let index = 0; index < features.length; index++) {
if ((nouns.includes(features[index]) == true)) {
let verb_pos = index + 1;
while (verb_pos < features.length) {
if (verbs.includes(features[verb_pos]) == true) {
var neg_pos = verb_pos - 1, is_negative = false;
while (neg_pos >= index && !is_negative) {
is_negative = (negatives.includes
(features[neg_pos--]) == true);
}
intents.push({
'intent': {
'action': features[verb_pos],
'ent': features[index],
'negative': is_negative
}
});
}
verb_pos++;
}
}
}
if ((intents != undefined)) {
resolve(intents.map((obj) => { return obj['intent']; }));
} else reject(0);
});
}
async function parse_noun_plus_verb_rev(features, pos, concepts) {
return new Promise(async (resolve, reject) => {
var nouns = pos['nouns'];
var verbs = pos['verbs'];
var negatives = get_negatives(features);
var intents = [], verb_pos_prev = 0;
for (let index = 0; index < features.length; index++) {
if ((nouns.includes(features[index]) == true)) {
let verb_pos = index - 1, is_verb = false;
while (verb_pos >= verb_pos_prev && !is_verb) {
if (verbs.includes(features[verb_pos]) == true) {
var neg_pos = verb_pos - 1, is_negative = false;
while (neg_pos >= 0 && !is_negative) {
is_negative = (negatives.includes(
features[neg_pos]) == true);
if (verbs.includes(features[neg_pos]) == true) {
is_negative = false; break;
}
neg_pos--;
}
intents.push({
'intent': {
'action': features[verb_pos],
'ent': features[index],
'negative': is_negative
}
});
is_verb = true;
}
verb_pos--;
}
verb_pos_prev = verb_pos + 1;
}
}
if ((intents != undefined)) {
resolve(intents.map((obj) => { return obj['intent']; }));
} else reject(0);
});
}
async function parse_noun_plus_suffix_noun(features, pos, concepts) {
return new Promise(async (resolve, reject) => {
var nouns = pos['nouns'];
var verbs = pos['verbs'];
var negatives = get_negatives(features);
var intents = [];
for (let index = 0; index < features.length; index++) {
if ((nouns.includes(features[index]) == true)) {
var noun_pos = 0;
while (noun_pos < features.length) {
var is_suffix_noun = noun_suffixes.filter(function (suffix) {
return features[noun_pos].match('\\' +
suffix + '$') != undefined ||
features[noun_pos].match('\\' + suffix + 's$') != undefined;
}).length > 0;
if ((is_suffix_noun == true) &&
(nouns.includes(features[noun_pos]) == true)) {
intents.push({
'intent': {
'action': features[index],
'ent': features[noun_pos],
'negative': false
}
});
}
noun_pos++;
}
}
}
if ((intents != undefined)) {
resolve(intents.map((obj) => { return obj['intent']; }));
} else reject(0);
});
}
Maintaining Decision-Making Process
The decision-making process basically relies on executing the following code:
module.exports = {
analyze: async function (document, concepts) {
return new Promise(async (resolve, reject) => {
await normalize(document, concepts).then(async (results) => {
let index = 0, nouns_suggs = [];
while (index < results['tokens'].length) {
const word_ps = new NlpWordPos();
var wd_stats = words_stats(results['tokens'][index]);
await word_ps.getPOS(results['tokens'][index]).then((details) => {
var nouns_stats = wd_stats.filter(function (stats) {
return details['nouns'].includes(stats['word']);
});
var nouns_prob_avg = nouns_stats.reduce((acc, stats) => {
return acc + stats['prob'];
}, 0) / nouns_stats.length;
nouns_suggs.push(nouns_stats.filter(function (stats) {
return stats['prob'].toFixed(4) >=
nouns_prob_avg.toFixed(4);
}));
});
index++;
}
var nouns = results['details']['nouns'];
var verbs = results['details']['verbs'];
var adjectives = results['details']['adjectives'];
var adverbs = results['details']['adverbs'];
var intents = results['tokens'], sentences = [],
intents_length = results['tokens'].length;
for (let index = 0; index < intents_length; index++) {
sentences = sentences.concat(split_by_conditions
(intents[index], function (intent) {
var is_entity = intents[index].filter(function (intent) {
return prep_list5.filter(function (entity) {
return intent.match('^' + entity);
}).length > 0;
}).length > 0;
return prep_list1.filter(function (value) {
return value == intent;
}).length > 0 && !is_entity;
}));
}
if (sentences.length > 0) {
intents = sentences;
}
intents_length = intents.length; sentences = [];
for (let index = 0; index < intents_length; index++) {
var intent_pos = 0;
sentences = sentences.concat
(split_by_conditions(intents[index], function (intent, n) {
let neg_pos = n - 1, has_negative = false;
while ((neg_pos >= intent_pos) && (!has_negative)) {
has_negative = negatives.includes(intents[index][neg_pos]);
if (has_negative == false)
neg_pos--;
}
var dup_count = intents[index].filter(function (token) {
return token == intent;
}).length;
var split = ((dup_count >= 2) &&
(!nouns.includes(intent) &&
!verbs.includes(intent) &&
!adjectives.includes(intent) &&
!adverbs.includes(intent) &&
!prep_list1.includes(intent) &&
!prep_list2.includes(intent) &&
!prep_list3.includes(intent) &&
!prep_list4.includes(intent) &&
!prep_list5.includes(intent)));
if (split == true) {
intent_pos = n;
}
return (split == true) && (has_negative == false);
}));
}
if (sentences.length > 0) {
intents = sentences;
}
var entity_intents = intents;
intents_length = intents.length; sentences = [];
for (let index = 0; index < intents_length; index++) {
sentences = sentences.concat
(split_by_conditions(intents[index], function (intent) {
return prep_list3.filter(function (value) {
return value == intent;
}).length > 0;
}));
}
if (sentences.length > 0) {
intents = sentences;
}
intents = intents.map(function (intents) {
return intents.filter(function (intent) {
return prep_list3.filter(function (prep) {
return prep == intent;
}).length == 0;
})
});
intents_length = intents.length; sentences = [];
for (let index = 0; index < intents_length; index++) {
sentences = sentences.concat(split_by_conditions
(intents[index], function (intent) {
var is_entity = intents[index].filter(function (intent) {
return prep_list5.filter(function (entity) {
return intent.match('^' + entity);
}).length > 0;
}).length > 0;
return negatives.filter(function (value) {
return value == intent;
}).length > 0 && !is_entity;
}));
}
if (sentences.length > 0) {
intents = sentences;
}
intents_length = intents.length; sentences = [];
for (let index = 0; index < intents_length; index++) {
sentences = sentences.concat(split_by_conditions(intents[index],
function (intent, n) {
let split = false;
var is_prep = prep_list2.filter(
function (value)
{ return value == intent; }).length > 0;
if (is_prep == true) {
if ((n > 0) && (n < intents[index].length - 1)) {
var is_noun_left = nouns.filter(function (noun) {
return noun == intents[index][n - 1];
}).length > 0;
var is_noun_right = nouns.filter(function (noun) {
return noun == intents[index][n + 1];
}).length > 0;
var is_verb_left = verbs.filter(function (verb) {
return verb == intents[index][n - 1];
}).length > 0;
var is_verb_right = verbs.filter(function (verb) {
return verb == intents[index][n + 1];
}).length > 0;
if ((prep_list4.includes(intents[index][n - 1])) ||
(prep_list4.includes(intents[index][n + 1]))) {
split = false;
}
else if ((is_noun_left = true) &&
(is_noun_right == true)) {
split = false;
}
else if (((is_noun_left == true) &&
(is_verb_right == true)) ||
((is_verb_left == true) &&
(is_noun_right == true))) {
split = (intent == 'or') ? false : true;
}
else {
var is_adj_left = adjectives.filter
(function (adjective) {
return adjective == intents[index][n - 1];
}).length > 0;
var is_adj_right = adjectives.filter
(function (adjective) {
return adjective == intents[index][n + 1];
}).length > 0;
var is_adv_left =
adverbs.filter(function (adverb) {
return adverb == intents[index][n - 1];
}).length > 0;
var is_adv_right = adverbs.filter
(function (adverb) {
return adverb == intents[index][n + 1];
}).length > 0;
var is_negative_left =
negatives.includes(intents[index][n - 1]);
var is_negative_right =
negatives.includes(intents[index][n + 1]);
if (intent == 'or') {
split = (!(is_adj_left &&
is_adj_right)) ? false : true;
split = (!(is_adv_left && is_adv_right)) ?
false : true;
split = ((is_negative_left == true ||
is_negative_right == true)) ? true : false;
}
else if (intent == 'and') {
if (!(is_noun_left && is_noun_right)) {
split = true;
}
}
}
return split;
}
}
}));
}
if (sentences.length > 0) {
intents = sentences;
}
intents = intents.map(function (intents) {
var is_entity = intents.filter(function (intent) {
return prep_list5.filter(function (entity) {
return intent.match('^' + entity);
}).length > 0;
}).length > 0;
return (is_entity == false) ?
intents.filter(function (value) {
return nouns.includes(value) ||
verbs.includes(value) ||
negatives.includes(value);
}) : intents;
}).filter(function (intents) {
return intents.length > 0;
});
var predicates = [];
for (let index = 0; index < intents.length; index++) {
if (intents[index].length > 1) {
await parse_verb_plus_noun(intents[index],
results['details'], concepts).then((results) => {
if (results != undefined && results.length > 0) {
predicates = predicates.concat(results);
}
});
}
}
for (let index = 0; index < entity_intents.length; index++) {
if (entity_intents[index].length > 1) {
await parse_noun_plus_verb(entity_intents[index],
results['details'], concepts).then((results) => {
predicates = predicates.concat(results);
});
}
}
for (let index = 0; index < entity_intents.length; index++) {
if (entity_intents[index].length > 1) {
await parse_noun_plus_suffix_noun(entity_intents[index],
results['details'], concepts).then((results) => {
predicates = predicates.concat(results);
});
}
}
for (let index = 0; index < entity_intents.length; index++) {
if (entity_intents[index].length > 1) {
await parse_noun_plus_verb_rev(entity_intents[index],
results['details'], concepts).then((results) => {
if (results != undefined && results.length > 0) {
predicates = predicates.concat(results);
}
});
}
}
var intents_results = [];
for (let i = 0; i < predicates.length; i++) {
for (let j = 0; j < concepts.length; j++) {
var is_similar = false;
var is_negative1 = predicates[i]['negative'];
var is_negative2 = concepts[j]['negative'];
var action1 = predicates[i]['action'];
var action2 = concepts[j]['intent']['action'];
var subject1 = predicates[i]['ent'];
var subject2 = concepts[j]['intent']['ent'];
if (is_negative1 == is_negative2) {
if ((action1 == action2) && (subject1 == subject2)) {
is_similar = true;
}
}
if (is_similar == true) {
intents_results.push(concepts[j]);
}
}
}
if (intents_results.length > 0) {
resolve({
'suggestions': nouns_suggs,
'intents': Array.from(new Set(intents_results))
});
} else reject(0);
});
});
},
}
The following code performs the NLP-analysis in the number of stages including the normalization, grammar parsing and decision-making. The code for normalization is listed below:
async function normalize(sentence, concepts) {
return new Promise(async (resolve, reject) => {
const word_ps = new NlpWordPos();
var tokens = sentence.replace(
new RegExp(/[.!?]/gm), '%').split(/[ %]/gm);
var tokens = split_by_conditions(tokens,
function (token) { return token == ''; });
tokens = tokens.map(function (tokens) {
return tokens.filter(function (token) { return token != ''; });
});
tokens = tokens.map(function (tokens) {
return tokens.map(function (token) {
return token.replace(/,$/gm, '');
});
});
var words = sentence.split(/[ ,]/gm).map(function (word) {
return word.replace(new RegExp(/[.!?]/gm), '');
}).filter(function (word) {
return word != '';
});
await word_ps.getPOS(sentence).then((details) => {
var actions = Array.from(new Set(
concepts.map(function (class_obj) {
return class_obj['intent']['action'];
})));
if (actions.length > 0) {
details['verbs'] = actions;
}
var entities = Array.from(new Set(
concepts.map(function (class_obj) {
return class_obj['intent']['ent'];
})));
if (entities.length > 0) {
details['nouns'] = entities;
details['nouns'] = details['nouns'].concat(
details['verbs'].filter(function (verb) {
return noun_suffixes.filter(function (suffix) {
return verb.match('\\' + suffix + '$') != undefined ||
verb.match('\\' + suffix + 's$') != undefined;
}).length > 0 || adj_suffixes.filter(function (suffix) {
return verb.match('\\' + suffix + '$') != undefined ||
verb.match('\\' + suffix + 's$') != undefined;
}).length > 0;
}));
}
tokens = tokens.map(function (tokens) {
return tokens.filter(function (value) {
return value.length > 2 ||
details['verbs'].includes(value) ||
prep_list2.includes(value) || prep_list3.includes(value) ||
prep_list5.includes(value);
})
});
if (tokens != undefined && tokens.length > 0) {
resolve({
'tokens': tokens, 'details': details,
'stats': { 'words': words,
'count': Array.from(new Set(words)).length }
});
} else reject(0);
});
});
}
These two main functions are essential for the entire NLP-analysis process.
Creating Semantic Knowledge Database
The final aspect that we will spotlight in the "Using the Code" chapter is creating a deploying semantic knowledge database using MySQL. The following database is the relational database, which SQL-script is listed below:
CREATE TABLE `actions` (
`action_id` int(11) NOT NULL AUTO_INCREMENT,
`action` varchar(255) NOT NULL,
PRIMARY KEY (`action_id`)
);
CREATE TABLE `entities` (
`entity_id` int(11) NOT NULL AUTO_INCREMENT,
`entity` varchar(255) NOT NULL,
PRIMARY KEY (`entity_id`)
);
CREATE TABLE `answers` (
`answer_id` int(11) NOT NULL AUTO_INCREMENT,
`answer` blob NOT NULL,
`url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`answer_id`)
);
CREATE TABLE `concepts` (
`concept_id` int(11) NOT NULL AUTO_INCREMENT,
`action_id` int(11) NOT NULL,
`entity_id` int(11) NOT NULL,
`desc` text,
`negative` int(11) NOT NULL,
`answer_id` int(11) NOT NULL,
PRIMARY KEY (`concept_id`)
)
CREATE VIEW `concepts_view` AS SELECT
1 AS `concept_id`,
1 AS `action`,
1 AS `entity`,
1 AS `desc`,
1 AS `negative`,
1 AS `answer`,
1 AS `url`;
The complete code that could be used for the database maintainance and data import contained in model/nlp-samular_db.sql.
Points of Interest
In this article, we've introduced an example of the rule-based natural language processing (NLP) engine. *BUT* The real work on the natural processing engine (NLP) development has only just begun :). It will be rather interesting to use the other strategies such as replacing the algorithm-based decision-making process with AI or machine learning based on artificial neural networks or modern classifier algorithms.
History
- 22nd February, 2019 - Final revision of this article published

