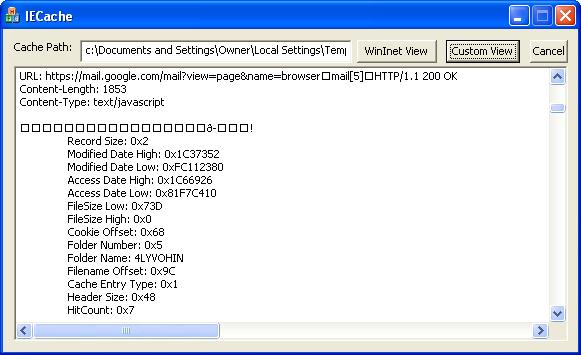
Introduction
There are two basic ways to read the cache files that Internet Explorer produces. One method is to use the WinInet cache functions to do the job. The other is to use a custom built solution to read the cache files. There are no clear advantages to using one method over the over, except perhaps that one is Microsoft based, and the other is not. In this article, I will present both methods of reading the cache.
Cache Structure
The cache has a 28 byte header tag that identifies the cache version: Client UrlCache MMF Ver 5.2. At index 0x48 from the file beginning is a two byte value containing the number of folders. Immediately following are 8 byte folder names, followed by a 4 byte value (unknown what it is for). From the end of the folder list, up until about 0x6000, is a bunch of unknown data. Then comes entries which typically are one of four possible types: Leak, Redr, URL, and Hash. It is unknown what the Hash entries are for, so we just read them, discard them, then continue on. The Leak and URL entries appear to have the same structure.
typedef struct UrlEntry
{
TCHAR szRecordType[4];
DWORD dwRecordSize;
FILETIME modifieddate;
FILETIME accessdate;
DWORD dwUnsure1;
DWORD dwUnsure2;
DWORD wFileSizeLow;
DWORD wFileSizeHigh;
BYTE uBlank[8];
#ifdef __IE40__
DWORD dwExtra;
#endif
DWORD uSame;
DWORD dwCookieOffset;
BYTE uFolderNumber;
BYTE unknown[3];
DWORD uFilenameOffset;
DWORD dwCacheEntryType;
DWORD unSure;
DWORD dwHeaderSize;
DWORD dwUnknown;
DWORD dwUnsure3;
DWORD wHitCount;
DWORD dwUseCount;
DWORD dwData2;
BYTE uMiscExtraData[8];
BYTE lpText[1];
}URLENTRY, *LPURLENTRY;
The Redr has the following structure:
typedef struct RedrEntry
{
TCHAR szRecordType[4];
DWORD dwRecordSize;
FILETIME dwNotSur;
BYTE lpWebUrl[1];
}REDRENTRY, *LPREDRENTRY;
And the Hash structure is:
typedef struct HashEntry
{
TCHAR szRecordType[4];
DWORD dwRecordSize;
BYTE lpHashText[1];
}HASHENTRY,*LPHASHENTRY;
This continues until the end of the file. Each URL size is in terms of blocks. One data block is 0x80 bytes. Most are two or three blocks long. They do not appear to be ordered by type, perhaps by date, but I have not looked that deeply into them.
Using the code
The first way to read the cache files is using custom built functions to read the file structures. The functions to accomplish this are:
HANDLE OpenCacheFile(TCHAR* szCacheFilePath);
WORD GetCacheFolderNum(HANDLE hFile);
void GetCacheFolders(HANDLE hFile,
WORD wFolders,LPCACHEFOLDERS& pFolders);
CString GetFolderName(LPCACHEFOLDERS pFolders, WORD wFolderNum);
DWORD GetFirstCacheEntry(HANDLE hFile,DWORD* lpdwOffset);
DWORD GetNextCacheEntry(HANDLE hFile,DWORD* lpdwOffset);
void ReadCacheEntry(HANDLE hFile,
DWORD* lpdwOffset, LPURLENTRY& lpData);
void ReadCacheLeakEntry(HANDLE hFile,
DWORD* lpdwOffset, LPLEAKENTRY& lpData);
void ReadCacheRedrEntry(HANDLE hFile,
DWORD* lpdwOffset, LPREDRENTRY& lpData);
void ReadCacheHashEntry(HANDLE hFile,
DWORD* lpdwOffset, LPHASHENTRY& lpData);
The code to use and process using this method is a bit complicated. It includes looping through the file, calling GetNextCacheEntry, and then a ReadCache*Entry call. The GetNext call merely moves the file pointer to the correct position to read the next entry, and returns the entry type. While, the Read calls actually read the data, fill the structure, and set the pointer to the end of the block. You could call these with arbitrary file positions but they would quickly break if you call them with incorrect file positions. An example of using these functions is:
HCURSOR hCur = SetCursor(LoadCursor(NULL, IDC_WAIT));
CString str;
m_path.GetWindowText(str);
HANDLE hFile =
OpenCacheFile(str.GetBuffer(str.GetLength()));
str = _T("This is a custom View ")
_T("reading bytes from the DAT files.\r\n");
m_test.SetWindowText(str);
WORD wNum = GetCacheFolderNum(hFile);
if (wNum == 0)
{
return;
}
CacheFolders* pFolders,*p;
GetCacheFolders(hFile,wNum,pFolders);
for (int n = 1; n <= wNum; n++)
{
CacheFolder lpFolder = (pFolders->folders[n-1]);
str.Format("Folder: %s\r\n",lpFolder.szFolderName);
}
DWORD dwOffset = 0;
int nEntries = 50;
DWORD dwType = GetFirstCacheEntry(hFile,
&dwOffset);
do
{
if ((dwOffset >= 0xB5C00))
dwType = dwType;
if (dwType == URL_ID)
{
URLENTRY *url;
ReadCacheEntry(hFile,&dwOffset,url);
CoTaskMemFree(url);
}
else if (dwType == LEAK_ID)
{
LEAKENTRY *url;
ReadCacheLeakEntry(hFile,&dwOffset,url);
CoTaskMemFree(url);
}
else if (dwType == REDR_ID)
{
REDRENTRY *url;
ReadCacheRedrEntry(hFile,&dwOffset,url);
CoTaskMemFree(url);
}
else if (dwType == HASH_ID)
{
HASHENTRY *url;
ReadCacheHashEntry(hFile,&dwOffset,url);
CoTaskMemFree(url);
}
dwType = GetNextCacheEntry(hFile,&dwOffset);
}
while ((nEntries-- >= 0) && (dwType != 0));
::CoTaskMemFree(pFolders->folders);
::CoTaskMemFree((void*)pFolders);
CloseHandle(hFile);
SetCursor(hCur);
Using WinInet to read the cache
The other method to reading the cache is using the WinInet functions. This is a rather simple method, and it returns pretty much the same information. A few function calls are needed but they can easily be wrapped into two functions. The first is to get the first cache entry, the next to get each subsequent entry. These functions do not appear to return results that are in the same order as the information in the file. And they do not allow you to read data from a location other than the default Internet Explorer cache. The two functions are:
HANDLE GetFirstInetCacheEntry(LPINTERNET_CACHE_ENTRY_INFO
lpCacheEntry, DWORD &dwEntrySize);
BOOL GetNextInetCacheEntry(HANDLE &hCacheDir,
LPINTERNET_CACHE_ENTRY_INFO lpCacheEntry,
DWORD &dwEntrySize);
And a sample of using them is:
LPINTERNET_CACHE_ENTRY_INFO lpCacheEntry;
DWORD MAX_CACHE_ENTRY_INFO_SIZE=4096;
DWORD dwEntrySize=MAX_CACHE_ENTRY_INFO_SIZE;
HANDLE hCacheDir;
int nCount=0;
lpCacheEntry =
(LPINTERNET_CACHE_ENTRY_INFO) new char[dwEntrySize];
lpCacheEntry->dwStructSize = dwEntrySize;
hCacheDir = GetFirstInetCacheEntry(lpCacheEntry,dwEntrySize);
nCount++;
do
{
dwEntrySize = MAX_CACHE_ENTRY_INFO_SIZE;
if (!GetNextInetCacheEntry(hCacheDir,
lpCacheEntry,dwEntrySize))
break;
nCount++;
}
while (nCount < 100);
delete [] lpCacheEntry;
FindCloseUrlCache(hCacheDir);
History
- v1.0 - Tested and worked fine with IE4 using Win98 and VS 6.0. Then I got XP and .NET 2003, and it would not work anymore. So I updated the code to work with IE6, XP, and .NET 2003. I do not have any other system, so I can not test on other platforms.

