Introduction
In some cases, you need to know what the best codepage (encoding) is to either transfer text over the internet or store it in a text file. One could argue that Unicode always does the trick but I needed the most efficient (byte saving) way to transfer data.
Detecting a code page from text is a very tricky task. But luckily, Microsoft provides the MLang API, in which the IMultiLang3 interface is used for outbound encoding detection.
Similarly, the IMultiLang2 interface has a function to detect the encoding of an incoming byte array. This is very handy for codepage detection of text stored in files or for text that needs to be sent over the internet.
The EncodingTools class offers some easy-to-use functions to determine the best encoding for different scenarios.
Background
The Problem
I started this along with another component that constructs MIME conformant emails. The body of the email is passed as String. The user had to provide the charset to use for the Transfer-Encoding by hand. This is fine as long as you know the target character set or always assume Unicode. But it is definitely not a good solution if you have an end-user GUI application (most users do not even know what an "encoding" is).
I wondered if it is possible to detect the best encoding from the given text.
The Dirty Hack Attempt
My first attempt was a simple brute-force attack:
- Built a list of suitable encodings (only iso-codepages and unicode)
- Iterate over all considered encodings
- Encode the text using this encoding
- Encode it back to Unicode
- Compare the results for errors
- If no errors remember the encoding that produced the fewest bytes
This is not only ugly, it does not even work properly. All single byte encodings are binary equal in their encoding result. The codepage is only used to map single bytes to the correct character for display.
So this method can only distinguish between ASCII (7bit), single byte (8bit) and the different Unicode flavors (UTF-7, UTF8, Unicode, etc.).
Finding Something Better
Then I remembered the IMultiLang2.DetectInputCodepage method that was introduced along with Internet Explorer 5.0. This method detects the encoding used in a text (used by Internet Explorer to do automatic codepage detection if the header is missing from a page). Even this was not suitable for my problem, and I wondered if there had been development since version 5.0. A wrapper function to the DetectInputCodepage is provided in the EncodingTools class.
Internet Explorer 5.5 introduced a new interface exported from the MLang DLL: IMultiLang3. This is what MSDN says about this interface:
This interface extends IMultiLanguage2 by adding outbound text detection functionality to it.
Wow! This sounded more than promising! The interface has only two methods:
DetectOutboundCodePage (for strings) DetectOutboundCodePageInIStream (for streams)
I chose to use the first one.
Using MLang
The MLang.dll is in the Windows\system32 directory. Along some exported functions, it provides some COM classes but does not contain a typelibrary. So the easy way (Add Reference in Visual Studio) did not work.
The MLang.idl is part of the Platform SDK and can be found in the include directory.
To create an assembly from the IDL file, use the following commands from the Visual Studio Command Prompt:
c:\temp\>midl MLang.idl
C:\temp>midl MLang.idl > null
Microsoft (R) 32b/64b MIDL Compiler Version 6.00.0366
Copyright (c) Microsoft Corporation 1991-2002. All rights reserved.
MLang.idl
unknwn.idl
wtypes.idl
basetsd.h
guiddef.h
oaidl.idl
objidl.idl
oaidl.acf
C:\temp>tlbimp mlang.tlb /silent
The result of those two commands is a brand new Assembly named MultiLanguage.dll.
Using Lutz Roeder's and Reflector I had a look at the signature:
MethodImpl(MethodImplOptions.InternalCall,
MethodCodeType=MethodCodeType.Runtime)]
void DetectOutboundCodePage([In] uint dwFlags,
[In, MarshalAs(UnmanagedType.LPWStr)] string lpWideCharStr,
[In] uint cchWideChar,
[In] ref uint puiPreferredCodePages,
[In] uint nPreferredCodePages,
[In] ref uint puiDetectedCodePages,
[In, Out] ref uint pnDetectedCodePages,
[In] ref ushort lpSpecialChar);
I was not so happy with the ref uint for the puiPreferredCodePages and puiDetectedCodePages parameters. Also, a typed enum for the dwFlags was missing.
So I first exported the generated assembly to C# source code and then changed it a little:
[Flags]
public enum MLCPF
{
MLDETECTF_MAILNEWS = 0x0001,
MLDETECTF_BROWSER = 0x0002,
MLDETECTF_VALID = 0x0004,
MLDETECTF_VALID_NLS = 0x0008,
MLDETECTF_PRESERVE_ORDER = 0x0010,
MLDETECTF_PREFERRED_ONLY = 0x0020,
MLDETECTF_FILTER_SPECIALCHAR = 0x0040,
MLDETECTF_EURO_UTF8 = 0x0080
}
[MethodImpl(MethodImplOptions.InternalCall,
MethodCodeType=MethodCodeType.Runtime)]
void DetectOutboundCodePage([In] MLCPF dwFlags,
[In, MarshalAs(UnmanagedType.LPWStr)] string lpWideCharStr,
[In] uint cchWideChar,
[In] IntPtr puiPreferredCodePages,
[In] uint nPreferredCodePages,
[In] IntPtr puiDetectedCodePages,
[In, Out] ref uint pnDetectedCodePages,
[In] ref ushort lpSpecialChar);
Then I added the source files to my project (no more MultiLanguage.dll assembly required).
Using IMultiLanguage3::DetectOutboundCodePage
Getting an instance of COM class implementing IMultiLanguage3 is straightforward:
MultiLanguage.IMultiLanguage3 multilang3 = new
MultiLanguage.CMultiLanguageClass();
if (multilang3 == null)
throw new System.Runtime.InteropServices.COMException(
"Failed to get IMultilang3");
The next thing is to fill the parameters.
The first parameter, dwFlags, is a combination of the tagMLCPF flags. I chose always to set the MLDETECTF_VALID_NLS because the result will be used for conversion.
The MLDETECTF_PRESERVE_ORDER and MLDETECTF_PREFERRED_ONLY are used depending on the parameters passed to my detection method.
The next two parameters (lpWideCharStr and cchWideChar) are simply the sting passed for detection and its length.
With the next two parameters (puiPreferredCodePages and nPreferredCodePages), the detection can be limited to a subset of all codepages. This is very useful if you only want to return a certain subset of codepages.
The last three parameters contain the result of detection after the method has completed successfully.
So the actual call looks like this:
uint[] preferedEncodings;
int[] resultCodePages = new int[preferedEncodings.Length];
multilang2.DetectInputCodepage(options,0, ref input[0], ref srcLen,
ref detectedEncdings[0], ref scores);
if (scores > 0)
{
for (int i = 0; i < scores; i++)
{
result.Add(Encoding.GetEncoding((int)detectedEncdings[i].nCodePage));
}
}
Finally the COM object should be freed.
Marshal.FinalReleaseComObject(multilang3);
Using IMultiLanguage2::DetectInputCodepage
After being able to choose the best encoding to send text over the internet, or save it to a stream, the next task was to detect the best encoding for incoming text if the sender (or storer) did not choose the best encoding.
The DetectInputCodepage has (at least) two practical uses. By default, Windows stores text files in the current default (UI) Encoding. For example, on my system this is "Windows-1252". A user from Russia will write text using "Windows-1251". Both codepages are singlebyte and do not have any preamble. So a text file will not contain any information about the used codepage.
So if you open a text file containing text created with codepage that is different than the current UI code page, a StreamReader will read the text as if it was stored in the UI's current codepage. (The encoding detection of the StreamReader is mostly a preamble check. So it will fail for almost any non-Unicode files (or those Unicode files without BOM.)
Most characters outside of the common ASCII charset will be displayed incorrectly.
This is where the DetectInputCodepage comes in handy. Its accuracy is not 100% but it is definitely better than the one from the StreamReader.
In the demo application, you can double click on an encoding to test which method has the better result (see "Testing the DetectInputCodepage performance" below).
The other practical use is to detect the encoding of emails from badly implemented mime mailers. Some wired mailers send emails in 8-bit encoding without specifying any characterset in the header. In this case, DetectInputCodepage can help a lot.
As for the DetectOutboundCodePage method, I change the method signature a little and add the MLDETECTCP enumeration. The resulting code looks like this:
public enum MLDETECTCP {
MLDETECTCP_NONE = 0,
MLDETECTCP_7BIT = 1,
MLDETECTCP_8BIT = 2,
MLDETECTCP_DBCS = 4,
MLDETECTCP_HTML = 8,
MLDETECTCP_NUMBER = 16
}
[MethodImpl(MethodImplOptions.InternalCall,
MethodCodeType=MethodCodeType.Runtime)]
void DetectInputCodepage([In] MLDETECTCP flags, [In] uint dwPrefWinCodePage,
[In] ref byte pSrcStr, [In, Out] ref int pcSrcSize,
[In, Out] ref DetectEncodingInfo lpEncoding,
[In, Out] ref int pnScores);
The usage of the function is almost identical to the DetectOutboundCodePage described earlier.
int maxEncodings;
int srcLen = input.Length;
int scores = detectedEncdings.Length;
MultiLanguage.MLDETECTCP options = MultiLanguage.MLDETECTCP.MLDETECTCP_NONE;
multilang2.DetectInputCodepage(options,0, ref input[0], ref srcLen,
ref detectedEncdings[0], ref scores);
if (scores > 0)
{
for (int i = 0; i < scores; i++)
{
result.Add(Encoding.GetEncoding((int)detectedEncdings[i].nCodePage));
}
}
My first tests were not that promising. I always had a COMExcpetion with E_FAIL thrown when I tried to detect a codepage.
The DetectInputCodepage will fail on texts that are too short, or that do not have BOM (Byte Order Mask / Encoding Preamble) prefixed data. There are two kinds of failures. If the input data is very short (less than 60 bytes), there is a good chance that the wrong codepage will be detected. Below 200 bytes, there is a good chance that DetectInputCodepage will return E_FAIL, because it could not decide which codepage to use. For the latter problem, I implemented a nasty workaround. I simply multiplied the input data up to 256 bytes. This seems to return reasonable results even for short strings.
if (input.Length < 256)
{
byte[] newInput = new byte[256];
int steps = 256 / input.Length;
for (int i = 0; i < steps; i++)
Array.Copy(input, 0, newInput, input.Length * i, input.Length);
int rest = 256 % input.Length;
if (rest > 0)
Array.Copy(input, 0, newInput, steps * input.Length, rest);
input = newInput;
}
Wrapping It All Up
I decided to create a static class to provide access to the DetectOutboundCodePage and DetectInputCodepage methods. It has some public methods that offer different levels of abstraction.
Here are the six high-level methods that should cover most of the usage scenarios:
GetMostEfficientEncoding GetMostEfficientEncodingForStream DetectInputCodepage ReadTextFile OpenTextFile OpenTextStrem
It also has three public static arrays of predefined codepage sets:
PreferedEncodings PreferedEncodingsForStream AllEncodings
These arrays contain the codepages in the order that return the best result, but not in the natural sort order.
Testing the DetectInputCodepage Performance
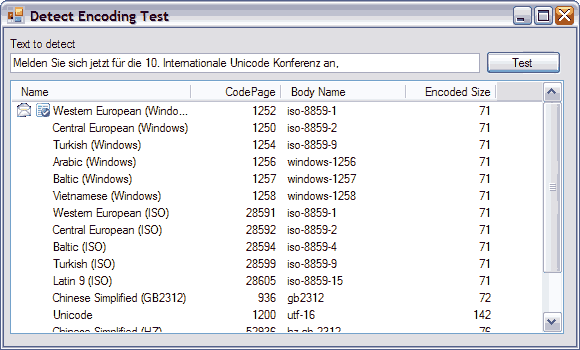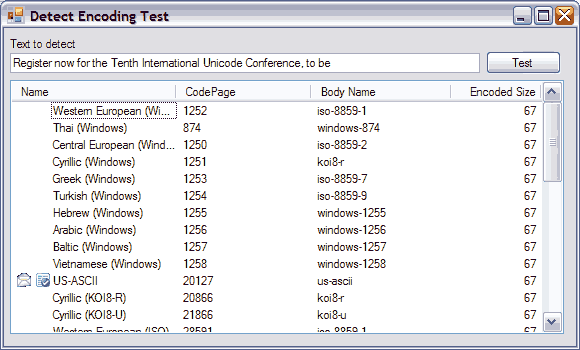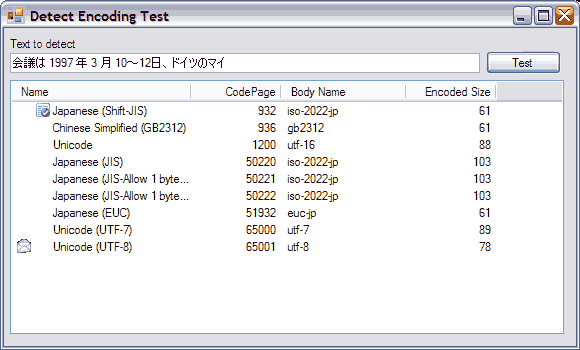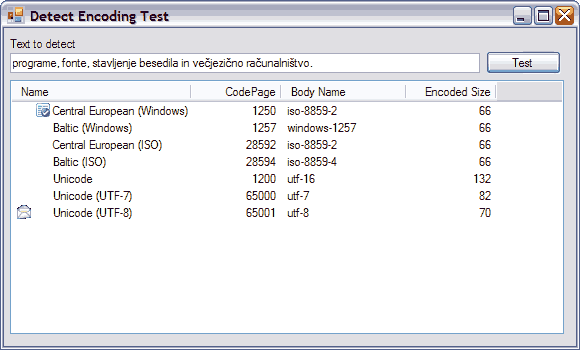
The screenshot below shows a comparison of the StreamReader encoding detection and the EncodingTools detection. The sample texts come from Unciode.org.

All the samples were detected correctly.
Using the EncodingTools Class
The following code snippets show how to use the EncodingTools class.
Outgoing Encoding
Detect best encoding for a Stream
private void SaveToStream(string text, string path)
{
Encoding enc = EncodingTools.GetMostEfficientEncodingForStream(text);
using (StreamWriter sw = new StreamWriter(path, false, enc))
sw.Write(text);
}
Detect best encoding for an email body
private void SaveToAsEmail(string text, string path)
{
Encoding enc = EncodingTools.GetMostEfficientEncoding(text);
using (StreamWriter sw = new StreamWriter(path, false, Encoding.ASCII))
{
sw.WriteLine("Subject: test");
sw.WriteLine("Transfer-Encoding: 7bit");
sw.WriteLine(
"Content-Type: text/plain;\r\n\tcharset=\"{0}\"",
enc.BodyName);
sw.WriteLine("Content-Transfer-Encoding: base64");
sw.WriteLine();
sw.Write(Convert.ToBase64String(enc.GetBytes(text),
Base64FormattingOptions.InsertLineBreaks));
}
}
Incoming Encoding
Open a Text File
private void OpenTextFileTest()
{
string content = EncodingTools.ReadTextFile(@"C:\test\txt");
using (StreamReader sr = EncodingTools.OpenTextFile(@"C:\test\txt"))
{
string fileContent = sr.ReadToEnd();
}
}
Reading from a Stream
private void ReadStreamTest()
{
using (MemoryStream ms = new MemoryStream(
Encoding.GetEncoding("windows-1252").GetBytes("Some umlauts: öäüß")))
{
using (StreamReader sr = EncodingTools.OpenTextStream(ms))
{
string fileContent = sr.ReadToEnd();
}
}
}
References
- MLang documentation on MSDN
History
- 17/01/2007: Initial release
- 22/01/2007: Fixed code to compile without warnings
- 27/10/2009: Updated source and demo project

