Introduction
I wrote this package for fun in order to be able to compare with PL/SQL code. The changes between to packages are saved as CLOBs. But it can be used to compare any two CLOBs where the only restriction is the maximum line length (4000).
It is based on the naive Longest Common Subsequence algorithm described here:
From the links above, we can see that for X and Y which are two sequences with length m and n respectively, the Longest Common Subsequence for the two sequences is defined by:
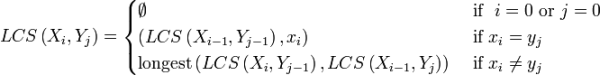
The pseudo-code to calculate the LCS Matrix (M) is given by:
function LCS_MATRIX(X[1..m], Y[1..n])
M = array(0..m, 0..n)
for i := 0..m
M[i,0] = 0
for j := 0..n
M[0,j] = 0
for i := 1..m
for j := 1..n
if X[i] = Y[j]
M[i,j] := C[i-1,j-1] + 1
else:
M[i,j] := max(M[i,j-1], M[i-1,j])
And based on the LCS Matrix, we can calculate the differences between both sequences with the following pseudo-code:
function printDiff(M[0..m,0..n], X[1..m], Y[1..n], i, j)
if i > 0 and j > 0 and X[i] = Y[j]
printDiff(M, X, Y, i-1, j-1)
print " " + X[i]
else
if j > 0 and (i = 0 or M[i,j-1] ≥ M[i-1,j])
printDiff(M, X, Y, i, j-1)
print "+ " + Y[j]
else if i > 0 and (j = 0 or M[i,j-1] < M[i-1,j])
printDiff(M, X, Y, i-1, j)
print "- " + X[i]
else
print ""
My goal on this article was to implement the pseudo-code above in the PL/SQL language, being the sequences X and Y defined by the lines of two CLOBs.
How the Algorithm Implementation Works
In the first step of the algorithm, the CLOBs are transformed into Arrays, where each line of the CLOB is mapped into each record of the array. This is done in the function clob_to_array which returns a varchar2 array.
One of the major difficulties of implementing this algorithm is that PL/SQL is not multi-dimension array friendly. While in other languages it's pretty easy to create an m x n array, in PL/SQL, it's a little bit more complicated. Thanks to Solomon Yakobson from Oracle Forums for teaching me how to do this:
TYPE t_number_array IS TABLE OF NUMBER;
TYPE t_bidimensional_number_array IS TABLE OF t_number_array;
matrix t_bidimensional_number_array := t_bidimensional_number_array();
FOR i IN 1 .. m + 1
LOOP
matrix.extend;
matrix(i) := t_number_array();
FOR j IN 1 .. n + 1
LOOP
matrix(i).extend;
END LOOP;
END LOOP;
Notice that in PL/SQL, the arrays start at value 1, so in order be able to have a Matrix with dimension [0..m,0..n], the Matrix I used is defined by [1..m+1,1..n+1].
After having the old and new file arrays, and having the LCS Matrix initialized, we can start populating it. The following procedure describes the logic used:
FOR i IN 1 .. m + 1
LOOP
FOR j IN 1 .. n + 1
LOOP
IF old_array(i - 1) = new_array(j - 1) THEN
matrix(i)(j) := matrix_i(i - 1) (j - 1) + 1;
ELSE
matrix(i)(j) := greatest(matrix(i) (j - 1), matrix(i - 1) (j));
END IF;
END LOOP;
END LOOP;
I wanted to display the differences line by line, instead of showing just one single output with the added and deleted lines as the one described in Introduction. So my main output is an array t_differences_array which shows the old and new lines side by side.
CREATE OR REPLACE TYPE t_differences AS OBJECT
(
old_line_number NUMBER,
old_file VARCHAR2(4000),
status VARCHAR2(20),
new_line_number NUMBER,
new_file VARCHAR2(4000)
);
CREATE OR REPLACE TYPE t_differences_array as table of t_differences;
For example, given the files OLD_FILE{A,D,E,B} and NEW_FILE{A,C,B}, the standard algorithm would display the differences like this:

While the goal I wanted to achieve was to not add extra lines when they were not necessary, which means changing the output to:
This goal was achieved by adding extra logic to the get_differences procedure. Mainly by saving the line where the differences started, and then starting to populate the other side differences from this saved line until the next equal line.
In the case where the number of different lines do not match, we will have one of the sides with a blank line number. This will also help distinguish the difference from a non-existing line from an existing blank line.
The following code optimizations are included in the algorithm:
- Reducing the problem set: Since in real life cases we normally compare files with small modifications, the LCS Matrix can be greatly reduced if we don't take into consideration the beginning and the end of the files where the lines don't change.
- Reducing the comparison time: When lines are too big, we can reduce the comparison time by hashing the lines and only comparing the hashed value.
Because of the reduced problem set optimization, the real code has three extra parameters defined by the first line where the differences start and the two end lines where the differences stop. These two parameters make the code harder to understand.
Using the code
It includes two main functions for comparing:
FUNCTION compare_line_by_line(old_file_i IN CLOB,
new_file_i IN CLOB) RETURN t_differences_array
FUNCTION compare_line_by_line_refcursor(old_file_i IN CLOB,
new_file_i IN CLOB) RETURN SYS_REFCURSOR
where the only difference is the output type.
I included a test table compare_file_test, so you can easily test the program for two different test cases.
Below, you can see an example of how to use the test table to compare two files:
WITH t AS
(SELECT *
FROM compare_file_test
WHERE id = 1)
SELECT a.*
FROM t,
TABLE(clob_compare.compare_line_by_line(t.old_file, t.new_file)) a
What is still missing
I plan to include a few extra options in future versions:
- Show only different lines
- Ignore cases
- Ignore spaces
- Trim lines
Last notes
I've only tested my implementation for a few test cases, it is possible that some bugs still exist.
I would appreciate suggestions/comments in order to improve and optimize the code.
History

