Introduction
Have you ever required better control over how non-printable characters are displayed? Would you like to remove or replace non-printable characters? Would you like to do this for Unicode text? Recently, I ran into these problems.
I expected an easy solution, but found none. Windows GDI provides an unmanaged function GetFontUnicodeRanges that does a lot of the work. I wrote a C# wrapper class, FontGlyphSet, to do the rest.
The FontGlyphSet class provides methods for replacing or removing characters that do not have representations (glyphs) in a specified font. The remainder of the article describes this class and how it was implemented. The class is freely available for use in both commercial and non-commercial applications, providing the copyright notice is retained.
Background
Recently, I needed to remove or replace non-printable characters in one of my applications. Initially, I considered doing what I have always done...treating characters outside the range of ASCII 32 (space) through ASCII 126 (tilde) as non-printable.
The very term "non-printable" is a bit of a misnomer that doesn't apply well to modern systems. In a world where printing is increasingly rare, Unicode dominates, and a dizzying array of fonts are available, it is hopelessly outdated.
What I really needed was a way to remove or replace characters that lacked a glyph in the font I was using to draw. So, armed with an updated vocabulary, I set out to search for a solution.
I started out with high hopes that the Font class would provide something like a bool HasGlyph(thisChar) method. But, no such luck. The search continued.
After a little more hunting around MSDN, it seemed that two unmanaged, Windows GDI functions GetFontUnicodeRanges and SelectObject could be combined to get the information I needed.
The first of these acquires a data structure, GLYPHSET, that includes an array of WCRANGE structures. Each element of the array, describes a range of characters that have representations (or glyphs).
So, now it was time to build a friendly wrapper class.
The Sample Program
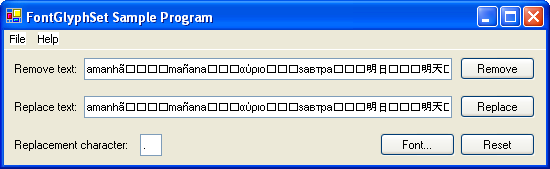
The sample program is easy to use. Click on the "Remove" button, and the program will remove all of the non-printable characters in the corresponding text box. Click on the "Replace" button, and non-printable characters will be replaced by the character specified as a "Replacement character". You can experiment by editing the text or changing the replacement character. Clicking the "Font" button, allows you to try out different fonts. The "Reset" button will set the text and replacement character back to their original values.
The following image shows what happens after the "Remove" and "Replace" buttons are clicked...

The next paragraph contains a brief description of the features of the sample text. If you are unfamiliar with Unicode, don't panic; some explanation and references are provided later in the article.
In the sample text, used by default, the "ã" in the word "amanhã" is actually formed from two characters: an "a" followed by a combining character for the tilde U+0303. Following this, the Unicode code point U+10000 is encoded as a surrogate pair, U+D800 and U+DC00. The other non-printable characters are all control characters with values less than U+0020 (the space character). Interestingly, in .NET 1.1, the TextBox control appears to incorrectly render the surrogate pair as two separate characters.
Using the Code
The class is also easy to use. First, it is necessary to create a FontGlyphSet object from the Font used to draw the text...
FontGlyphSet = new FontGlyphSet(Font);
When replacing or removing characters with FontGlyphSet, it is important to enable a performance enhancement. It uses approximately 8K of memory, but speeds up the Contains method (used by every other method). If you do not do this, the code will still work, but it may take longer to search through all of separate ranges for a specific character.
FontGlyphSet.IsFastContains = true;
Then, to replace or remove characters just use the ReplaceAbsent or RemoveAbsent methods...
myString = FontGlyphSet.ReplaceAbsent(myString, '.');
myString = FontGlyphSet.RemoveAbsent(myString);
Methods
The FontGlyphSet class includes the following public methods...
bool Contains(char charValue);
string RemoveAbsent(string inText);
int RemoveAbsent(char [] inText, int inStart, int inLength,
char [] outText, int outStart);
string ReplaceAbsent(string inText, char replacement);
int ReplaceAbsent(char [] inText, int inStart, int inLength,
char [] outText, int outStart, char replacement);
Properties
The FontGlyphSet class includes the following public properties...
uint CodePointCount;
bool Is8BitIndices;
bool IsFastContains;
uint Flags;
uint RangeCount;
FontRange [] Ranges;
The Implementation
The first step is to import GetFontUnicodeRanges and SelectObject so that they can be used within the class...
using System.Runtime.InteropServices;
[DllImport("gdi32.dll")]
private static extern uint GetFontUnicodeRanges (
IntPtr hdc, IntPtr lpgs);
[DllImport("gdi32.dll")]
private static extern IntPtr SelectObject (
IntPtr hdc, IntPtr hgdiobj);
The next step is to get the information from these unmanaged functions. To do this, get a device context, associate the font with it, invoke GetFontUnicodeRanges to get the size of the GLYPHSET structure, and then call the same function a second time to get the data for the structure...
Graphics g = Graphics.FromHwnd(IntPtr.Zero);
IntPtr hdc = g.GetHdc();
IntPtr hFont = font.ToHfont();
IntPtr savedFont = SelectObject(hdc, hFont);
uint size = GetFontUnicodeRanges(hdc, IntPtr.Zero);
IntPtr glyphSetData = Marshal.AllocHGlobal((int) size);
GetFontUnicodeRanges(hdc, glyphSetData);
After this, the Marshal.ReadInt16 and Marshal.ReadInt32 methods are used to get the data from the structure. The data is loaded into an array of FontRange objects. The FontRange class is another class included with this solution. However, since it is unlikely one would call it directly, I will leave its documentation to the code comments.
Following this, because many of the resources are unmanaged, there is a bit of clean up required...
Marshal.FreeHGlobal(glyphSetData);
SelectObject(hdc, savedFont);
g.ReleaseHdc(hdc);
g.Dispose();
The removal and replacement of characters is pretty obvious with a couple of small exceptions. While debugging, I discovered that some fonts have quite a lot of character ranges. I became concerned that the lookup time to test if a character exists in one of these ranges might be prohibitive.
So, I added the IsFastContains property. By building a BitArray with bits for each of the 65,536 possible character values, the lookup time could be reduced considerably.
Another small problem arises with the way strings are encoded internally. They are encoded as a series of 16-bit words. The coding scheme is called UTF-16. The most commonly used characters fall in a range known as the BMP (Basic Multi-Lingual Plane). Each of these characters have a value less than 65,536 and can be encoded in a single word.
However, Unicode also allows for characters with values greater than 65,535. These values are encoded as surrogate pairs. Each 16-bit word of the pair contains half of the value. All such characters are treated as non-printable by FontGlyphSet.
The problem arises during replacement of these characters. Since the Unicode character actually takes up two 16-bit words in the string, it is important to replace both words of this surrogate pair with a single character. Changes were made to ReplaceAbsent to properly handle this situation.
Removal of characters is less problematic. Each word of the surrogate pair uses a range of values that uniquely identifies it as such (0xD800-0xDBFF and 0xDC00-0xDFFF). According to ISO/IEC 10646 these values should not be associated with valid code points. For this reason, one would not expect glyphs for these characters in a properly designed font. The code simply depends on the fact that both words of the surrogate pair will be removed independently as a consequence of their values.
Conclusions
The FontGlyphSet class that I have implemented works sufficiently for my needs. It is certainly an improvement over the technique of removing/replacing characters outside the printable ASCII range. However, the Unicode character set is very large and my time is very limited. So, it is quite likely that the class may need further refinements. I will do my best to keep the code here up-to-date with any new discoveries.
While a long time reader, this is my first submission to Code Project. I hope others find it helpful.
References
GetFontUnicodeRanges (MSDN), http://msdn2.microsoft.com/en-us/library/ms533944.aspx
Mapping of Unicode characters (Wikipedia), http://en.wikipedia.org/wiki/Mapping_of_Unicode_characters
GLYPHSET (MSDN), http://msdn2.microsoft.com/en-us/library/ms533995.aspx
SelectObject (MSDN), http://msdn2.microsoft.com/en-us/library/ms533272.aspx
Unicode (Wikipedia), http://en.wikipedia.org/wiki/Unicode
UTF-16 (Wikipedia), http://en.wikipedia.org/wiki/UTF-16
WCRANGE (MSDN), http://msdn2.microsoft.com/en-us/library/ms534022.aspx
Revision History
03-12-2007
Original article.

