Quick Links
- Schema definitions
- What is sp_execsql?
- Transactions and NHibernate
- Practices to consider
- To cache or not to cache
- Calling Stored Procedures
Introduction
This is the second part in a two-piece article focused on optimizing the efficiency of your NHibernate ORM layer. In part one, I wrote an in-depth discussion of various techniques for detecting and isolating the performance flaws in your data layer interaction. At this point, I will assume you have a clear definition of your bottleneck and some sort of a goal metric that you aim to achieve. The following sections define areas of your NHibernate application that can be optimized. Each area has a set of performance tweaks, as well as the potential gains and the side effects you will need to be aware of. Remember, if it's not broken, don't fix it!
Background
One of my clients hosts an application that is monolithic in its data complexity and business logic (120+ tables, 400+ classes). NHibernate gives us the benefit of drastically simplifying our code base and cost of maintenance, but the intense data and business logic have real-time speed requirements, which demand the most optimal behavior possible in our data layer. The following information is compiled from days of experimenting with some of NHibernate's lesser documented features, as well as stepping around some of its frustrating idiosyncrasies. At the time of this writing, the current release (stable version) of NHibernate is 1.0.3.0. An attractive and relatively stable beta version (1.2) is also available. Like any popular framework, speed and stability improve simply with time, and some of these performance tweaks are only pertinent to certain versions.
Experimentation Environment
It always helps to have some sort of an existing and familiar codebase to work with. The DBAs commonly use Northwind as their environment, and thanks to the work of James Avery and his development blog, I found a running implementation of the NHibernate/Northwind project we can use to play with. This is written in VS2005, with an NHibernate version of 1.01-contrib. This project offers up some great ideas of properties and methods to consider adding to the base class of your entity classes, so it's definitely worth a look. I'll be using this frequently to demonstrate examples.
Part 1: Schema definitions
NHibernate is only as efficient as the SQL that it generates. Consider the following two identical SQL statements:
select * from publishers
select pub_id, pub_name, city, state, country from pubs.dbo.publishers
Did you know, the latter statement has a considerably faster execution time. Why? Both statements require validation and a compiled query plan before execution, but the first query requires extra work to resolve the specific database object "publishers" as well as which columns are involved with "*". The database needs to find out what * means, what kind of database object is "publishers", and where it is located. The moral of the story: fully qualified names mean less interpretation overhead work for your database server. Performance gains through query verbosity varies widely, but it's always a good practice to follow. NHibernate enables you to take advantage of this concept by allowing you to define your schema for each session.
Take the following example. Use this line in the NHibernate section of your .config file.
<add key="hibernate.default_schema" value="Northwind.dbo"/>
This will actually translate into the following SQL code (in the Northwind project) for selecting categories:
execsp_executesql N'SELECT .... FROM Northwind.dbo.Categories category0_'
For those of you lucky enough to have multiple schemas or databases, Billy McCafferty has shed some light on the subject via the usage of multiple config files.
Part 2: What is sp_execsql?
One of the greatest things about NHibernate is that in its basic form, it is database-agnostic. The SQL generated by your NHibernate app is determined by the dialect that you employ. If you are using the SQL200X dialect of NHibernate, you will observe frequent usage of the sp_execsql statements. They are generated from session calls such as session.GetBy(..) and session.CreateCriteria(...). sp_execsql is a built-in Stored Procedure that takes SQL commands as an argument and executes them. It's limited to an input of nvarchar(4000), it supports Unicode, and it works nicely for interfaces that generate SQL dynamically, such as NHibernate. Each call to sp_execsql operates as a single SQL batch, which means the statements are executed in a serial fashion without any buffering.
Why do we rely on this Stored Procedure so heavily when we could just generate the SQL directly? sp_execsql not only executes the given command parameter, it takes some time to compile and cache the query plan such that subsequent similar calls are optimized. If sp_execsql is called with a similar query multiple times, the benefit of a cached compiled query plan is leveraged. When you have groups of similar queries executing in a line, the end result is a perceived gain in "momentum" as the cached query plan is built and reused. Following this behavior, the disadvantages of sp_execsql come into play with rare or diverse queries, where time is actually wasted building and caching an execution plan that is seldom reused.
Consider the following example:
Using the Northwind project, I go to the ManageCategories.aspx page. I click on a few different categories to view their properties. Each click is a callback to the database to retrieve data about a specific category.
The following is a trace of the resulting SQL generated by NHibernate (and my "clicking"):
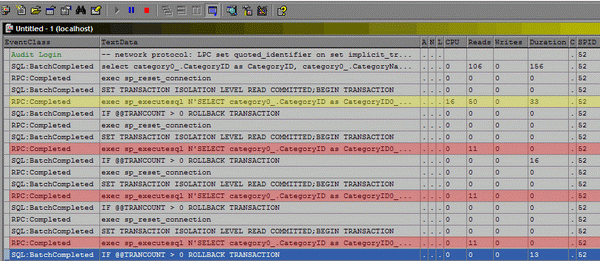
The first "yellow" call is my initial click to view a given category. sp_execsql takes the time to compile and cache the query plan, hence the "CPU cost" of 16, 50 reads, and the 33ms duration of execution. In this case, compiling and storing this plan was worthwhile, because my subsequent clicks generated similar SQL code, and the query plan was reused with much more efficient results (see the relative costs on the red rows?).
This leaves two obvious questions:
- How "similar" must two given queries be such that a query plan is reused?
- What is the lifetime of a given query plan in the cache before it is invalidated?
Alas, the answers for this are heavily circumstantial. A query plan is reused when SQL Server decides that the execution time of the existing query plan is faster than building and running a new one. For example, if you were to look at any two queries using the SQL Query Analyzer, do they have similar execution plans? The cache lifetime of a given query plan is for the benefit of SQL Server; it's a "black box" scheme, and should not be relied upon nor predicted. If you need something unconditionally cached, consider using NHibernate's caching features, or the DBCC PINTABLE function for faster access (more on this later). If you have a vastly diverse set of queries that are running slow, consider breaking them down into parameterized user-defined functions, indexed Views, or Stored Procedures. Maybe, there is a way you can group these similar queries together such that you will see the same behavior as above.
Part 3: Transactions and NHibernate
Transactions are a critical issue on enterprise applications. They have a direct effect on your data integrity and scalability. Too much speed can risk integrity, too much integrity constraints can lower speed thresholds. When employing NHibernate, you should be aware of the isolation level you are using and the average footprint and time cost of your transactions.
Isolation level definitions
If you are building an enterprise application, you have some threshold of anticipated concurrency loads. The isolation level of a given transaction defines its behavior in situations involving concurrency. Defining the isolation level on your transactions will have a night and day effect on the scalability of your enterprise application. NHibernate allows you to define the isolation level of each transaction, or more conveniently, a default (but overridable) isolation level for the application, in general. The catch-22 of isolation levels is a tradeoff between speed and safety, and NHibernate allows you to choose from the set of System.Data built-in isolation levels that should fit any situation you may need, ordered from the safest levels to the fastest levels:
Serializeable - A lock is held on the database object (read - entire table) until the end of the transaction. Multiple serializeable operations can be rolled back while preserving integrity.RepeatableRead - "Reading locks" and "writing locks" on rows are held until the end of the transaction. The risk includes missing newly inserted rows created from outside sources during the transaction.ReadCommitted - "Reading locks" are quickly released, but "writing locks" on rows are not released until the end of the transaction. This is the default isolation level in SQL Server. The risk includes a non-repeatable read due to mid-transaction updates from outside sources.ReadUncommitted - "Reading locks and "writing locks" on rows are released before the end of the transaction. The risk includes "phantom update", referring to inconsistent reads during a transaction.Chaos - Only the highest priority of writes use locks. Aside from the universal ACID benefits of transactions, I have yet to find a use for this isolation level.
To define the default isolation level for your application, add something such as the following to your .config file:
<add key="hibernate.connection.isolation" value="ReadCommitted" />
To define a custom isolation level for a given transaction, add the System.Data.IsolationLevel argument to your transaction declaration:
ITransaction transaction =
session.BeginTransaction(System.Data.IsolationLevel.ReadCommitted);
Why should I define my isolation level in NHibernate? Isn't this kind of concept database-specific? Yes, it is database-specific, but some code such as:
ITransaction transaction=
session.BeginTransaction(System.Data.IsolationLevel.ReadCommitted);
session.SaveOrUpdate(entity);
transaction.Commit();
will actually result in the following SQL code sent to your SQL Server upon execution:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED; BEGIN TRANSACTION
exec sp_executesql N'UPDATE Northwind.dbo.Categories SET CategoryName = @p0,
Picture = @p1, Description = @p2 WHERE CategoryID = @p3', N'@p0 nvarchar(4000),...
COMMIT TRANSACTION
Transaction granularity and its effects on scalability
One common gap in misunderstanding between the software engineer and the DBA is the concept of transactions and its effect on scalability. Imagine the following scenario:
Joe the engineer designs an e-commerce app to sell concert tickets. When a customer clicks on "check out", a transaction is started that "reserves" the ordered stock of tickets, and the transaction commits once the customer is finished confirming and entering payment information. Joe thinks this is perfect because it ensures the customer's stock is inaccessible to other buyers while the customer is checking out.
A few weeks down the road, Joe's going to be looking for a new job. Why? This usage of transactions is dangerously wrong on many levels.
- What if I buy all the tickets to the next Devo concert and redirect to my MySpace page before checking out and paying? Depending on the isolation level, no one else can access these items until my transaction is committed or times out, and no one else can purchase tickets until Joe's application gets a response from me checking out. Devo fans will not be happy, and you wouldn't want to see an unhappy Devo fan, now would you? My point is that transactions should never be left open waiting for user input.
- This is more subtle, but equally as important: depending on the isolation level in use, once a given row is accessed within a transaction, the row is commonly "locked" for the remainder of the transaction lifetime. This means that other operations that may need to access this row to complete their task are suspended until the transaction is complete. If this is a commonly accessed piece of data, you'll see operations lining up (and waiting) (and timing out) (and deadlocking) as they try to access this popular chunk of data. To make matters worse, SQL Server has a "greedy" locking scheme, where it rarely locks a single row without locking a radius of the neighboring rows (page-level-locking) in anticipation for contiguous updates and inserts.
Use transactions with consideration. Does this particular Use Case need ACID properties? If your given Use Case is read-only, are you sure that you need to use a transaction? How much time does your transaction take between the initialization and the commitment? Is it more than a second? Visualize your transactions as cars trying to merge onto a one lane highway; smaller cars make for a more efficient highway than 18-wheelers! Can you decompose your transaction down into multiple smaller transactions? If not, do you have the chance of employing this logic in a faster way, such as a Stored Procedure, or SQL delegated CLR? Transactions are a great way to ensure the integrity of your data via ACID, and multiple transactions can be nested within one another, but transactions with high granularity quickly lock down resources and dent your scalability. The paradigm is, a complete lack of transactional integrity can compromise your data integrity.
Part 4: Practices to consider
.NET design best practices
I wont pretend to be the software engineering authority; Billy McCafferty has already written a great article on this subject that covers the best arrangement of your NHibernate layer, complete with accommodations for Generics and a testing framework. This is the starting point for using NHibernate correctly. The following is a methodology for keeping your queries efficient and flexible via the use of HQL-generating classes.
The search criteria object
The single biggest issue ORM applications face is excessive I/O between the database and the application. All too often, a collection of objects is loaded from the database, when only one object in the collection is truly needed. To avoid this trend, you can write a custom method inside your DAO layer that holds the HQL for your specific needs. There is a problem with this: every time you need to load a specific object in a new context, you need to write a new custom method, and manage more HQL. Sometimes, to avoid the buildup of HQL in your application, it is best to assign a class with the responsibility of generating the HQL for multiple contexts. I call this a "SearchCriteria" class. This class will have custom properties available for specifying search criteria, as well as a method for automatically generating the HQL for retrieving the specific instance. The benefit? All of your HQL for a given entity is stored in a single place, and a criteria object serves as the connection between a loosely coupled data layer and a business layer.
To give an example, we will once again refer to the Northwind codebase. We can streamline the search process of a given persistent object by employing the following class model:

Represented by the following code example in a new file named ISearchCriteria:
namespace Northwind.Domain
{
public interface ISearchCriteria
{
string HQL
{
get ;
}
}
}
Now, each property of the Category class can potentially be a parameter for the criteria class to handle. To simplify this example, we will create our category-specific search criteria class named CategorySearchCriteria, with the following two properties:
using System;
using System.Collections.Generic;
using System.Text;
namespace Northwind.Domain
{
class CategorySearchCriteria:ISearchCriteria
{
#region defaults
private static readonly int defaultID = -1;
private static readonly bool defaultExcludeCategoriesWithProducts = false;
#endregion
#region members
private int id = defaultID;
private bool excludeCategoriesWithProducts =
defaultExcludeCategoriesWithProducts;
#endregion
#region properties
public int Id
{
get { return id; }
set { id = value; }
}
public bool ExcludeCategoriesWithProducts
{
get { return excludeCategoriesWithProducts; }
set { excludeCategoriesWithProducts = value; }
}
#endregion
#region HQL
public string HQL
{
get
{
StringBuilder builder = new
StringBuilder("select cat from Category cat where (1=1) ");
if (id != defaultID)
builder.Append(" and cat.ID = '" + id + "'");
if (excludeCategoriesWithProducts !=
defaultExcludeCategoriesWithProducts)
builder.Append(" and cat.Id not in " +
"(select p.Category.Id from Product p) ");
return builder.ToString();
}
}
#endregion
}
}
The interesting points of the above code:
- "
where (1=1)" is an initial clause to the WHERE criteria. It's a commonly used trick when generating SQL-flavored code. If no other search criteria parameters are set, this object will generate the HQL that returns all categories. - Every time we have a new criteria property, we create a new default value, and a new filter to the
WHERE clause. - Since this class generates HQL, natively supported features such as paging can easily be implemented via the
SetFirstResult()/SetMaxResults() methods.
Part 5: To cache or not to cache
If there is one recurring theme of this article, it's about avoiding the excessive I/O between the database and the .NET tier that NHibernate can potentially introduce. Sometimes, instead of concerning yourself with optimizing database interaction, you should explore the possibility of bypassing database interaction via the use of a cache. In a nutshell, caching is the practice of storing copies of frequently accessed data in an easily and quickly accessible storage location. This storage location is potentially unreliable, and it's important to know when the storage and the true data source are out of sync. It is in many respects a double edged sword, and a good understanding of your caching scheme is essential.
- You can manually cache database tables in SQL Server using the DBCC PINTABLE method.
- You can cache sets of persistent objects in NHibernate using NHibernate's caching features (which come in two implementations, Bamboo Prevalence, and the more common ASP.NET caching).
- You can employ the Second Level Cache feature inside the ActiveRecord framework from the Castle Project.
- You can write your own object pooling design such as a singleton class to customize your caching behavior.
Caching will help you:
- Quickly deliver data that is frequently accessed, but seldom inserted or changed.
- Lower the amount of database interaction, and therefore boost your speed and scalability.
Caching won't help you:
- With the predictability of your application. A poorly placed caching mechanism on a clustered environment can be trouble, since each server in the cluster may potentially have their own version of the cache.
When exploring the possibility of caching data, ask the following questions:
- What is the scope of the data that I want to cache?
- Do I want to cache data immediately at program start, or upon initial loading of the data?
- What is the lifetime of a given cached object before it should be invalidated?
- What chain of events need to happen when a cached object is invalidated?
- What chain of events need to happen when an object in cache is updated?
- What chance is there that the cached data can be changed and invalidated by outside forces?
Part 6: Stored Procedures
The usage of precompiled SQL commands is an often misunderstood notion from the Software Engineering Community. Some people view them as a silver bullet, some abhor them altogether. Before I explain how to employ Stored procedures, I will try to clarify when it's a valid route to follow:
Stored Procedures will help you:
- If you can write a Stored Procedure/UDF that will use a consistent and reusable query plan.
- When you need a high degree of control over your database in terms of locking, nested transactions, and temp tables.
- When you are working with data inaccessible to the NHibernate mappings.
- You want to leverage business-logic enhancements such as the CLR or the job scheduling agent in SQL Server 2005.
- When you have a single method with a few parameters that causes a large amount of updates or inserts.
Stored Procedures won't help you:
- Load large sets of data any faster. Heavy amounts of I/O are limited by the connection media.
- If the manner in which your Stored Procedure behaves varies widely (this causes multiple recompilations of the same Stored Procedure at runtime).
- With your code maintenance overhead. By employing the use of database logic, you have, in a sense, violated the NHibernate "purity" of your application design. In other words, you have spread portions of your business intelligence into the data tier, and the interface between the two tiers needs to be synchronized and maintained. Furthermore, you must keep track of what is and is not a responsibility of your database. Think of the intricacies involved with your Unit Testing and debugging.
- With paging. Even in version 1.2, Stored Procedure queries can't be paged with
SetFirstResult()/SetMaxResults(). Unless you write the custom SQL for paging yourself, you will always get the entire result set back from the call.
All too often, the need for a frequently used (but expensive) query comes up. Consider using indexed views or user-defined functions (UDF) for read-only-specific query optimizations. The main challenge is mapping the return values from a Stored Procedure into NHibernate's view, such that NHibernate can manage the persistent object in a normal fashion.
For the sake of an example, I will use the "Ten Most Expensive Products" Stored Procedure in Northwind, and show you how this can be called in both versions of NHibernate.
Calling Stored Procedures in 1.0.X
NHibernate 1.0 does not directly support the usage of Stored Procedure calls. It can be hacked via creative usage of the session.CreateSQLQuery(..) method. The challenge is that NHibernate will be expecting a specific set of column aliases returned from the database, and your Stored Procedure must match up with these column aliases precisely. If a column is missing, or the returned column name alias does not match NHibernate's expectations, a SQLException is thrown. How do we know what the correct column aliases are? The column alias convention seems to vary with the specific version of NHibernate you are using, so when in doubt, capture some profiled queries generated by NHibernate as examples. Fortunately, we have the Product query listed above, so we can change the existing Stored Procedure:
create procedure
"Ten Most Expensive Products" AS
SET ROWCOUNT 10
SELECT Products.ProductName AS
TenMostExpensiveProducts,
Products.UnitPrice
FROM
Products
ORDER BY Products.UnitPrice
DESC
GO
into something more palatable by NHibernate 1.0.X:
CREATE procedure [Ten Most Expensive Products]
AS
SET ROWCOUNT 10
SELECT
product0_.ProductID as ProductID0_,
product0_.UnitsOnOrder as UnitsOnO6_0_,
product0_.ProductName as ProductN2_0_,
product0_.ReorderLevel as ReorderL7_0_,
product0_.Discontinued as Disconti8_0_,
product0_.QuantityPerUnit as Quantity3_0_,
product0_.UnitPrice as UnitPrice0_,
product0_.SupplierID as SupplierID0_,
product0_.UnitsInStock as UnitsInS5_0_,
product0_.CategoryID as CategoryID0_
FROM
Northwind.dbo.Products product0_
ORDER BY
product0_.UnitPrice DESC
GO
And finally, call it using the CreateSQLQuery method:
IList products = session.CreateSQLQuery("exec [Ten Most Expensive Products]",
"irrelevant parameter", typeof(Product)).List();
As expected, this returns the top ten most expensive products, ordered correctly, with the full persistence functionality of NHibernate. Note that the return alias parameter is unused. In NHibernate 1.2, this parameter is deprecated. The disadvantages:
- The obvious challenge of finding the correct return column aliases that NHibernate is expecting.
- Whenever you change the property set for a given class, there is a chance you will need to revisit the Stored Procedures related to the class to update the aliases.
In my experiences, I've often found it to be more worthwhile to use the System.Data library over NHibernate 1.0 for calling specific database functions, but I wanted to show you it is a possibility to use.
Calling Stored Procedures in 1.2.X
Due to popular demand, one of the biggest new features in 1.2 is support for accessing database objects. This goes above and beyond the mere realm of Stored Procedures! Support for native SQL gives you a higher degree of control over your database. Once again, the challenge lies within mapping the return values from a Stored Procedure into NHibernate's view of the persistent object. This time around, we have more power over the mappings by defining our database calls within the relational mapping file, ala IBatis style. Inside of the Product.hbm.xml file, we declare exactly how to call the procedure, what the procedure will return, and how to map the returned values:
<sql-query name="sp_TenMostExpensiveProducts" callable="true">
<return class="Product">
<return-property name="ProductID" column="ProductID"/>
<return-property name="UnitsOnOrder" column="UnitsOnOrder"/>
<return-property name="ProductName" column="ProductName"/>
<return-property name="ReorderLevel" column="ReorderLevel"/>
<return-property name="Discontinued" column="Discontinued"/>
<return-property name="QuantityPerUnit" column="QuantityPerUnit"/>
<return-property name="UnitPrice" column="UnitPrice"/>
<return-property name="SupplierID" column="SupplierID"/>
<return-property name="UnitsInStock" column="UnitsInStock"/>
<return-property name="CategoryID" column="CategoryID"/>
</return>
exec [Ten Most Expensive Products]
</sql-query>
With <return-property>, you can explicitly tell NHibernate what column aliases to use, instead of NHibernate injecting its own column aliases (see the above example for 1.0.X).
The corresponding Stored Procedure becomes much more readable:
CREATE procedure [Ten Most Expensive Products]
AS
SET ROWCOUNT 10
SELECT
ProductID,
UnitsOnOrder,
ProductName,
ReorderLevel,
Discontinued,
QuantityPerUnit,
UnitPrice,
SupplierID,
UnitsInStock,
CategoryID
FROM
Northwind.dbo.Products
ORDER BY
UnitPrice DESC
GO
The call on the .NET side ends up:
IList products = session.GetNamedQuery("sp_TenMostExpensiveProducts") .List();
This scratches the surface of NHibernate's 1.2 SQL capabilities. For more information about native SQL support and its potential, visit the NHibernate docs.
Conclusion
In part 1, I discussed methodologies for finding and isolating your data-related performance and scalability problems. In this article, I covered the various ways to address these problems. NHibernate is an evolving framework, growing both in flexibility and popularity with developers, and for many good reasons! The next time someone dismisses the potential of performance in an ORM framework, maybe you can point them to this article as a proof of concept!
History
- 04/07/2007 - Initial release.
- 04/07/2007 - Amendment - Many-to-one flaw correction in section 6.
- 04/08/2007 - Amendment - I removed the many-to-one flaw in section 6 until further notice. I'm going to add a section regarding fetching schemas and their effect on performance in the near future.

