Introduction
There are some people on planet Earth who still don't understand the difference between a byte and a character. So, let's start with the basics.
A byte is information storage. 1 byte = 8 bits. That is it.
A character is any written symbol. It ranges from English letters to Chinese letters to any other special characters, or even scientific, or mathematical symbols. In order to let the computer store characters, there are many ways for encoding. If the encoding is 8-bit encoding, this means that every character will be stored in one single byte. But other encodings offer 7-bit encoding (like ANSI) or 16-bits encoding (like Unicode).
Code Page represents the encoding mechanism that is used to encode characters into a bit-stream. Here are some examples of mostly common Code Pages:
| Code Page | Name | AKA |
| 1200 | utf-16 | Unicode |
| 1250 | windows-1250 | Central European (Windows) |
| 1251 | windows-1251 | Cyrillic (Windows) |
| 1252 | Windows-1252 | Western European (Windows) |
| 1253 | windows-1253 | Greek (Windows) |
| 1254 | windows-1254 | Turkish (Windows) |
| 1255 | windows-1255 | Hebrew (Windows) |
| 1256 | windows-1256 | Arabic (Windows) |
| 20127 | us-ascii | US-ASCII |
| 20936 | x-cp20936 | Chinese Simplified (GB2312-80) |
| 20949 | x-cp20949 | Korean Wansung |
| 28591 | iso-8859-1 | Western European (ISO) |
| 65001 | utf-8 | Unicode (UTF-8) |
| 65005 | utf-32 | Unicode (UTF-32) |
Background
Files are a stream of bytes. If the file is a text file, then this stream of bytes should represent those characters in one Code Page as mentioned above. However what is not stored within the file is that piece of information that tells which Code Page was used to do the encoding (although we can write algorithms that try to find a best guess). So, if the file is written in a Code Page that is not supported by the system that interprets the file, a conversion will be needed to re-encode the file in the expected Code Page.
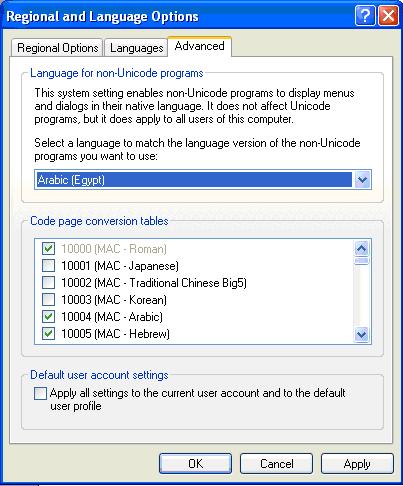
For the example in the screen shot below, if the Regional and Language Options in Windows XP sets the language to match non-Unicode programs to Arabic (Egypt), this means that the encoding used to encode TXT files will be (Windows-1256) .
If the text file is opened later on, a system that has a different setting in Regional and Language Options (like English (United States)). This will cause the file to be interpreted incorrectly.
Using the Code
The software requires .NET 2.0 to run. First provide a path for the input file, and the input code-page. And the path for the output files with the target Code-Page.

References
History
- 13th April, 2007: Initial post

