Introduction
Microsoft SQL Server 2005 Integration Services (SSIS) is a platform for building high performance data integration solutions, including extraction, transformation, and load (ETL) packages for data warehousing. (read more from MSDN)
Business Intelligence (BI) Studio provides graphical tools for designing and debugging packages; tasks for performing workflow functions such as FTP operations, for executing SQL statements, or for sending e-mail messages; data sources and destinations for extracting and loading data; transformations for cleaning, aggregating, merging, and copying data. SSIS ships along with a rich set of and application programming interfaces (APIs) for programming the Integration Services object model.
Integration Services replaces Data Transformation Services (DTS), which was first introduced as a component of SQL Server 7.0.
In this article we will explore the SSIS APIs and how we can use them for our purpose.
Background
Couple of months ago, I had to work with SSIS APIs to implement a custom import wizard (similar to SQL server import wizard) and during that time I explored these APIs. I found that it contains a great improvement over its previous version (a.k.a. DTS).
Unfortunately I did not find adequate code sample on these APIs which could help me to run faster in my business way. And that's why I wrote an article explaining how we can programmatically create an SSIS package in Code Project. I personally received several emails asking me to explain more on this. And that's why I am writing another article on this.
A quick architectural overview
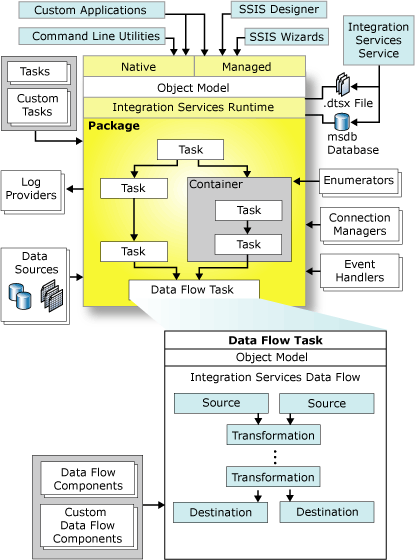
SSIS Architecture (image source : MSDN)
Integration services (SSIS) architecture consists of several containers and task components. These elements can be categorized in four sections:
- Integration Services Service
- Integration Services Object Model
- Integration Services Runtime
- Integration Services Data Flow
The first one, Integration Services service, a Windows service, monitors running SSIS packages and manages the storage of packages. It's available in SQL Server Management Studio.
SSIS object model is a managed set of APIs that allows us to write custom applications, command line utilities etc.
SSIS Runtime is an environment that runs the SSIS package, manages transactions etc. Runtime executables are the smallest part that runs into the environment. For example, packages, containers, tasks, event handlers all of these are runtime executables.
Data flow is the most important (and critical too) part of SSIS architecture. It contains a data flow engine that manages the data flow components. A significant number of data flow components ships along with the SSIS installation. And these can be categorized in three categories – source components (which extracts the data from a system), transformation components (performs transformations, modifications onto the extracted data) and load components (which simply performs the data loading tasks into the destination systems). Besides the available data flow components, we can write our own custom data flow components to accomplish any custom requirements.
Although the architectural codes are written in native language (C++, COM), we can use any CLR languages to start programming with these APIs.
For a detailed knowledge about the architecture of SSIS, please go to MSDN.
Start writing a pilot project
I believe, in order to understand the details it's always better to start implementing a "pilot" application first. Therefore let's implement a simple package. For this pilot project we will use C#.

Pilot package into the designer
I am going to create a vanilla SSIS package that consists of a single data flow task. And the data flow task contains two data flow components. A source data flow component that reads a source (CSV file) and a destination component which loads the data into a destination (SQL server database - in this sample).
The dataflow components
Before writing any code, let's create a comma separated file which we will use as our data source. So create a file named as Sample.csv and paste the following data into the file and finally save it.
"Name","Age","JoinDate","Salary","Retired"
"Jon Tuite","45","2004-01-03 00:00:00","55.265","False"
"Linda Hamilton","25","2002-01-03 00:00:00","155.265","False"
"Sen Seldiver","42","2002-01-03 00:00:00,","458.2","True"
"Rose Dalson","25","2004-01-03 00:00:00","55.265","False"
It is a CSV file delimited by a comma. And the file decorated with double quote (") as a text qualifier.
Open Visual Studio .NET 2005 and create a new application (you can use Windows application or console application whatever you like). Now add some assembly references that are for SSIS object model. The assemblies are:
Microsoft.SQLServer.DTSPipelineWrap Microsoft.SQLServer.DTSRuntimeWrap Microsoft.SQLServer.ManagedDTS Microsoft.SQLServer.PipelineHost
Our project reference will look something like this:
Create a new class named ImportPackage and append the following directives inside the ImportPackage.cs code file.
using Microsoft.SqlServer.Dts.Runtime;
using PipeLineWrapper = Microsoft.SqlServer.Dts.Pipeline.Wrapper;
using RuntimeWrapper = Microsoft.SqlServer.Dts.Runtime.Wrapper;
We are now going to declare some member variable that will be required later.
private Package package;
private ConnectionManager flatFileConnectionManager;
private ConnectionManager destinationDatabaseConnectionManager;
private Executable dataflowTask;
Create a method named CreatePackage into the class.
package = new Package();
package.CreationDate = DateTime.Now;
package.ProtectionLevel = DTSProtectionLevel.DontSaveSensitive;
package.Name = "Some name";
package.Description = "A simple package";
package.DelayValidation = true;
package.PackageType =
Microsoft.SqlServer.Dts.Runtime.
DTSPackageType.DTSDesigner90;
So this method simply instantiates a new package variable and sets a value to some initial properties.
According to the diagram created in SSIS designer (that we have seen earlier) we will create a data flow task now. And the dataflow task will contain two data flow components (source and destination) – both components will require a connection component to extract and load data from and to the source and destination. So let's create the connection component for the source first.
It is worth mentioning one thing here, which is, for a flat file connection manager we need to explicitly create the source columns (the columns that are available into the CSV file). We are going to write a method CreateSourceColumns() which will serve this purpose. You might have already guessed that we need to read the available column names from the source file to do this. For this pilot application we are simply hardcoding these inside the code. But it should be read from the file using .NET IO APIs (you can use Microsoft.Jet.OLEDB.4.0 objects as an alternative of .NET IO APIs). In order to hard code the available column names, I am using a string collection as a member variable inside the class.
private List<string> srcColumns = new List<string>();
and populating its value into the constructor method:
public ImportPackage()
{
srcColumns.Clear();
srcColumns.Add("\"Name\"");
srcColumns.Add("\"Age\"");
srcColumns.Add("\"JoinDate\"");
srcColumns.Add("\"Salary\"");
srcColumns.Add("\"Retired\"");
}
private void CreateFlatFileConnection()
{
string flatFileName = @"C:\Sample.csv";
string FlatFileMoniker = @"FLATFILE";
flatFileConnectionManager =
package.Connections.Add(FlatFileMoniker);
flatFileConnectionManager.ConnectionString =
flatFileName;
flatFileConnectionManager.Name =
"SSIS Connection Manager for Files";
flatFileConnectionManager.Description =
string.Concat("SSIS Connection Manager");
flatFileConnectionManager.Properties
["ColumnNamesInFirstDataRow"]
.SetValue(flatFileConnectionManager,
true);
flatFileConnectionManager.
Properties["Format"].
SetValue(flatFileConnectionManager, "Delimited");
flatFileConnectionManager.
Properties["HeaderRowDelimiter"].
SetValue(flatFileConnectionManager, "\r\n");
flatFileConnectionManager.Properties
["TextQualifier"].
SetValue(flatFileConnectionManager, "\"");
CreateSourceColumns();
}
private void CreateSourceColumns()
{
RuntimeWrapper.IDTSConnectionManagerFlatFile90
flatFileConnection =
flatFileConnectionManager.InnerObject as
RuntimeWrapper.IDTSConnectionManagerFlatFile90;
RuntimeWrapper.IDTSConnectionManagerFlatFileColumn90 column;
RuntimeWrapper.IDTSName90 name;
Debug.WriteLine(flatFileConnection.Columns.Count);
foreach (String colName in srcColumns)
{
column =
flatFileConnection.Columns.Add();
if (srcColumns.IndexOf(colName) == (srcColumns.Count - 1))
column.ColumnDelimiter =
"\r\n";
else
column.ColumnDelimiter = ",";
name = (RuntimeWrapper.IDTSName90)column;
name.Name = colName.Replace("\"","");
column.TextQualified = true;
column.ColumnType =
"Delimited";
column.DataType =
Microsoft.SqlServer.Dts.Runtime.
Wrapper.DataType.DT_STR;
column.ColumnWidth = 0;
column.MaximumWidth = 255;
column.DataPrecision = 0;
column.DataScale = 0;
}
}
You may have noticed that we are creating COM objects using monikers. Now we will create the connection manager object for the destination data flow component.
private void CreateDestinationDatabaseConnection()
{
string OleDBMoniker =
@"OLEDB";
string ConnectionString =
@"Data Source=MOIM023;
Initial Catalog=ImportDatabase;
Integrated Security=SSPI;Provider=SQLNCLI;
Auto Translate=false;";
destinationDatabaseConnectionManager
= package.Connections.Add(OleDBMoniker);
destinationDatabaseConnectionManager.ConnectionString
= ConnectionString;
destinationDatabaseConnectionManager.Name
= "SSIS Connection Manager for Oledb";
destinationDatabaseConnectionManager.Description
= string.Concat("SSIS Connection Manager for OLEDB");
}
So far so good, it is time to create the data flow components. I am writing a method CreateDataFlowTask() which will basically create and initialize the data flow components.
Before going to write this data flow task creation method, let's create a class Column like the following:
public class Column
{
private string name;
public string Name
{
get { return name; }
set { name = value; }
}
private Microsoft.SqlServer.Dts.
Runtime.Wrapper.DataType dataType;
public Microsoft.SqlServer.Dts.
Runtime.Wrapper.DataType DataType
{
get { return dataType; }
set { dataType = value; }
}
private int length;
public int Length
{
get { return length; }
set { length = value; }
}
private int precision;
public int Precision
{
get { return precision; }
set { precision = value; }
}
private int scale;
public int Scale
{
get { return scale; }
set { scale = value; }
}
private int codePage = 0;
public int CodePage
{
get { return codePage; }
set { codePage = value; }
}
}
Lets create a method into the ImportPackage class which is a utility method that helps to determine the target column's data type length etc.
private Column GetTargetColumnInfo(string sourceColumnName)
{
Column cl = new Column();
if( sourceColumnName.Contains("Name"))
{
cl.Name = "Name";
cl.DataType =
Microsoft.SqlServer.Dts.Runtime.
Wrapper.DataType.DT_STR;
cl.Precision = 0;
cl.Scale = 0;
cl.Length = 255;
cl.CodePage = 1252;
}
else if(
sourceColumnName.Contains("Age"))
{
cl.Name = "Age";
cl.DataType =
Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_I4;
cl.Precision = 0;
cl.Scale = 0;
cl.Length = 0;
}
else if( sourceColumnName.Contains("JoinDate"))
{
cl.Name = "JoinDate";
cl.DataType =
Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_DATE;
cl.Precision = 0;
cl.Scale = 0;
cl.Length = 0;
}
else if( sourceColumnName.Contains("Salary"))
{
cl.Name = "Salary";
cl.DataType =
Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_NUMERIC;
cl.Precision = 6;
cl.Scale = 3;
cl.Length = 0;
}
else if( sourceColumnName.Contains("Retired"))
{
cl.Name = "Retired";
cl.DataType =
Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_BOOL;
cl.Precision = 0;
cl.Scale = 0;
cl.Length = 0;
}
return cl;
}
Now we can write the Data flow task creation method.
private void CreateDataFlowTask()
{
string dataFlowTaskMoniker = "DTS.Pipeline.1";
dataflowTask = package.Executables.Add(dataFlowTaskMoniker);
Here we are creating a dataflow task executable by using a moniker. A data flow task is an executable that can contain one or more data flow components (i.e. source, transformation or destination components).
Generally all data flow components have two collection properties. One is Input collections and another is output collections. As the names indicates the input collection contains one or more inputs (can come from different sources), the output collection object contains one or more outputs (can provide data to different destinations) and one error output – which contains the errors that has taken place during the data manipulation inside the component.
Now we can create those data flow components under this dataflowTask object.
PipeLineWrapper.IDTSComponentMetaData90 sourceComponent =
((dataflowTask as TaskHost).InnerObject as
PipeLineWrapper.MainPipe).ComponentMetaDataCollection.New();
sourceComponent.Name
= "Source File Component";
string SourceDataFlowComponentID =
"{90C7770B-DE7C-435E-880E-E718C92C0573}";
sourceComponent.ComponentClassID =
SourceDataFlowComponentID;
The dataflow components are COM objects. When we invoke the TaskHost's ComponentMetaDataCollection.New(), it creates a generic component meta data object but still it is not populated with all specific properties that is necessary for the source component. The following two lines will actually create an instance of a specific data flow component (In this case a source component-according to the given CLSID).
PipeLineWrapper.CManagedComponentWrapper
managedFlatFileInstance
= sourceComponent.Instantiate();
managedFlatFileInstance.ProvideComponentProperties();
The source component needs to refer to the connection manager object that we created earlier.
if (sourceComponent.RuntimeConnectionCollection.Count > 0)
{
sourceComponent.RuntimeConnectionCollection[0]
.ConnectionManagerID =
flatFileConnectionManager.ID;
sourceComponent.RuntimeConnectionCollection[0].
ConnectionManager =
DtsConvert.ToConnectionManager90
(flatFileConnectionManager);
}
managedFlatFileInstance.AcquireConnections(null);
managedFlatFileInstance.ReinitializeMetaData();
managedFlatFileInstance.ReinitializeMetaData() will read the input column names from the connection manager object and will automatically populate an input object inside its input collection object. You can check the Count property of the sourceComponent.InputCollection , you will find that it is 1. Now we need to create the mapping between the input and output columns – so that the component's output contains the values that it will read from the source file.
It is important to understand that, all the objects into a package have an id. In fact, each column (output or input whatever) has an ID that is unique to the scope of the package. I am going to use a dictionary object to keep track between each output column id and it's name. We will need this information later.
Dictionary<string, int> outputColumnLineageIDs
= new Dictionary<string,int>();
PipeLineWrapper.IDTSExternalMetadataColumn90 exOutColumn;
foreach (PipeLineWrapper.IDTSOutputColumn90 outColumn in
sourceComponent.OutputCollection[0].OutputColumnCollection)
{
exOutColumn =
sourceComponent.OutputCollection
[0].ExternalMetadataColumnCollection[outColumn.Name];
managedFlatFileInstance.MapOutputColumn(
sourceComponent.OutputCollection[0].ID,
outColumn.ID, exOutColumn.ID, true);
outputColumnLineageIDs.Add(outColumn.Name, outColumn.ID);
}
managedFlatFileInstance.ReleaseConnections();
So the source dataflow component is ready to use now. Let's create the destination dataflow component now. Before creating the data destination component we need to create the database and the datatable that will be the destination. So let's create the datatable using the following SQL scripts. (For the sake of simplicity we are creating the database manually – but it is supposed to be created programmatically as well. But it must exist before invoking the destination data flow component's ReinitializeMetaData(), otherwise it will generate an error.)
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[DataTable](
[Name] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[Age] [varchar](50),
[JoinDate] [varchar](50),
[Salary] [varchar](50) NULL,
[Retired] [varchar](50) NULL
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
Now we can create the data destination component.
string OleDBDestinationDataFlowComponentID
= "{E2568105-9550-4F71-A638-B7FE42E66922}";
PipeLineWrapper.IDTSComponentMetaData90
datadestinationComponent =
((dataflowTask as TaskHost).InnerObject as
PipeLineWrapper.MainPipe).ComponentMetaDataCollection.New();
datadestinationComponent.Name =
"Data Destination Component";
datadestinationComponent.ComponentClassID =
OleDBDestinationDataFlowComponentID;
managedOleInstanceDestinationComponent =
datadestinationComponent.Instantiate();
managedOleInstanceDestinationComponent
.ProvideComponentProperties();
The destination dataflow component is created. We need to create a path between the source components output and destination components input so that the data that gets out from the source component will feed directly to the input of the destination component.
PipeLineWrapper.IDTSPath90 pathDD
= ((dataflowTask as TaskHost).InnerObject as
PipeLineWrapper.MainPipe).PathCollection.New();
pathDD.AttachPathAndPropagateNotifications(
sourceComponent.OutputCollection[0],
destinationComponent.InputCollection[0]);
We need to prepare the output of the destination component so that the data can be written into the destination database.
string DatabaseName = "ImportDatabase";
string TableName = "DataTable";
if (destinationComponent
.RuntimeConnectionCollection.Count > 0)
{
destinationComponent
.RuntimeConnectionCollection[0].ConnectionManagerID =
destinationDatabaseConnectionManager.ID;
destinationComponent
.RuntimeConnectionCollection[0].ConnectionManager =
DtsConvert
.ToConnectionManager90(destinationDatabaseConnectionManager);
}
managedOleInstanceDestinationComponent.
SetComponentProperty(
"AccessMode", 0);
managedOleInstanceDestinationComponent.
SetComponentProperty
("AlwaysUseDefaultCodePage", false);
managedOleInstanceDestinationComponent.
SetComponentProperty
("DefaultCodePage", 1252);
managedOleInstanceDestinationComponent.
SetComponentProperty(
"FastLoadKeepIdentity", false);
managedOleInstanceDestinationComponent.
SetComponentProperty(
"FastLoadKeepNulls", false);
managedOleInstanceDestinationComponent.
SetComponentProperty(
"FastLoadMaxInsertCommitSize", 0);
managedOleInstanceDestinationComponent.
SetComponentProperty(
"FastLoadOptions",
"TABLOCK,CHECK_CONSTRAINTS");
managedOleInstanceDestinationComponent.
SetComponentProperty(
"OpenRowset",
string.Format("[{0}].[dbo].[{1}]",
DatabaseName, TableName));
managedOleInstanceDestinationComponent.
AcquireConnections(null);
managedOleInstanceDestinationComponent.
ReinitializeMetaData();
PipeLineWrapper.IDTSInput90 input =
destinationComponent.InputCollection[0];
PipeLineWrapper.IDTSVirtualInput90 vInput
= input.GetVirtualInput();
foreach (PipeLineWrapper.IDTSVirtualInputColumn90 vColumn
in vInput.VirtualInputColumnCollection)
{
if (outputColumnLineageIDs
.ContainsKey(vColumn.LineageID))
{
managedOleInstanceDestinationComponent.
SetUsageType(
input.ID, vInput,
vColumn.LineageID,
PipeLineWrapper.DTSUsageType.UT_READONLY);
}
}
PipeLineWrapper.IDTSExternalMetadataColumn90 exColumn;
foreach (PipeLineWrapper.IDTSInputColumn90 inColumn in
destinationComponent.InputCollection[0]
.InputColumnCollection)
{
exColumn
= destinationComponent.
InputCollection[0]
.ExternalMetadataColumnCollection[
inColumn.Name.Replace(
"\"","")];
Column mappedColumn
= GetTargetColumnInfo(exColumn.Name);
string destName = mappedColumn.Name;
exColumn.Name = destName;
managedOleInstanceDestinationComponent
.MapInputColumn(
destinationComponent.InputCollection[0].ID,
inColumn.ID, exColumn.ID);
}
managedOleInstanceDestinationComponent.ReleaseConnections();
That's enough for the pilot package project. If we run our application it will move the data from the CSV to the destination database.
Using Data Conversion component
So far, our package was assuming the same data type for the destination columns as it is in the source columns (that's why the columns of our data table are defined as varchar). Now we will modify the package so that it can change the data type before moving the database to the destination component.
In order to change the data type we need to use a different data flow component – Data Conversion Component. So our objective package will be something like the following:
We need to create a new data flow component (data conversion component) and we need to place the new component between the source and destination. Therefore, we will now modify the CreateDataFlowTask() method. Let's insert the following lines just after the managedFlatFileInstance.ReleaseConnections(); // close line.
string DataConversionDataflowComponentID
= "{C3BF62C8-7C5C-4F85-83C3-E0B6F6BE267C}";
PipeLineWrapper.IDTSComponentMetaData90
dataconversionComponent =
((dataflowTask as TaskHost).InnerObject as
PipeLineWrapper.MainPipe)
.ComponentMetaDataCollection.New();
dataconversionComponent.Name
= "Data conversion Component";
dataconversionComponent.ComponentClassID =
DataConversionDataflowComponentID;
managedOleInstanceDataConversionComponent =
dataconversionComponent.Instantiate();
managedOleInstanceDataConversionComponent
.ProvideComponentProperties();
dataconversionComponent.InputCollection
[0].ExternalMetadataColumnCollection.IsUsed
= false;
dataconversionComponent
.InputCollection[0].HasSideEffects = false;
We need to create a path between the source component's output and the data conversion component's input.
PipeLineWrapper.IDTSPath90 path =
((dataflowTask as TaskHost).InnerObject as
PipeLineWrapper.MainPipe).PathCollection.New();
path.AttachPathAndPropagateNotifications(
sourceComponent.OutputCollection[0],
dataconversionComponent.InputCollection[0]);
It's time to configure the data conversion component.
PipeLineWrapper.IDTSInput90 input =
dataconversionComponent.InputCollection[0];
PipeLineWrapper.IDTSVirtualInput90 vInput
= input.GetVirtualInput();
foreach (PipeLineWrapper.IDTSVirtualInputColumn90 vColumn
in vInput.VirtualInputColumnCollection)
{
managedOleInstanceDataConversionComponent
.SetUsageType(
input.ID, vInput, vColumn.LineageID,
PipeLineWrapper.DTSUsageType.UT_READONLY);
}
dataconversionComponent.OutputCollection[0]
.TruncationRowDisposition =
PipeLineWrapper.DTSRowDisposition.RD_NotUsed;
dataconversionComponent
.OutputCollection[0].ErrorRowDisposition =
PipeLineWrapper.DTSRowDisposition.RD_NotUsed;
PipeLineWrapper.IDTSOutput90 output =
dataconversionComponent.OutputCollection[0];
foreach (PipeLineWrapper.IDTSInputColumn90 inColumn in
dataconversionComponent.InputCollection
[0].InputColumnCollection)
{
PipeLineWrapper.IDTSOutputColumn90 outputColumn =
dataconversionComponent.OutputCollection[0]
.OutputColumnCollection.New();
outputColumn.Name = inColumn.Name;
Column targetColumn
= GetTargetColumnInfo(inColumn.Name);
int length = targetColumn.Length;
int precision = targetColumn.Precision;
int scale = targetColumn.Scale;
Microsoft.SqlServer.Dts.Runtime.
Wrapper.DataType dataType
= targetColumn.DataType;
outputColumn.SetDataTypeProperties
(dataType, length, precision,
scale, targetColumn.CodePage);
outputColumn.ExternalMetadataColumnID = 0;
outputColumn.ErrorRowDisposition
= PipeLineWrapper.
DTSRowDisposition.RD_RedirectRow;
outputColumn.TruncationRowDisposition
= PipeLineWrapper.DTSRowDisposition.RD_RedirectRow;
PipeLineWrapper.IDTSCustomProperty90 property
= outputColumn.CustomPropertyCollection.New();
property.Name
= "SourceInputColumnLineageID";
property.Value
= GetSourceColumnLineageID(targetColumn.Name);
property
= outputColumn.CustomPropertyCollection.New();
property.Name
= "FastParse";
property.Value = false;
derivedLineageIdentifiers[outputColumn.LineageID] =
outputColumn.Name;
}
Data conversion component configuration is ready now. Lets create a path between the data conversion component and the data destination component to complete the flow of the data.
PipeLineWrapper.IDTSPath90 pathBetweenDCandDD
= ((dataflowTask as TaskHost).InnerObject as
PipeLineWrapper.MainPipe).PathCollection.New();
pathDD.AttachPathAndPropagateNotifications(
dataconversionComponent.OutputCollection[0],
destinationComponent.InputCollection[0]);
We need to update the data destination configuration code as well. Basically we need to use the derivedLineageIdentifiers to retrieve the source lineage id and update the external metadata column's data type of the destination component.
Before doing this, let's quickly change the data table structure into the SQL database as follows:
CREATE TABLE [dbo].[DataTable](
[Name] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[Age] [int] NULL,
[JoinDate] [datetime] NULL,
[Salary] [numeric](18, 9) NULL,
[Retired] [bit] NULL
) ON [PRIMARY]
Notice that we are using different data types now rather using the varchar for all the columns.
if (destinationComponent.RuntimeConnectionCollection.Count > 0)
{
destinationComponent.RuntimeConnectionCollection
[0].ConnectionManagerID =
destinationDatabaseConnectionManager.ID;
destinationComponent
.RuntimeConnectionCollection[0].ConnectionManager =
DtsConvert.ToConnectionManager90
(destinationDatabaseConnectionManager);
}
managedOleInstanceDestinationComponent
.SetComponentProperty
("AccessMode", 0);
managedOleInstanceDestinationComponent
.SetComponentProperty
("AlwaysUseDefaultCodePage",
false);
managedOleInstance.
SetComponentProperty
("DefaultCodePage", 1252);
managedOleInstanceDestinationComponent.
SetComponentProperty
("FastLoadKeepIdentity", false);
managedOleInstanceDestinationComponent
.SetComponentProperty("FastLoadKeepNulls", false);
managedOleInstanceDestinationComponent
.SetComponentProperty
("FastLoadMaxInsertCommitSize", 0);
managedOleInstanceDestinationComponent
.SetComponentProperty
("FastLoadOptions",
"TABLOCK,CHECK_CONSTRAINTS");
managedOleInstanceDestinationComponent
.SetComponentProperty("OpenRowset",
string.Format("[{0}].[dbo].[{1}]",
DatabaseName, TableName));
managedOleInstanceDestinationComponent
.AcquireConnections(null);
managedOleInstanceDestinationComponent
.ReinitializeMetaData();
PipeLineWrapper.IDTSInput90 input =
destinationComponent.InputCollection[0];
PipeLineWrapper.IDTSVirtualInput90 vInput
= input.GetVirtualInput();
foreach (PipeLineWrapper.IDTSVirtualInputColumn90 vColumn in
vInput.VirtualInputColumnCollection)
{
if (derivedLineageIdentifiers.ContainsKey(vColumn.LineageID))
{
managedOleInstanceDestinationComponent.
SetUsageType(
input.ID, vInput,
vColumn.LineageID,
PipeLineWrapper.DTSUsageType.UT_READONLY);
}
}
PipeLineWrapper.IDTSExternalMetadataColumn90 exColumn;
foreach (PipeLineWrapper.IDTSInputColumn90 inColumn in
destinationComponent.InputCollection[0]
.InputColumnCollection)
{
exColumn = destinationComponent
.InputCollection[0]
.ExternalMetadataColumnCollection
[inColumn.Name
.Replace("\"","")];
Column mappedColumn = GetTargetColumnInfo(exColumn.Name);
string destName = mappedColumn.Name;
exColumn.Name = destName;
exColumn.DataType =
mappedColumn.DataType;
managedOleInstanceDestinationComponent.
MapInputColumn(destinationComponent
.InputCollection[0].ID,
inColumn.ID, exColumn.ID);
}
managedOleInstanceDestinationComponent.ReleaseConnections();
Done! Now our package can change the data type during the data importing process.
Handling Error data rows
Now we are going to think about the error data rows. Assume if the CSV contains the following data:
"Name","Age","JoinDate","Salary","Retired"
"Jon Tuite","45","","25.3","False"
"Linda Hamilton","25",2002-01-03 00:00:00,"BAD DATA","True"
"Sen Seldiver","42","2002-01-03 00:00:00,","458.2","True"
"Jon Clerk","DAMAGE","2001-01-03 00:00:00","455.265","False"
"Rose Dalson","25","2004-01-03 00:00:00","55.265","False"
Here notice that the first row contains missing data in the JoinDate field and the second row contains bad data in the Salary field. So the data conversion component will fail to convert these two rows. Now if we want to report these error rows during the data flow task processing, then we need to create an extra destination data flow component into the package. This extra destination component will keep track the error rows and will move them into a SQL database. In order to accomplish this, let's modify the code base again. Now our desired package will look something like this:
You might have already guessed that we are going to use another OLEDB destination component to keep track of the error rows. So let's create a connection manager for the new error destination component (we could use the previous one – but let's create another one so that the error can be moved to any other database rather than the destination database).
private void CreateErrorDatabaseConnection()
{
string OleDBMoniker = @"OLEDB";
errorDatabaseConnectionManager
= package.Connections.Add(OleDBMoniker);
errorDatabaseConnectionManager.ConnectionString
= ConnectionString;
errorDatabaseConnectionManager.Name
= "SSIS error Connection Manager for Oledb";
errorDatabaseConnectionManager.Description
= string.Concat("SSIS Connection Manager for ");
}
We need to create another table to keep track of the error rows. So let's create a table using the following SQL script:
CREATE TABLE [ErrorTable] (
[Name] VARCHAR(50),
[Age] VARCHAR(50),
[JoinDate] VARCHAR(50),
[Salary] VARCHAR(50),
[Retired] VARCHAR(50),
[ErrorCode] INTEGER,
[ErrorColumn] INTEGER
)
We will modify the CreateDataFlowTask() to implement this error handling functionality. Let's append the following code into that method.
PipeLineWrapper.IDTSComponentMetaData90 errorTrackerComponent =
((dataflowTask as TaskHost).InnerObject
as PipeLineWrapper.MainPipe).ComponentMetaDataCollection.New();
errorTrackerComponent.ComponentClassID =
OleDBDestinationDataFlowComponentID;
managedOleInstanceErrorComponent =
errorTrackerComponent.Instantiate();
managedOleInstanceErrorComponent
.ProvideComponentProperties();
errorTrackerComponent.Name
= "Error Tracker component";
Naturally we need to establish a path between the data conversion error output and the error destination components input. So do it as follows:
PipeLineWrapper.IDTSPath90 pathDE
= ((dataflowTask as TaskHost).InnerObject as
PipeLineWrapper.MainPipe).PathCollection.New();
pathDE.AttachPathAndPropagateNotifications(
dataconversionComponent.OutputCollection[1],
errorTrackerComponent.InputCollection[0]);
As we discussed earlier in the article, the output collection contains two outputs; one is the data and another is for error outputs. So we have created the new path with dataconversionComponent.OutputCollection[1].
We will now configure the error destination component.
if (errorTrackerComponent.RuntimeConnectionCollection.
Count > 0)
{
errorTrackerComponent
.RuntimeConnectionCollection[0].ConnectionManagerID =
errorDatabaseConnectionManager.ID;
errorTrackerComponent.
RuntimeConnectionCollection[0].ConnectionManager =
DtsConvert.ToConnectionManager90
(errorDatabaseConnectionManager);
}
managedOleInstanceErrorComponent.
SetComponentProperty
("AccessMode",
0);
managedOleInstanceErrorComponent.
SetComponentProperty
("AlwaysUseDefaultCodePage",
false);
managedOleInstanceErrorComponent.
SetComponentProperty
("DefaultCodePage", 1252);
managedOleInstanceErrorComponent.
SetComponentProperty(
"FastLoadKeepIdentity", false);
managedOleInstanceErrorComponent.
SetComponentProperty
("FastLoadKeepNulls", false);
managedOleInstanceErrorComponent.
SetComponentProperty(
"FastLoadMaxInsertCommitSize", 0);
managedOleInstanceErrorComponent.
SetComponentProperty
("FastLoadOptions",
"TABLOCK,CHECK_CONSTRAINTS");
managedOleInstanceErrorComponent.
SetComponentProperty
("OpenRowset",
string.Format("[{0}].[dbo].[{1}]",
DatabaseName, ErrorTableName));
managedOleInstanceErrorComponent.AcquireConnections(null);
managedOleInstanceErrorComponent.ReinitializeMetaData();
PipeLineWrapper.IDTSInput90 input =
errorTrackerComponent.InputCollection[0];
PipeLineWrapper.IDTSVirtualInput90 vInput
= input.GetVirtualInput();
foreach (PipeLineWrapper.IDTSVirtualInputColumn90 vColumn in
vInput.VirtualInputColumnCollection)
{
managedOleInstanceErrorComponent.SetUsageType(
input.ID, vInput, vColumn.LineageID,
PipeLineWrapper. DTSUsageType.UT_READONLY);
}
PipeLineWrapper.IDTSExternalMetadataColumn90 exColumn;
foreach (PipeLineWrapper.IDTSInputColumn90 inColumn in
errorTrackerComponent.InputCollection[0]
.InputColumnCollection)
{
exColumn
= errorTrackerComponent.InputCollection[0].
ExternalMetadataColumnCollection
[inColumn.Name.Replace("\"","")];
exColumn.DataType = Microsoft.SqlServer.
Dts.Runtime.Wrapper.DataType.DT_STR;
managedOleInstanceErrorComponent.
MapInputColumn(errorTrackerComponent.
InputCollection[0].ID,
inColumn.ID, exColumn.ID);
}
managedOleInstanceErrorComponent.ReleaseConnections();
An error component typically stores the error code and error column lineage id along with the entire row data. So the error data table contains the columns available into the CSV file along with two extra columns (errorCode and errorColumn).
In this way we will only find the error code and the error row lineage ID (which is simply an identifier) of the output column. But we can write some extra code to find out an error description along with the error row name rather its identifier. I found an interesting article on this.
Now if we run the application it will move those two error rows into the error table and move all other rows into the datatable.
Using Derived Column Component
The CSV file that we last discussed has two error rows. And our current implementation moves both rows into the error destination table. But what we will do, if we need to bring the first row into the destination database rather than moving it to the error destination? For example, let's assume our destination data table schema says that it can contains null in the JoinDate and salary fields. But our current implementation will never move the missing data rows into the destination database. It will always fail to convert the missing data and finally considers it as an error row. Therefore for some businesses, may be it will be a problem indeed. To resolve this problem, we can replace the data conversion component with a Derived column component to get rid of this problem. Derived column component is an awesome component that is mainly used to transform the data. The Derived Column transformation creates new column values by applying expressions to transformation input columns. An expression can contain any combination of variables, functions, operators, and columns from the transformation input. The result can be added as a new column or inserted into an existing column as a replacement value. The Derived Column transformation can define multiple derived columns, and any variable or input columns can appear in multiple expressions. For more details on this please read MSDN.
In order to replace the data conversion component with a derived column component we need to make some minor change into the existing code base that we developed so far.
Creating a derived column component is exactly the same as creating a data conversion component except for the component class ID. The Component class id for a derived column component is "{9CF90BF0-5BCC-4C63-B91D-1F322DC12C26}".
string DerivedColumnDataflowComponentID
= "{9CF90BF0-5BCC-4C63-B91D-1F322DC12C26}";
PipeLineWrapper.IDTSComponentMetaData90
derivedColumnComponent =
((dataflowTask as TaskHost).InnerObject as
PipeLineWrapper.MainPipe).ComponentMetaDataCollection.New();
derivedColumnComponent.Name
= "Derived Column Component";
derivedColumnComponent.ComponentClassID =
DerivedColumnDataflowComponentID;
managedOleInstanceDerivedColumnComponent =
derivedColumnComponent.Instantiate();
managedOleInstanceDerivedColumnComponent.
ProvideComponentProperties();
derivedColumnComponent.InputCollection[0].
ExternalMetadataColumnCollection.IsUsed =
false;
derivedColumnComponent.
InputCollection[0].HasSideEffects = false;
As you can see, the component creation is pretty much the same as we did for the data conversion component creation. Now we will write the configuration code for the derived column component. This is also the same as the way in which we configured the data conversion component – except here we will create a new property for the expression. The configuration code is as follows:
CManagedComponentWrapper managedOleInstance =
derivedColumnDataFlowComponent.ComponentInstance;
IDTSInput90 input =
derivedColumnDataFlowComponent.
InnerObject.InputCollection[0];
IDTSVirtualInput90 vInput = input.GetVirtualInput();
Dictionary<string, int> lineAgeIDs
= new Dictionary<string, int>();
foreach (IDTSVirtualInputColumn90 vColumn in
vInput.VirtualInputColumnCollection)
{
managedOleInstance.SetUsageType(
input.ID, vInput, vColumn.LineageID,
DTSUsageType.UT_READONLY);
lineAgeIDs[vColumn.Name] = vColumn.LineageID;
}
derivedColumnDataFlowComponent
.InnerObject.OutputCollection[0].TruncationRowDisposition =
DTSRowDisposition.RD_NotUsed;
derivedColumnDataFlowComponent.
InnerObject.OutputCollection[0].ErrorRowDisposition =
DTSRowDisposition.RD_NotUsed;
IDTSOutput90 output = derivedColumnDataFlowComponent
.InnerObject.OutputCollection[0];
foreach (IDTSInputColumn90 inColumn in
derivedColumnDataFlowComponent.
InnerObject.InputCollection[0].InputColumnCollection)
{
IDTSOutputColumn90 outputColumn =
derivedColumnDataFlowComponent.
InnerObject.
OutputCollection[0].OutputColumnCollection.New();
outputColumn.Name = inColumn.Name;
Column targetColumn = GetTargetColumnInfo(inColumn.Name);
int length = targetColumn.ColumnLength;
int precision = targetColumn.Precision;
int scale = targetColumn.Scale;
Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType
dataType = targetColumn.DataType;
int codePage = 0;
if (dataType ==
Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_STR)
{
precision = 0;
scale = 0;
codePage = 1252;
}
else if(dataType ==
Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_NUMERIC)
{
length = 0;
}
else if (dataType ==
Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_DATE)
{
length = 0;
precision = 0;
scale = 0;
}
else if (dataType ==
Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_BOOL)
{
length = 0;
precision = 0;
scale = 0;
}
outputColumn.SetDataTypeProperties
(dataType, length, precision, scale, codePage);
outputColumn.ExternalMetadataColumnID = 0;
outputColumn.ErrorRowDisposition =
DTSRowDisposition.RD_RedirectRow;
outputColumn.TruncationRowDisposition =
DTSRowDisposition.RD_RedirectRow;
string expression = string.Empty;
string friendlyExpression = string.Empty;
GetExpressionString(ref expression,
ref friendlyExpression,
dataType, length, precision,
scale,
lineAgeIDs, outputColumn.Name);
IDTSCustomProperty90 property =
outputColumn.CustomPropertyCollection.New();
property.Name = "Expression";
property.Value = expression;
property = outputColumn.CustomPropertyCollection.New();
property.Name
= "FriendlyExpression";
property.Value
= friendlyExpression;
derivedLineageIdentifiers[outputColumn.LineageID]
= outputColumn.Name;
We defined a method here named GetExpressionString() which is actually creating the expression string. Let's implement the method now.
private void GetExpressionString(ref string expression, ref string
friendlyExpression,
Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType dataType,
int length, int precision, int scale,
Dictionary<string, int> lineAgeIDs,
string columnName)
{
expression = string.Empty;
friendlyExpression = string.Empty;
int lineageID = lineAgeIDs[columnName];
switch (dataType)
{
case Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_STR:
expression =
string.Format("#{0}",lineageID);
friendlyExpression = string.Format("{0}", columnName);
break;
case Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_I4:
expression =
string.Format("[ISNULL](#{0}) || #{1} ==
\"\" ? NULL(DT_I4) : (DT_I4)#{2}",
lineageID, lineageID, lineageID);
friendlyExpression = string.Format("ISNULL([{0}]) || [{1}] ==
\"\" ? NULL(DT_I4) : (DT_I4)[{2}]",
columnName, columnName, columnName);
break;
case Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_DECIMAL:
case Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_NUMERIC:
expression = string.Format("[ISNULL](#{0}) || #{1} ==
\"\" ? NULL(DT_NUMERIC,{2},{3}) : (DT_NUMERIC,{4},{5})#
{6}", lineageID, lineageID, precision, scale, precision,
scale, lineageID);
friendlyExpression =
string.Format("[ISNULL]([{0}]) || [{1}] ==
\"\" ? NULL(DT_NUMERIC,{2},{3}) : (DT_NUMERIC,{4},
{5})[{6}]", columnName, columnName, precision, scale,
precision, scale, columnName);
break;
case Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_DATE:
expression = string.Format("[ISNULL](#{0}) || #{1} ==
\"\" ? NULL(DT_DATE) : (DT_DATE)#{2}", lineageID,
lineageID, lineageID);
friendlyExpression = string.Format("ISNULL([{0}]) || [{1}] ==
\"\" ? NULL(DT_DATE) : (DT_DATE)[{2}]",
columnName, columnName, columnName);
break;
case Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_I8:
expression = string.Format("[ISNULL](#{0}) || #{1} ==
\"\" ? NULL(DT_I8) : (DT_I8)#{2}", lineageID,
lineageID, lineageID);
friendlyExpression = string.Format("ISNULL([{0}]) || [{1}] ==
\"\" ? NULL(DT_I8) : (DT_I8)[{2}]",
columnName, columnName, columnName);
break;
case Microsoft.SqlServer.Dts.Runtime.Wrapper.DataType.DT_BOOL:
expression = string.Format("[ISNULL](#{0}) || #{1} ==
\"\" ? NULL(DT_BOOL) : (DT_BOOL)#{2}",
lineageID, lineageID, lineageID);
friendlyExpression =
string.Format("ISNULL([{0}]) || [{1}] ==
\"\" ? NULL(DT_BOOL) : (DT_BOOL)[{2}]",
columnName, columnName, columnName);
break;
default:
expression = string.Format("#{0}", lineageID);
friendlyExpression =
string.Format("{0}", columnName);
break;
}
}
So that's all for our derived column implementation. Now our package should bring the missing rows into the data destination table – as it is supposed to. Although the derived column usually does the real data derived tasks, it can be used to resolve this issue as well.
Conclusion
In this article I just described the way in which we can programmatically use different data flow components to meet our custom purpose. I hope you will enjoy this.

