Contents
I was working on building an RPC server the other day when I ran into an interesting threading related problem. RPC servers are, as you might know, simple global functions implemented in your executable that the RPC runtime invokes whenever remote clients initiate a call. Here's a block diagram that shows how it works:
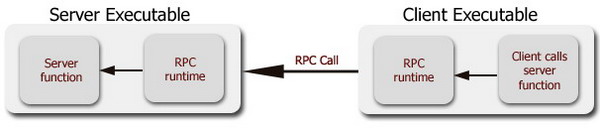
One of the key issues here is that the RPC runtime will call your implementation on an arbitrary thread that it creates/draws out from a thread pool. For the application that I was working on, it so happened that there were about 20 functions exposed from the server and all of them needed access to a window that had been popped up on the screen from the server EXE's primary thread. This, of course, presents us with a problem because the Win32 UI system insists that any kind of manipulation on a window must always occur from the thread that created the window. Now, given that my server functions will always be called on arbitrary threads, I had to figure out some way of transferring control from the RPC thread to the thread that had created the window. This article presents a technique that will let us do this by taking advantage of the way function calls occur on 32-bit x86 systems.
Before we proceed, I'd like to set some terminology straight. Just so I don't hasten my inexorable descent into carpal tunnel syndrome and lose my means for livelihood any sooner than is strictly necessary, I am going to use the term UI thread to refer to the thread that created the window and the term worker thread while referring to all other threads. The primary distinguishing factor between the two, apart from the fact that the former has created a window, is the presence of a message loop in it. A UI thread will have a message pump going that, typically, looks something like this:
MSG msg;
BOOL bReturn;
while( ( bReturn = GetMessage( &msg,
NULL,
0, 0 ) ) != FALSE )
{
if( bReturn == -1 )
{
}
else
{
TranslateMessage( &msg );
DispatchMessage( &msg );
}
}
A worker thread, on the other hand, just does a specific task and terminates.
It is useful to remember that this distinction is only logical, in that from the operating system's (OS) and the CPU's perspective, all threads are created equal and are treated likewise, except of course, when one of them has its thread priority boosted, in which case the OS scheduler gives it the right of way. Now that we've got the terminology out of the way, let's see how you can switch some threads around for fun and profit!
First, I'll show you how you can use the header tswitch.h in your own C++ project for switching the thread on which a given routine executes. For it to be applicable, however, your project and your routine must satisfy certain pre-requisites:
- Your solution must feature a window of some sort (duh!).
- Your routine must only take and return real and/or integral type parameters. Pointers are also allowed. This means that your function parameters and return values must be
ints, floats, chars, or pointers. This only leaves out doubles, structures, and unions that are passed and returned by value. We'll see why this restriction exists later on in the article. - Your application must target the 32-bit x86 architecture. x64 is not supported.
- Your routine must use the
__stdcall or the __cdecl function calling convention.
Assume that you have a function called TheGreatDoofus that is executing on a worker thread. You need it to run on the thread that has created a window, the handle to which is available to you in the variable hWnd. Here's how you'd use tswitch.h to switch the execution of the routine to the UI thread.
#include "tswitch.h"
void __cdecl TheGreatDoofus( HWND hWnd,
int foo,
char *bar,
AStructure *pStruct )
{
THREAD_SWITCH( hWnd, TheGreatDoofus, 5, ccCdecl )
SetWindowText( hWnd,
_T( "I switched the great doofus!" ) );
}
Here's how the macro THREAD_SWITCH has been declared in tswitch.h:
#define InvokeRequired(hwnd) ( GetCurrentThreadId() != \
GetWindowThreadProcessId( hwnd, NULL ) )
#define THREAD_SWITCH(hwnd, fn, params, conv) \
if( InvokeRequired(hwnd) ) \
{ \
SendMessage( hwnd, WM_INVOKE, \
(WPARAM)new ThreadSwitchContext( (DWORD_PTR)fn, \
ThreadSwitchContext::GetEBP(), params, conv ), 0 ); \
return; \
}
I'll explain the code that the macro expands to in a moment. Let's look at another example where the function returns a 32-bit LONG value and happens to use the __stdcall function calling convention (we'll examine calling conventions in some detail later):
#include "tswitch.h"
LONG __stdcall TheGreatDoofus( HWND hWnd,
int foo,
char *bar,
AStructure *pStruct )
{
THREAD_SWITCH_WITH_RETURN( hWnd, TheGreatDoofus,
5, ccStdcall, LONG )
SetWindowText( hWnd,
_T( "I switched the great doofus!" ) );
return 0L;
}
The parameters are exactly the same as THREAD_SWITCH except that in this case, it requires one additional parameter to specify the type of the return value (LONG in the example above). And finally, in your window procedure, you'd need to handle a message called WM_INVOKE, like so:
LRESULT CALLBACK WndProc( HWND hWnd, UINT message,
WPARM wParam, LPARAM lParam )
{
if( message == WM_INVOKE )
{
THREAD_SWITCH_INVOKE(wParam);
}
return DefWindowProc( hWnd, message, wParam, lParam );
}
If you're using MFC, then you'll have to add an ON_REGISTERED_MESSAGE message map entry. The MFC version might look like this:
BEGIN_MESSAGE_MAP( CDoofusFrame, CFrameWnd )
ON_REGISTERED_MESSAGE( WM_INVOKE, OnInvoke )
END_MESSAGE_MAP()
LRESULT CDoofusFrame::OnInvoke( WPARAM wParam,
LPARAM lParam )
{
THREAD_SWITCH_INVOKE( wParam );
}
That's it! Couldn't get simpler, could it?! Now, we take a look at the deep dark implementation secrets!
Before we get to the deep dark secrets, however, you'll need to know a bit of x86 assembly language programming. I'll cover just enough assembly in this section so you can follow along without too much trouble. While I am no assembly expert, I will, however, try and share my smattering knowledge of it. In fact, we'll only look at four assembly instructions now, because those are the only instructions used here!
A program in assembly is composed of a sequence of instructions. Well, aren't all programs written in just about any language a sequence of instructions, you rightfully ask! Yes, indeed they are. The key difference is that, with assembly, most of the time, a single instruction actually does only a single thing (as opposed to a line of C# code, for instance, which might set off a chain of events on computers distributed all over the planet, and you might not even know about it)! Another aspect of programming using assembly is that you are coding close to the metal, so to speak. You find yourself having to deal with CPU registers, stacks etc., directly.
The notion of a stack data structure is central to assembly language programming (in fact, we use stacks even when using C and C++ - all function parameters and local variables are allocated on the stack; I am going to assume that you know what it is). As you might know, the stack is a last in first out structure. There are a set of assembly instructions that allow you to manipulate it in various ways. To push an item on to the stack, you use an instruction called, well, push! Here's a sample that pushes the value 10 on to the stack.
push 10
Simple, eh?! In the code given above, push is the instruction code and 10 is the operand. If you are using Visual C++, then you can directly embed assembly into your source files. Here's an example:
void DoTheAssemblyJiggyWiggy()
{
__asm push 20
__asm
{
push 10
push 20
push 30
}
int value = 30;
__asm push value
}
What's really neat about embedded assembly is that the compiler allows you to refer to and access local variables from the assembly! In the snippet above, for example, the number 30 stored in the variable value is pushed on to the stack by referring to it from the assembly.
CPU registers are the fastest form of computer memory available to a CPU. There are various kinds of registers on a typical CPU, differentiated by size and purpose. There are four general purpose registers called - for lack of better names - A, B, C, and D! But, somebody thought those names were too short, and decided to append an X to each one. So, we ended up having AX, BX, CX, and DX, instead. These registers are all 16 bits wide, and you can even access their low and high bytes separately, if you are so inclined. For example, AH and AL refer to the high and low bytes of the register AX. You can use a similar scheme for BX, CX, and DX as well. On 32-bit CPUs, the size of these registers became 32-bits wide. The 32-bit versions simply had an E prepended to them. The same four registers, therefore, when 32-bits wide, are called - EAX, EBX, ECX, and EDX.
So, how do you assign a value to one of these registers? You use the mov instruction. Unlike push, mov requires two operands. The first one is the destination where the assigned value must be stored, and the second is the value that is to be assigned. Here're a few examples:
void DoTheAssemblyJiggyWiggyAgain()
{
__asm mov ax, 10
__asm
{
mov bl, 5
mov bh, 5
}
unsigned long value = 0xFFFFFFFF;
__asm mov ecx, value
}
To add two values, you use the add instruction. Like mov, add requires two operands. It simply accumulates the second operand value into the first. The following snippet, for instance, adds 10 to whatever happens to be stored in ECX. If ECX had had the value 5, then after the following line is executed, it will have the value 15.
add ecx, 10
A function call is made using the call instruction. Here's an example:
void Dooga()
{
}
void DoTheAssemblyJiggyWiggyOnceAgainPlease()
{
__asm call Dooga
}
That's it! That's all the assembly you'll need to know to understand thread switching internals. You might get to know a few more registers and learn about two other small instructions off-hand, but otherwise, this is it. And, you thought this was going to be hard!
Let's now take an under-the-hood look at how function calls really work on 32-bit x86 systems. Consider the following insultingly simple C++ code:
int Add( int value, char ch )
{
return (value + 10);
}
void Booga()
{
int value = 10;
value = Add( value, 'a' );
}
Here's the disassembly for this code snippet, generated using DUMPBIN. I've edited the output a bit so that we can focus on the important stuff. Let's try and dissect it.
?Add@@YAHHD@Z (int __cdecl Add(int,char)):
push ebp
mov ebp,esp
mov eax,dword ptr [ebp+8]
add eax,0Ah
pop ebp
ret
?Booga@@YAXXZ (void __cdecl Booga(void)):
push ebp
mov ebp,esp
push ecx
mov dword ptr [ebp-4],0Ah
push 61h
mov eax,dword ptr [ebp-4]
push eax
call ?Add@@YAHHD@Z
add esp,8
mov dword ptr [ebp-4],eax
mov esp,ebp
pop ebp
ret
The first thing that might have caught your eye is the keyword __cdecl that seems to have been surreptitiously inserted between the return type and the function name. Here's what I am talking about:
(int ^__strong lang=<span class="code-string">asm">__cdecl Add(int)):
__cdecl is an extension keyword (i.e., a keyword that is not part of the C or C++ standards) used by the Visual C++ compiler to identify functions that are to use the C function calling convention. A function calling convention is used to tell the compiler exactly how parameters are to be passed to a function and how the stack state should be restored after the function call is complete. We review here two of the most commonly used calling conventions on Windows systems - __cdecl and __stdcall.
The __cdecl calling convention is the default for C and C++ programs when using the Visual C++ compiler; i.e., if you do not explicitly specify a calling convention, then the compiler would use __cdecl. With this convention, function parameters are passed via the stack in right-to-left order. Further, the caller is expected to restore the stack state after the function call is complete. If you wanted to call the Add function shown above, passing the value 10 and 'a' to it, then this is how you would do it in assembly:
push 97
push 10
call Add
add esp, 8
ESP is a special purpose register that the CPU uses to track the next available location on the stack. Of the total address space available to a process, stack addresses start out from the high end, and heap addresses start out from the low end. Here's a picture depicting this:

What this means is that when you push something on to the stack, ESP is reduced by the size of the data that was pushed. For example, if ESP is currently pointing to the address 100, then pushing a 4 byte integer would cause the register value to be decremented by 4 so that after the push, ESP would have the value 96. Freeing this space is a simple matter of adding 4 back to ESP using the assembly instruction add. In the code snippet above, since we are using the __cdecl calling convention, it is the caller's responsibility to restore the stack state after the function call completes, which we do so by adding 8 to ESP. We add 8 because we pushed two 4 byte values on to the stack before the call instruction. Even though the second parameter is a 1 byte char, values pushed on the stack need to be 32-bits wide.
As you might imagine, using the __cdecl function calling convention results in code bloat because the add instruction to appropriately adjust ESP must be inserted into the code stream at every point the function call is made.
The __stdcall calling convention is similar to __cdecl in that parameters are passed via stack in right-to-left order. The stack restoration responsibility, however, resides with the called function. If the function Add, as defined above, had been set to use the __stdcall calling convention, then the code for calling it would look like this in assembly:
push 97
push 10
call Add
As you might have noticed, we do not restore the stack after the function call. The function Add would have done this for us.
Now that we've seen the effect that calling conventions have upon the code that is generated while making a function call, let us next take a look at the code that is generated inside the called function itself. I reproduce the disassembly for the function Add here, which as you might recall, was configured to use the __cdecl calling convention.
?Add@@YAHHD@Z (int __cdecl Add(int,char)):
push ebp
mov ebp,esp
mov eax,dword ptr [ebp+8]
add eax,0Ah
pop ebp
ret
The text ?Add@@YAHHD@Z is the decorated (mangled) name of the function Add. The first two lines represent the function prologue, and the last two lines the function epilogue. Everything in between is the function body. These are automatically inserted by the compiler for all functions (except when the calling convention has been marked as __naked).
The EBP register is used to store the base pointer for a given function. The base pointer points to the location on the stack from where the parameters for the current function can be accessed. As we saw a while back, calling a function like Add involves the pushing of parameters on to the stack, followed by a call instruction. The call instruction does two things - it first pushes the return address on to the stack, and then transfers control to the called address. So, when you're at the first instruction in the function Add, here's what the stack looks like:
The first thing that Add does is to push the current value of EBP, which contains the base pointer of the caller, on to the stack. It does this so that it can restore the caller's base pointer when the function returns. It then loads the current value of ESP into EBP to establish the current function's base pointer. Here's what the stack looks like once the function prologue has been executed:
In any given function, therefore, you can access all the parameters passed to it by adding 8 bytes to the address stored at EBP. We add 8 bytes in order to skip the caller's EBP and the return address.
The function epilogue does the reverse - it pops the caller's base pointer value from the stack into the EBP register and executes a ret instruction that causes the CPU to shift control to the return address that's stored at the top of the stack. The pop instruction, as you might have guessed, does the inverse of push - it reads whatever happens to be at the location pointed at by ESP into the destination that you give as the instruction's operand and adds 4 to ESP.
So, is that all there is to calling functions? Well, not really. There are quite a few other calling conventions that I haven't covered here (__fastcall, __naked, __thiscall) because they aren't relevant to the topic under discussion. But, you should be able to easily find more information on these somewhere else on the great internet!
Now that we've covered all the background, thread switching itself is quite straightforward. Here's what we do from the worker thread:
- We check if the current routine is executing on the window's thread by comparing the value that
GetCurrentThreadId returns with the value that GetWindowThreadProcessId returns. GetWindowThreadProcessId returns the ID of the thread on which the given window has been created. In tswitch.h, this check is performed from a macro called InvokeRequired. Here's how it has been defined:
#define InvokeRequired(hwnd) ( GetCurrentThreadId() != \
GetWindowThreadProcessId( hwnd, NULL ) )
If the routine is not running on the UI thread, then we send a message called WM_INVOKE to the given window, along with the following information packed up in a data structure called ThreadSwitchContext, via WPARAM:
- Address of the function to be called under the UI thread's context.
- The
EBP value of the current routine. - The number of parameters accepted by the current function.
- And, the calling convention used by it.
This is how the ThreadSwitchContext structure has been declared:
struct ThreadSwitchContext
{
DWORD_PTR Address;
DWORD_PTR Ebp;
BYTE ParamsCount;
CallingConvention Conv;
ThreadSwitchContext( DWORD_PTR addr, DWORD_PTR ebp,
BYTE count, CallingConvention conv ) :
Address( addr ), Ebp( ebp ),
ParamsCount( count ), Conv( conv )
{
}
... other structure members here ...
};
Please note that we send WM_INVOKE to the target window using SendMessage, and not PostMessage. This is important because SendMessage is a blocking call that will not return till the message under question has been processed by the target window, which is a key requirement for this technique to work. Basically, we need the stack frame of the worker thread to remain intact till WM_INVOKE has been processed completely.
In the window procedure of the target window, we process WM_INVOKE like so. This implementation is available in the ThreadSwitchContext::Invoke method.
- We cast the
WPARAM parameter to a ThreadSwitchContext object and retrieve the worker thread's base pointer value stored in ThreadSwitchContext::Ebp. - We add
8 to ThreadSwitchContext::Ebp to access the first parameter to the function. - We then launch a loop that iterates
ThreadSwitchContext::ParamsCount times. During each iteration, we access the worker thread routine's input parameter in the order that it was pushed on to that thread's stack, and push it on to the local thread's stack. Here's what it looks like:
LPBYTE params = (LPBYTE)Ebp;
for( int i = ParamsCount - 1 ; i >= 0 ; --i )
{
DWORD_PTR param = *((PDWORD_PTR)(params + (i * sizeof(DWORD_PTR))));
__asm push param
}
Once this is done, the local stack is fully set up for making a call to the worker thread routine. We do the invocation using the assembly call instruction.
DWORD_PTR address = Address;
__asm call address
Once the called routine completes execution, the return value will be made available in the register EAX. We save this value into a local variable.
DWORD_PTR dwEAX;
__asm mov dwEAX, eax
And finally, if the calling convention of the routine is __cdecl, then we clean up the stack by adding the space that we had taken off it while pushing the parameters.
DWORD stack = ( ParamsCount * sizeof( DWORD ) );
if( Conv == ccCdecl )
{
__asm add esp, stack;
}
That's all there is to it really! The only other interesting implementation detail is the mechanism we use to access the worker thread's EBP register. I wanted the enabling of thread switching in a given routine to be as painless as possible, which is why I wrapped up all the gory details in friendly macros such as THREAD_SWITCH and THREAD_SWITCH_WITH_RETURN. One problem that I ran into while doing this was with the use of embedded assembly in macros, in that you couldn't! Inline assembly in a macro seems to really mess up the pre-processor! So, this became a problem when I tried to access the local routine's EBP register which, had this problem not existed, I would have done like this:
#define THREAD_SWITCH(hwnd, fn, params, conv) \
if( InvokeRequired(hwnd) ) \
{ \
DWORD dwEBP; \
__asm mov dwEBP, ebp
SendMessage( hwnd, WM_INVOKE, \
(WPARAM)new ThreadSwitchContext( (DWORD_PTR)fn, \
dwEBP, params, conv ), 0 )
return
}
Since this was producing weird compilation errors, I decided to use a helper function such as the following to access the EBP value and use it from the macro:
DWORD_PTR GetEBP()
{
DWORD_PTR dwEBP;
__asm mov dwEBP, ebp
return dwEBP
}
If you've been reading the article carefully, then you'd know that this cannot work! It cannot work because, now, GetEBP itself is a function and has its own base pointer, which naturally is different from the caller's. So then, I modified GetEBP to look like this:
DWORD_PTR GetEBP()
{
DWORD_PTR dwEBP;
__asm mov dwEBP, ebp
return *( (PDWORD_PTR)dwEBP )
}
The idea is to take advantage of the fact that the value pointed at by the local function's base pointer is the caller's base pointer (recall that to access the function parameters, we had to skip this and the return address). Now, everything was hunky dory, till I did a release build, i.e., a build having all the compiler optimizations turned on. Now, suddenly, I found my parameters having strange values after the thread switch. As it turned out, since GetEBP was so small, the compiler went ahead and inlined it! Talk about coming around a full circle! So finally, I settled on the following definition for GetEBP:
DWORD_PTR GetEBP()
{
DWORD_PTR dwEBP;
__asm mov dwEBP, ebp
#ifdef _DEBUG
return *( (PDWORD_PTR)dwEBP )
#else
return dwEBP
#endif
}
As I had mentioned when listing out the pre-requisites, the technique described here cannot be used with functions that accept structures, unions, or double parameters by value. The same thing applies for function return values as well. The reason why this is so is that our thread switching logic assumes that each parameter to the function consumes exactly 4 bytes on the stack. With structures, unions, and doubles, this might not be the case.
So, there it is! You can download tswitch.h here, and you can download a demo project here. Feel free to report bugs and give feedback on this article's discussion forum, and I'll be happy to respond and oblige!
- September 16, 2007: Article first published.

