Contents
Introduction
The first step to intelligent image/video processing for face recognition in uncontrolled scenery with complex backgrounds (outdoor environments, airports, train/bus stations) is face detection. The precision of the latter heavily depends on your face recognition results. Typically scientists investigating in that field do not have the time or the ability to develop optimized C++ code ready for commercial use and confine themselves to the Matlab development process only.
The purpose of this article is to provide an SSE optimized, C++ library for face detection that I developed, so you can start using it right now in your video surveillance applications. The classifiers supplied with it were trained on my webcam images collected over a period of time with different lighting conditions and it detects me without a glitch in real time. For non-face data, I used some webcam snapshots of a background. Extracted rectangles from the image are filtered with Gaussian, after which histogram normalization occurs, so the faces, if present, after applying that procedure become quite similar in appearance. You can find the algorithm behind it described below, and if you experience problems with your particular identity try to retrain the networks on numerous databases available on the Internet with a lot more different faces in the training set - the one having the same size as my lib of the face image 19x19 is CBCL. It is over 100 MB and I've no access to broadband currently.
Background
An understanding of wavelet-analysis, dimensionality reduction methods (PCA, LDA, ICA), artificial neural networks (ANN), support vector machines (SVM), SSE programming, image processing, morphological operations (erosion, dilation), histogram equalization, image filtering, C++ programming and some face detection background would be desirable. I'm not going to describe every point mentioned as it would take a lot of writing, you should rather have a look at Google or Wiki for numerous tutorials available.
Using the Code
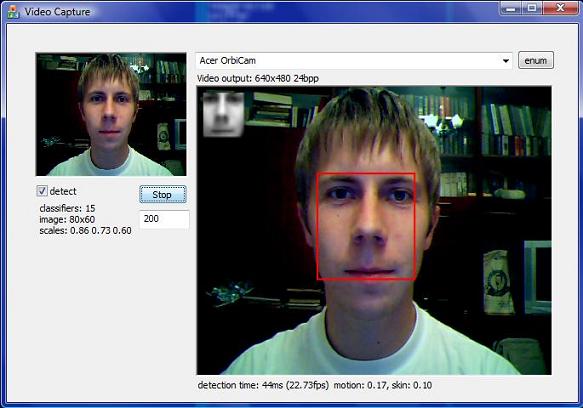
The MFC interface to the program is taken from my other project Video Preview and Frames Capture to Memory with SampleGrabber in Buffered Mode. Though the compiled demo version was initialized to 640x480 video stream, if your webcam supports only different frame rates you have to recompile it initializing m_Width and m_Height variables to your resolution in CVidCapDlg constructor. In case your webcam runs in 320x240, that is two times smaller than 640x480 you have to also change m_ResizeRatio from 0.125 to 0.25(twice the number). The reason behind such modifications is that in order to run in real time, it is expensive to search over the initial 640x480 image for 19x19 sized faces (very, very small ones). I downscale the image using the code from my article Fast Dyadic Image Scaling with Haar Transform to 0.125 of its original size: 80x60. Now if you start looking over 19x19 rectangles in that downscaled image for a face, its actual size on a 640x480 image will be 8 times bigger: 152x152. The down sampling benefits the algorithm not only in speed of computation but in getting a coarse grained version of the face without noise and superfluous details. And under such down sampling all faces become quite similar in appearance which facilitates detection. The 152x152 size of the face on a 640x480 image is as if it is situated about the distance you sit down in front of your monitor. So you should place yourself at that distance or closer if you want the computer to see you. For your 320x240 webcam video stream, you have to scale down the image to only 0.25 of its size. The downscaled 80x60 image is further interpolated to 0.86, 0.73 and 0.6 of its size. So the pyramid is built and the search for a face is implemented on that pyramid of images, which allows the computer to 'see' the size of the face, the closer you move to the webcam, the bigger the rectangle of the face will be identified.
To start the detection process, click the enum button to select the video source device, choose capture rate in milliseconds, default one is 1000 (frame captured every second), check detect box to load or unload classifiers, you will get the cvInfo replaced with:
classifiers: 15
image: 80x60
scales: 0.86, 0.73, 0.60
The loaded classifiers reside in the files face.nn, pca.nn, preflt.nn and skin.nn in the same directory with the executable. You may skip skin detection process in cases of bad lighting condition by simply deleting the skin.nn file, in that case the status for classifiers would be:
classifiers: 11
image: 80x60
scales: 0.86, 0.73, 0.60
Now click the Run button and watch for your face being detected in the central large static control. It detects the face on my 2.2Ghz AMD MK-38 at about 15-25fps, but sometimes runs even at 35-50fps - have a look at the results section. So I may set the frames capture rate to 100 (10 frames per second) without too much processor overload.
The Algorithm
The algorithm is not novel and has been reported in many scientific papers. The downscaled image is smoothed with Gaussian filter to reduce noise, then the search is performed over 19x19 rectangles which are histogram equalized before the classification process. To further reduce dimensionality of the 361 dimensional column vector, composed of concatenation of the columns from 19x19 matrix, we may linearly project it to orthogonal PCA, LDA or non-orthogonal ICA projection matrix whose columns are projection basis vectors of the same dimensionality. In my projection matrix, I first used 40 eigenvectors obtained from PCA transform of my training faces/non-faces set. The next 2 images show some of the faces, non-faces I used from my training set:

Faces
Non-faces
In total I used about 1800 vectors with faces and 34000 non-faces for PCA, LDA and ICA transforms. The matrix thus used for transformation to obtain projection basis is of 35800x361 size. The 40 dimensional training samples after being projected to 361x40 PCA, LDA or ICA projection matrix were further used to train ANN classifier composed of 4 layers with 40, 20, 10 and 1 neurons correspondingly. The PCA projection proved best classification results, so that determined the choice of the dimensionality reduction method.
The 40 PCA eigenvectors used in my algorithm are shown below:
They contain about 95% of variance. The projected data is shown below as mean +- std. The red color denotes face data and green non-face data. We can see that in the first 25 projections, more variation between means is observed and the rest could be attributed to noise. I'd like to run NN training, classification sessions on different number of projected components and post the results in the near future.
Below, the scatter plot is presented for the 4th and 9th projected vectors to give an idea of how our PCA projected data 'lives' in 2D space. The rest of the 2D scatter plots for various combinations of projected components possess the same appearance. It's a pity we cannot plot the 40 dimensional space in the same way.
The LDA algorithm well separates only the first component, the rest just have the same means. The LDA projected data is shown below:
The scatter plot for 1st and 2nd projected LDA components is depicted below with red for face vectors and green for non-face:
I like the appearance of eigenvectors (eigenfaces) obtained from PCA transformation of the matrix composed from the faces samples (1800x361) as they resemble the faces present in the training matrix.
Some methods use just eigenfaces shown above as a projection basis.
For the ANN training procedure, I randomly divided 1800 faces and 34000 non-faces to half for the training set and the other half for validation and test sets. The validation one is used as the yearly stopping criteria and the test set is the independent estimate of how well the network generalizes. I used the ANN backpropagation gradient descent training algorithm with momentum Backpropagation Artificial Neural Network in C++ and Matlab Neural Network Toolbox with backpropagation gradient descent with momentum and adaptive learning rate. My ANN implementation took about 10 seconds on 2.2Ghz to train the network. The best result of the training session is shown below with sensitivity, specificity, positive and negative predictivities and accuracy for training half, validation and test sets:
ann1Dn.exe t pca19x19.nn scrpca void 100 void void 0.5 3
TRAINING SET: 36097
VALIDATION SET: 9023
TEST SET: 9475
loading data...
cls1: 1787 cls2: 34310 files loaded. size: 40 samples
validation size: 446 8577
test size: 469 9006
training...
epoch: 1 out: 0.876908 0.109924 max acur: 0.88 (epoch 1)
se:98.65 sp:98.66 ac:98.66
epoch: 2 out: 0.908594 0.084828 max acur: 0.90 (epoch 2)
se:99.55 sp:98.78 ac:98.81
epoch: 3 out: 0.915247 0.083308 max acur: 0.93 (epoch 3)
se:98.43 sp:99.28 ac:99.24
epoch: 4 out: 0.919266 0.081627 max acur: 0.94 (epoch 4)
se:98.43 sp:99.45 ac:99.40
epoch: 5 out: 0.922610 0.083322 max acur: 0.95 (epoch 5)
se:97.98 sp:99.52 ac:99.45
epoch: 6 out: 0.925658 0.084236 max acur: 0.96 (epoch 6)
se:98.21 sp:99.66 ac:99.59
epoch: 7 out: 0.927656 0.084170 max acur: 0.96 (epoch 6)
se:98.21 sp:99.66 ac:99.59
epoch: 8 out: 0.928191 0.085515 max acur: 0.97 (epoch 8)
se:98.88 sp:99.77 ac:99.72
epoch: 9 out: 0.927756 0.088423 max acur: 0.97 (epoch 8)
se:98.88 sp:99.77 ac:99.72
epoch: 10 out: 0.929448 0.087034 max acur: 0.97 (epoch 8)
se:98.88 sp:99.77 ac:99.72
training done.
classification results: maxacur.nn
train set: 872 16727
sensitivity: 100.00
specificity: 99.96
+predictive: 99.20
-predictive: 100.00
accuracy: 99.96
validation set: 446 8577
sensitivity: 98.88
specificity: 99.77
+predictive: 95.66
-predictive: 99.94
accuracy: 99.72
test set: 469 9006
sensitivity: 98.93
specificity: 99.77
+predictive: 95.67
-predictive: 99.94
accuracy: 99.73
However Matlab provided slightly better performance, but the training session lasts several minutes:
net = train2(net,{face;nface},1000,'traingdx');
TRAINGDX-calcgrad, Epoch 0/1000, MSE 0.0380841/0,
Gradient 0.0161943/1e-006
TRAINGDX-calcgrad, Epoch 25/1000, MSE 0.0379897/0,
Gradient 0.0160989/1e-006
TRAINGDX-calcgrad, Epoch 50/1000, MSE 0.0377002/0,
Gradient 0.0157962/1e-006
TRAINGDX-calcgrad, Epoch 75/1000, MSE 0.0367918/0,
Gradient 0.0148357/1e-006
TRAINGDX-calcgrad, Epoch 100/1000, MSE 0.0342653/0,
Gradient 0.0131359/1e-006
TRAINGDX-calcgrad, Epoch 125/1000, MSE 0.0288224/0,
Gradient 0.00899192/1e-006
TRAINGDX-calcgrad, Epoch 150/1000, MSE 0.0195839/0,
Gradient 0.00661213/1e-006
TRAINGDX-calcgrad, Epoch 175/1000, MSE 0.0114634/0,
Gradient 0.00248487/1e-006
TRAINGDX-calcgrad, Epoch 200/1000, MSE 0.00730671/0,
Gradient 0.00141872/1e-006
TRAINGDX-calcgrad, Epoch 225/1000, MSE 0.00619382/0,
Gradient 0.0139478/1e-006
TRAINGDX-calcgrad, Epoch 250/1000, MSE 0.00552043/0,
Gradient 0.00225788/1e-006
TRAINGDX-calcgrad, Epoch 275/1000, MSE 0.00506328/0,
Gradient 0.00117316/1e-006
TRAINGDX-calcgrad, Epoch 300/1000, MSE 0.00394131/0,
Gradient 0.000806827/1e-006
TRAINGDX-calcgrad, Epoch 325/1000, MSE 0.00304252/0,
Gradient 0.00243748/1e-006
TRAINGDX-calcgrad, Epoch 350/1000, MSE 0.00297078/0,
Gradient 0.00102562/1e-006
TRAINGDX-calcgrad, Epoch 375/1000, MSE 0.0028294/0,
Gradient 0.00061697/1e-006
TRAINGDX-calcgrad, Epoch 400/1000, MSE 0.00243267/0,
Gradient 0.000526016/1e-006
TRAINGDX-calcgrad, Epoch 425/1000, MSE 0.00187066/0,
Gradient 0.00242446/1e-006
TRAINGDX-calcgrad, Epoch 450/1000, MSE 0.00183145/0,
Gradient 0.000864909/1e-006
TRAINGDX-calcgrad, Epoch 475/1000, MSE 0.0017861/0,
Gradient 0.000520862/1e-006
TRAINGDX-calcgrad, Epoch 500/1000, MSE 0.00167154/0,
Gradient 0.000361654/1e-006
TRAINGDX-calcgrad, Epoch 525/1000, MSE 0.00136531/0,
Gradient 0.000335621/1e-006
TRAINGDX-calcgrad, Epoch 550/1000, MSE 0.00132639/0,
Gradient 0.00278421/1e-006
TRAINGDX-calcgrad, Epoch 575/1000, MSE 0.00128443/0,
Gradient 0.000823477/1e-006
TRAINGDX-calcgrad, Epoch 600/1000, MSE 0.00123788/0,
Gradient 0.000294566/1e-006
TRAINGDX-calcgrad, Epoch 625/1000, MSE 0.00110702/0,
Gradient 0.000240032/1e-006
TRAINGDX-calcgrad, Epoch 650/1000, MSE 0.000992816/0,
Gradient 0.00162968/1e-006
TRAINGDX-calcgrad, Epoch 675/1000, MSE 0.000973248/0,
Gradient 0.000397771/1e-006
TRAINGDX-calcgrad, Epoch 700/1000, MSE 0.000951908/0,
Gradient 0.000277682/1e-006
TRAINGDX-calcgrad, Epoch 725/1000, MSE 0.000891638/0,
Gradient 0.000194585/1e-006
TRAINGDX-calcgrad, Epoch 750/1000, MSE 0.000745773/0,
Gradient 0.000971981/1e-006
TRAINGDX-calcgrad, Epoch 775/1000, MSE 0.000738705/0,
Gradient 0.000281221/1e-006
TRAINGDX-calcgrad, Epoch 800/1000, MSE 0.000731111/0,
Gradient 0.000223325/1e-006
TRAINGDX-calcgrad, Epoch 825/1000, MSE 0.000708551/0,
Gradient 0.0001534/1e-006
TRAINGDX-calcgrad, Epoch 850/1000, MSE 0.000642279/0,
Gradient 0.000133356/1e-006
TRAINGDX-calcgrad, Epoch 875/1000, MSE 0.000624203/0,
Gradient 0.00193949/1e-006
TRAINGDX-calcgrad, Epoch 900/1000, MSE 0.000604328/0,
Gradient 0.000337345/1e-006
TRAINGDX-calcgrad, Epoch 925/1000, MSE 0.000593177/0,
Gradient 0.000146603/1e-006
TRAINGDX-calcgrad, Epoch 950/1000, MSE 0.000560221/0,
Gradient 0.000115208/1e-006
TRAINGDX-calcgrad, Epoch 975/1000, MSE 0.000535758/0,
Gradient 0.00183329/1e-006
TRAINGDX-calcgrad, Epoch 1000/1000, MSE 0.000518507/0,
Gradient 0.000550508/1e-006
TRAINGDX, Maximum epoch reached, performance goal was not met.
train set: 893 17154
sensitivity: 99.55
specificity: 100.00
+predictive: 100.00
-predictive: 99.98
accuracy: 99.98
mse: 0.000519
validation set: 447 8578
sensitivity: 96.42
specificity: 99.90
+predictive: 97.95
-predictive: 99.81
accuracy: 99.72
mse: 0.001824
test set: 447 8578
sensitivity: 97.32
specificity: 99.90
+predictive: 97.97
-predictive: 99.86
accuracy: 99.77
mse: 0.001746
The traingdx Matlab method provided best classification results compared to other training algorithms, as they tend to converge very fast without good generalization performance on validation and test sets.
I have obtained classification accuracy in terms of geometric mean for sensitivity and positive predictivity for the test set using different numbers of PCA components during ANN classification process. As I mentioned before, after the 25th component the classification rate does not change too much.
Next, some preprocessing tips are described which help to reduce the search region significantly.
Motion Detection
You may significantly reduce the search region for the faces using temporal information between successive frames in video stream. I implemented a simple motion detector class which keeps the difference between successive frames. So you have to look over the area where the motion was detected. In order not to lose the already detected face, if the person keeps still, I mark the pixels in the found face rectangle area and on the next frame the face detector is induced to search over that region again.
Skin Detection
I use color information from RGB data to detect skin regions and search only over them. If it is not dark and illumination is sufficient you may not look over blue or green colored regions to expect the face present there. I used only skin samples from white persons, as I did not have pictures of people from other nationalities, but you may collect them and arrange say different skin detectors for various skin types and use them interchangeably. For non-skin data, I used some background colored pictures. The color data is a 3 dimensional vector having 3 channels of red, green and blue values in the range from 0 to 255, I scale it to the range 0.0 ... 1.0 before classification. I used ANN classifier for that purpose composed of 3 layers 3, 6 and 1 neurons correspondingly. Again Matlab session provided slightly better performance compared to my ANN code. The network is very short so I present the complete file here. I'll present the description of the file format later on.
3
3 6 1
0
1
0.000000 1.000000
0.000000 1.000000
0.000000 1.000000
12.715479
3.975381
7.267306
-2.828213
-5.901746
56.047752
-31.722653
-21.872528
-10.393643
-11.324373
42.869545
-27.680447
3.026848
-8.795427
-32.185852
62.505981
8.211640
-32.108111
81.444914
-48.067621
8.276753
19.659469
-50.115191
27.516311
-15.402503
-9.760841
4.400588
18.516097
0.624907
4.414670
17.972277
net = train2(net,{skin;nskin},1000);
TRAINLM-calcjx, Epoch 0/1000, MSE 0.0775247/0, Gradient 0.0431253/1e-010
TRAINLM-calcjx, Epoch 25/1000, MSE 0.00730059/0, Gradient 0.000136228/1e-010
TRAINLM-calcjx, Epoch 50/1000, MSE 0.00658964/0, Gradient 6.8167e-005/1e-010
TRAINLM-calcjx, Epoch 64/1000, MSE 0.00657199/0, Gradient 1.68806e-005/1e-010
TRAINLM, Validation stop.
train set: 2959 6383
se: 98.11
sp: 99.09
pp: 98.04
np: 99.12
ac: 98.78
er: 0.006637
validation set: 1479 3191
se: 98.78
sp: 99.22
pp: 98.32
np: 99.43
ac: 99.08
er: 0.005474
test set: 1479 3191
se: 97.77
sp: 99.22
pp: 98.30
np: 98.97
ac: 98.76
er: 0.006467
In case you use both motion and skin detection, the masks obtained from detection are merged together with the AND operation.
Rough Non-face Rejection
Before calculating expensive projections from 361 dimensional space to a 40 dimensional one, that is 40 convolution operations on 361 dimensional vectors (40 * (361 multiplications + 360 additions)) you may compose small sized classifiers, ANN with couple of hidden neurons or SVM with just two support vectors. They could hardly be expected to produce a high detection rate alone, but having a high specificity rate (percent of correct non-face detections) can reject a vast majority of non-face regions. In the case of positive detection, I continue to PCA projection and further classification stage.
I arranged the ANN classifier composed of 3 layers of 361, 3 and 1 neurons correspondingly. With that ANN structure, we perform just 3 convolutions on 361 dimensional vectors (3 * (361 multiplications + 360 additions)), that is about 13.3 increase in performance in case of non-face rectangle rejection. For the training I used the entire dataset, as the number of hidden neurons is very, very small we may not expect over fitting at all. The training session from Matlab is shown below:
net = train2(net, {face;nface}, 1000, 'trainscg');
TRAINSCG-calcgrad, Epoch 0/1000, MSE 0.0706625/0,
Gradient 0.0408157/1e-006
TRAINSCG-calcgrad, Epoch 25/1000, MSE 0.0252248/0,
Gradient 0.00524303/1e-006
TRAINSCG-calcgrad, Epoch 50/1000, MSE 0.0208643/0,
Gradient 0.00410831/1e-006
TRAINSCG-calcgrad, Epoch 75/1000, MSE 0.0199327/0,
Gradient 0.00245891/1e-006
TRAINSCG-calcgrad, Epoch 100/1000, MSE 0.0183846/0,
Gradient 0.00243653/1e-006
TRAINSCG-calcgrad, Epoch 125/1000, MSE 0.0167635/0,
Gradient 0.00413765/1e-006
TRAINSCG-calcgrad, Epoch 150/1000, MSE 0.0156056/0,
Gradient 0.00222181/1e-006
TRAINSCG-calcgrad, Epoch 175/1000, MSE 0.0145851/0,
Gradient 0.00154122/1e-006
TRAINSCG-calcgrad, Epoch 200/1000, MSE 0.0138646/0,
Gradient 0.00187787/1e-006
TRAINSCG-calcgrad, Epoch 225/1000, MSE 0.0130431/0,
Gradient 0.00110514/1e-006
TRAINSCG-calcgrad, Epoch 250/1000, MSE 0.0124017/0,
Gradient 0.000794686/1e-006
TRAINSCG-calcgrad, Epoch 275/1000, MSE 0.0119851/0,
Gradient 0.000686196/1e-006
TRAINSCG-calcgrad, Epoch 300/1000, MSE 0.0115745/0,
Gradient 0.000538587/1e-006
TRAINSCG-calcgrad, Epoch 325/1000, MSE 0.0110115/0,
Gradient 0.000619825/1e-006
TRAINSCG-calcgrad, Epoch 350/1000, MSE 0.0106856/0,
Gradient 0.000397777/1e-006
TRAINSCG-calcgrad, Epoch 375/1000, MSE 0.0103944/0,
Gradient 0.000335075/1e-006
TRAINSCG-calcgrad, Epoch 400/1000, MSE 0.0101617/0,
Gradient 0.000491891/1e-006
TRAINSCG-calcgrad, Epoch 425/1000, MSE 0.00997477/0,
Gradient 0.00054992/1e-006
TRAINSCG-calcgrad, Epoch 450/1000, MSE 0.00982742/0,
Gradient 0.000277635/1e-006
TRAINSCG-calcgrad, Epoch 475/1000, MSE 0.00973586/0,
Gradient 0.000246542/1e-006
TRAINSCG-calcgrad, Epoch 500/1000, MSE 0.00964214/0,
Gradient 0.000430392/1e-006
TRAINSCG-calcgrad, Epoch 525/1000, MSE 0.00955025/0,
Gradient 0.000208358/1e-006
TRAINSCG-calcgrad, Epoch 550/1000, MSE 0.00946008/0,
Gradient 0.000259309/1e-006
TRAINSCG-calcgrad, Epoch 575/1000, MSE 0.00935917/0,
Gradient 0.000293115/1e-006
TRAINSCG-calcgrad, Epoch 600/1000, MSE 0.00928761/0,
Gradient 0.000297855/1e-006
TRAINSCG-calcgrad, Epoch 625/1000, MSE 0.00922528/0,
Gradient 0.000220927/1e-006
TRAINSCG-calcgrad, Epoch 650/1000, MSE 0.0091606/0,
Gradient 0.000237646/1e-006
TRAINSCG-calcgrad, Epoch 675/1000, MSE 0.0091048/0,
Gradient 0.000301604/1e-006
TRAINSCG-calcgrad, Epoch 700/1000, MSE 0.00903629/0,
Gradient 0.000338506/1e-006
TRAINSCG-calcgrad, Epoch 725/1000, MSE 0.00897432/0,
Gradient 0.000207054/1e-006
TRAINSCG-calcgrad, Epoch 750/1000, MSE 0.00892802/0,
Gradient 0.000189826/1e-006
TRAINSCG-calcgrad, Epoch 775/1000, MSE 0.00888097/0,
Gradient 0.000197304/1e-006
TRAINSCG-calcgrad, Epoch 800/1000, MSE 0.00882134/0,
Gradient 0.00015089/1e-006
TRAINSCG-calcgrad, Epoch 825/1000, MSE 0.00875718/0,
Gradient 0.000262308/1e-006
TRAINSCG-calcgrad, Epoch 850/1000, MSE 0.00870468/0,
Gradient 0.000160878/1e-006
TRAINSCG-calcgrad, Epoch 875/1000, MSE 0.00865585/0,
Gradient 0.000154301/1e-006
TRAINSCG-calcgrad, Epoch 900/1000, MSE 0.00860733/0,
Gradient 0.000194127/1e-006
TRAINSCG-calcgrad, Epoch 925/1000, MSE 0.00853522/0,
Gradient 0.000360248/1e-006
TRAINSCG-calcgrad, Epoch 950/1000, MSE 0.00847012/0,
Gradient 0.000149492/1e-006
TRAINSCG-calcgrad, Epoch 975/1000, MSE 0.00841884/0,
Gradient 0.00017306/1e-006
TRAINSCG-calcgrad, Epoch 1000/1000, MSE 0.0083688/0,
Gradient 0.000173782/1e-006
TRAINSCG, Maximum epoch reached, performance goal was not met.
elapsed time: 18.441611 min
train set: 1788 17853
se: 95.08
sp: 99.16
pp: 91.89
np: 99.51
ac: 98.79
er: 0.008369
We can see that the percent of correct detections for non-face vectors is 99.16%, an utterly robust rate.
The next picture shows the output of the last stage ANN classifier, which takes PCA transformed 19x19 data vectors. The output for the classification is in the range 0.0 - 1.0, as a sigmoid function is used in the output layer of ANN.
The upper image shows ANN detection of the PCA transformed vectors. As the neural network was trained to match 0.1 output for non-face and 0.9 for face, the general image is of light blue color, with a hot red spot in the middle matching the found face. The surrounding frame of true blue color where the zero is put, I search over the region where the entire 19x19 rectangle fits. The bottom image shows a combination of prefilter and PCA transformed ANN classification. If the prefilter rejects the rectangle as belonging to the non-face class I output 0.0, otherwise continue to PCA transformation and ANN classification. You may observe that the whole light blue region from the upper image is replaced with zeros (true blue color).
In addition to ANN prefilter, I composed linear SVM classifier arranged of just 2 support vectors representing means of faces and non-faces data from the training set. It provides even faster processing than ANN, just two convolutions of 361 dimensional vectors, but it lacks performance with 76.72% of correct detection rate of non-face vectors. The classification on the training set is shown below:
sensitivity: 93.85
specificity: 76.72
+predictive: 28.76
-predictive: 99.20
accuracy: 78.28
You may use either of them, just rename the corresponding classifier to the file preflt.nn.
Library Description
The main classes in the face detection library that you have to use to built your own application are:
ImageResize MotionDetector FaceDetector
I've wrapped them in the cvlib.cpp file for easier usage in an MFC application. The ImageResize is described in my article Fast Dyadic Image Scaling with Haar Transform. The MotionDetector class is pretty simple. All you have to do is to initialize it to the down sampled image width and height. As you remember, I use 640x480 video stream in my MFC application and down sample it to 0.125 of its original size: 80x60. Then just use its MotionDetector::detect() method supplying image that you obtain from ImageResize after the downscaling procedure:
-
void MotionDetector::init(unsigned int image_width,
unsigned int image_height);
-
const vec2Dc* MotionDetector::detect(const vec2D* frame,
const FaceDetector* fdetect);
You have to provide the FaceDetector object you use to MotionDetector::detect() as the second argument. Because it marks the found face rectangles in its frame as the search region, you do not end up losing the detected face in case the motion ceased, as I described above. The vec2D is the SSE optimized floating point 2D vector you may find in my article Vector Class Wrapper SSE Optimized for Math Operations. Its little brother vec2Dc is the char type object containing a similar interface as vec2D. After MotionDetector::detect() you receive the pointer to the vec2Dc object where zero entries denote no motion and non-zero is the motion region.
This is the code for the MotionDetector::detect() function:
const vec2Dc* MotionDetector::detect
(const vec2D* frame, const FaceDetector* fdetect)
{
if (status() < 0)
return 0;
m_last_frame->sub(*frame, *m_last_frame);
RECT r0;
for (unsigned int i = 0; i < fdetect->get_faces_number(); i++) {
const RECT* r = fdetect->get_face_rect(i);
r0.left = r->left;
r0.top = r->top;
r0.right = r->right;
r0.bottom = r->bottom;
m_last_frame->set(255.0f, r0);
}
for (unsigned int y = fdetect->get_dy();
y < m_motion_vector->height() - fdetect->get_dy(); y++) {
for (unsigned int x = fdetect->get_dx();
x < m_motion_vector->width() - fdetect->get_dx(); x++) {
if (fabs((*m_last_frame)(y, x)) > m_TH)
(*m_motion_vector)(y, x) = 1;
else
(*m_motion_vector)(y, x) = 0;
}
}
*m_last_frame = *frame;
return m_motion_vector;
}
After that you may proceed to the actual face detection process. You also have to initialize the FaceDetector object before its usage. I implement initialization and detection in the cvlib.cpp wrapper this way:
float m_zoom = 0.125f;
vector<float> m_scales;
ImageResize resize;
MotionDetector mdetect;
FaceDetector fdetect;
void cvInit(unsigned int image_width, unsigned int image_height,
unsigned int face_width, unsigned int face_height, double zoom)
{
m_zoom = (float)zoom;
resize.init(image_width, image_height, m_zoom);
mdetect.init(resize.gety()->width(), resize.gety()->height());
if (m_scales.size()) {
fdetect.init(resize.gety()->width(), resize.gety()->height(),
face_width, face_height,
&m_scales[0], (unsigned int)m_scales.size());
} else
fdetect.init(resize.gety()->width(), resize.gety()->height(),
face_width, face_height);
}
int cvInitAI(const wchar_t* face_detector,
const wchar_t* projection_matrix,
const wchar_t* skin_filter,
const wchar_t* preface_filter)
{
int res;
res = fdetect.load_face_classifier(face_detector);
if (res != 0)
return res;
res = fdetect.load_projection_matrix(projection_matrix);
if (res != 0)
return res;
if (skin_filter != 0)
fdetect.load_skin_filter(skin_filter) ;
if (preface_filter != 0)
fdetect.load_preface_filter(preface_filter);
return fdetect.status_of_classifiers();
}
void cvSetScales(const double* scales, unsigned int size)
{
m_scales.clear();
for (unsigned int i = 0; i < size; i++)
m_scales.push_back((float)scales[i]);
}
The image_width and image_height in the cvInit() function is the original size of the image in the video stream, 640x480 in my case. The face_width and face_height is the 19x19 sized face rectangle. With cvSetScales(), I add 3 more scales to which 80x60 image will be interpolated: 0.86, 0.73 and 0.6. So the computer will 'see' the size of your face. Next you proceed to the initialization of the FaceDetector object.
-
void FaceDetector::init(unsigned int image_width,
unsigned int image_height, unsigned int face_width,
unsigned int face_height, const float* scales = 0,
unsigned int nscales = 0);
The image_width and image_height here are the downscaled size of your image. scales is the pointer to the array with 0.86, 0.73, 0.6 numbers in my case, but you may supply your choice, say 1.3, 0.8, 0.7, 0.5 and the computer will see you as you move away from the webcam on 1.3 magnified version of the 80x60 image.
With the next functions you just load and unload classifiers:
-
int FaceDetector::load_skin_filter(const wchar_t* fname);
-
void FaceDetector::unload_skin_filter();
-
int FaceDetector::load_preface_filter(const wchar_t* fname);
-
void FaceDetector::unload_preface_filter();
-
int FaceDetector::load_projection_matrix(const wchar_t* fname);
-
void FaceDetector::unload_projection_matrix();
-
int FaceDetector::load_face_classifier(const wchar_t* fname);
-
void FaceDetector::unload_face_classifier();
Their names are self-explanatory and they return 0 upon success.
In my lib, you may find ANNetwork and SVMachine classifiers. They use vec2D class for SSE optimized matrix operations. I'm going to post the article in the future on that subject and describe the neural network classifier that I used for training. Otherwise if you are familiar with ANN and SVM algorithms, you may without hurdle understand the code. I've wrapped them in the AIClassifier class, so you may load either ANN or SVM file with one function. However, it is advisable to implement AIClassifier as the ABC class and ANNetwork, SVMachine as the implementation. Hope I'll make such changes in the future.
The face detection process goes this way:
int cvDetect(const unsigned char *pBGR)
{
wchar_t err[256] = L"";
if (resize.gety() == 0)
return -1;
__try {
resize.resize(pBGR);
return fdetect.detect(resize.gety(), resize.getr(),
resize.getg(), resize.getb(),
mdetect.detect(resize.gety(), &fdetect));
}
__except(EXCEPTION_EXECUTE_HANDLER) {
swprintf(err, 256, L"SEH error code: 0x%X",
GetExceptionCode());
MessageBox(0, L"error.", err, MB_OK|MB_ICONERROR);
return 0;
}
}
I added SEH handling in case you modified the code for your resolution improperly. However, I have not yet experienced any SEH error and warrant the code is robust.
You receive an RGB stream of data with the first byte as a blue channel in the triplet. Next I resize it 8 times to 80x60 with ImageResize::resize() and continue to face detection:
-
int FaceDetector::detect(const vec2D* y, char** r, char** g, char** b, const vec2Dc* search_mask = 0);
It takes gray scale image and its R, G, B channels from ImageResize class. The search_mask is the vec2Dc vector returned by MotionDetector::detect() method and it is optional. The detect function returns 0 or more faces are found upon success or a negative value in case you missed initialization process or forgot to load classifiers.
To access the detected face rectangles you may use these functions:
-
inline unsigned int FaceDetector::get_faces_number() const;
-
inline const RECT* FaceDetector::get_face_rect(unsigned int i) const;
-
inline const vec2D* FaceDetector::get_face(unsigned int i) const;
I provide its implementations in cvlib.cpp wrapper:
unsigned int cvGetFacesNumber()
{
return fdetect.get_faces_number();
}
void cvFaceRect(unsigned int i, RECT& rect)
{
if (i < 0) i = 0;
if (i >= fdetect.get_faces_number()) i =
fdetect.get_faces_number() - 1;
const RECT* r = fdetect.get_face_rect(i);
rect.left = int((float)r->left * (1.0f / m_zoom));
rect.top = int((float)r->top * (1.0f / m_zoom));
rect.right = int((float)(r->right + 1) *
(1.0f / m_zoom) - (float)r->left * (1.0f / m_zoom));
rect.bottom = int((float)(r->bottom + 1) *
(1.0f / m_zoom) - (float)r->top * (1.0f / m_zoom));
}
const vec2D* cvGetFace(unsigned int i)
{
return fdetect.get_face(i);
}
Do not forget that the RECT structure is filled with face coordinates relatively to the downscaled image and you have to multiply them by the number of times you downscale your image in the ImageResize class, 8 times for 0.125, 4 times for 0.25 and so on.
File Formats
The file formats for ANN and SVM classifiers are presented below. The projection matrix is also implemented with linear, 2-layered neural network composed of 361 and 40 neurons correspondingly so you may use your own projection basis in that format.
I'll describe the ANN file structure on the skin.nn example:
3
3 6 1
0
1
0.000000 1.000000
0.000000 1.000000
0.000000 1.000000
12.715479
3.975381
7.267306
-2.828213
-5.901746
56.047752
-31.722653
-21.872528
-10.393643
-11.324373
42.869545
-27.680447
3.026848
-8.795427
-32.185852
62.505981
8.211640
-32.108111
81.444914
-48.067621
8.276753
19.659469
-50.115191
27.516311
-15.402503
-9.760841
4.400588
18.516097
0.624907
4.414670
17.972277
3 is the number of layers. 3 6 1 is the number of neurons per layer. The next two numbers 0 and 1 denote linear normalization for the input layer and 1 is sigmoidal squashing for hidden and output layers. The next two columns with zeros and ones are the input vector normalization params. The first column is the addition term and the second is multiplication. So every input vector fed to the network is normalized according to:
X[i] = (X[i] + A[i]) * B[i];
Next, go the neurons coefficients themselves. You may use ANNetwork::saveW() function to obtain the matrices:
W1 4x6
12.7155 -5.9017 -10.3936 3.0268 8.2116 8.2768
3.9754 56.0478 -11.3244 -8.7954 -32.1081 19.6595
7.2673 -31.7227 42.8695 -32.1859 81.4449 -50.1152
-2.8282 -21.8725 -27.6804 62.5060 -48.0676 27.5163
W2 7x1
-15.4025
-9.7608
4.4006
18.5161
0.6249
4.4147
17.9723
Every column is the single neuron weight with the first element as a bias weight with 1.0 as an input. Just concatenate them in column wise order and you will get my file format.
This is the example of the 4 layered network:
4
3 8 4 1
0
1
0.000000 1.000000
0.000000 1.000000
0.000000 1.000000
0.025145
-0.235785
0.251309
0.746412
-0.554480
-0.608912
0.592695
-0.035175
-0.471400
-0.362423
-0.010304
0.264203
0.954675
0.097983
0.960209
-0.744931
-0.008009
-1.698955
-0.697944
1.098258
0.500820
-0.199090
-0.157125
1.243531
-0.411520
-1.217646
-0.388029
0.768772
-0.364904
-1.983003
0.663086
1.999845
1.052666
0.241385
0.301041
-0.479706
1.353455
-1.687823
-0.411694
-1.080923
-1.886460
0.517472
-0.873151
0.833913
-0.836865
0.143565
0.822298
0.750636
0.407058
0.601209
0.802379
-0.277260
0.334823
0.086736
0.254606
-0.617788
-0.544399
-0.724927
-1.301591
-1.319710
0.708224
0.845066
0.172427
-0.606166
0.311338
0.405023
0.610455
1.672150
-0.192386
-2.995480
1.061938
-1.674936
2.250647
Its weights matrices are shown below so that you may get a general idea:
W1 4x8
0.0251 -0.5545 -0.4714 0.9547 -0.0080 0.5008 -0.4115 -0.3649
-0.2358 -0.6089 -0.3624 0.0980 -1.6990 -0.1991 -1.2176 -1.9830
0.2513 0.5927 -0.0103 0.9602 -0.6979 -0.1571 -0.3880 0.6631
0.7464 -0.0352 0.2642 -0.7449 1.0983 1.2435 0.7688 1.9998
W2 9x4
1.0527 0.5175 0.8024 -1.3197
0.2414 -0.8732 -0.2773 0.7082
0.3010 0.8339 0.3348 0.8451
-0.4797 -0.8369 0.0867 0.1724
1.3535 0.1436 0.2546 -0.6062
-1.6878 0.8223 -0.6178 0.3113
-0.4117 0.7506 -0.5444 0.4050
-1.0809 0.4071 -0.7249 0.6105
-1.8865 0.6012 -1.3016 1.6722
W3 5x1
-0.1924
-2.9955
1.0619
-1.6749
2.2506
The SVM format is pretty simple too:
361
2
linear
-0.806308
1
... 361 entries of numbers
-1
... 361 entries of numbers
361 is the dimension of the input vector, 2 is the number of support vectors present in the file, linear is the type of SVM, -0.806308 is the bias and then the actual support vectors. The first element in this example 1 for the first SV and -1 for the second denotes weight as the alpha * y, there y is the class mark -1 or 1 and alphas you obtain from training SVM. In my case I composed linear SVM and used support vectors as mean vectors of face class and non-face class. For the description of the training formula, have a look at the 'Statistical Learning and Kernel Methods' by B. Scholkopf. I remember I downloaded it from the Kernel Machines site.
Some Results
Here I present some snapshots from my application that I just collected. You may have a look at the bottom status line for the fps rate. Motion and skin is the amount detected in the range 0.0 - 1.0.
27.03fps, 12% of motion and 9% of skin.
19.23fps, 24% of motion and 14% of skin.
55.56fps, 12% of motion and 2% of skin!
Points of Interest
With the advent of multicore processors, you may optimize the vec2D class using OpenMP support. I believe that will increase the speed of detection to a couple of times. You may also experiment with different neural network topologies or try to use less eigenvectors, and also experiment with online databases. Let me know if you obtain better results. I'll post your classifiers as an addon.
Updates
9 Jan 2008 - Retrained Classifiers on CBCL Faces Database
CBCL faces dataset contains 2429 face samples and 4548 non-face samples in 19x19 rectangle size. I added them to my own collected samples from several persons and repeated the PCA and classifiers training on thus new composed dataset. The necessary steps I performed are Gaussian smoothing and histogram equalization on CBCL data as I use these operations as the preprocessing steps in my algorithm. Now those whose faces were quite different from mine will be detected without problems I believe.
The new 40 eigenvectors are shown below:
They also contain about 95% of variance. The projected data is shown below as mean +- std. The red color denotes face data and green non-face. I also reduced my non-face data.
You may observe that the 4th projection provides the best separation of the classes. The 4th eigenvector resembles some face.
I used my Backpropagation Artificial Neural Network in C++ and did the training again as 50% for train set and 50% for validation and testing:
ann1Dn.exe t pca19x19.nn scrpca void 100 void void 0.5 3
TRAINING SET: 12977
VALIDATION SET: 6654
TEST SET: 6987
loading data...
cls1: 4217 cls2: 22401 files loaded. size: 40 samples
validaton size: 1054 5600
test size: 1107 5880
training...
epoch: 1 out: 0.845651 0.141380 max acur: 0.90 (epoch 1)
se:97.25 sp:96.52 ac:96.63
epoch: 2 out: 0.884783 0.106216 max acur: 0.92 (epoch 2)
se:97.72 sp:97.23 ac:97.31
epoch: 3 out: 0.895387 0.097048 max acur: 0.92 (epoch 2)
se:97.72 sp:97.23 ac:97.31
epoch: 4 out: 0.900517 0.093550 max acur: 0.94 (epoch 4)
se:98.01 sp:97.82 ac:97.85
epoch: 5 out: 0.903232 0.090293 max acur: 0.94 (epoch 5)
se:96.87 sp:98.23 ac:98.02
epoch: 6 out: 0.905548 0.088409 max acur: 0.94 (epoch 5)
se:96.87 sp:98.23 ac:98.02
epoch: 7 out: 0.902383 0.086369 max acur: 0.94 (epoch 7)
se:97.15 sp:98.38 ac:98.18
epoch: 8 out: 0.904038 0.084748 max acur: 0.94 (epoch 7)
se:97.15 sp:98.38 ac:98.18
epoch: 9 out: 0.905107 0.081640 max acur: 0.94 (epoch 7)
se:97.15 sp:98.38 ac:98.18
epoch: 10 out: 0.902668 0.081184 max acur: 0.94 (epoch 7)
se:97.15 sp:98.38 ac:98.18
epoch: 11 out: 0.901597 0.079696 max acur: 0.95 (epoch 11)
se:96.49 sp:98.64 ac:98.30
training done.
training time: 00:00:47:531
classification results: pca19x19.nn
train set: 2056 10921
sensitivity: 99.81
specificity: 99.60
+predictive: 97.90
-predictive: 99.96
accuracy: 99.63
validation set: 1054 5600
sensitivity: 97.15
specificity: 98.73
+predictive: 93.52
-predictive: 99.46
accuracy: 98.48
test set: 1107 5880
sensitivity: 98.01
specificity: 98.45
+predictive: 92.26
-predictive: 99.62
accuracy: 98.38
The performance degraded about 1-3% on the new composed sets compared to training on my own data.
The prefilter linear SVM composed of 2 support vectors representing means of original 19x19 face and non-face data however significantly increased classification performance:
sensitivity: 81.65
specificity: 91.09
+predictive: 63.31
-predictive: 96.35
accuracy: 89.60
Now you may just unzip the pca.nn, face.nn, preflt.nn and replace my old AI files with them (backup my previous ones also). Now run the program. Remember to remove skin.nn if the lighting conditions are bad. If you are still not detected, remove SVM preflt.nn pre-filter (do not forget to reclick detect check box to reload classifiers). I noticed that SVM prefilter do not see me on some of my train pics. That is not a problem, since it is linear and very simple but significantly boosts computation performance. I'll provide ANN prefilter on a new dataset, until then you may use the older one bin\pca\preflt.nn from demo.zip file.

