Introduction
A custom IComparer object can be used to provide the .NET sort algorithms an alternate strategy for ordering strings. The IComparer presented here attempts to interpret a string the way a human might, rather than the computer's strict lexicographical ordering.
Background
A recent article at CodingHorror charged that "The default sort functions in almost every programming language are poorly suited for human consumption." The computer relies on a strict comparison, character by character, of the strings being sorted, but this is not the way that humans think of the strings.
Mentally, we humans break the string into chunks, recognizing some chunks as text that can be compared character-wise, but also seeing some chunks numerically. The numeric chunks should be sorted by value, but standard sorting algorithms do not take this into account.
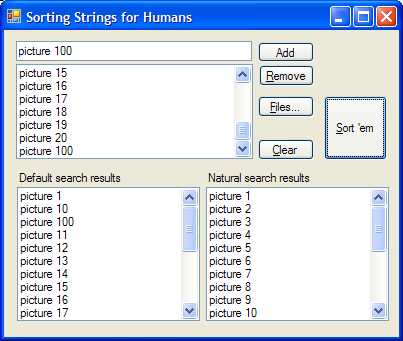
| Consider a photographer naming his files. It would be perfectly reasonable for him (assuming that he thinks like a normal human, not perverted like us programmers) to name his files like so: | If our photographer were to enter these into a typical piece of software and sort it, the output would be the thoroughly unacceptable: |
- Picture 1
- Picture 2
- Picture 3
- Picture 4
- Picture 5
- Picture 6
- Picture 7
- Picture 8
- Picture 9
- Picture 10
- Picture 11
- Picture 12
- Picture 13
- ...
- Picture 20
- ...
- Picture 100
|
- Picture 1
- Picture 10
- Picture 100
- Picture 11
- Picture 12
- Picture 13
- ...
- Picture 2
- Picture 20
- ...
- Picture 3
- Picture 4
- Picture 5
- Picture 6
- Picture 7
- Picture 8
- Picture 9
|
Our goal, therefore, is to reform the computer's antisocial ways, allowing it to make its user a bit more comfortable.
Using the Code
This goal is greatly simplified by the .NET Framework. Microsoft has made some overtures itself towards the humanization of software built on the .NET platform: notice the built-in support for globalization. More specifically, helping our purpose is the design principle allowing many default behaviors to be customized to the developer's own purposes, such as the many areas in which the Provider pattern has been implemented.
In our case, we can employ a custom-built IComparer to provide an alternate means of ordering the strings in a collection. Given the IComparer presented here, using it rather than the built-in comparison of strings is trivial.
This block of code is taken from the demo application for the library:
List<string> n = new List<string>(lbInputList.Items.Count);
foreach (string s in lbInputList.Items)
{
n.Add(s);
}
n.Sort(new NaturalComparer());
Most of this code is devoted to creating and filling a List from the contents of a listbox. The actual use of the custom IComparer is nothing but the final line of this block.
The List.Sort() method provides several overloads. The common one, with no parameters, uses the built-in string comparison. But here, we create an instance of an alternate comparator implementing the IComparer interface, and pass that to the Sort.
Points of Interest
NaturalComparer is able to provide the string ordering service to the sort method by implementing the IComparer interface. Its design has three primary parts: chopping each string into chunks, interpreting the values of each chunk, and comparing each chunk.
Implementing IComparer
Actually, this code implements two interfaces, the old-fashioned IComparer from .NET 1.0 for backward compatibility, and the more typesafe IComparer<string>. The former is "hidden" by explicit interface definition, and simply passes off any call to the type-specific version. The interface requires just one method:
int Compare(string left, string right) { ... }
The int that is returned should have one of three values:
0 - The values sort to the same place in the list (it's worth noting that this does NOT imply that the two values are equal). -1 - The left parameter is "smaller" - in an ascending list, it goes first. 1 - The left parameter is "larger" - in an ascending list, it goes last.
So our task in implementing this method is to find some magic that can decide whether our hypothetical human would consider one string larger or smaller than another.
Chunking the Strings
We'd like to emulate what's (presumably) going on in the mind of a human: identifying discrete pieces of information inside the string, and comparing each in turn. The big challenge is in determining what constitutes a separate chunk.
I would submit that white space serves to separate chunks, but the amount of it is irrelevant. Indeed, with proportional spacing, it can be difficult to determine how many spaces (or tabs!) there are, even when consciously trying. I find that I don't expect any ordering to be determined by the ordering of punctuation and other characters that aren't either words or numbers, so my approach is to consider all of that noise as well.
In a nutshell, then, the string is broken down into chunks of words and numbers.
As with any real programming problem, there are many ways to skin the cat. I initially considered a more object-oriented approach with a state machine that would scan each string, assembling and returning text tokens and numeric tokens, both deriving from a base token class. This would probably have been more efficient because it would only have required scanning as far as necessary to find some difference; in many cases, the end of a string won't need to be considered. However, the amount of complexity it adds to the code (at least, the code that you need to write yourself) grew too large for the work I was willing to invest.
Instead, I simply use a regular expression to chop up each string. The regex I developed looks for groups of letters-only or digits-only, with other ignored "junk" between them.
Since the point of using this is to sort a list, it's expected that the comparison will be called many times (twice per comparison, and with most algorithms there will be N log(n) comparisons), I have compiled the regular expression, and saved it as a static field in the class. The initial compilation of the regex takes some time on startup, but is likely to be worthwhile when sorting a string of any appreciable size.
private static Regex sRegex;
static NaturalComparer()
{
sRegex = new Regex(@"[\W\.]*([\w-[\d]]+|[\d]+)", RegexOptions.Compiled);
}
When asked to compare, we ask the regex to return all of the matches found from each of the two strings.
MatchCollection leftmatches = sRegex.Matches(left);
MatchCollection rightmatches = sRegex.Matches(right);
Then we loop through each of the matches from the left string, following along in the right string using an Enumerator as a cursor to remember our position. Actually, we hope not to loop through the whole thing; as soon as we can definitively say that one string should precede the other, we return that information.
If one string runs out of matches before the other, the one that ran out is considered "smaller". We can tell that the left one ran out first because we've finished the foreach loop, but there is still at least one match remaining from the right (which we determine by attempting to move the enumerator to the next item). Conversely, if the right string's enumerator can't move any further while we're still in the loop, then the right string has run out.
IEnumerator enrm = rightmatches.GetEnumerator();
foreach (Match lm in leftmatches)
{
if (!enrm.MoveNext())
{
return 1;
}
Match rm = enrm.Current as Match;
int tokenresult = CompareTokens(CapturedStringFromMatch(lm),
CapturedStringFromMatch(rm));
if (tokenresult!=0)
{
return tokenresult;
}
}
return enrm.MoveNext() ? -1 : 0;
(By the way, one wonders why the MatchCollection can only provide an old-fashioned non-typesafe enumerator, rather than an Enumerator<Match>.)
Pros and Cons of the RegEx
Had we taken the OO approach, we could have built additional intelligence into the string chunking. But with the simpler regular expression approach, we're forced to accept some compromises.
One compromise is the way numbers are interpreted. The period is treated as a separator, never a decimal point. This interferes with the ability to handle decimal numbers (although I've implemented a hack workaround as you'll see later). However, by not treating decimal numbers properly, we do gain the ability to handle version numbers (e.g. 1.02.1.68) properly.
The handling of word-breaking characters could be better. Things like hyphenation and apostrophes aren't addressed. It would be possible to make a (much more complicated) regex to handle some of this. However, these choices are necessarily language-dependent, so I elected not to build an English-only solution.
In any case, regular expressions are extremely versatile. If your application demands somewhat different chunking, I encourage you to experiment with the regex.
Comparing Chunks
Given two chunks (one from each string), the first thing to do is determine whether they represent numbers or just text. This is done by trying to parse the matched string into a double. I use a double not because of decimals (remember, my regex doesn't handle that anyway), but because the set of digits might describe a really huge number.
leftisnum = double.TryParse(left, out leftval);
rightisnum = double.TryParse(right, out rightval);
A numeric comparison is only necessary if both chunks represent numbers. If one is, but not both, then the numeric one sorts first. If neither are (i.e. they're both text), then a regular old string comparison is used.
The actual numeric comparison bears some explanation. If the values are different, then the behavior is as expected. However, if the strings represent the same value, we don't necessarily regard the values as equivalent. Since 1 and 001 both evaluate to the same value, but may mean very different things in some contexts, there's an extra check.
Consider a comparison of strings 2.1 and 2.001; we'd obviously want the latter to evaluate as smaller. But when the chunk comparison takes place, we don't have visibility to the preceding "2.". My hack solution is to simply assume that numbers having equivalent value, but differing lengths are different. Specifically, other things being equal, the longer one is considered to be a smaller value. This rule correctly evaluates this example.
if (leftisnum)
{
if (!rightisnum)
{
return -1;
}
if (leftval<rightval)
{
return -1;
}
if (rightval<leftval)
{
return 1;
}
return Math.Sign(right.Length - left.Length);
}
Conclusion
Determining whether a human would place one string in order in front of another is a fuzzy question, and may not have any deterministic correct answer. But a reasonable algorithm isn't difficult to develop. And once you've got that algorithm, the design of the .NET Framework makes it trivially easy to make your application sort strings in a manner that a normal person will find much more intuitive.
And this is a worthy goal. Computers can do amazing things, but today's state of the art is still a sad state of affairs in terms of computer usability. I believe that investing effort into this is more valuable than much of the direction of software development today.
Acknowledgements
- Effective C#: 50 Specific Ways to Improve Your C# by Bill Wagner
Provides a great discussion of the implementation of IComparer and its cousin IComparable. And that's just one of the 50 articles in the book. Every C# developer should not only read this, but have it close at hand. - Regulazy by Roy Osherove
A fantastic tool for figuring out and testing regular expressions. - Jeff Atwood's CodingHorror
Consistently discusses both new technology and the failures of the software development world.
History
- 2007-12-31 (no code change)
- Removed comment about lack of docs on
Compare return values, since the documentation was pointed out to me
- 1.0.1.2 - 2007-12-17
- Bug fix - missed one possible combination when comparing numbers to text
- 1.0.0.1 - 2007-12-16

