Introduction
In this article, we will discuss a solution to a software puzzle "Find Sophie". The puzzle is a modification of the famous NP-hard "Traveling Salesman" problem.
Unfortunately, many job interviews require software engineers to solve hard programing puzzles. The puzzles do not test abstract thinking, understanding, communication skills, reasoning, learning, planning, and problem solving. In short, they do not test any of those things that define intelligence.
Luckily, Microsoft is no longer the front runner of the software industry and majority of the companies stopped imitating Microsoft and do not ask "Four People on a Bridge" type puzzles. It is fair to say that Google, Facebook, and Apple have taken Microsoft’s place as software industry leaders. So now every company wants to be the next Google or Facebook and, as a result, they ask the same questions that Google, Facebook, and Apple ask – algorithmic puzzles.
It is almost impossible to solve those puzzles without the knowledge of basic (and not so basic) algorithms. "Find Sophie" solution is based on graph theory algorithms so before we get into details, we have to review some of them.
Background
First, some useful terms:
Vertices are the circles in a graph and edges are the lines connecting the vertices. Big-O notation is used to quantify the running time of each algorithm. Graphs can also be conveniently described using a two-dimensional matrix that contains 1 if there is an edge connecting the two vertices and 0 otherwise. Weighted graphs have a number assigned to each edge. For weighted graphs, ones can be substituted with the non-zero weight of the edge. Trees are a subset of graphs – directed graphs. For trees, vertices are called nodes. Each node can have zero or more children (nodes that can be navigated to from the parent node).
| Short Description |
|
| Depth First Search (DFS) | Mostly used to traverse a tree, and it does so by going as deep as it can until it hits a node that has no children.Then it backtracks. Non-recursive implementations use a stack to keep track of the nodes traversed. | O(V + E) |
| Breadth First Search (BFS) | Instead of going into depth, like in DFS, we first explore all the branches (children) before backtracking. | O(V + E) |
| Dijkstra's | Used to find shortest paths in non-negative weighted graphs between a pair of vertices. A queue is frequently used to implement the algorithm. | O(V^2)
(basic implementation) |
| Floyd–Warshall |
|
Used to find shortest paths in weighted graphs between all pairs of vertices. Unlike Dijkstra’s algorithm will also work for negative weights. Fails to calculate the shortest path if negative cycles exist. |
|
|
| Prim's algorithm | Used to find a minimum spanning tree (a tree that connects all vertices together and has the minimum total weight) in a weighted undirected graph. | O(V^2)
(basic implementation) |
The Puzzle
Now we are finally ready to explore the THE PUZZLE.
After a long day of coding, you love to head home and relax with a loved one. Since that whole relationship thing hasn't been working out for you recently, that loved one will have to be your cat, Sophie. Unfortunately you find yourself spending considerable time after you arrive home just trying to find her. Being a perfectionist and unable to let anything suboptimal be a part of your daily life, you decide to devise the most efficient possible method for finding Sophie.
Luckily for you, Sophie is a creature of habit. You know where all of her hiding places are, as well as the probability of her hiding in each one. You also know how long it takes you to walk from hiding place to hiding place. Write a program to determine the minimum expected time it will take to find Sophie in your apartment. It is sufficient to simply visit a location to check if Sophie is hiding there; no time must be spent looking for her at a location. Sophie is hiding when you enter your apartment, and then will not leave that hiding place until you find her.
Your program must take the name of an input file as an argument on the command line.
Note: You do not have to read input and output specifications (unless you really want to).
Input Specifications
The input file starts with a single number, m, followed by a newline. m is the number of locations available for Sophie to hide in your apartment. This line is followed by m lines, each containing information for a single location of the form (brackets for clarity):
<location name> <probability>
where probability is the probability that Sophie is hiding in the location indicated. The sum of all the probabilities is always 1. The contents of these lines are separated by white-space. Names will only contain alphanumeric characters and underscores ('_'), and there will be no duplicate names. All input is guaranteed to be well-formed. Your starting point is the first location to be listed, and in effect it costs you no time to check if Sophie is there.
The file continues with a single number, c, followed by a newline. c is the number of connections that exist between the various locations. This line is followed by c lines, each of the form:
<location name> <location name> <seconds>
where the first entry is the name of location and the second one is the number of seconds it takes you to walk between them. Again these lines are white-space-delimited. Note that the locations are unordered; you can walk between them in either direction and it will take the same amount of time. No duplicate pairs will be included in the input file, and all location names will match one described earlier in the file.
Output Specifications
Your output must consist of a single number followed by a newline, printed to standard out. The number is the minimum expected time in seconds it takes to find Sophie, rounded to the nearest hundredth. Make sure that the number printed has exactly two digits after the decimal point (even if they are zeroes). If it is impossible to guarantee that you will find Sophie, print "-1.00" followed by a newline instead.
Example
It definitely looks like a graph problem but it is almost impossible to solve a problem like that without a good example:
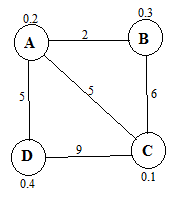
In our example, Vertex A is the entrance to the apartment (the first possible hiding place of the cat). The probability that the cat is hiding there is 0.2. It takes 2 second for the guy to walk from A to B (another hiding place), and the probability of the cat being there is 0.3.
By definition, expectation, in a discrete case, is x1*p1 + x2*p2 + x3*p3 + … where x is the value with probability p. For example, expected value of finding Sophie if we go to location C and on the way pass location D is probability of cat being at location D multiplied by time it takes to reach location D plus probability of cat being at location C multiplied by the time it takes to reach location C –> 0.4 * 5 + (5+9)*0.1 = 3.4.
We have to visit all vertices to find the expected value. In our example, there are 6 possible paths.
ABCD, ABDC, ADCB, ADBC, ACBD, ACDB
Mathematically speaking, we want to rearrange 3 (BCD) different objects into a sequence. There are 3*2*1 ways to do it, and in discrete math, this is called n-factorial (3! = 3*2*1 = 6). Now it might seem obvious that ADCB is a better choice than ABDC (via A) because going from B to D we have to come back to A but this is not correct. While for ADCB, we have 5*0.4 + 0.1*14 + 20*0.3 = 9.4, For ABDC (via A), we have 2*0.3 + 9*0.4 + 18 *0.1 = 6. It is easier to represent all 6 paths as a tree.

If we calculate all six paths we will see that ABDC (via A) gives us the best expected value. So the algorithm that we used to solve this example does the following:
- Find all permutations (ABCD, ABDC, ADCB, ADBC, ACBD, and ACDB).
- For each permutation, find shortest path for each pair of vertices on the path (for ABCD, find shortest path between AB, BC, and CD)
- For each permutation, calculate the expected value using the shortest paths.
- Choose the minimum expected value
That is a good solution but it has a problem. Its time complexity is at least O(N!). So solving the problem for 20 nodes will be unrealistic (20! = 2432902008176640000). So we really need to find some optimization. And by looking at the tree, we can see that we can easily disregard at least some of the paths without calculating the entire path. So if we start from the left, and calculate ABCD and then ABDC we know that current minimum expected value is 6 and there is no need to calculate ACDB because ACD already sums up to 6.1. While in case of 4 nodes the optimization is minimal, for 20 nodes this simple optimization will help us to disregard entire branches, transforming the solution from to O(N^3). Of course, the worst case is still O(N!) but let’s hope for the best.
Solution
Once we understand the example, it is easy to see the solution. For N hiding places, we construct a tree that has (N-1)! paths (each permutation is a path). For each path, we calculate the shortest (in terms of expectation) path between every two vertices on the path and sum them up. This way we calculate the expected value of each path, and all we have to do now is to find the minimum one. And yes, as discussed above, we have to add some optimization to achieve a better average running time then O(N!).
Implementation
void Graph::read_graph(char* file) reads the graph from input files into memory. It creates two data structures; a matrix of weights (double** Weight) and a vector of nodes that contain the probabilities. The matrix will be used to calculate the shortest paths and the nodes will be used to create all desired permutations.
So what algorithm should we choose to calculate shortest paths between vertices? We can certainly use Dijkstra's algorithm but its basic implementation runs in O(V^2) and we would have to run it many times (Worst case N!, without any caching). Floyd–Warshall’s algorithm is a better choice because it runs in O(V^3), worst case, and computes shortest paths between ALL pairs of vertices. The best thing about this algorithm is that implementing it is easy.
The input for the algorithm is NxN matrix that has weight as the value. In our case, the weight is always positive so we can have -1 as “not connected”. For our example, the matrix would like that:
The algorithm modifies the input matrix so that at the end, its values are the shortest paths.
So according to the matrix, the shortest path between D and B is 7. Don’t be surprised that the shortest path between A and A is 4 and not 0 because we have visit B before going back to A.
Here is the code:
void Graph::run_floyd()
{
for (int k = 0; k < NodeCount; ++k)
{
for (int i = 0; i < NodeCount; ++i)
{
for (int j = 0; j < NodeCount; ++j)
{
double sum = Weight[i][k] + Weight[k][j];
bool inf = ((Weight[i][k] == -1) || (Weight[k][j] == -1));
if (!inf)
{
if (Weight[i][j] == -1)
{
Weight[i][j] = sum;
}
else if (sum < Weight[i][j])
{
Weight[i][j] = sum;
}
}
}
}
}
}
An that is how it works. The two inner loops iterate through the matrix. The third loop (k) relies on the fact that path[i][j] = min ( path[i][j], path[i][k]+path[k][j] ). For each two vertices, can we get a better solution if we go through a third vertex (k)? If yes, we simply update the matrix. Note, that for this problem the matrix will always be symmetrical because the graph is not directed.
Next thing we need to do is to create all the permutations (paths) and calculate expected time for every permutation (with some optimization to skip unrealistic ones). We do it in function called permutate.
Unfortunately the function is recursive but the idea behind this function is simple. We add all the nodes (places where the sucker hides) to a vector (an array). Each node in the array has a flag that states whether the node is part of the current permutation or not. We will loop through the array choosing the first node that is not currently used, calculating its expected value and recursively passing the values to the function. This way, we generate a tree similar to the tree drawn in the example without consuming any additional space. Our optimization will also help us not to generate branches that are greater than the current minimum expected time.
double permutate(double probability, double expectation, double time, Node* currNode)
{
if (m_Nodes.size() < 2)
{
if (m_Nodes.size() == 0)
{
return - 1;
}
else
{
return 0;
}
}
if (!currNode)
{
currNode = m_Nodes[0];
probability = 1 - currNode->getProbability();
expectation = 0;
}
else
{
probability -= currNode->getProbability();
expectation += time * currNode->getProbability();
}
if (m_CurrentMin >= 0)
{
if (expectation + probability * time >= m_CurrentMin)
{
return m_CurrentMin;
}
}
bool allInUse = true;
for(unsigned int i=1; i < m_Nodes.size(); ++i)
{
Node* nextNode = m_Nodes[i];
if (nextNode->isInUse())
{
continue;
}
allInUse = false;
nextNode->setInUse(true);
permutate(probability, expectation, time +
Weight[currNode->getID()][nextNode->getID()], nextNode);
nextNode->setInUse(false);
}
if (allInUse) {
m_CurrentMin = expectation;
}
return m_CurrentMin;
}
Conclusion
That is it for the solution. The problem is not hard, but requires a lot of thought and patience. Not many companies can afford puzzles like this one to be part of their hiring process, but Facebook is an exception – it has almost a billion users and IPO is not too far away. Now, whether you want to be part of this hiring process is entirely up to you. And yes, many small (and not so small) companies will try to imitate the success of Facebook by adding comparable problems into their interview process. They will probably fail with the “success” part but will definitely succeed in eliminating 99% of good software engineers.))
If you have no life (or a job) and want to work in Silicon Valley, the blog has a set of questions from a typical technical interview.

