Introduction
This article is about the CppArchivPlus class and how to use it in your projects. CppArchivPlus is a very small C++ class that provides effective methods to organize your data. I have written the class for the purpose of sending data across a network and keeping track of certain data. Implementing critical routines as the ones in my class in ASM can increase performance speed, thus I have coded the entire class in Assembly using MASM in combination with Microsoft Visual Studio 2010. My class has nothing to do with the MFC CArchiv class.
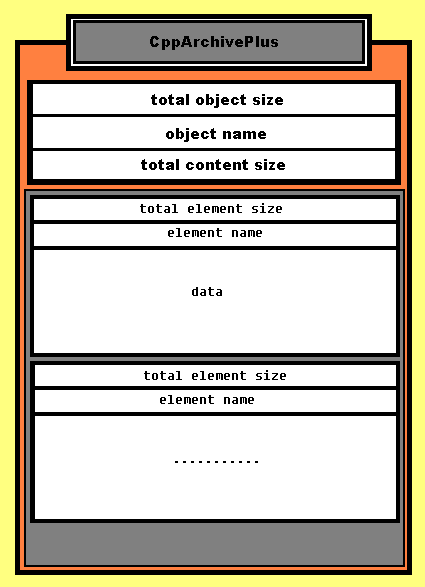
CppArchivPlus
First, I want to point out some of the advantages of using this class in your C++ code. You can dynamically add data to the CppArchivPlus object by using the add_data() function. Data inside the object is contained inside of an Element that can only be found/removed by its name. In the code below, you can see a very simple example of the basic usage of how to add objects. A 32 bit string hash algorithm is included; though I can not guarantee that it is the most effective hash algorithm, it will have to do the job for now.
#define STR_SIZE 0x0D
char str_a[] = {"Hello World!\0"}
unsigned long ul_name = 0x00;
int main(void)
{
CppArchivePlus* pArchiveObject = new(STR_SIZE) CppArchivePlus;
ul_name = CppArchivePlus::hash("Billy\0");
pArchiveObject->add_data(str_a,STR_SIZE,ul_name);
pArchiveObject->add_data(str_a,STR_SIZE,ul_name+1);
}
The primary intend of this class is to prevent memory leaks and to provide better streaming capabilities for any form of data. Since the object is always in a serialized state, it makes it very easy to stream it without any further processing. You also don't need to keep track of the object size since the total size is contained within the object header. The header also contains the overall object name and the byte count of the contained data. That makes the CppArchivePlus class very easy to use with general streams and sockets. An example of how easy it is to send a created instance of CppArchivePlus over a network is shown below.
SOCKET sock;
send( sock, pArchiveObject, pArchiveObject->get_t_size(), NULL );
You can remove data from the object by using the remove_data() method, an example of which can be seen below. Note that remove_data() does not minimize the actual object memory that was allocated, all it does is remove all contents that were written by add_data().
pArchiveObject->remove_data(ul_name);
To find data, you will have to resort to the GET_DATA macro which is nothing but a macro for the get_space method. The get_space method is used to find an element by its name. But because the element address is not automatically the data address, I suggest you use the GET_DATA macro. What get_data does is go through every entry within the object and compare names until it finally finds the matching item. The more objects that are listed inside the class instance, the longer the process of finding a name it will take. Which brings me to the overall performance.
I assumed right from the beginning that the class would work faster with medium/bigger objects because of the "first dword then byte" writing algorithms used in the add_data and remove_data methods. When I finished and tested the class, it turned out to be right.
Summary
It was very fun working on this. I am very new to ASM, this is actually my first real project I have written in it. Working with C++ on such a low level really helped me get a better look into the mechanics of the language itself. Please, if anyone has suggestions about my ASM code, let me know what I can do better.

