Introduction
The attached code is an implementation of the VF graph isomorphism algorithm. This algorithm is available at the VF Graph Comparing library, and there are other programs which form a wrapper to call into this library from, for instance, Python. The same could certainly be done for C#, but the code here implements the algorithm entirely in C#, bypassing the C++ library altogether. There were a few reasons for this. First, this offers the algorithm in an entirely managed environment. Second, I found the original C++ code to be not so efficient and not terribly well written. Third, the VF library was actually coded to do comparisons between various algorithms so you get those algorithms in tow whenever you use the library, and finally, it just sounded like fun.
Background
The graph isomorphism problem accepts a pair of directed graphs as an input, and returns true if one graph is just a "relabeling" of the other. The VF algorithm will also perform a subgraph isomorphism in which the there is a subgraph of the first graph which is isomorphic to the second graph. It also allows for retrieving the mapping after a match has been made. It allows for context checking in which nodes can carry attributes, and those attributes can be tested against the corresponding attributes for the isomorphic node, and the matching can be rejected based on the outcome of such tests. At its simplest, this allows the user to "color" nodes and only allow nodes of the same color to be matched.
The VF algorithm essentially builds up the isomorphism one match at a time, and does an educated backtracking search for the matches. There are various criteria when determining if the addition of a match is acceptable. Some of these are merely to boost performance, but the most important criterion is that the newly added match maintains the isomorphism of the group gathered thus far. In this way, it's pretty obvious that when you've handled all the nodes in the second graph, you've achieved the isomorphism you're looking for.
The details for all this can be found in the paper: A (sub)graph isomorphism algorithm for matching large graphs. My implementation follows this paper pretty exactly. About the only difference is that I use a sorted list for some of the internal sets of nodes, which means I'm more liable to come onto a viable match earlier. It also means that I can stop searches earlier than in the original algorithm.
Using the code
The code is implemented as a class library. There are two primary classes required to interface with the code. The first is the Graph class which is used to create/manipulate your graph. The only constructor for Graph is the default one which takes no parameters. Once you have a graph, you can insert nodes using InsertNode() and edges using InsertEdge(). Normally, InsertNode is called with no parameters, in which case it returns the integer ID for the inserted node. These integer IDs can then be used in the InsertEdge(int node1, int node2) call to insert edges between nodes. An alternative form of InsertNode takes a single object parameter which represents the attribute for the inserted node. The attributes can be arbitrary, or they can represent an implementation of the IContextCheck interface. The IContextCheck is very simple, and looks like this:
interface IContextCheck
{
bool FCompatible(IContextCheck icc);
}
As shown below, the match can be set up to use these context check attributes, in which case any two nodes which are examined as a possible match have the context check called on them. If the context check returns false, then no match is allowed. In this case, all attributes in the graph must implement IContextCheck. Any nodes with no attribute will match with any other node. Attributes can also be attached to edges via the InsertEdge(iNode1, iNode2, object attr), but they (currently) can't be used to affect the match as the attributes attached to nodes are.
Graph graph = Graph();
graph.InsertNodes(4)
graph.InsertEdge(0,1);
graph.InsertEdge(1,2);
graph.InsertEdge(2,3);
graph.InsertEdge(3,0);
There are also methods to delete nodes (DeleteNode(int ID)) and edges (DeleteEdge(int idFrom, idTo)). Please note that we are entering directed edges so that InsertEdge(1,0) is a different edge from the one inserted with InsertEdge(1,0).
Once you have created a pair of graphs which you wish to check for isomorphism, you can create a VfState object with them using the constructor VfState(Graph graph1, Graph graph2). The VfState can then be used to do the actual check, as follows:
...
VfState vfs = new VfState(graph1, graph2);
bool fIsomorphic = vfs.FMatch();
if (fIsomorphic)
{
int[] mapping = vfs.Mapping1To2;
...
There is also a Mapping2To1 with the mapping from graph2 to graph1. In subgraph isomorphism (which is used by default), the algorithm looks for a subgraph of graph1 which is isomorphic to graph2. The VfState can take two booleans as either VfState(graph gr1, graph gr2, boolean fIso) or VfState(graph gr1, graph gr2, boolean fIso, boolean fContextCheck). If fIso is true, then the algorithm searches for a strict isomorphism. This is more efficient than searching for a subgraph isomorphism. If fContextCheck is true, then all node attributes are context checked against the counterparts in the mapping, as outlined above.
Update: In addition to the above two signatures for the VfState constructor, there is now another which takes a third boolean: VfState(graph gr1, graph gr2, boolean fIso, boolean fContextCheck, boolean fFindAll). fFindAll is false, by default. If true, then after the match, you can get a list of all mappings of all isomorphisms. Each isomorphism is represented in the list by a FullMapping structure, which just holds the 1 to 2 and 2 to 1 mappings in two int[] arrays, as in the following example.
...
VfState vfs = new VfState(graph1, graph2, false, false, true);
bool fIsomorphic = vfs.FMatch();
if (fIsomorphic)
{
foreach(FullMapping fm in vfs.Mappings)
{
int[] mapping1to2 = fm.arinodMap1To2;
int[] mapping2to1 = fm.arinodMap2To1;
...
Algorithm overview
As mentioned above, the algorithm is, basically, a search over the space of matches for an isomorphism between graph2 and some subgraph of graph1. By "match", I mean a mapping from a single node of graph1 to a single node of graph2. Each step in the search algorithm proposes adding a new match to the isomorphism as developed so far. If we can extend these matches to include all of graph2, then we're finished. If not, we have to backtrack and attempt different matches. The top level algorithm of this search looks like this (since the 4/29 update, this is really pseudo code, with the stuff for multiple isomorphisms left out for clarity, but the basic idea is still intact):
bool FMatchRecursive()
{
Match mchCur;
CandidateFinder cf;
if (FCompleteMatch())
{
return true;
}
cf = new CandidateFinder(this);
while ((mchCur = cf.NextCandidateMatch()) != null)
{
if (FFeasible(mchCur))
{
BacktrackRecord btr = new BacktrackRecord();
AddMatchToSolution(mchCur, btr);
if (FMatchRecursive())
{
_fSuccessfulMatch = true;
return true;
}
btr.Backtrack(this);
}
}
return false;
}
I should point out that this is a recursive version which is easier to understand, but ifdefed out in the actual code in favor of a non-recursive version. You can ifdef it back in and verify that it works via the NUnit code, but it may blow the stack with sufficiently large graphs and will be less efficient. The method uses a CandidateFinder to locate potential matches, runs through them, and uses a feasible method to do more careful checking. This checking includes ensuring that the match doesn't break the isomorphism we've established thus far. BacktrackRecord allows us to undo the effects of the call to AddMatchToSolution in case this match doesn't work out. We provisionally add the match to the current isomorphism, extending its range by one more node in each graph, and we recursively check to see if we can extend this new isomorphism to a complete mapping over graph2. If so, we're done and return true. If not, we move back to the state before we added the match, and look for other potential matches in the main loop.
The real key functions here are NextCandidateMatch and FFeasible. These two functions depend very much on a division of the nodes into four sets on each graph. The first set, which we'll refer to as I1/I2 on graph1/graph2, are the nodes which are participating in the isomorphism produced at each stage of the algorithm. The second set, T1/T2 for graph1/graph2, is the set of nodes which have at least one edge pointing towards a node in I1/I2. The third set, F1/F2 for graph1/graph2, is the set of nodes which have at least one edge pointing to them from a node in I1/I2. Note that if a node has both predecessors and successors in I1/I2, then it is a member of both F1/F2 and T1/T2. Finally, nodes which are disconnected from any node in the isomorphism are in sets D1/D2.
These groups are maintained by the use of an enum:
[Flags]
enum Groups
{
ContainedInMapping = 1,
FromMapping = 2,
ToMapping = 4,
Disconnected = 8
}
Each node maintains a field with this enum in it stating which group it belongs to. In addition, the VfState class keeps a list of each of these groups, sorted by degree of each node.
Obviously, if we are to maintain the isomorphism by adding a match between a node N1 in graph1 and N2 in graph2, certain structural rules must hold, and this is how our search manages to whittle down the candidates to a select few and weed out incorrect matches fairly quickly. For instance, the CandidateFinder ensures that either both nodes come from the T sets, or both from the F sets, or both from the D sets. The case for the T sets stems from the observation that if N1 points into the current isomorphism, then so must N2. Similarly for the F and D sets. If there are no nodes in either T1 or T2, the candidate finder looks to the F sets, and after that, the D sets. When CandidateFinder searches through a particular group for matches, it does so by decreasing degree since that is the way the lists are sorted. This has a couple of implications. First of all, it gives us a better shot at matching the correct nodes earlier rather than later. Secondly, since N1 must have at least as many edges as N2 (remember that graph2 can map into a subgraph of graph1), we can give up as soon as we find a node in the T1 list with degree less than N2 since all nodes thereafter will have still lower degree. Actually, if a true isomorphism is being sought, then we can stop if the first node of T1 has a different degree than the first node of T2. There are many situations where we have an equality failure condition in the case of a true isomorphism or a >= failure condition in the case of a subgraph isomorphism. For that reason, we have a delegate in the VfState class, fnComp, which performs one or the other of these tests, and we set it once when the VfState is constructed and then use fnComp throughout the code thereafter for these tests.
Once the CandidateFinder has selected a viable match, we do further checking with FFeasible(). There are essentially four tests that a match must pass to be allowed through FFeasible(). The first and foremost, simply verifies that the match, when added to the current isomorphism, doesn't wreck that isomorphism. To be precise, every node in the isomorphism which is connected to N1 must map to a node which is similarly connected to N2. In addition, if context checking is being done, it is also done here in the feasibility test, and matches can be rejected if their attributes conflict. This is really the only absolute requirement. As long as this is true, as we add nodes, we will always maintain a valid isomorphism of the nodes in the I sets so that when all nodes of graph2 are in I2, we will have our completed isomorphism. However, using only this criteria would allow many matches which would have to be manually backtracked over eventually, so we want to prune our choices here, and that is what the other three requirements of FFeasible are all about.
The other three requirements are really just versions of the same rule applied to the T, F, and D groups, so I'll just discuss it for the T groups, but the same logic applies to the other two groups. I'm still assuming that we are adding a match between nodes N1 of graph1 and N2 of graph2. We require that the count of In edges from nodes in T1 to N1 exceed the count of In edges from nodes in T2 to N2. Ditto for the Out edges. This is another situation where we use fnComp as described above to do an equality test for true isomorphism or inequality for subgraph isomorphism. This same test is applied to the F sets and D sets. The code to do the first test described here (In edges from T1 nodes compared to In edges from T2 nodes) looks like this:
if (!fnCmp(
GetGroupCountInList(lstIn1, _vfgr1, Groups.FromMapping),
GetGroupCountInList(lstIn2, _vfgr2, Groups.FromMapping)))
{
return false;
}
Here, GetGroupCountInList() just counts the nodes in the list of the first argument which are in the correct group for the graph given by _vfgr1 (graph1) or _vfgr2 (graph2). The lstIn1 is just the list of nodes which have an edge pointing towards N1, and similarly for lstIn2.
When we add the matching to the isomorphism, this potentially moves several other nodes into other groups. The AddMatchToSolution() method keeps track of all this movement in the backtrack record so everything can be moved back if the match fails. The backtrack records are just linked lists of BacktrackActions, each of which is either a movement into the isomorphism or a movement from one group to another.
This completes the overview of the algorithm. I'm not including the conversion between Graphs and VfGraphs. The main difference here is to sort the nodes in the order of increasing degree in the VfGraph and the setup of various lists of nodes in preparation for the VF algorithm. All the nodes are initially placed in the D group, and the I group is empty. We also keep the mapping between the unsorted nodes in the original Graph structure and the nodes in the VfGraph structure so that we can sort it all out in the end and return mappings via Mapping2To1 and Mapping1To2, which refer to the node IDs in the original Graph objects rather than the IDs used in the VfGraphs. This is all really more in the matter of bookkeeping than any part of the algorithm proper.
Performance
When I started looking at the code, I wanted to find out how many matches were getting through the candidate finder, how many were getting through the feasibility checker, and how many made it through both but were ultimately backtracked over. I got my random graph creator to create a random graph with 1000 nodes, and found to my surprise that no nodes were being backtracked - the combination of the candidate finder and the feasibility checking was acting as a perfect oracle of what would end up in the final isomorphism. That seemed impossible, and I suspected a bug. To test this, I commented out the call to backtrack, and ran all the NUnit code. Two tests failed, which made me feel much better - my backtrack code was actually useful. After I started thinking about this, it all began to make much more sense. In the case of a random graph, there are probably very few nodes which have maximum degree. Of those with the same maximum degree, in order to pass the feasibility test, they must have the same number of Out edges and In edges. More than likely, this uniquely identifies the first match to be entered into the isomorphism. From there on, as the isomorphism builds up, the chances that the isomorphism itself is wrong go rapidly to essentially zero, since to assume otherwise is to assume that there are two isomorphically identical portions in the random graph. Ditto for adding new matches, since they must be attached to the current isomorphism and more than likely can only fit in one place of the isomorphism. So, we have a good chance of getting the first matches correct, and after those, the chances go up rather than down. Consequently, it began to dawn on me that the algorithm is going to work very well on random graphs. In fact, if we assume no backtracking and a constant average degree, I believe that the algorithm is O(n^2), which is great.
Of course, at this point, I wanted to try to find much worse cases. It seems obvious that it's going to have more backtracks if the graph is "highly automorphic", by which I mean that large portions of the graph are isomorphic to other portions. It seemed to me that a really bad case of this was a grid - nodes at the intersections of the gridlines, and edges between them along the grid lines. When I tried this, sure enough, there were lots and lots of backtracks. I realized that it ought to be worse when there was no isomorphism, so I hooked two opposite "corners" of the grid together with an edge in one graph which wasn't present in the second. I had to cancel out of this run after a long wait, because I think it's pretty close to the worst case. Since the corners had lower degrees than the middle nodes, they were going to be examined after all the middle nodes had been checked for isomorphism, and since they were the only non-isomorphic part, it was going to try zillions of backups. To verify this, instead of one graph between these two nodes, I inserted several so their higher degree caused the algorithm to examine them first. This caused the runtime to be almost immediate. Of course, I was trying this with a 30x30 grid, and it probably would have run reasonably well for smaller versions. One possibility which would have eliminated this particular problem is to have just done a comparison of node degrees. Since I'm already sorting nodes by degree, this should be easy. It will also work for subgraphs where I have to establish a one to one mapping between nodes in the second graph and nodes with a larger degree in the first graph.
Another potential problem area might be comparing a graph with much higher degrees with one with much lower degrees. This could eliminate the advantage of sorting the nodes, tending to bring isomorphic nodes together in the candidate finder. I don't think it would be too awful a problem since the original algorithm described in the links at the start of this article never took advantage of graph ordering at all. Of course, if the degrees got high enough, it might actually be easier since nodes will match to other nodes more easily. In the extreme, any 1-1 mapping will do if the first graph is complete.
So, the lesson is that the worst case can be pretty awful, but smaller graphs or more random graphs are pretty safe to expect a O(n^2) performance.
I also did some very non-disciplined timing (I didn't try to eliminate any background processing, for instance), and came up with the following for the random graphs in my test:
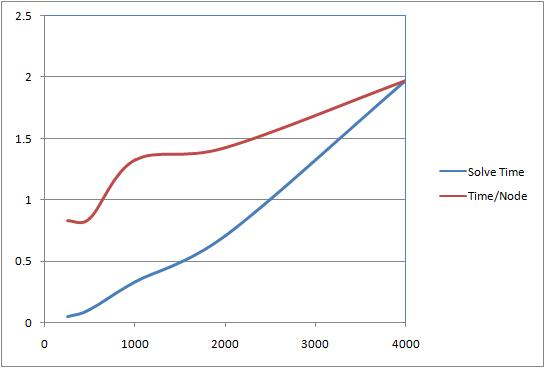
Note that the time/node has been multiplied by 4000 so that it scales nicely on the graph. The edge load factor for the 1000 node graph was 0.1 so that each node has an average of about 100 In edges and 100 Out edges. I wanted to hold the degrees the same for all the graphs, so for the other sized graphs, the edge load factor is inversely proportional to the count of nodes. Thus, the load factor for the 2000 node graph was 0.05.
Points of interest
A few caveats should be pointed out. First of all, when we speak of subgraph isomorphism, the definition of subgraph here is a graph obtained by removing nodes and their attached edges. This means that you can't remove edges directly in the subgraph unless they are attached to a removed node. I don't think this is any big problem to allow for, but haven't incorporated it yet.
The code has NUnit testing included. I like NUnit, and recommend you get it and the excellent TestDriven.NET Visual Studio add-in. They're both free and very worthwhile, and I think you'll be happy you did in the end. However, if you can't bring yourself to take these simple steps, then you can just eliminate the NUnit.FrameWork reference in the project and take the NUNIT definition out of the debug configuration. Even in this case, you can probably understand the code a bit better by looking at the NUnit code. There is no test or demo program in the code since it's been tested entirely through NUnit.
One last point - I would assume that the base code runs just fine on Mono, but I'm not set up to test it. I'm not sure whether NUnit runs there, so it might have to be removed also.
History
- 1-23-08 - First version.
- 1-24-08 - Algorithm overview added, and (whoops!) forgot originally to make
FMatch public. Added back in an ifdefed out recursive call, and made a name change or two. - 1-30-08 - Corrected the first link, added a section on performance, and added a quick one time degree compatibility check between graphs.
- 4-29-08 - Added in the ability to get a list of all isomorphisms rather than the first one found.

