Introduction
This article describes a class to read Unicode character names. The names are read from the file UnicodeData.txt, which is one of the files that make
up the Unicode Character Database. A copy of the file is included with the demo project, but it can also be obtained
from the aforementioned link.
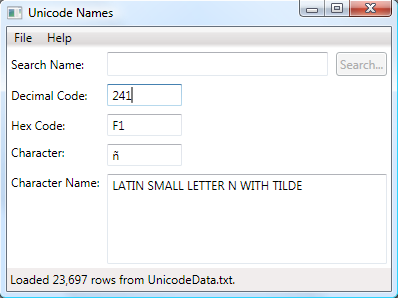
A demo application is also provided. The application allows the user to enter a decimal or hexadecimal code point, type a character, or search for a character name.
While the application is useful for touring the available names, it is overly complex for learning how to use the classes themselves.
Background
The UnicodeNames class, which this article describes, relies on some supporting classes that I described in previous articles.
Specifically, it uses the CsvReader class described in the article Flexible CSV reader/writer
with progress reporting. It also uses the PreviewTextBox control described in the article WPF TextBox
with PreviewTextChanged event for filtering.
To simply use the UnicodeNames class described in this article, neither of the other articles is required for reading.
There are two name fields available in UnicodeNames.txt. The Name field, located in the second column of this file, is used preferentially.
However, for control characters, the name is always <control>. The alternative name field Unicode_1_Name is used, in these instances, when it is available.
For example, code point 10 (decimal) has a name of <control> and a Unicode_1_Name of LINE FEED (LF). In this case, the latter is used.
Additionally, there are large ranges of code points that do not have names. However, the range has a named starting and ending code point. The names of these
two code points are suffixed with First and Last. The UnicodeNames class will return this same name (without the suffix)
for all characters between these two code points.
Examples of these code points (in hexadecimal) are 100000 (First), 100001, and 10FFFD (Last). All are within the range <Plane 16 Private Use>.
Using the Code
The code could not be much simpler to use. Creating an instance of the class is done as follows:
string path = "UnicodeData.txt";
UnicodeNames names = new UnicodeNames(path);
names.LoadFile();
Getting the name for a character is as simple as the following:
int codePoint = 10;
string name = names[codePoint];
You should also plan on disposing of the UnicodeNames instance when you are no longer going to use it, as follows:
names.Dispose();
Finally, if you have concerns about the time required to load the file into memory, there are methods and properties that make it easy to integrate with
a BackgroundWorker component.
The RowEnd event is raised each time a row of the file is read. To further assist, the ProgressPercentage property describes the percentage
of the file that has been loaded. Lastly, the CancelAsync method is available to abort the load operation.
Points of Interest
This was my first full fledged foray into WPF development. I did cheat a little bit and use WinForms for its AboutBox. To the WPF purists out there, I apologize.
History
- 8/3/2011 - The original version was uploaded.

