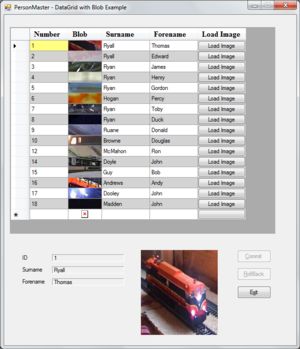
Objective
The purpose of this article is to provide a working example of a BLOB column on a DataGridView on a Windows Form using C++/CLI. It also demonstrates some related and unrelated features:
- A Command Button on the
DataGridView - The Enum flag in action
- Creating two Visual Studio projects in the same solution
- Parsing XML without reference to a schema using recursion
- Creating and updating XML nodes again without reference to a schema
- Managing XML attributes
- Using preprocessor directives as an alternative to interactive debugging
- The benefits of layered approach
- Compare and contrast the XML data handler with the MySQL data handler
Background
Like the enum class columns on the DataGridView, there are very few examples of BLOBs on a DataGridView using C++/CLI on the web but in this case, there are some good examples in C# and VB that are available. Most examples use either hard coded data or a relational database - but this one is among the few to draw its data from XML.
Example Origin
The example is drawn from a system I am working on, which relies on stored images to identify customers.
A Doubtful Design Decision
Before going any further, it is important to draw attention to what experienced users would recognise as an insane decision to combine a DataGridView with XML using Document Object Model (DOM) access. Why? Because the entire dataset is in memory twice! And to make matters worse, we are using memory hungry BLOBs, or Binary Large Objects to give them their full name. If you are implementing a similar form with a DataGridView and have XML as your chosen data store, then explore using XML stream XmlReader/ XmlWriter.
However, this is a tutorial example and I want to simulate the behaviour of the MySQL database that my applications deliver in terms of instant updates and deletes, and for this, DOM is much more suited. Equally, if you need to manipulate XML in the normal course of your work, I believe DOM offers greater flexibility; this has also influenced my decision to use it here.
Style Note
I don’t like much more than the definitions in my .h files, so where the IDE adds a Windows Form function or event to the .h, my practice is to call a user defined function in the .cpp passing on the parameters. It’s an overhead, because I cannot force the IDE to insert Windows Form functions directly into the .cpp, and when I relocate them there, the IDE gets confused – but I prefer the order that it gives things. OK, now on to the real stuff.
Managing the BLOB
Loading the BLOB Using the Command Button
Before looking at the BLOB on the DataGridView, we will first add a command button to the grid. We will use this button to begin the loading of the BLOB. Add the button by editing the properties of your DataGridView, then choosing Edit Columns. Give one of these columns a type of DataGridViewButtomColumn.
Again, using your Properties panel, put a CellContentClick event on your DataGridView. Here is the code I have in mine:
if (e->ColumnIndex != dgLoadImage->Index)
return; else
{
OpenFileDialog^ openfiledialog = gcnew OpenFileDialog();
openfiledialog->DefaultExt = L"bmp|jpg|gif";
if (openfiledialog->ShowDialog() == System::Windows::Forms::DialogResult::OK)
{
m_FileName = openfiledialog->FileName;
String ^MessageString = "Button Click";
MessageBox::Show(m_FileName,MessageString);
pictureBox1->Image= Drawing::Image::FromFile(m_FileName);
gridPerson->Rows[e->RowIndex]->Cells[dgBlob->Index]->Value=
Drawing::Image::FromFile(m_FileName);
m_fs = gcnew FileStream(m_FileName, FileMode::Open, FileAccess::Read);
m_ElementList = m_ElementList | m_FlagBits::BLOB;
}
}
First up, the click event is programmed to exit if the column in question is anything other than the button column - in this case, dgLoadImage. Now this statement is redundant since there is only one button column on the grid, but it is there if needed in future.
The first action in the else block is to offer the standard open file dialog filtered by typical document types. But you will notice a bug in the filtering - everything comes back. Since it is not central to anything, I allowed that one to slip through.
The line:
pictureBox1->Image= Drawing::Image::FromFile(m_FileName);
pulls the image into a PictureBox below the grid
This brings us to the first key line of the article:
gridPerson->Rows[e->RowIndex]->Cells[dgBlob->Index]->Value=
Drawing::Image::FromFile(m_FileName);
The BLOB column dgBlob on the current row of the DataGrid (gridPerson) now has the image stored in it. Finally, I stream the BLOB into a FileStream^ variable m_fs and set an enum flag to indicate that there has been a value change on the dgBlob column, both for later use.
Extracting the BLOB from a Row
I am using the RowEntered event on the DataGridView to demonstrate extracting a BLOB from a DataGridView row. This is the code involved:
try
{
array<Byte> ^byteBLOBData = gcnew array<Byte>(0);
byteBLOBData = safe_cast<array<Byte>^>(
gridPerson->Rows[e->RowIndex]->Cells[dgBlob->Index]->Value);
MemoryStream^ stream = gcnew MemoryStream(byteBLOBData);
pictureBox1->Image = Image::FromStream(stream);
}
catch(...)
{
pictureBox1->Image = nullptr;
}
First, I declare a new byte array byteBLOBData into which I am casting the BLOB cell. Then I launder this into a memory stream, and finally I pass that stream to the pictureBox1 image.
Note the use of catch(...). This is a lot like using goto, not advisable but useful in limited circumstances. It is not advisable because you are ignoring the error situation without examining or otherwise dealing with it. However, I use it in one circumstance only, where I am happy to assign a null value to an element regardless of what caused the error to occur.
Saving (Persisting) the BLOB
Right now, we have our BLOB on the DataGridView, but that is not of much use if we lose it as soon as the form is closed. We need to save it somehow. For this, I am using the RowValidating event to capture the BLOB cell into a variable defined as array<Byte>^.
The Person class has a BLOB field, m_Blob defined as arrayBlobXMLGrid<Byte>^. p_Blob is the property that manages data transfers to and from this field. I am using a binary reader (br) to extract the image data from the file stream (m_fs) saved earlier. The Length property on m_fs decides how many bytes are read into the BLOB on the Person class.
BinaryReader ^br = gcnew BinaryReader(m_fs);
TransactionPerson->p_Blob = br->ReadBytes(safe_cast<int>(m_fs->Length));
TransactionPerson->p_BlobLen = m_fs->Length;
TransactionPerson->p_BlobName= m_fs->Name;
br->Close();
m_fs->Close();
Close your binary reader and the file stream variables. Completing the Save requires some specific actions depending on the nature of the repository you are using.
Saving to XML
String^ modifiedBlob;
modifiedBlob = Convert::ToBase64String(arg_PersonRow->p_Blob);
The BLOB node's value element will be of type string so I apply a conversion to Base64 on our byte array before passing it to a temporary String^ variable. This done, it can be saved like any other node.
Saving to a Relational Database Using SQL
cmd->Parameters->Add("@Photo", MySqlDbType::LongBlob,
arg_PersonRow->p_Photo->Length)->Value = arg_PersonRow->p_Photo;
@photo is a command parameter, the @ symbol before a token in the CommandText string marks that token as a parameter, and the code here loads that parameter with our BLOB identifying it to the MySQL database as MySqlDbType::LongBlob. Following this, the Insert or Update Statement will complete the save process.
Loading a Saved BLOB into the DataGridView
The third aspect required to complete our BLOB management is some code to load our saved BLOB information back into the DataGridView. In this instance, my approach depends on the format in which the image is stored.
From XML
When I detect an XML node containing BLOB data during parsing, I populate a temporary byte array by extracting the Base64String information from the node value:
tmpBlob = Convert::FromBase64String(ArgValue);
From SQL
Extracting the BLOB from the results of a SQL fetch also involves the population of a temporary byte array:
tmp_Photo = gcnew array<Byte>(reader->GetInt32(11));
reader->GetBytes(3,0,tmp_Photo,0,reader->GetInt32(11));
The size of the byte array is determined in this example by field 11 (where the image length is stored when the image is saved). We then use MySQLDataReader's GetBytes method to extract the BLOB. These are what the parameters are:
- 3 - the element number of the BLOB in the fetched row.
- 0 - the offset, and since we are not using one, the image is to be found from position 0 in element 3.
tmp_Photo - the name of the byte array that will receive the BLOB.reader->GetInt32(11) - the length of the BLOB, stored in element 11 of the fetched row.
Completing the Load
My fetch module will return a list of Persons for population onto the DataGridView. This list is in the same format coming from either XML or SQL. There is no further BLOB specific action required to get it onto the DataGridView. For completeness, this is the code:
array<Object^>^ itemRec = gcnew array<Object^> {candidate->p_PersonID,
candidate->p_Blob,
candidate->p_Surname,
candidate->p_Forename
};
gridPerson->Rows->Add(itemRec);
That is all that is involved in managing a BLOB on a DataGridView, but there is much more in the code used to achieve this that is worth taking a look at.
A Command Button on the DataGridView
In this example, I have used the IDE to add a command button to my DataGridView at design time. A column type of DataGridViewButtonColumn will create the button for you. In order to use the button, I have added a CellContentClick event to my DataGridView. At first glance, the code for this event looks a little bizarre as it opens with an if statement that forces exit when the click event is on any column other than the button.
if (e->ColumnIndex != dgLoadImage->Index)
return; else
{
:
}
This is just me being extra careful. The CellContentClick event will only fire for button columns, so in this example, I have nothing to worry about; however, if I had more than one button on my form, then I need to determine which column triggered the click event and act accordingly.
The Enum Flag in Action
In my most recent example on enum columns on the DataGridView, the code also included enum flags which were not put to any use in that example. Here you get to see how enum flags can be defined and used. The technology behind enum flags borrows heavily from bitwise operations in traditional computing, but you do not need to be particularly concerned about this. So to begin, here is the enum flag definition from this example:
[Flags] enum class m_FlagBits
{
PERSONID = 1,
SURNAME = 2,
FORENAME = 4,
BLOB = 8,
};
m_FlagBits m_ElementList;
The first thing to note is the [Flags] attribute. This instructs the compiler to treat the enum class definition that follows as a set of bitwise flags. The next significant aspect is the numbering associated with each flag. It must commence at 1 and double for each new flag. Failure to follow this practice will not produce any compiler errors but will lead to unexpected results at run time. Finally, we define a variable, in this case, m_ElementList, whose type is our new enum flag class.
The flags in this example correspond to the columns on our DataGridView and we will be using them to note which columns have had value changes made to them.
Every time the user enters a new row, I use the RowEntered event on the DataGridView to set all the flags to false. This is the code:
m_ElementList = m_ElementList & ~ m_FlagBits::PERSONID;
m_ElementList = m_ElementList & ~ m_FlagBits::SURNAME;
m_ElementList = m_ElementList & ~ m_FlagBits::FORENAME;
m_ElementList = m_ElementList & ~ m_FlagBits::BLOB;
For example, consider PERSONID. The first statement above tells us that m_ElementList is equal to itself and PERSONID is false. This is repeated for every flag. Next, when a change is made to a column value, I turn on the flag for that column using this line:
m_ElementList = m_ElementList | m_FlagBits::PERSONID;
If you watch m_ElementList using the debugger, you will see it adding the value from the class definition for every flag set to true and subtracting any flag value where a flag is set to false. So internally, an m_ElementList value of 5 would tell the system that PERSONID and FORENAME are true and all other flags are false. But we do not have to worry about interrogating this value. We can check each flag by name to see if we need to take any action:
if (static_cast<int>(m_ElementList) & static_cast<int>(m_FlagBits::PERSONID))
{
TransactionPerson->p_PersonID = System::Convert::ToInt16(lblPersonID->Text);
}
Note the casting of the values to integer. This is the method I have learned and it works reliably. There may well be a neater one. In English, what we are saying is, "If m_ElementList includes PERSONID is true then do something". Consider the old fashioned bitwise method of explaining this. For our purposes, we have PERSONID and FORENAME true and all others are false. We can represent m_ElementList as "1010" where the 1's represent PERSONID and FORENAME. m_FlagBits::PERSONID is represented as 1000. Applying a bitwise AND to these does a binary addition resulting in 1000, or true for PERSONID allowing some action to take place.
However, a flag set to false such as m_FlagBits::SURNAME, represented as 0100, will return a value of false when ANDed against m_ElementList containing "1010" so no action happens for Surname.
In large applications, the data stores, be they tables or XML, will have long rows. There are significant performance benefits to updating only those columns to which changes were made, and Enum flags are a useful way to manage this degree of control.
Creating Two Visual Studio Projects in the Same Solution
Normally I have a 1 to 1 relationship between projects and solutions, as much out of habit as anything else. However, in the event that I do resume producing commercially viable code of my own, then some of my modules will play a role in multiple systems. This example has two modules in it and for ease of loading on the part of members who choose to download it, I have opted to experiment with a single solution approach. The primary benefit that I see from a single solution is that the entire application can be compiled at once. Naturally, the Solution Explorer on the IDE is also more meaningful, and the IDE does not need to be told where to find assemblies because it places both the main exe and any DLLs in the same folder at solution level.
When you click "File -> New -> Project" from the menu (or use the key sequence Ctrl+Shift+N), the default Solution setting is "Create new solution". Change this so that it is "Add to Solution", as shown here:

Parsing XML Without Reference to a Schema Using Recursion
The set of functions used in this example to parse XML and extract the relevant data are based on the set I use for complex customs and excise messages. While they are overkill for this very simple XML, they will prove very useful if you need to interrogate large XML documents at some stage. I have taken them from the examples provided by Stephen Fraser in his book "Pro Visual C++/CLI and the .NET 3.5 Platform" (Apress 2009). This method uses XML as a DOM or Document Object Model. It is driven by a Navigate function which requires the first node on the document as a seed from which it will commence its processing. This is how you get this first node:
XmlNode ^node = doc->FirstChild;
Navigate
Navigate is an excellent example of recursion in action. If you visualize your XML document as a tree, Navigate travels down the leftmost available path, calling itself for both the first child of the current node and the next sibling of the current node. Each call is stored to be revisited. When it hits a null node, it stops making calls and dusts off the most recently stored NextSibling, where upon it begins the call and store sequence again until it hits a null. This process repeats itself until there are no further nodes to process.
But Navigate does more than just call itself. As soon as it has established that the current node is not null, it will call either a Process_Node function for text type nodes or Process_Attribute when a node has attributes.
As discussed, Navigate takes a node as a parameter, but you will also see another parameter, depth. This parameter is not required, but I maintain it because it is useful sometimes during debugging, particularly on complex XML with identical subtrees at different levels in the document.
Process_Node
Process_Node takes the parent of the current node and the value of the current node as parameters. So why the parent and not the node itself? This is a quirk of the DOM. For example, consider one of our nodes, PERSON_ID, it has a node type of "Element" and its value, the actual Person ID, is stored in a child node of type Text. So when we hit a text node, we pass the value of that text node and its parent so that we know what element we are dealing with to Process_Node. In Process_Node, we examine each node by name and take an action depending on that node. Because this example is populating a grid, I have chosen to hold back the information until I have got all the siblings on the current row.
Process_Attribute
Process_Attribute takes the current node, the current attribute, and the value of the current attribute as parameters. We could reduce this to just the current attribute, and still provide the same functionality. The current node's only purpose is to simplify information for the debugging process in this example. In larger documents with identically named attributes on different nodes, it improves the readability of the code, but makes no other contribution. Similarly, passing the value as a separate parameter contributes only to readability.
Typically, you check the name of the attribute and the name of the node then perform your chosen action.
Creating and Updating XML Nodes Again Without Reference to a Schema
When the flag to act on a node is set, I search for the node, and if it is not found and I have a value to put away, then it is time to create a node, otherwise the existing node is either updated or removed by the function to update nodes.
Creating a Node
My method of creating an XML node is not particularly attractive and in time I will replace it, however it works, and "if it ain't broken..." etc. What I do is build a list of elements from the current node to be added all the way back to the root. Elements common to all nodes are added as part of the Create_Node function. Because our example uses a very shallow tree, we have multiple instances of this strange looking logic:
node_list->Clear();
node_list->AddLast("Person_ID");
Create_Node(doc, arg_PersonRow->p_PersonID.ToString(), node_list, nullptr);
However, in a more complex example, it makes more sense:
node_list->Clear();
node_list->AddLast("GoodsShipment");
node_list->AddLast("CustomsGoodsItem[" + GI_Index.ToString() +"]");
node_list->AddLast("Consignee");
node_list->AddLast("Address");
node_list->AddLast("CityName");
Create_Node(doc, GoodsItemConsigneeCity->Text, node_list, nullptr);
Create_Node
Create_Node takes the XML document, the value of the node to be inserted, the path list, and where relevant, an attribute list as parameters. The first act carried out in Create_Node is the addition of any common nodes to the head of the list.
A document element is created for the new node:
new_node = ArgDoc->CreateElement(ArgList->Last->Value->ToString());
Next, a text element is created for the value to be associated with the new node:
node_text = ArgDoc->CreateTextNode(ArgValue);
Then make the text element a child of the new node:
new_node->AppendChild(node_text);
We add any attributes at this point, but I will deal with these as a separate topic. So moving on, the node just added is removed from the list and the Create_Parent node is called using the document, the new node just created, and the remains of the list. Create_Parent will decide where the new node fits into the document.
Create_Parent
This function calls itself recursively and beginning with the the parent of the new node passed from Create_Node, takes the parent of that node from the node list, checks the document for it, and where the parent does not exist, creates it and keeps repeating the process until it finds a parent that does exist.
Looking at the function, if it finds that the node list passed in is empty, it sets up the document root and that is all it needs to do.
if (ArgList->Last == nullptr)
{
XmlNode ^tmp;
XmlAttribute ^att;
tmp = ArgDoc->CreateXmlDeclaration("1.0","UTF-8","");
ArgDoc->AppendChild(tmp);
tmp = ArgDoc->CreateComment(
"Test XML created by Ger Hayden's BlobGridXml example");
ArgDoc->AppendChild(tmp);
att = ArgDoc->CreateAttribute("xmlns:xsi");
att->Value = "http://www.w3.org/2001/XMLSchema-instance";
ArgChild->Attributes->Append(att);
ArgDoc->AppendChild(ArgChild);
ret urn; }
However, that is a rare event, the only time that condition is ever satisfied is adding the first node to a blank document. Carrying on, now things begin to get ham-fisted, but like I said, it works. The list of parents needs to be converted to a string that can be used in an XPath search to establish if the parent node at the end of it exists. This is the code to build that string:
TmpStr = "";
current = ArgList->First;
if (current != nullptr)
{
TmpStr ="//";
while (current != nullptr)
{
TmpStr += current->Value->ToString();
current = current->Next;
if (current != nullptr)
{
TmpStr +="/";
}
}
}
The resultant string is used to search the document as follows:
TmpNode = ArgDoc->SelectSingleNode(TmpStr);
When a node is found, the new node passed in as a parameter can be inserted among its siblings using the Insert_Sibling function, and again our work is done, with no further calls necessary.
However, you may find that the parent node does not exist, in which case it has to be created:
new_parent = ArgDoc->CreateElement(ArgList->Last->Value->ToString());
Note that some node names coming off the list will have indices in [] on them. This causes the CreateElement to fail, so these are checked for and, if found, stripped off in the catch block. If the refined string cannot be used to create a parent, a failure occurs and no further action is taken. Having successfully created a parent node, the node passed in as a parameter is appended to its new parent node, the parent node is removed from the end of the list of parent nodes, and as its last act, Create_Node is called again recursively, with the document, the new parent node, and what remains of the node list:
new_parent->AppendChild(ArgChild);
ArgList->RemoveLast();
Create_Parent(ArgDoc, new_parent, ArgList);
Insert_Sibling
Insert_Sibling takes the document, a parent node, and a child node as parameters, then determines where among its siblings the child should be placed. This is heavily hardcoded and has to be reworked any time the document format changes. This function is the one that makes the case for using the schema to decide where elements should go on a document.
It looks at the name of the node passed in, and for each node, it nominate a unique parent string in XPath format, then checks the name of the child, and for each child, builds a list of siblings that must come before it. E.g.:
if (ArgNode->Name == "row")
{
Parent = "//row[" + (Row_Index +1) + "]/";
sibling_list->Clear();
if (ArgChild->Name == "Person_ID")
{
sibling_list->Clear();
}
if (ArgChild->Name == "Surname")
{
sibling_list->Clear();
sibling_list->AddLast("Person_ID");
}
if (ArgChild->Name == "Forename")
{
sibling_list->Clear();
sibling_list->AddLast("Person_ID");
sibling_list->AddLast("Surname");
}
if (ArgChild->Name == "Blob")
{
sibling_list->Clear();
sibling_list->AddLast("Person_ID");
sibling_list->AddLast("Surname");
sibling_list->AddLast("Forename");
}
}
Now that we know the siblings that precede our child node, we need to see which one closet to the child actually exists. This is the job of the Find_Candidate function. When a candidate is found, the child node is added after it:
ArgNode->InsertAfter(ArgChild, Candidate);
Otherwise, it is added as the first sibling:
ArgNode->PrependChild(ArgChild);
Find_Candidate
Find_Candidate takes the document, the parent node in XPath format, and a list of siblings as parameters. It cycles through the sibling list, storing the most recently found one, until either the list is exhausted or a search fails. It returns the most recently found node if any, or if not, returns null. This is the code:
Candidate = nullptr;
while (curr_list_item != nullptr)
{
TmpNode = ArgDoc->SelectSingleNode(ArgParent +
curr_list_item->Value->ToString());
if (TmpNode != nullptr)
Candidate = TmpNode;
curr_list_item = curr_list_item->Next;
}
return Candidate;
Updating a Node
My update process is much less involved. If a new value exists, the node value is changed, but if the new value is null, the node is removed. This is managed by the Update_Node function.
Update_Node
Update_Node takes the current node, its new value, and possibly a list of attributes as parameters. If the new value is null, it calls Delete_Node and concludes. But when there is a value to be updated, we need to cycle through a node's children until we find its text node:
ArgNode = ArgNode->FirstChild;
while ((ArgNode->NodeType.ToString()!= "Text") && (ArgNode != nullptr))
{
ArgNode = ArgNode->NextSibling;
}
If we find a text node, the code to change the value is a simple:
ArgNode->Value = ArgValue;
Having changed the value, the attributes may also need attention, but this will be dealt with separately. If a text node is not found, a message is shown informing the user that the node has not been updated.
Delete_Node
Delete_Node takes the node to be removed as a parameter. I don't like childless nodes in my XML, so the first thing I do in this function is check to see if the current node has any siblings:
if ((ArgNode->NextSibling != nullptr) || (ArgNode->PreviousSibling != nullptr))
{
has_siblings = true; }
else
{
has_siblings = false;
}
If it does have siblings, then all this function needs to do is remove the node passed in, but first we need to find its parent:
if (ArgNode->ParentNode != nullptr)
{
Parent = ArgNode->ParentNode;
has_parent = true;
}
else
{
has_parent = false;
}
Once we have established that this node has a parent, removing it is very easy:
Parent->RemoveChild(ArgNode);
If the node just deleted has no sibling, but has a parent, then we remove the parent too using a recursive call:
Delete_Node(Parent);
This will ensure that the delete action keeps going until it works its way back up to a node with siblings. This keeps the document tidy, ensuring that any element either has a child or a value. In the extreme case, it removes the entire document. But for this to happen, we would need to have a document with only one element having a value and a long list of ancestors.
Managing XML Attributes
We have already met attributes when we looked at Create_Node and Update_Node. In this example, the attributes I use are the name and size of the BLOB. Typical other attributes you may encounter are language on free text fields, or currency code when a monetary value is being represented.
When a node, in this example the BLOB, has an attribute, I set a flag and build an attribute list whose elements consist of name and value pairs.
AttributeList = gcnew List<CAttributeDefinition^>();
AttributeList->Add(gcnew CAttributeDefinition("Name", arg_PersonRow->p_BlobName));
AttributeList->Add(gcnew CAttributeDefinition("size", arg_PersonRow->p_BlobLen.ToString()));
The attribute list is included as the last parameter to either Create_Node or Update_Node.
Create_Node
In Create_Node, we call Add_Attribute for each attribute to be added.
Update_Node
The situation in Update_Node is a little more complex. We examine the attributes already in the node for each candidate. If a match is found, that attribute is updated, otherwise it is added. This is the code:
for each (CAttributeDefinition^ Candidate in ArgAttrList)
{
bool AttrUpdated = false;
for (int i = 0; i < ArgNode->Attributes->Count; i++)
{
if (ArgNode->Attributes[i]->Name == Candidate->m_Attribute_Name)
{
ArgNode->Attributes[i]->Value = Candidate->m_Attribute_Value;
AttrUpdated = true;
}
}
if (!AttrUpdated)
{
Add_Attribute(doc, ArgNode->ParentNode, Candidate);
}
}
But that is not all - if the node is found to have no attributes, then call Add_Attribute for each attribute to be added, as was done in Create_Node, and finally where attributes exist on the node, but the Attributes flag is false (will happen when the updated node has no attributes), all attributes must be removed:
ArgNode->Attributes->RemoveAll();
There is one other scenario for which I have not included code - removing individual attributes.
Add_Attribute
Add_Attribute is not a complex function. It takes the document, the node, and the candidate (includes both name and value, remember) as parameters.
It creates an attribute on the document using the attribute name, then adds the value to the attribute, and finally appends the attribute to its node. This is the code:
XmlAttribute ^attr;
attr = ArgDoc->CreateAttribute(Arg_NewAttr->m_Attribute_Name);
attr->Value = Arg_NewAttr->m_Attribute_Value;
ArgNode->Attributes->Append(attr);
Using Preprocessor Directives as an Alternative to Interactive Debugging
If you have already looked at the sample code included with this article, you will have noticed blocks of grayed out code encased in # tags. These are not strays from Twitter, but are in fact refugees from a bygone era of C coding when interactive debuggers were often not available. E.g., from DB_PersonManager.cpp:
#ifdef SHOW_DELETE_DISPLAYS
MessageString = "Found Sibling Name = ";
if (ArgNode->NextSibling != nullptr)
MessageString += ArgNode->NextSibling->Name;
else
MessageString += ArgNode->PreviousSibling->Name;
MessageBox::Show(MessageString);
#endif
This has a commented out companion in DB_PersonManager.h:
So why have I bothered to include these dinosaurs in my code? Firstly, they offer a great way of speedy debugging where there are a set of 'Usual Suspects' whose values you need to check when things are not working out. Simply remove the commenting before the #define and recompile. The #ifdef code then goes black, and when you recompile, these values display. They are also a great way of doing debug on code deployed to machines that do not have the IDE. E.g., those of a client. Simply deploy a .exe with the #define uncommented and you get your displays. This is a safer and faster method than keying in and then removing displays in situations where you need them. Quicker because there are only two characters to insert or remove, and safer because there is no risk of mistakenly removing a line of mission critical code along with the display, or of omitting to remove a display that might be in somewhere awkward, like a big loop, which as Murphy would have it will only show itself when your client's IT Manager for Company President is looking on. Experiment with them and consider how they might help you.
The Benefits of a Layered Approach
The objective of a layered design is the separation of the different activities that make up your system using a tiered structure in such a way that you can change any one of them with little or no impact on the other layers. A typically layered system might begin with menu modules. These in turn call the modules in a second layer whose function is to display forms and that allow the user to manage data and create reports. The modules in this interactive layer in turn call modules in an input/output layer. The function of the IO layer is to manage the reading and writing of data. In a properly layered system, it should be possible to change the methods used by, for example, the IO layer modules to manage data using XML where they previously managed it using SQL without having to change code in the menu and interactive layers. Where the data access calls are embedded in the interactive module, they become more difficult to find, and are often fundamentally intertwined in the logic of the interactive module. Another benefit of layering is that data manipulation statements, e.g., getting the age of an individual, can be reused.
This example does not have a menu layer but it has modules that could typically sit on the interactive layer (BlobXmlGrid2) and the I/O layer (DB_PersonManager).
Compare and Contrast XML Datahandler with MySQL Datahandler
In this section, we will look at DB_PersonManager from this example and DB_PersonMaster from the ticketing system I have under development. I will use them to illustrate the similarities and differences when it comes to interchanging the modules in your I/O layer between XML and a relational database. First up, they would not normally have different names, this is a safety precaution I took to keep them from accidentally editing my system code while preparing this example.
These are the common function calls:
DB_PersonManager
static List<DB_PersonManager::CPersonMaster^>^ Fetch_PersonMaster(int arg_call_type);
static int Update_PersonMaster(CPersonMaster^ arg_PersonRow,
int arg_UpdateList, int arg_Index);
static int Insert_PersonMaster(CPersonMaster^ arg_PersonRow,
int arg_InsertFlags, int arg_Index);
DB_PersonMaster
static List<DB_PersonMaster::CPersonMaster^>^
Fetch_PersonMaster(MySqlConnection^ arg_Connection, int arg_call_type);
static int Update_PersonMaster(MySqlConnection^ arg_Connection,
CPersonMaster^ arg_PersonRow, int arg_UpdateList);
static int Insert_PersonMaster(MySqlConnection^ arg_Connection,
CPersonMaster^ arg_PersonRow, int arg_InsertList);
The only difference is that I am passing in a connection string, and if the need to have interchangeable XML/relational database IO emerges for my system, then this will be parameterized too, and the delete function will be restored to the SQL version. Currently, all my IO modules share a common dynamic delete statement. The internal structure of these functions is very different, but they produce the same end results. The XML version has the following raft of additional internal functions not required by the relational database version:
static void Navigate(XmlNode ^node, int depth);
static void Process_Attribute(XmlNode^ ArgNode,
XmlAttribute^ ArgAttr, String^ ArgValue);
static void Process_Node(XmlNode ^ArgNode, String^ ArgValue);
static void Add_the_Person();
static XmlElement^ Create_Node(XmlDocument ^ArgDoc,
String ^ArgValue,
LinkedList<String^>^ ArgList ,
List<CAttributeDefinition^>^ ArgAttrList);
static void Delete_Node(XmlNode ^ArgNode);
static void Update_Node(XmlNode ^ArgNode,
String^ ArgValue,List<CAttributeDefinition^>^ ArgAttrList);
static void Create_Parent(XmlDocument ^ArgDoc, XmlElement ^ArgChild,
LinkedList<String^>^ ArgList );
static void Insert_Sibling(XmlDocument ^ArgDoc, XmlNode ^ArgNode, XmlElement ^ArgChild);
static XmlNode^ Find_Candidate(XmlDocument ^ArgDoc, String ^ArgParent,
LinkedList<String^>^ ArgList );
static String^ ReformatListEntry(String ^ArgListEntry);
static void Add_Attribute(XmlDocument ^ArgDoc, XmlNode ^ArgNode,
CAttributeDefinition^ Arg_NewAttr);
Walking Through the Attached Code
The attached BlobXmlGrid2 example is a complete Visual Studio 2008 project, cleaned before zipping. First again, a note on my style. I don’t like much more than the definitions in my .h files, so where the IDE adds a Windows Form function to the .h, my practice is to call a user defined function in the .cpp passing on the parameters. It’s an overhead, because I cannot force the IDE to insert Windows Form functions directly into the .cpp, and when I relocate them there, the IDE gets confused – but I prefer the order that it gives things.
This sample is a standard Windows Forms application with a DataGridView and several labels dropped on from the toolbox as illustrated in the second screenshot. The Expiry Type column is a combobox column as are Unit ID and Unit Description, the other three columns are textbox columns. All this is achieved using the form designer.
In here, we will take a further, somewhat higher level, look at Form1.h, BlobXmlGrid2.cpp, DB_PersonManager.h, and DB_PersonManager.cpp modules.
Form1.h
This is the complete list of assemblies I am referencing:
using namespace System;
using namespace System::ComponentModel;
using namespace System::Collections;
using namespace System::Windows::Forms;
using namespace System::Data;
using namespace System::Drawing;
using namespace System::IO;
using namespace System::Collections::Generic;
using namespace DB_PersonManager;
Note the call to DB_PersonManager. This is essential to calling our assembly to manage the XML. In addition to calling the namespace, we need to include a reference to the assembly. Launch the property page using either Alt-F7 or menu options Project -> BlobXMLGrid2 Properties. The properties page looks like this:
Now click on Add New Reference, then go to the Browse tab. Find DB_PersonManager.DLL and select it for inclusion.
In addition to the Launchform function call, I have one other line in the constructor. This is for the error icon:
m_CellInError = gcnew Point(-2, -2);
After the:
#pragma endregion
I define my internal variables and functions. Included here is the enum class prefixed [Flags].
There are two variables defined for the error icon handling followed by the definitions for the DataTables, BindingSources, and DataSets.
The final segment of the .h file has the function definitions added through the form designer on the IDE for the DataGridView and the buttons Commit, Rollback, and Exit. They are:
UserAddedRowCellValueChangedRowEnterRowValidatingCellBeginEdit – Stores colours – doesn’t have anything in the .CPPCellEndEdit – Restores colour then calls the .CPP functionUserDeletingRowbtnCommit_ClickbtnRollback_ClickExit_Click – Shuts down the exampleFormClosingList_Setup
BlobXmlGrid2.cpp
LaunchForm
There are a few interesting ‘bells and whistles’ on show in this function called from the constructor.
This code customizes the grid header:
DataGridViewCellStyle^ headerStyle = gcnew DataGridViewCellStyle;
headerStyle->Font = gcnew System::Drawing::Font("Times New Roman", 12,FontStyle::Bold);
gridPerson->ColumnHeadersDefaultCellStyle = headerStyle;
Personalizing the selection colours:
gridPerson->DefaultCellStyle->SelectionBackColor=Color::FromArgb(255,255,128);
gridPerson->DefaultCellStyle->SelectionForeColor=Color::Black;
Tooltip text on the column headers:
for each(DataGridViewColumn^ column in gridPerson->Columns)
column->ToolTipText = L"Click to\nsort rows";
Apply xolour binding to the grid:
gridPerson->AlternatingRowsDefaultCellStyle->BackColor = Color::LightGray;
Load_People is called to populate the grid. The functions that follow have for the most part already been visited above for one feature or another.
Load_People
Load_People populates the grid using the fetch function on DB_PersonManager.
Process_RowEntered
Process_RowEntered initializes the enum flags and stores the contents of the current row.
Process_CellEndEdit
Process_CellEndEdit is included only for its role in displaying error icons.
Process_CellValueChanged
Process_CellValueChanged updates the labels and sets enum flag values when contents are changed.
Process_RowValidating
Process_RowValidating is part of the error handling. Update_Row will only be called if this function is satisfied.
Update_Row
Update_Row looks after inserts and updates on the XML.
Process_UserDeletingRow
Process_UserDeletingRow is called when a row has been deleted from the grid. It replicates the delete on the XML.
Process_Commit
Process_Commit makes grid changes permanent.
Process_Rollback
Process_Rollback restores the grid to the most recently committed state.
Process_Exit
Process_Exit is used to leave the example, checking for unsaved changes as it goes.
Process_Click
Process_Click handles the button click on the grid.
DB_PersonManager.h
DB_PersonManager begins with the commented out preprocessor declarations.
Then we have the required namespaces:
using namespace System;
using namespace System::Windows::Forms;
using namespace System::Collections::Generic;
using namespace System::Drawing;
using namespace System::Xml;
using namespace System::Text;
Next, the Person class itself is defined:
public ref class CPersonMaster
{
public:
CPersonMaster(void)
{
}
CPersonMaster(String^ arg_BlobName,
Int64 arg_BlobLen,
array<Byte> ^arg_Blob,
String^ arg_Forename,
String^ arg_Surname,
int arg_PersonID) :
m_BlobName(arg_BlobName),
m_BlobLen(arg_BlobLen),
m_Blob(arg_Blob),
m_Forename(arg_Forename),
m_Surname(arg_Surname),
m_PersonID(arg_PersonID){}
CPersonMaster(String^ arg_Forename,
String^ arg_Surname,
int arg_PersonID) :
m_Forename(arg_Forename),
m_Surname(arg_Surname),
m_PersonID(arg_PersonID){}
property String^ p_BlobName
{
String^ get()
{
return m_BlobName;
}
void set(String^ arg_BlobName)
{
m_BlobName = arg_BlobName;
}
}
property Int64 p_BlobLen
{
Int64 get()
{
return m_BlobLen;
}
void set(Int64 arg_BlobLen)
{
m_BlobLen = arg_BlobLen;
}
}
property array<Byte> ^p_Blob
{
array<Byte>^ get()
{
return m_Blob;
}
void set(array<Byte>^ arg_Blob)
{
m_Blob = arg_Blob;
}
}
property String^ p_Surname
{
String^ get()
{
return m_Surname;
}
void set(String^ arg_Surname)
{
m_Surname = arg_Surname;
}
}
property String^ p_Forename
{
String^ get()
{
return m_Forename;
}
void set(String^ arg_Forename)
{
m_Forename = arg_Forename;
}
}
property int p_PersonID
{
int get()
{
return m_PersonID;
}
void set(int arg_PersonID)
{
m_PersonID = arg_PersonID;
}
}
private:
String^ m_BlobName;
Int64 m_BlobLen;
array<Byte>^ m_Blob;
String^ m_Surname;
String^ m_Forename;
int m_PersonID;
};
The header is concluded with the definition of the communications class:
public ref class CComs_PM
{
private:
static ref class CAttributeDefinition
{
public:
CAttributeDefinition(String^ arg_Name, String^ arg_Value)
:m_Attribute_Name(arg_Name), m_Attribute_Value(arg_Value)
{}
String^ m_Attribute_Name;
String^ m_Attribute_Value;
};
static String^ tmpID, ^tmpForename, ^tmpSurname, ^tmpBlobName;
static array<Byte>^ tmpBlob;
static Int64 tmpBlobLen;
static Image^ tmpImage;
static int Row_Index;
static XmlDocument ^doc;
static LinkedList<String^>^ node_list;
static void Navigate(XmlNode ^node, int depth);
static void Process_Attribute(XmlNode^ ArgNode,
XmlAttribute^ ArgAttr, String^ ArgValue);
static void Process_Node(XmlNode ^ArgNode, String^ ArgValue);
static void Add_the_Person();
static XmlElement^ Create_Node(XmlDocument ^ArgDoc,
String ^ArgValue,
LinkedList<String^>^ ArgList ,
List<CAttributeDefinition^>^ ArgAttrList);
static void Delete_Node(XmlNode ^ArgNode);
static void Update_Node(XmlNode ^ArgNode, String^ ArgValue,
List<CAttributeDefinition^>^ ArgAttrList);
static void Create_Parent(XmlDocument ^ArgDoc, XmlElement ^ArgChild,
LinkedList<String^>^ ArgList );
static void Insert_Sibling(XmlDocument ^ArgDoc, XmlNode ^ArgNode, XmlElement ^ArgChild);
static XmlNode^ Find_Candidate(XmlDocument ^ArgDoc, String ^ArgParent,
LinkedList<String^>^ ArgList );
static String^ ReformatListEntry(String ^ArgListEntry);
static void Add_Attribute(XmlDocument ^ArgDoc, XmlNode ^ArgNode,
CAttributeDefinition^ Arg_NewAttr);
static List<CAttributeDefinition^>^ AttributeList;
public:
static void SaveDocument();
static List<DB_PersonManager::CPersonMaster^>^ PersonList;
static String^ m_Filename;
[Flags] enum class m_FlagBits
{
PERSONID = 1,
SURNAME = 2,
FORENAME = 4,
IMAGE = 8,
};
static bool m_HasAttributes;
static List<DB_PersonManager::CPersonMaster^>^ Fetch_PersonMaster(int arg_call_type);
static void Delete_PersonMaster(int arg_Index);
static int Update_PersonMaster(CPersonMaster^ arg_PersonRow,
int arg_UpdateList, int arg_Index);
static int Insert_PersonMaster(CPersonMaster^ arg_PersonRow,
int arg_InsertFlags, int arg_Index);
};
}
DB_PersonManager.cpp
First we have two include statements:
#include "stdafx.h"
#include "DB_PersonManager.h"
These are followed by the function set:
Fetch_PersonMaster
Fetch_PersonMaster gets all the XML records.
Navigate
Navigate controls how the XML is traversed when retrieving the data.
Insert_PersonMaster
Insert_PersonMaster is called to manage the addition of data to the XML.
Update_PersonMaster
Update_PersonMaster is called to manage the updating of data already on the XML.
Delete_PersonMaster
Delete_PersonMaster looks after removing rows from the XML.
Process_Attribute
Process_Attribute extracts attribute data from XML notes.
Process_Node
Process_Node examines each node for data content.
Add_the_Person
Add_the_Person adds a fully extracted person row to the list for return to the calling module.
Create_Node
Create_Node creates the new node when adding data to the XML.
Create_Parent
Create_Parent creates a parent for the new node when it is found not to have one.
Insert_Sibling
Insert_Sibling decides where among a list of siblings to place the new node.
Find_Candidate
Find_Candidate searches through the list built by Insert_Sibling to determine the exact location for the new node.
ReformatListEntry
ReformatListEntry strips off the element number from a node list entry, if it is present.
SaveDocument
SaveDocument saves the XML document.
Update_Node
Update_Node updates the value of a node.
Delete_Node
Delete_Node removes a node.
Add_Attribute
Add_Attribute adds attributes to a node.
History
- 2011-08-16: V1.0 - Initial submission.

