Introduction
There are many articles explaining how to inject assembly code into a portable executable (host application). Most of them are very good. However, they seem to require you have high skills in assembly programming. Besides, most of the times, the injected code does nothing more than show a message box.
In this article that I want to demonstrate, you don't need to be an assembly expert to inject a complex routine in a host program. In fact, you need basic knowledge about certain concepts to understand the entire process. I'm going to show how to make C++ compiler create the assembly code you want to inject.
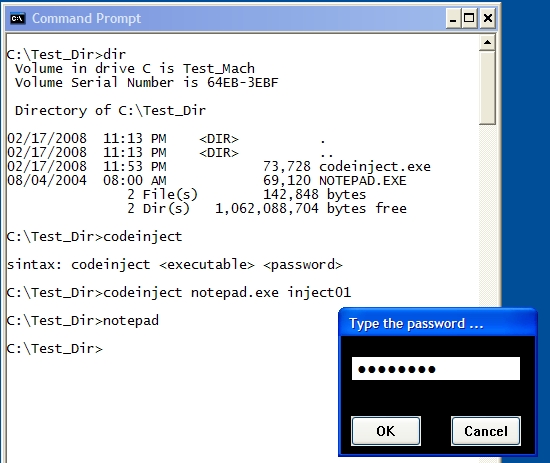
In the picture above, you can see what I'm going to demonstrate to you: codeinject.exe injects a password dialog routine into a portable executable (notepad.exe in that case). Thus, every time a user starts that executable, a password dialog will be popped up asking for the right password (inject01 in this case). If the user does not know the password, notepad.exe is not executed.
This article does not focus on P.E. structure deeply. It states some basic information about it. There is a lot of information you can find on the Internet related to portable executable structure.
The purpose of this article is purely educational. It might help you understand how virus corrupts files injecting malicious code. It also gives you better ideas about how a compiler generates assembly code. I will not be responsible for the bad usage of techniques you learn here.
Contents
- Let Us Start Testing codeinject.exe
- What Tools You Need to Understand this Article
- The Basic Steps
- Injection of Compiled Code - Prerequisites
- Creating the Code Injector Program
- Conclusion
1. Let Us Start Testing codeinject.exe
Before starting our tour over the "code injection world", let us see what the demo project can do. Download and unzip it. The application that performs code injection is named as codeinject.exe. It is a console application and is very simple to use. I packed a copy of notepad.exe and calc.exe for you to test with codeinject.exe. I advice that you always test on copies, never use it on the original files.
The first screen shot in this article shows how to use codeinject.exe. The syntax is quite simple:
codeinject <PE> <password>
<PE> - Portable Executable: An executable or DLL <password> - A case sensitive password limited with minimum 5 and maximum 10 characters
codeinject.exe fails if:
<PE> is not a valid Portable Executable <password> length is out of range - LoadLibrary and/or GetProcAddress system calls are not present in Import Directory of the executable. (No, this sample does not change the Import Directory. But don't get disappointed, most of Windows executables have LoadLibrary and GetProcAddress present in the Import Directory.)
If codeinject.exe succeeds, no message is printed.
Important Information
- codeinject.exe was not tested over DLL files.
- codeinject.exe was tested on Windows 2000 and Windows XP. No tests were performed on Windows Vista.
- There is no size limit imposed for a portable executable. I have tested over 13 MB executables. But, if codeinject.exe loads all executables to memory before injecting code then, there should be a limit.
2. What Tools You Need to Understand this Article
You might try to understand what I did by just reading this article and studying the source code. However, there are some steps you must understand to get there. So, you should download at least these two tools:
- Explorer Suite: A freeware suite of tools including a PE editor called CFF Explorer and a process viewer.
- IDA Pro: The most powerful disassembler ever. I wrote this article by using IDA Pro version 5.0.0. Previous versions of IDA Pro will work too but they can present different behavior.
We only use CFF Explorer from the Explorer Suite.
3. The Basic Steps
As I said, the purpose of this article is to demonstrate that we can build a C application and with some effort, we can inject the compiled code as a new section of any executable. The main advantage of using compiled code to inject is that we can build more complex routines - of course a good assembly programmer can do the same.
I do not intend to deeply explain Portable Executable structure so, only P.E. relevant information is mentioned through this article. If you want more detailed information about Portable Executable structure, you can Google it.
3.1 Step 1: Choosing a Compiler and Making the First Test
The very first thing is to choose a compiler and learn a little bit about how it generated the assembly code. In this article, the compiler used is C++ from Visual Studio 2005, but feel free to choose another one.
In this article, I will focus only on Release configurations. Debug configurations are not good to extract code to be injected because they add more complexity into the generated assembly.
Let us create the simplest C program:
- Open Visual Studio 2005 -> File - > New -> Project
- In New Project window, select project type as Win32 Console Application and Empty project in Application Settings (Figure 1):

Figure 1(a): Win32 Console Application
Figure 1(b): Empty Project
Let us suppose you named this application as test_app.
- Now, right-click on test_app and click Add->New Item. Select C++ File (*.cpp) template, give it any name.
- Type the most basic C program:
int main(int _argc, char *_argv[] )
{
return 0;
}
- Select Active Configuration as Release and build it.
Now open Release\test_app.exe with CFF Explorer and let us see what we got:
Figure 2(a): You see 4 sections were created. Sections keep assembly organized. A section might contain code or data (even both if necessary).
Figure 2(b): Only 3 lines of code produced an exec that call 38 functions from 2 DLLs!
Sections names indicate what they keep. In Figure 2:
.text keeps executable code (code section) .rdata keeps constant data .data keeps global data .rsrc keeps resource information
.rdata might be mixed with .idata that is the Import Section (where all system call references are kept).
Note: Borland compiler uses different names like CODE instead of .text for code section.
In Figure 2(b), we see the Import Directory information (.idata). The function calls you see are the necessary system calls to start a Windows application. You may be asking yourself: If those functions are there which part of the code is calling them !? There is only a main function!
Well, you may think main or WinMain are the entry points of your application, but the truth is that main (or WinMain) is called after a real entry point (named start routine or any other name. That depends.) has been executed. Every Windows application has a start routine.
And what does the start routine do? Things like verify if the executable is compatible with the current Windows version. You know, if you try to execute a WinCE executable on Windows XP, a message box saying "app is not a valid Win32 Application" is shown. Or "This program cannot be run in DOS mode" when you try to execute a Windowed application in a pure command prompt. That is what I know about that function.
You noticed import directory has references to 2 DLLs. KERNEL32.dll is referenced by every Windows application. Most of the basic Win32 system calls are exported by KERNEL32.dll. It is part of the Operating System core. There are other important operating system DLLs like USER32.dll or GDI32.dll.
How about MSVCR80.dll? That DLL is part of the .NET Framework. So, if you want test_app to run in other Windows machine, you should copy it too!
So, how can I get rid of MSVCR80.dll? I want a pure executable that depends upon the system DLL only. Just right-button click on test_app project and select Properties -> C++ -> Code Generation (see Figure 3).
Figure 3
By selecting Multi-threaded (/MT) you get rid of MSVCR80.dll. Rebuild test_app again and open a new version with CFF Explorer. You will see significant changes on the Import Directory of the executable:
Figure 4
You see? Now test_app is only dependent on a system DLL that you know is present in all Windows systems. Also notice GetProcAddress is selected and if you scroll down you will see LoadLibrary (probably named as LoadLibraryA - MultiByte character set version. If the application was build as UNICODE character set it would be named as LoadLibraryW).
What I mean is if you build test_app or any application having MSVCR80.dll as dependency and try to test codeinject.exe over it you will fail (see here).
3.2 Step 2: Learning a Little More
It is time to open source code and see what we have there. There are 4 projects in solution and I know codeinject project is the one that is really interesting to you. However, I still need to give you a little more information about Visual Studio 2005 C++ compiler before we proceed to code injection of compiled code. I advice you to read this topic because it has some details we must know to get success in the next application you will code.
Now we are focusing on the project named first. It is a simple project with useless code that serves only to analyze how the compiler builds assembly code. If you have still not download IDA Pro I recommend you do it because it is an essential tool if you want to understand the rest of this article.
Ok, open first.cpp, select Release as active configuration and build first project.
It is time to test IDA Pro features (It has hundreds of options and functions. I myself know about 5% of all its features!):
- Open IDA Pro File->Open and open first.exe in the Release directory.
- A dialog Load a new file is shown. Just click on Ok (Figure 5(a)) and wait till it terminates the analysis. When it finishes, you will hear a BEEP and read The initial autoanalysis has been finished in the status window (Figure 5(b)).
Figure 5(a)
Figure 5(b)
After IDA Pro finishes the analysis, a Disassembly view is shown. If it is not, then menu View->Open Subviews->Disassembly. Also, on Options->Compiler... check Visual C++ compiler and press Ok.
Recall that I said a P.E. has 2 entry points? Yes it does. But IDA Pro starts pointing to main/WinMain address (Figure 6).
Figure 6
Just to show you where the real entry point is, click menu View->Open Subviews->Exports and you will see the real entry point routine named, in this case, mainCRTStartup (it could be named start or $LN31. it does not matter.). Double click on it and the Disassembly view will show up again this time pointing to the mainCRTStartup code. You read a jmp (jump) instruction jmp __tmainCRTStartup (Figure 7(a)). Double click on it and scroll down until you see a call _main instruction (Figure 7(b)):
Figure 7(a)
Figure 7(b)
Double click on it and you go back straight to the main assembly code.
Note: The memory addresses (like 004015C8) depend upon things like compiler version or compiler settings. So if you compile this code using VC++ 6 that call _main address could be 0040124C. The addressing of instructions is also based upon two values of Optional Header in P.E.: AddressOfEntryPoint and ImageBase. I advice you to study P.E. structure to understand how that works. You also might check those values with CFF Explorer.
Let us take a look at the first.cpp source code to understand some interesting aspects of code compilation. There, some lines of code are commented but we are going to uncomment them in the next compilation.
Note: Line 10 reads #pragma warning(disable:4996). That pragma disables the annoying warning: warning C4996: 'strcpy' was declared deprecated.
There are 3 functions defined and notice func_B and func_C are enclosed by #pragma code_seg (Line 55). I used #pragma code_seg to create a new code section (or segment code) named .seg0 where the assembly code of those two functions will be generated. To check .seg0 contents click View->Open Subviews->Segments (Figure 8(a)) . Also open first.exe with CFF Explorer (Figure 8(b)):
Figure 8(a)
Figure 8(b)
You may have noticed IDA Pro shows a .idata section and no .rsrc section and CFF Explorer is the opposite. IDA Pro did not rename .rsrc to .idata. What it did was extract .idata (Import Directory) from .rdata. .rsrc keeps the resource information but first.exe has no resources. You don't have to worry about that because I do not.
Now on IDA Pro, double click on .seg0 line to show disassembly view (Figure 9):
Figure 9
In Figure 9, you see the code of func_B starting in 0040A000. The end of section .seg0 is 0040A019. Notice that call instruction is at 0040A011. It is calling the MessageBox API call that was mapped when USER32.dll was loaded: __imp__MessageBoxA@16 is the address of MessageBox API.
IDA Pro allows you debug the application. You might set breakpoints with F2, F9 to run, F7 does step into and F8 does step over.
You have already realized func_C assembly is not there. Where is the func_C code? It was not generated because func_C is not called in the entire program. That was the reason. It is commented on Line 38. Then, if you uncomment it and rebuild first again it will be generated. Try it.
To check it after rebuilding first.exe on IDA Pro, click on File->Close, a Save database dialog will be shown with some options. Check Don't pack database, Collect garbage and DON'T SAVE the database and click Ok.
File->Open first.exe again and go to .seg0 segment (or section). You will see func_C assembly generated. However, sometimes you want only the assembly of a function generated but you don't really want it executed. How to do that?! Write a fake-If, I mean an If instruction where the condition will never happen:
if ( _argc == - 1 )
func_C(l_var0);
That If works well.
Let us take a deep look at some pieces of main assembly code and make some comments about first.cpp:
Symbols like var_50 are symbolic representation IDA Pro offers for variables created within main function:
var_50 => char l_var0[64]; var_8 => int l_var1 = 0; var_4 => char *l_var2;
Where the hell is var_C from ? It is something that is used in Buffer Security Check. VC compiler uses it to add that extra assembly code. Later in this article, we will see that we must get rid of that because only inline code is allowed in a compiled routine we want to inject.
There are two important things here:
Double click where you read offset aAnotherSampleS. You see? You go straight to .rdata section (or segment). Although "another sample string (%ld)!\n" is a value in the main function and it is not kept as local data.
The same happens in Line 27 where strcpy moves "test string\n" to l_var0.
You should remember constant strings are stored in another section, never in .text section (code section). And if we use strings in the code we want to inject?
We will see how later in this article. For now, it is enough to mention that you must map and save all strings you want to use.
Another thing worth mentioning is the call memset:
memset, memcmp are called intrinsic functions because they are not contained in libraries (like MessageBox, CreateWindow, etc.) but built-into the compiler.
When you code a complex injectable function, you may use such intrinsic functions but you don't want a call to a code out of the scope of your injectable code. Do you? Otherwise you would have to find and move all code referenced by that call to the host program.
Here we see those 2 global variables (Line 16-17).
Double click on any of them and you go straight to .data section where global data is usually kept. When coding your injectable application, avoid using global variables.
So far, we analyzed first.exe assembly code without changing compiler settings. First project has disabled all optimizations. So, let us change it to maximize speed optimization (Figure 11):
Figure 11
Rebuild first.exe and reopen it with IDA Pro and you will see two dramatic changes:
.seg0 does not exist anymore func_B and func_C are inlined in main
Why did the compiler inline our functions and not built-in functions like memset? (it did inline strcpy!). Well, I don't know. What I know is I can prevent compiler from removing .seg0 with #pragma optimize (Line 53). Remove the comments from optimize directive (Lines 53 and 74) and rebuild first.exe again. Reload/reopen first.exe and you will see .seg0 again. By using #pragma optimize we turned off optimizations only for .seg0.
It would be a good thing if compiler inlines built-in functions because after all, we set maximize speed optimization right? Check a list of built-in functions reading about #pragma intrinsic. You will read functions like printf are not considered intrinsic then we will never get that inlined.
codeinject.exe does not inject code that uses printf or sprintf but it injected code that makes calls to memcmp and memcpy and I tried to use #pragma intrinsic to inline those functions. Unfortunately, that #pragma does not work the way I expected because the compiler still decides if it should inline a built-in function or not. So, I had to invent another way - you will see later. (Read more information about Compiler Intrinsics).
4. Injection of Compiled Code - Prerequisites
So far, we have seen a few basic interesting aspects how Visual Studio 2005 C++ compiler generates assembly code. We have always focused on Release configuration. Debug configuration is not interesting because it adds more complexity to assembly code. Of course, feel free to build all projects in workspace with Debug configuration to analyze assembly code.
There are two more projects to analyze before we move to codeinject. They are pwddlg and pwdcon. Those are intermediate steps until we get our codeinject working.
4.1 Step 1: Planning What You Want to Inject and Coding a sample Program
If you are sure what kind of code you plan to inject and what operation it will perform then, the first step is code a sample application that performs exactly what you want. For this article, this is what I planned:
"Inject the code of a popup dialog password as new section of an executable to be shown every time that executable is started. If user types incorrect password executable is not executed."
Ok, keeping that in mind I coded a simple application, pwddlg, that only shows a simple dialog, created dynamically. Select pwddlg project and open main.cpp. You will see the code is pretty simple. When you build pwddlg and execute, a simple window is shown (Figure 11):
Figure 11
Notice, password is hard coded as PASSWORD (Line 74) - not important, just used as reference because user will inform password he wants when using codeinject.exe. So, pwddlg application is our reference program. The assembly generated from it is what will be injected. The source code must be as simple as possible following some basic rules:
- Write the application using pure C. Not C++ (I mean, do not use classes).
- Don't use global variables.
- Try to use API calls to do everything.
- Avoid built-in compiler functions.
I have used built-in compiler functions like memset and you may asking yourself why I did not use ZeroMemory. Well, if you check its definition, you will find a memset for sure:
winbase.h
#define ZeroMemory RtlZeroMemory
winnt.h
#define RtlZeroMemory(Destination,Length) memset((Destination),0,(Length))
4.2 Step 2: Enumerating All Required Strings, Functions Names and DLL Names
Having written and tested the sample program, the next step is to enumerate all
strings, functions names and DLL names. We must do that because we have to move all that information together with assembly code. Recall what I said about
constant strings, even they are within the function body that are not part of function local data. Linker uses to address them in a different section (
.rdata), not in the code section.
pwddlg has the following constant strings:
| String | Line |
| "@PWDWIN@" | 19, 23 |
| " Type the password ..." | 24 |
| "BUTTON" | 33, 34 |
| "OK" | 33 |
| "Cancel" | 34 |
| "EDIT" | 35 |
| "Sorry! Wrong password." | 76 |
| "Password" | 76 |
Also, we must enumerate API function calls and DLLs where they are called. We need this because the code injected must load DLLs and address the required API calls. Code injected will use LoadLibrary and GetProcAddress, both of them work with strings arguments. You will notice some names finished with A meaning ANSI version of the function. That happens because an application can use Multibyte or Unicode character set and functions that have string arguments are kept in both versions - If I had used UNICODE functions, they would end with letter W (meaning wide char version):
| DLL | API function names |
| USER32.dll | RegisterClassExA |
CreateWindowExA |
SetWindowTextA |
ShowWindow |
UpdateWindow |
SetFocus |
GetMessageA |
TranslateMessage |
DispatchMessageA |
GetWindowTextA |
MessageBoxA |
PostQuitMessage |
DefWindowProcA |
GetSystemMetrics |
GetDlgItem |
DestroyWindow |
| KERNEL32.dll | ExitProcess |
Don't worry about functions like strcpy, memcmp, strlen and so on for now. There are no DLLs where they are kept then, I had to figure another way and that will be shown later in the next topic.
The following picture shows roughly an executable mapped in RAM memory having a new injected section (.x123y):
Figure 12
You should keep in mind that the new injected section will contain the pwddlg assembly plus all required data to make it work. And pwddlg uses two functions:
- The code in the
main function that will be the new entry-point function in the host program (named from now on as NewEntryPoint). - The code in
PwdWindow, a callback function also injected into the host program.
Then, when you load the executable with injected code, the first thing to be executed is code in NewEntryPoint address ( which is in .x123y). However, NewEntryPoint must know:
- The address of
string constants in .x123y - The address of
PwdWindow in .x123y - The address of LoadLibrary and GetProcAddress in Import Directory of host application. Thus, it can load and map the addresses of all API calls it needs.
You already know everything NewEntryPoint needs will be in .x123y itself but NewEntryPoint must find them by itself. You see in Figure 12 the start and end addresses of .x123y section are unknown because they will be different to every host application.
Remember, the new code was not linked to the host application, it was injected. Then, no data was really addressed. NewEntryPoint is responsible for addressing that data and it must be the very first thing it does.
Figure 13 show a more detailed view of how section .x123y will appear in memory.
Figure 13
DATA_EP is NewEntryPoint's data area where all data NewEntryPoint and PwdWindow need is. NewEntryPoint is the assembly code of NewEntryPoint function. DATA_PW is PwdWindow's data area: It is a small data area which contains the address of DATA_EP. PwdWindow is the assembly code of PwdWindow callback function.
Everything is put together in the same section (.x123y). codeinject.exe creates a section similar to Figure 13.
On Memory column the beginning of .x123y is addressed by X. That X is the address NewEntryPoint must find out. By knowing X, NewEntryPoint can find anything else and create conditions to how PwdWindow runs.
4.3 Step 3: Creating a Template Program Based on Sample Program
The last step before coding the injector itself is to create a template program based on a sample program. pwdcon is the template program. The main advantage of a template program is that you can debug what injected code will do and guarantee it will work. I mean, it is not easy to debug injected code because you would need to understand assembly pretty well. And the purpose of this article is to show that you do not need to be an assembly expert to create a good code injector.
Also, you can easily copy and paste what you did in template program to your injector program (codeinject.exe) with some minor changes. Thus, if you read and understand this topic it will be easier to you understand the codeinject project.
When you open pwdcon.cpp you will find code a little bit unusual. The code is organized by using #pragma region (works like #region in C#). Build it and see it works just like pwddlg.
pwdcon.cpp is divided in 5 regions. Let us start with MISC_OPERATIONS.
Note: I cannot refer to line numbers because that depends upon whether regions are collapsed or expanded.
Look at the main function. The first function called is fill_data_areas that creates the data areas that will be injected together with assembly code, see Figure 13:
DATA_EP is represented by vg_data_ep_data (see region DATA_AREAS_DEFINITION). DATE_PW is represented by vg_data_pw_data (see region DATA_AREAS_DEFINITION).
The argument TEST01 is a password used for test purposes. codeinject receives that password via command line.
Notice I dimensioned vg_data_ep_data to 1024 bytes (_MAX_SECTION_DATA_SIZE_), a size big enough to keep all data required by NewEntryPoint and PwdWindow:
#define _OFFSET_STRINGS 32
#define _OFFSET_DLL_NAMES 200
#define _OFFSET_FUNCTION_NAMES 250
#define _OFFSET_FUNCTION_ADDR 600
#define _MAX_SECTION_DATA_SIZE_ 1024
#define _MAX_SECTION_SIZE 4096
#define _GAP_FUNCTION_NAMES 5
#define _MAX_SEC_SECTION_DATA_SIZE_ 16
BYTE vg_data_ep_data[_MAX_SECTION_DATA_SIZE_];
BYTE vg_data_pw_data[_MAX_SEC_SECTION_DATA_SIZE_];
Yes, PwdWindow uses the same data area. That is the reason why vg_data_pw_data is only dimensioned to 16 bytes. In fact, DATA_PW saves only the address of DATA_EP. That is the best way to do: keep all data used for NewEntryPoint and PwdWindow in only one piece of memory.
Those #defines indicate the offset of data in DATA_EP (vg_data_ep_data).
For instance, constant strings start 32 bytes from the beginning of the data area (#define _OFFSET_STRINGS 32).
The code in fill_data_areas saves some data in vg_data_ep_data, including the strings used, API call names and DLL names. Take a look in the region named REQUIRED_STRINGS. There are two arrays of strings, one for constant strings (vg_string_list) and another for API names (vg_imports).
A question arises when you read the code of fill_data_areas: What are those "<E>"? Well, they are that comments say: end marks of data area. You will understand it in the next section.
fill_data_areas code is present in codeinject project with some changes (some things can be done only in the final application).
The next function is NewEntryPoint itself. It is placed in CODE_THAT_WILL_BE_INJECTED region. It deserves special attention because it will be injected in the host program and it prepares all environment so the rest of injected code runs properly. Keep in mind NewEntryPoint is executed in pwdcon only to simulate what happens in the host application. NewEntryPoint and PwdWindow represents the code to be injected.
Like fill_data_areas it is present in codeinject with some changes in the code. The code is divided in steps. Most parts of code should be explained now:
- In code commented as STEP 01, the variable
dwCurrentAddr will save the address in memory of the instruction being currently executed. Of course not in this code but in codeinject project. And when injected code is running dwCurrentAddr after it receives the memory address, it is used to determine the address of DATE_EP. - In code commented as STEP 02 you read:
_MEMCPY_( (void *)dwPwdWindowDS, &dwDataSection, sizeof(DWORD) );
That _MEMCPY_ is the way I found to solve inline problem when using built-in functions. I mean, I created my own versions. Take a look at the region named CUSTOM_INLINE_FUNCTIONS. Thus, I guarantee the assembly code of the function that will be injected have no calls to code outside of NewEntryPoint.
- In code commented as STEP 03 you see
NewEntryPoint mapping some information pre-saved by fill_data_areas. - In code commented as STEP 04,
NewEntryPoint loads and addresses all API calls using the names pre-saved by fill_data_areas. Notice, it saves the addresses in DATE_EP itself to be used later ( _OFFSET_FUNCTION_ADDR offset).
Take a look at the region named REQUIRED_IMPORTS. There are function types for all required API calls. - In code commented as STEP 05,
NewEntryPoint creates the references for all API calls it needs by using addresses it saves in STEP 04.
The rest of the code is the creation of a dialog window just like pwddlg. But this time only functions pointers are used - those mapped in STEP 04.
Last but not least, we have the PwdWindow function. The first step is finding the address of DATA_EP which is saved in the first 4 bytes of DATE_PW. PwdWindow uses functions pointers mapped earlier by NewEntryPoint.
Note: Again, it is important you understand that NewEntryPoint and PwdWindow will never be executed when running codeinject.exe. They are the code to be injected and will be executed only when the host application is run.
5. Creating the Code Injector Program
This is the last part of this article. So far, I tried to expose some concepts I think were necessary before explaining anything about the codeinject project. Now, it is time to put it all together and see how it works. Let us start with the source tree:
Figure 14
I have organized some source code in extra folders (or filters):
- Code to Inject contains code that will not be executed but injected.
- Tool Classes contains PEToolHelp. It is a simple helper class to deal with the P.E. structure. I will not explain it. If you want to understand what
PEToolHelp does, please Google information about P.E structure.
5.1 Understanding Execution Flow of Codeinject
Recall codeinject.exe syntax which receives two arguments: a portable executable path and a case sensitive password. Open codeinject.cpp and see the main function. Notice I have used #pragma region in codeinject.cpp. I cannot refer to line numbers because that depends on whether regions are collapsed or expanded.
In code commented as *** Loads PE file we see how to use the instance of PEToolHelp. It is passed to LoadFile member function the host P.E. path and if everything goes fine no error is returned. PEToolHelp loads all files in memory. There is no size checking so may be a very big P.E. can abort codeinject.exe.
If the loading process is Ok, the next step is to verify if LoadLibrary and GetProcAddress are present in Import Directory of host program. That is a prerequisite to the codeinject.exe working (check syntax). As I said, if you want codeinject.exe working in all situations you must handle that. I mean, code yourself a routine to change Import Directory of host program adding references to those API functions calls if they are not present.
Next, fill_data_areas is called. In codeinject it receives one more argument which is the PEToolHelp instance. It fills the same two global variables you see in pwdcon that represent data areas (Figure 13): vg_data_ep_data (DATA_EP) and vg_data_pw_data (DATA_PW). There are some differences between fill_data_areas in pwdcon and this one. However, only one difference deserves explanation:
dwEPSize = (DWORD)NewEntryPoint_End - (DWORD)NewEntryPoint;
(void) memcpy( &vg_data_ep_data[12], &dwEPSize, sizeof(DWORD) );
You know NewEntryPoint is executed only in the host program and it needs some required data to work. In some point of its execution it needs to know what its size in bytes is (!). Yes, with that information it can calculate the offsets of DATE_PW and PwdWindow in .x123y section. So, that information needs to be saved in DATA_EP before code is injected. Well, how can codeinject know the size of assembly, in bytes, of NewEntryPoint ?
To understand that, open extra_code.cpp. That source contains only the code to be injected. You see all code is placed in a new code segment (or section code) named .extcd (Line 13). I wanted to isolate that code from the rest. If you open codeinject.exe in demo project with CFF Explorer, you can see .extcd section (Figure 15):
Figure 15
There are 4 functions: NewEntryPoint (Line 15), NewEntryPoint_End (Line 226), PWdWindow (Line 231) and PwdWindow_End (Line 325).
NewEntryPoint_End is end mark of NewEntryPoint as PwdWindow_End is end mark of PwdWindow. Those functions will not be injected, they are used only to calculate size in bytes of assembly code. Thus, dwEPSize = (DWORD)NewEntryPoint_End - (DWORD)NewEntryPoint; is supposed to return the size of NewEntryPoint to dwEPSize.
You have already realized that NewEntryPoint_End must be in a higher address in memory than NewEntryPoint otherwise dwEPSize would have a wrong value. Right? Also, NewEntryPoint_End must be the first compiled function after NewEntryPoint as PwdWindow_End must be the first compiled function after PwdWindow. Ok, open codeinject.exe with IDA Pro then click on View->Open subviews -> Segments, double click on .extcd.
Scroll down the view and you will see the assembly of NewEntryPoint_End straight below NewEntryPoint assembly (Figure 16(a)) and PwdWindow_End below PwdWindow (Figure 16(b)):
Figure 16(a)
Figure 16(b)
It is important you understand I had to do many tests to get all 4 functions in .extcd assembled and addressed correctly. I have tested many compiler settings plus some source code tricks to get the final result. We will see which compiler settings are used in the next topic.
Back to execution flow, after fill_data_areas has been performed, all data required that will be used by injected code is supposed to be in vg_data_ep_data (DATE_EP) . Next lines are interesting:
(void) memset( vg_new_section, 0x00, sizeof(vg_new_section) );
iOffSet = 0;
(void) memcpy( &vg_new_section[iOffSet], vg_data_ep_data, sizeof(vg_data_ep_data) );
iOffSet += sizeof(vg_data_ep_data);
(void) memcpy( &vg_new_section[iOffSet], (BYTE *)NewEntryPoint,
(DWORD)NewEntryPoint_End - (DWORD)NewEntryPoint );
iOffSet += ((DWORD)NewEntryPoint_End - (DWORD)NewEntryPoint);
(void) memcpy( &vg_new_section[iOffSet], vg_data_pw_data, sizeof(vg_data_pw_data) );
iOffSet += sizeof(vg_data_pw_data);
(void) memcpy( &vg_new_section[iOffSet], (BYTE *)PwdWindow,
(DWORD)PwdWindow_End - (DWORD)PwdWindow );
pe->AddCodeSection( ".x123y", vg_new_section,
_MAX_SECTION_SIZE, _MAX_SECTION_DATA_SIZE_ );
pe->SaveFile(argv[1]);
The new section .x123y is created in those lines. I defined a max size of 4 KB for .x123y represented by vg_new_section variable.
First vg_data_ep_data (DATA_EP) is added followed by NewEntryPoint assembly code, vg_data_pw_data (DATA_PW) and, finally, PwdWindow assembly code. See Figure 13.
AddCodeSection is a PEToolHelp member function responsible for adding and aligning .x123y section. And last but not least, P.E. is saved again now having password dialog code injected.
5.2 Compiler Settings and Source Code Tricks
As I said in the previous topic, there is a combination of source code tricks and compiler settings that guarantee injected code is correctly built. Some of them are enumerated below:
Compiler Setting # 1
Explanation
Multi-byte (ANSI) character set is easier to handle. Functions like strlen are easier to implement than wcslen.
Compiler Setting # 2
Explanation
Maximize Speed is necessary to keep NewEntryPoint_End and PwdWindow_End (end-mark functions) addressed correctly. If you try to disable Optimization those end-mark functions might be addressed in smaller memory addresses. For instance, NewEntryPoint_End might be addressed before NewEntryPoint.
Compiler Setting # 3
Explanation
We must get rid of Buffer Security Check by disabling it. When this option is enabled compiler adds extra code in assembly code, see below:
In fact, Buffer Security Check is an attempt to avoid buffer overrun. However, we do not need this in our assembly code.
Source Code Trick # 1
int __stdcall NewEntryPoint_End();
LRESULT __stdcall PwdWindow_End(char *_not_used);
Explanation
You already know NewEntryPoint_End and PwdWindow_End works only as end-marks and they are not injected. So, it does not matter what the prototype is, right?
Wrong! Believe it or not, they must have different prototypes otherwise the compiler will assume only one of them. I really don't know why.
Source Code Trick # 2
__forceinline void _MEMSET_( void *_dst, int _val, size_t _sz )
{
while ( _sz ) ((BYTE *)_dst)[--_sz] = _val;
}
__forceinline void _MEMCPY_( void *_dst, void *_src, size_t _sz )
{
while ( _sz-- ) ((BYTE *)_dst)[_sz] = ((BYTE *)_src)[_sz];
}
Explanation
Recall built-in compiler functions. We must be sure those functions are inlined. However, no compiler settings can guarantee that.
The solution is to implement user functions that do the same.
__forceinline keyword relies on the judgment of the programmer and puts all those functions inlined.
5.3 How Injected Code (NewEntryPoint) Works
This is the last part and I'm going to explain how injected code runs in the context of host program. If you read topic 4.3 you saw I have explained most parts of NewEntryPoint (in pwdcon project) but some points are still obscure.
Open extra_code.cpp and you will see the very first thing NewEntryPoint performs is find where address of DATA_EP (Figure 13) is. Recall I said NewEntryPoint does not know which address it is running and where data it needs is into .x123y section? It must find the required data and address it before running the rest of the code.
The only way I found to do that (find that X address) is what you see in code commented as STEP 01 (Line 21). The first piece of code is an ASM block:
__asm{
call lbl_ref1
lbl_ref1:
pop dwCurrentAddr
}
That code is the only piece of assembly code I have used in this article. And it is pretty simple. What it does is save the execution address memory pointed by register EIP into variable dwCurrentAddr.
By having an address of memory as base, the next code finds the address of DATA_EP:
while ( dwMagic != 0x3E453C00 )
dwMagic = (DWORD)(*(DWORD *)(--dwCurrentAddr));
dwDataSection = dwCurrentAddr - (_MAX_SECTION_DATA_SIZE_ - 4);
That while instruction decrements address in dwCurrentAddr to find a DWORD value equal to 0x3E453C00.
What does 0x3E453C00 mean ? If you translate byte per byte to ASCII representation you will have "<E>"! Now you know what the meaning of that string is (see topic 4.3).
When the while ends, current memory address is the end of DATA_EP.
By knowing the end of DATA_EP address and knowing its size in bytes, finding the start address of it is a simple calculation (Line 38).
Then, dwSectionData saves the address of DATA_EP (that X address in Figure 13).
On Line 44 the address of DATA_EP is saved into DATA_PW to be used by PwdWindow. Recall fill_data_areas saved size of NewEntryPoint into DATA_EP[12] (offset 12). See code of fill_data_areas in codeinject.cpp. So, NewEntryPoint can easily calculate address of DATA_PW:
DATA_PW address = address of DATA_PE + size in bytes of DATA_PE + size in bytes NewEntryPoint.
Ok, there is nothing more to say about NewEntryPoint. The rest of the code was commented in topic 4.3. Let us move to PwdWindow code (Line 231).
The code commented as STEP 01 is equivalent to NewEntryPoint. However, it is the address of DATA_PW that code tries to find:
__asm{
call lbl_ref1
lbl_ref1:
pop dwCurrentAddr
}
while ( dwMagic != 0x3E453C00 )
dwMagic = (DWORD)(*(DWORD *)(--dwCurrentAddr));
dwSecDataSection = dwCurrentAddr - (_MAX_SEC_SECTION_DATA_SIZE_ - 4);
dwDataSection = (*((DWORD *)dwSecDataSection));
dwSecDataSection saves the address of DATA_PW. The first 4 bytes of DATA_PW contains the address of DATA_EP (see NewEntryPoint Line 44).
By having DATA_EP address, PwdWindow can map all API function calls it needs.
Note: PwdWindow is a callback function. It is a window procedure function and it is called many times while password dialog is opened to process Windows GUI messages. Then, it performs STEP 01, 02 and 03 every time it is called.
6. Conclusion
I hope you have enjoyed reading this article. There are many ways to inject code in a portable executable and I have stated more than one way. I don't know if it is the best way but I believe it is more practical and easy than writing big routines in assembly.
Once more, do not use what you learned here to code evil applications.
Hope this helps.
History
- 10 March, 2008: First version

