Introduction
Xport, XHTML parsing & objective reporting toolkit, is a C++ template class library, which can be included in any C++ project, to enable the creation and generation of xhtml documents. Although Xport was developed with the idea of creating xhtml documents for reporting purposes, Xport can be used to create xhtml documents for many other uses as well.
Xport also provides xhtml and stylesheet parsing capabilities. Xport can parse practically any xhtml document, and HTML documents that are not overly mal-formed.
Xport provides the capability of generating and parsing documents of various document types. Three document type classes are provided with Xport, xhtml strict 1.0, xhtml transitional 1.0, and xhtml frameset 1.0. Xport's flexible design also allows for the easy inclusion of additional document types. Which ever document type you use with Xport, Xport enforces the rules of that particular document type.
Xport also provides the capability of working with standard character types, or wide character types to support unicode.
Multiple types of iterators are available in Xport to provide STL like capabilities when working with documents, elements, and stylesheets. These iterators are compatible with STL containers and algorithms. A descendant iterator is also provided to allow the traversal of the document tree, or subtree within a document. Using STL's algorithms, any distinguishable element in the document tree can be found quickly and easily.
Xport contains a well designed class hierarchy, and a rich well documented interface. Key classes are appropriately named to convey their purpose. Type names including document, element, markup, comment, stylesheet, and stylesheet_rule, make using the classes intuitive. Although Xport is made up entirely of class templates, there is no need to use template syntax when using Xport, as type aliases are provided for all the various class templates and document types. Many of the the operations in the key classes in Xport reflect those operations found in STL container, providing a intuitive and friendly interface.
The documentation availaible from the link above details every operation in every class, and also gives an example for every public operation of all classes in Xport.
Using the code
Although Xport consists entirely of class templates, you need know nothing of templates to use Xport and all it's features. Type aliases are provided in Xport to allow it's use without working directly with the template classes. For example, the following code snippet creates and saves a basic xhtml strict document.
using namespace Xport;
document doc(root_doc);
markup::iterator it = doc.body()->insert(element(p));
it->insert("This is the first paragraph of the document");
*doc.body() << (element(p)
<< "This is the second paragraph of the document");
doc.write("c:/myDoc.htm");
Creating stylesheets is just as easy with Xport with Xport's stylesheet classes. The example below illustrates creating a simple xhtml document with a linked stylesheet.
#include "xhtml_doc.h"
using namespace Xport;
document doc(root_doc);
*doc.title() << "Sample xhtml document";
*doc.body() << (element(h1)
<< "This is a sample xhtml document!");
markup::iterator it = doc.body()->insert(element(p));
*it << "This document was created by Xport, "
<< "to demonstrate it's xhtml generation features. "
<< "pcdata can be inserted into elements all at once, "
<< "or seperately. The push_back() operation behaves "
<< "similar to the insert() operation when insert() "
<< "is supplied a single argument. When supplied a "
<< "single argument (the pcdata to insert), "
<< "the insert() operation inserts the object/pcdata "
<< "at the end of the called element. "
<< "But when supplied with an additional argument, "
<< "a child iterator, the child iterator "
<< "specifies where the object/pcdata will be inserted.";
it = doc.body()->push_back(element(ul));
*it << (element(li, "li1") << "List item 1");
*it << (element(li, "", "red") << "List item 2");
*it << (element(li, "", "red") << "List item 3");
stylesheet ss;
stylesheet::iterator sit = ss.insert(stylesheet_rule("h1"));
*sit << declaration(css::color, "red")
<< declaration(text_align, "center");
sit = ss.insert(stylesheet_rule("p"));
*sit << declaration(margin_left, "30px")
<< declaration(padding, "10px")
<< declaration(css::width, "400px")
<< declaration(css::border, "thin groove blue");
sit = ss.insert(stylesheet_rule("ul"));
*sit << declaration(padding_left, "20px");
sit = ss.insert(stylesheet_rule("#li1"));
*sit << declaration(css::color, "green");
sit = ss.insert(stylesheet_rule("li.red"));
*sit << declaration(css::color, "red");
it = doc.head()->insert(element(Xport::link));
it->attribute(rel, "stylesheet");
it->attribute(type, "text/css");
it->attribute(href, "test_doc.css");
formatter fmtr("c:/test_doc.htm");
fmtr.option(max_line_length, 80);
doc.write(fmtr);
ss.write("c:/test_doc.css");
The following classes form Xport's interface
xhtml classes
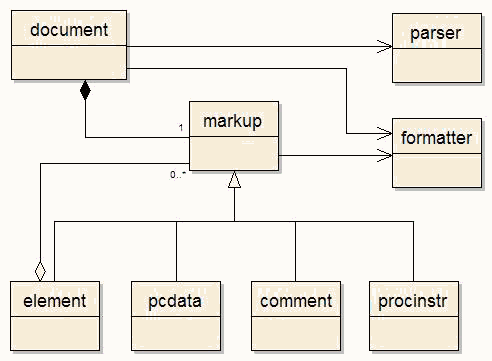
Xport's xhtml classes support the functionality of creating and parsing xhtml documents. As mentioned above, Xport consists entirely of class templates, but type aliases are declared for all the interface classes for user convenience. The xhtml template classes are paramatized on two types, the document type and the character type. The list below reveals all Xports xhtml interface class templates, and the type aliases available for those classes.
| class template | type alias |
|---|
xhtml
strict | wchar xhtml
strict | xhtml
transitional | wchar
xhtml transitional | xhtml
frameset | wchar xhtml
frameset |
|---|
| xhtml_doc | document | wdocument | tdocument | wtdocument | fdocument | wfdocument |
|---|
| xhtml_markup | markup | wmarkup | tmarkup | wtmarkup | fmarkup | wfmarkup |
|---|
| xhtml_element | element | welement | telement | wtelement | felement | wfelement |
|---|
| xhtml_pcdata | pcdata | wpcdata | tpcdata | wtpcdata | fpcdata | wfpcdata |
|---|
| xhtml_comment | comment | wcomment | tcomment | wtcomment | fcomment | wfcomment |
|---|
| xhtml_processing_instruction | procinstr | wprocinstr | tprocinstr | wtprocinstr | fprocinstr | wfprocinstr |
|---|
| xhtml_formatter | formatter | wformatter | tformatter | wtformatter | fformatter | wfformatter |
|---|
| xhtml_parser | parser | wparser | tparser | wtparser | fparser | wfparser |
|---|
Table 1: Xport's xhtml class templates and type aliases
Xport's default document type is xhtml strict, which is colored blue in the table above. Most of the example reports will reflect this document type. Thus, users of the library will normally use only the type aliases in blue above to create documents.
A brief description of Xport's xhtml types is given below. The default type alias names will be used to describe the different xhtml types available.
document
In Xport, the document type encapsulates an xhtml document. The document object is one of the most important objects you'll utilize. The document object organizes it's content in a tree structure, or document tree. A standard xhtml document normally contains the elements html, head, title, and body elements. These elements are known in Xport as the root elements and a document which contain these root elements is considered a root document. When you create a document object, you can optionally create it as a root document, with those root elements included. Those root elements, and all other elements contained within, form the document tree. Once content has been added to the document , the document can be written to a file or stream. document objects can also parse xhtml files, as well as html files. The results of parsing html files will vary, depending on the form of the html file.
markup
markup is the base type for element, comment, and procinstr. markup is used mainly with the use of Xport's markup iterators, which are discussed further below. All markup iterators return references and pointers to markup objects, which are actually objects derived from markup. So, the interface of markup is very important indeed, as it is only through markup 's interface that we're able to access those objects derived from markup, when working with markup iterators.
element
Xport's element type encapsulates an xhtml element. element objects are used more frequently than any other object type when creating content for the document. An element object is the only markup object which can contain other markup objects, giving element objects the responsibility of making up the document tree. There are a number of ways to add and insert other markup objects into element objects, which are all detailed in the documentation and examples. Xport will only allow elements to be inserted in other elements which do not violate the document type specifications for the document type used. For instance, Xport will not allow a p element to be inserted in another p element, because that would be an xhtml violation for all document types. Each document type has specific rules, or document type definitions, which is enforced by Xport.
The element accepts three arguments in it's constructor. The first argument is required, and specifies the tag name of the element to create. In Xport, tag names are enumerated for convenience. The second optional argument specifies the id attribute for the element, and the optional third argument specifies the class attribute for the element.
An element can also be assigned attributes, which are also enumerated for convenience. The document type definitions specify which attributes can be assigned to which elements, and Xport also enforces these rules. Xport also provides an easy way to assign styles to particular elements through style attributes, but since stylesheets are supported in Xport, the use of stylesheets is encouraged over the use of style attributes.
pcdata
Xport's pcdata type encapsulates PCDATA (parsable character data) in an xhtml docuement. pcdata objects are mostly used implicitly in Xport. Whenever text is inserted into an element, Xport places the text in a pcdata object. When an element contains PCDATA, the element will contain one or more pcdata objects, which include the PCDATA. The number of pcdata objects which comprise the PCDATA within an element depends on how the PCDATA was inserted into the element.
Regardless of whether elements are represented as an element object, or as part of a pcdata object, when an (x)html document is parsed by Xport, the parser will always parse elements, including inline elements, as element objects rather than include them in pcdata objects. This means that if a paragraph element, for example, would contain content which includes inline elements and PCDATA, the paragraph element will be parsed into multiple separate pcdata objects and element objects.
comment
Xport's comment is a very simple type, which encapsulates an xhtml comment. Comments are not a necessary item in xhtml, but they can be useful to document the xhtml source. Like elements, comments are also derived from markup, and are also considered markup objects.
procinstr
Xport's procinstr encapsulates an xhtml processing instruction. There are many forms of processing instructions in xhtml, but all are delimeted by <? and ?> . One of the more popular types of processing instructions are PHP processing instructions. procinstr is also derived from markup and is also considered a markup object.
formatter
Xport's formatter is used to format the output of documents, whether to a file or to a stream. A formatter object provides detailed control of the xhtml output. With the formatter, you can specify the layout style of any element in the document. You can also specify the maximum line length, and the way entities are presented in the document. Indeed, with Xport's parser along with Xport's formatter, you may use the toolkit to simply reformat current xhtml documents to your liking.
parser
Xport's parser allows the parsing of xhtml and html documents. If the xhtml is properly formed, the parser object will parse the document with no problems. If the document is mal-formed, the parser object will do it's best to parse the document with it's errors. The parser object will parse the file or stream into an Xport document object. No matter how mal-formed the document being parsed, the resulting document object will always be well formed, because Xport does not allow for invalid xhtml. The parser object also allows users to specify options on how documents are parsed, giving users control over such things as newline preservation, entity transformations, and byte order mark preservation. A log can optionally be generated by the parser object on it's progress.
stylesheet classes

Xport's stylesheet functionality is implemented in another set of template classes, which are parametized only by the character type. As with the xhtml template classes, there are type alias declared for the stylesheet template classes to make them easier to work with. The table below illustrates the stylesheet template classes, and their type aliases.
| class template | type alias |
|---|
| narrow character | wide character |
|---|
| xhtml_stylesheet | stylesheet | wstylesheet |
|---|
| xhtml_stylesheet_rule | stylesheet_rule | wstylesheet_rule |
|---|
| xhtml_stylesheet_import | stylesheet_import | wstylesheet_import |
|---|
| xhtml_stylesheet_comment | stylesheet_comment | wstylesheet_comment |
|---|
| stylesheet_declaration | declaration | wdeclaration |
|---|
Table 2: Xport's stylesheet class templates and type aliases
Xport's default character type for stylesheet type aliases is the standard narrow character type. Using standard narrow characters, library users will use only those type aliases in blue, displayed in the table to the left. Xport's stylesheet object encapsulates a cascading style sheet. The stylesheet object can easily be written to a file, or embedded in a document. Xport's stylesheet object can also parse existing stylesheets, from a file or from a stream.
A brief description of Xport's stylesheet types is given below. The default type alias names will be used to describe the different stylesheet types available.
stylesheet
Xport's stylesheet encapsulates an cascading style sheet. stylesheet's interface is small, but very important. It's three operations, add_item(), write(), and parse() give stylesheet it's main functionality. There are three types of objects which can be added to a stylesheet object, a stylesheet_rule, stylesheet_comment, and stylesheet_import. This makes the stylesheet object simpler than the document object. Most of the work for adding a stylesheet to a document involves the stylesheet_rule detailed further below.
stylesheet_rule
Xport's stylesheet_rule encapsulates a CSS rule. When creating stylesheets in Xport, stylesheet_rule objects are used more than any other stylesheet types. Since a stylesheet rule always contains a selector which specifies the parts of the document to which the rule applies, the stylesheet_rule takes a mandatory string argument in it's constructor, which specifies the selector for the rule. After creating a stylesheet_rule object, declarations are added to it with the add_declaration() operation. This is the primary operation in stylesheet_rule and there are two forms of it. The first form accepts a declaration object, which is described below. The second form of the operation accepts two arguments. The first argument specifies the css property, and the second argument specifies that properties value. The css property names are enumerated for convenience. The properties value is specified as a string argument.
stylesheet_import
Xport's stylesheet_import has one basic purpose, to allow the import of another stylesheet into the current stylesheet.
stylesheet_comment
Xport's stylesheet_comment encapsulates a stylesheet comment. This type allows users to add comments to stylesheets.
declaration
Xport's declaration encapsulates a CSS declaration. Once a declaration object is created, it can be added to a stylesheet_rule. The declaration expects two mandatory arguments in it's constructor. The first argument specifies the css property, and the second argument specifies that properties value.
iterator classes
Xport's iterator functionality is available for both xhtml markup and stylesheets. There are two types of iterators available for markup, child markup iterators and descendant markup iterators. As the names imply, child iterators traverse over the immediate children of an element or document, whereas descendant iterators traverse over all descendants of an element or the document.
A brief description of Xport's iterator types is given below.
markup::iterator and markup::const_iterator
Xport's child markup iterators, iterator and const_iterator are very useful for both creating and parsing xhtml documents. Not only do these iterators allow the traversal of child markup objects, but they can also be used to insert, add, and erase child markup objects. The iterator in particular, is so useful, that an iterator is returned from an elements insert() operation. The returned iterator in turn can be used to insert additional markup in the element to which the iterator points. Users are encouraged to make heavy use of iterators when generating content in a document.
markup::descendant_iterator and markup::const_descendant_iterator
Xport's descendant markup iterators, descendant_iterator and const_descendant_iterator are used when it's necessary to traverse descendants of a document or particular element in the document. These iterators traverse in a pre-order fashion. A descendant iterator of a document object can traverse every markup object in the whole document, which can be very handy. Like iterators, descendant iterators can also be used for inserting, adding, and erasing markup in the document.
stylesheet::iterator and stylesheet::const_iterator
Xport's stylesheet iterators, iterator and const_iterator are very useful for both creating and parsing stylesheets. Not only do these iterators allow the traversal of stylesheet items, but they can also be used to insert, add, and erase stylesheet items, which include stylesheet rules, import rules, and comments. The iterator in particular, is so useful, that an iterator is returned from a stylesheet insert() operation. When a stylesheet rule is inserted, the returned iterator in turn can be used to insert declarations in the stylesheet_rule to which the iterator points. Users are encouraged to make heavy use of iterators when generating stylesheet items in a stylesheet.
stylesheet_item::iterator and stylesheet_item::const_iterator
Xport's stylesheet rule iterators, iterator and const_iterator are very useful for both creating and parsing stylesheet rules. Although these iterators traverse declarations which are embedded in stylesheet_rule objects, this iterator is declared and defined in stylesheet_rule's base class, stylesheet_item.
History
Version 1.6.1
Introduced to CodeProject
Version 1.6.5
Fixed compiler error caused by name conflice with windows define for "small".
Added operator < operation to stylesheet_iterator and stylesheet_rule_iterator.
Misc minor bug fixes.
Version 1.6.7
Fixed bug in document::insert(stylesheet);
Fixed const issue in stylesheet_rule_iterator.
Removed unused clear_all enumeration.
VC6 compatibility changes.
For more information on Xport, and a complete version history, visit Xport's Home Page

