Table of Contents
- Introduction
- How it Works
- Adding Balanced Data Distributor(BDD) in the SSIS toolbox
- Let us look at an example
- When to use the BDD
- References
- Conclusion
Microsoft has released a new SSIS 2008 transform component called SSIS Balanced Data Distributor(BDD) on 6/7/2011. This component accepts a single input and almost evenly distributes the data stream across multiple destinations via multithreading. It can be downloaded from here.
The documentation says:
BDD accepts a single input and evenly distributes the data stream across multiple destination via multithreading. The transform takes one pipeline buffer worth of rows at a time and moves it to the next output in a round robin fashion. It’s balanced and synchronous so if one of the downstream transforms or destinations is slower than the others, the rest of the pipeline will stall so this transform works best if all of the outputs have identical transforms and destinations. The intention of BDD is to improve performance via multi-threading. Several characteristics of the scenarios BDD applies to: 1) the destinations would be uniform, or at least be of the same type. 2) the input is faster than the output, for example, reading from flat file to OleDB.
N.B.~BDD works only on SSIS 2008 and SSIS 2008 R2 versions.
After installation of the BalancedDataDistributor-x86.exe file, we need to add it to the toolbox of Data Flow Transformation as under.
Step 1: Right click on the Data Flow Transformation and select Choose Items:
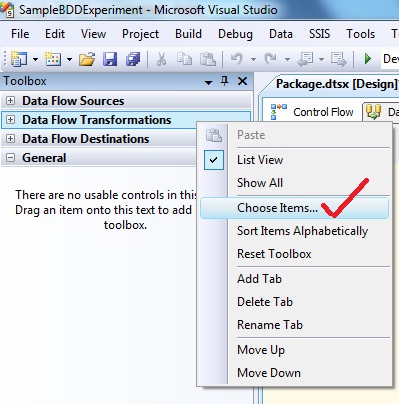
Step 2: From the Choose Items dialog box that appears, select SSIS Data Flow Items tab and from there, choose Balanced Data Distributor and finally click OK:

We will find that the BDD has been added to our Data Flow Transformation section:
BDD takes a single input and tries to distribute the data in an almost equal proportion to its various outputs, e.g., if we have 5 outputs, then each output component will receive almost 1/5th of the total input data. The efficiency of BDD comes since it operates on the data buffer and not on individual rows.
Let us have a text file, say input.txt, which is having 10,00,000(ten lac) rows. It’s a simple text file which holds some employee information like EmpID, EmpName, EmpSex and EmpPhoneNumber.
Step 1: Open Bids and drag and drop a Data Flow Task in the Control Flow Designer.
Step 2: In the Data Flow Designer, first add a Flat File source and specify the input.txt file as its source. If we make a preview, the output (partial) will be as under:
Step 3: Next, add a BDD whose source is obviously the Flat file Source.
N.B.~ Apart from its name, internal metadata validation and description, BDD does not offer any other customizations of any kind.
The property window of BDD looks as under:
Step 4: Add 5 flat file destinations, each of whose source will be our BDD. Specify the destination files for each Flat File Destination component as Output1.txt, Output2.txt, Output3.txt, Output4.txt, Output5.txt respectively. Our design should look as under:
Step 5: Now let us run the package and the output is as under:
As can be figured out, out of 10 lac data, BDD distributed 2,04,240 rows of data in the first output component while the others receive 1,98,940 rows. If we divide 10 lac by 5, then every output component is supposed to received 2 lac rows of data evenly. But since the distribution was happening through multithreading, henceforth there is no control over the data being divided precisely.
Now if we open the output files, we can find out the way BDD has distributed the data, e.g.:
| File Name | First Record | Last Record | Total # of Records |
| Output1.txt | 1,Name1,Female,12345679 | 1000000,Name1000000,Male,13345678 | 2,04,240 |
| Output2.txt | 9948,Name9948,Male,12355626 | 964859,Name964859,Female,13310537 | 1,98,940 |
| Output3.txt | 19895,Name19895,Female,12365573 | 974806,Name974806,Male,13320484 | 1,98,940 |
| Output4.txt | 29842,Name29842,Male,12375520 | 984753,Name984753,Female,13330431 | 1,98,940 |
| Output5.txt | 39789,Name39789,Female,12385467 | 994700,Name994700,Male,13340378 | 1,98,940 |
BDD works on the principle of Parallelism. It provides an easy way of creating independent segments by distributributing the work over multiple threads.
N.B.~ As discussed earlier, this component uses an internal buffer of 9,947 rows (as per the experiment, I found so) and it is pre-set. There is no way to override this. As a proof, instead of 10 lac rows, we will use only 9,947 (Nine thousand nine forty seven ) rows in our input file and will observe the behavior. After running the package, we will find that all the rows are being transferred to the first output component and the other components received nothing.
Now let us increase the number of rows in our input file from 9,947 to 9,948 (Nine thousand nine forty eight). After running the package, we find that the first output component received 9,947 rows while the second output component received 1 row.
So we can infer that the component has some pre-defined logic of distributing rows to its output components which has been abstracted.
- If there is a huge chunk of data coming and there is a necessity of reading those faster.
- If there is no ordering dependency of the data as BDD works on the Parallelism principle and not sequentially.
In this article, we have seen the advantage of BDD, and have also seen about its working. We have observed that by taking advantage of parallelism, the BDD enhances the speed of data transformation. Henceforth it is better to use it on multi-processor configuration as opposed to single-processor configuration.
Thanks for reading the article.
History
- 31st August, 2011: Initial post

