Introduction
Since the time I’ve wrote my first article about motion detection, I’ve got a lot of e-mails from different people around the world, who found the article quite useful and found a lot of applications of the code in many different areas. Those areas included simple video surveillance topics to quite impressive applications, like laser gesture recognition, detecting comets with telescope, detecting humming-birds and making camera shots of them, controlling water cannons, and many others.
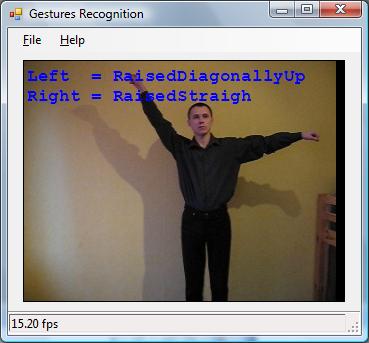
In this article, I would like to discuss one more application, which uses motion detection as its first step, and then does some interesting routines with the detected object – hands gesture recognition. Let’s suppose we have a camera which monitors an area. When somebody gets into the area and makes some hands gestures in front of the camera, the application should detect the type of the gesture, and raise an event, for example. When a hands gesture is detected, the application could perform different actions depending on the type of the gesture. For example, a gesture recognition application could control some sort of device, or another application sending different commands to it depending on the recognized gesture. What type of hands gestures are we talking about? The particular application which is discussed in the article can recognize up to 15 gestures, which are a combination of four different positions of two hands – hand is not raised, raised diagonally down, diagonally up, or raised straight.
All the algorithms described in the article are based on the AForge.NET framework, which provides different image processing routines used by the application. The application also uses some motion detection routines which are inspired by the framework and another article dedicated to motion detection.
Before we go into deep discussions about what the application does and how it is implemented, let’s take a look at a very quick demo ...
Note: There are some code snippets provided in the article, don’t try to build them – they are just provided to clarify the idea. However, the code snippets represent real working code, which are copy-pasted from the files included in the article source code. So, if you would like to see the complete code and build it, check the article’s attachments.
Motion detection and object extraction
Before we can start with hands gesture recognition, first of all, we need to recognize the human’s body which demonstrates the gesture, and find a good moment when the actual gesture recognition should be done. For both these tasks, we are going to reuse some motion detection ideas described in the motion detection article.
For the object extraction task, we are going to use the approach which is based on background modeling. Let’s suppose that the very first frame of a video stream does not contain any moving objects, but just contains a background scene.

Of course, such assumptions can not be true in all cases. But, first of all, let's assume it could be valid for most cases, so it is quite applicable, and second, our algorithm is going to be adaptive, so it could handle situations, like when the first frame contains not just the background. But, let’s be consecutive ... So, our very fist frame could be taken as an approximation of the background frame.
if ( backgroundFrame == null )
{
width = image.Width;
height = image.Height;
frameSize = width * height;
backgroundFrame = grayscaleFilter.Apply( image );
return;
}
Now, let’s suppose that after a while, we receive a new frame which contains some object, and our task is to extract it.
When we have two images, the background and the image with an object, we could use the Difference filter to get the difference image:
Bitmap currentFrame = grayscaleFilter.Apply( image );
differenceFilter.OverlayImage = backgroundFrame;
Bitmap motionObjectsImage = differenceFilter.Apply( currentFrame );
On the difference image, it is possible to see the absolute difference between two images – whiter areas show the areas of higher difference, and black areas show the areas of no difference. The next two steps are:
- Threshold the difference image using the
Threshold filter, so each pixel may be classified as a significant change (most probably caused by a moving object) or as a non-significant change. - Remove noise from the threshold difference image using the
Opening filter. After this step, the stand alone pixels, which could be caused by noisy camera and other circumstances, will be removed, so we’ll have an image which depicts only the more or less significant areas of changes (motion areas).
It looks like, we got quite a good hands gesture image, and we are ready for the next step – recognition ... Not yet. The object’s image we got as an example represents a quite recognizable human’s body which demonstrates a hands gestures. But, before we get such an image in our video stream, we’ll receive a lot of other frames, where we may have many other different objects which are far from being human bodies. Such objects could be anything else moving across the scene, or it even could be quite bigger noise than the one we filtered out before. To get rid of false objects, let’s go through all the objects in the image and check their sizes. To do this, we are going to use the BlobCounter class:
blobCounter.ProcessImage( motionObjectsData );
Blob[] blobs = blobCounter.GetObjectInformation( );
int maxSize = 0;
Blob maxObject = new Blob( 0, new Rectangle( 0, 0, 0, 0 ) );
if ( blobs != null )
{
foreach ( Blob blob in blobs )
{
int blobSize = blob.Rectangle.Width * blob.Rectangle.Height;
if ( blobSize > maxSize )
{
maxSize = blobSize;
maxObject = blob;
}
}
}
How are we going to use the information about the biggest object’s size? First of all, we are going to implement an adaptive background, which we’ve mentioned before. Suppose that, from time to time, we may have some minor changes in the scene, like minor changes of light conditions, movements of small objects, or even a small object that has appeared and stayed on the scene. To take these changes into account, we are going to have an adaptive background – we are going to change our background frame (which is initialized from the first video frame) in the direction of our changes using the MoveTowards filter. The MoveTowards filter slightly changes an image in a direction to make a smaller difference with the second provided image. For example, if we have a background image which contains a scene only, and an object image which contains the same scene plus an object on it, then applying the MoveTowards filter sequentially to the background image will make it the same as the object image after a while – the more we apply the MoveTowards filter to the background image, the more evident the presence of the object on it becomes (the background image becomes "closer" to the object image – the difference becomes smaller).
So, we check the size of the biggest object on the current frame and, if it is not that big, we consider the object as not significant, and we just update our background frame to adapt to the changes:
if ( ( maxObject.Rectangle.Width < 20 ) || ( maxObject.Rectangle.Height < 20 ) )
{
moveTowardsFilter.OverlayImage = currentFrame;
moveTowardsFilter.ApplyInPlace( backgroundFrame );
}
The second usage of the maximum object’s size is to find the one which is quite significant and which may potentially be a human’s body. To save CPU time, our hands gesture recognition algorithm is not going to analyze any object which is the biggest on the current frame, but only objects which satisfy some requirements:
if ( ( maxObject.Rectangle.Width >= minBodyWidth ) &&
( maxObject.Rectangle.Height >= minBodyHeight ) &&
( previousFrame != null ) )
{
}
OK, now we have an image which contains a moving object, and the object's size is quite reasonable so it could be a human’s body potentially. Are we ready to pass the image to the hands gesture recognition module for further processing? Again, not yet ...
Yes, we’ve detected a quite big object, which may be a human’s body demonstrating some gesture. But, what if the object is still moving? What if the object did not stop yet and it is not yet ready to demonstrate us the real gesture it would like to do? Do we really want to pass all these frames to the hands gesture recognition module while the object is still in motion, loading our CPU with more computations? More than that, since the object is still in motion, we may even detect a gesture which is not the one the object would like to demonstrate. So, let’s not hurry with gesture recognition yet.
After we detect an object which is a candidate for further processing, we would like to give it a chance to stop for a while and demonstrate us something – a gesture. If the object is constantly moving, it does not want to demonstrate us anything, so we can skip its processing. To catch the moment when the object has stopped, we are going to use another motion detector, which is based on the difference between frames. The motion detector checks the amount of changes between two consequent video frames (the current and the previous one) and, depending on this, decided if there is motion detected or not. But, in this particular case, we are interested not in the motion detection, but the detection of absence of motion.
differenceFilter.OverlayImage = previousFrame;
Bitmap betweenFramesMotion = differenceFilter.Apply( currentFrame );
BitmapData betweenFramesMotionData = betweenFramesMotion.LockBits(
new Rectangle( 0, 0, width, height ),
ImageLockMode.ReadWrite, PixelFormat.Format8bppIndexed );
thresholdFilter.ApplyInPlace( betweenFramesMotionData );
openingFilter.ApplyInPlace( betweenFramesMotionData );
VerticalIntensityStatistics vis =
new VerticalIntensityStatistics( betweenFramesMotionData );
int[] histogram = vis.Gray.Values;
int changedPixels = 0;
for ( int i = 0, n = histogram.Length; i < n; i++ )
{
changedPixels += histogram[i] / 255;
}
betweenFramesMotion.UnlockBits( betweenFramesMotionData );
betweenFramesMotion.Dispose( );
if ( (double) changedPixels / frameSize <= motionLimit )
{
framesWithoutMotion++;
}
else
{
framesWithoutMotion = 0;
framesWithoutGestureChange = 0;
notDetected = true;
}
As it can be seen from the code above, the difference between frames is checked by analyzing the changedPixel variable, which is used to calculate the amount of changes in percents, and then the value is compared with the configured motion limit to check if we have a motion or not. But, as can also be seen from the code above, we don’t call the gesture recognition routine immediately after we detect that there is no motion. Instead of this, we keep a counter which calculates the amount of consequent frames without motion. And, only when the amount of consequent frames without motion reaches some certain value, we finally pass the object to the hands gesture recognition module.
if ( framesWithoutMotion >= minFramesWithoutMotion )
{
if ( notDetected )
{
blobCounter.ExtractBlobsImage( motionObjectsData, maxObject );
Gesture gesture = gestureRecognizer.Recognize( maxObject.Image, true );
maxObject.Image.Dispose( );
...
}
}
One more comment before we move to the hands gesture recognition discussion. To make sure we don’t have false gesture recognition, we do an additional check – we check that the same gesture can be recognized on several consequent frames. This additional check makes sure that the object we’ve detected really demonstrates us one gesture for a while and that the gesture recognition module provides an accurate result.
if (
( gesture.LeftHand == previousGesture.LeftHand ) &&
( gesture.RightHand == previousGesture.RightHand )
)
{
framesWithoutGestureChange++;
}
else
{
framesWithoutGestureChange = 0;
}
if ( framesWithoutGestureChange >= minFramesWithoutGestureChange )
{
if ( GestureDetected != null )
{
GestureDetected( this, gesture );
}
notDetected = false;
}
previousGesture = gesture;
hands gesture Recognition
Now, when we have detected an object to process, we can analyze it, trying to recognize a hands gesture. The hands gesture recognition algorithm described below assumes that target object occupies the entire image, but not part of it:
The idea of our hands gesture recognition algorithm is quite simple, and 100% based on histograms and statistics, but not on things like pattern recognition, neural networks, etc. This makes this algorithm quite easy, in terms of implementation and understanding.
The core idea of this algorithm is based on analyzing two kinds of object histograms – horizontal and vertical histograms, which can be calculated using the HorizontalIntensityStatistics and VerticalIntensityStatistics classes:
We are going to start the hands gesture recognition from utilizing the horizontal histogram since for the first step, it looks more useful. The first thing we are going to do is to find areas of the image which are occupied by hands, and the area, which is occupied by the torso.
Let’s take a closer look at the horizontal histogram. As it can be seen from the histogram, the hands’ areas have relatively small values on the histogram, but the torso area is represented by a peak of high values. Taking into account some simple relative proportions of the human body, we may say that the human hand thickness can never exceed 30% percent of the human body height (30% is quite a big value, but let’s take this for safety and as an example). So, applying a simple threshold to the horizontal histogram, we can easily classify the hand areas and the torso area:
HorizontalIntensityStatistics his =
new HorizontalIntensityStatistics( bodyImageData );
int[] hisValues = (int[]) his.Gray.Values.Clone( );
double torsoLimit = torsoCoefficient * bodyHeight;
for ( int i = 0; i < bodyWidth; i++ )
{
hisValues[i] = ( (double) hisValues[i] / 255 > torsoLimit ) ? 1 : 0;
}
From the threshold horizontal histogram, we can easily calculate the hands’ length and the body torso width – the length of the right hand is the width of the empty area on the histogram from the right, the length of the left hand is the width of the empty area from the left, and the torso’s width is the width of the area between the empty areas:
int leftHand = 0;
while ( ( hisValues[leftHand] == 0 ) && ( leftHand < bodyWidth ) )
leftHand++;
int rightHand = bodyWidth - 1;
while ( ( hisValues[rightHand] == 0 ) && ( rightHand > 0 ) )
rightHand--;
rightHand = bodyWidth - ( rightHand + 1 );
int torsoWidth = bodyWidth - leftHand - rightHand;
Now, when we have the hand lengths and the torso’s width, we can determine if the hand is raised or not. For each hand, the algorithm tries to detect if the hand is not raised, raised, diagonally down, raised straight, or raised diagonally up. All four possible positions are demonstrated on the image below, in the order they were listed above:
To check if a hand is raised or not, we are going to use some statistical assumptions about body proportions again. If the hand is not raised, its width on the horizontal histogram will not exceed 30% of the torso’s width, for example. Otherwise, it is raised somehow.
if ( ( (double) leftHand / torsoWidth ) >= handsMinProportion )
{
}
else
{
}
So far, we were able to recognize a hand position – when the hand is not raised. Now, we need to complete the algorithm by recognizing the exact hand position when it is raised. And to do this, we’ll use the VerticalIntensityStatistics class, which was mentioned before. But now, the class will be applied not to the entire object’s image, but only to the hand’s image:
Crop cropFilter = new Crop( new Rectangle( 0, 0, leftHand, bodyHeight ) );
Bitmap handImage = cropFilter.Apply( bodyImageData );
VerticalIntensityStatistics stat = new VerticalIntensityStatistics( handImage );
The image above contains good samples, and using the above histograms, it is quite easy to recognize the gesture. But, in some cases, we may not have such clear histograms like the ones above, but only noisy histograms, which may be caused by light conditions and shadows. So, before making any final decisions about the raised hand, let’s perform two small preprocessing steps of the vertical histogram. These two additional steps are quite simple, so their code is not provided here, but can be retrieved from the files included in the article source code.
- First of all, we need to remove the low values from the histogram, which are lower than 10% of the histogram’s maximum value, for example. The image below demonstrates a hand’s image which contains some artifacts caused by shadows. Such artifacts can be easily removed by filtering low values on the histogram, what is also demonstrated on the image below (the histogram is filtered already).
- Another type of issue which we need to take care about is a "twin" hand, which is actually a shadow. This could be easily solved by walking through the histogram and removing all peaks which are not the highest peak.
At this point, we should have a clear vertical histograms, like the ones we’ve seen before, so now we are a few steps away from recognizing the hands gesture.
Let’s start by recognizing a straight-raised hand first. If we take a look at the image of a straight hand, then we could make one more assumption about body proportions – the length of the hand is much bigger than its width. In the case of a straight-raised hand, its histogram should have a quite high, but thin peak. So, let’s use these properties to check if the hand is raised straight:
if ( ( (double) handImage.Width / ( histogram.Max -
histogram.Min + 1 ) ) > minStraightHandProportion )
{
handPosition = HandPosition.RaisedStraigh;
}
else
{
}
(Note: The Min and Max properties of the Histogram class return the minimum and maximum values with non-zero probability. In the above sample code, these values are used to calculate the width of the histogram area occupied by the hand. See the documentation for the AForge.Math namespace.)
Now, we need to make the last check to determine if the hand is raised diagonally up or diagonally down. As we can see from histograms of diagonally raised up/down hands, the peak for the diagonally up hand is shifted to the beginning of the histogram (to the top, in the case of a vertical histogram), but the peak of the diagonally down hand is shifted more to the center. Again, we can use this property to check the exact type of the raised hand:
if ( ( (double) histogram.Min / ( histogram.Max - histogram.Min + 1 ) ) <
maxRaisedUpHandProportion )
{
handPosition = HandPosition.RaisedDiagonallyUp;
}
else
{
handPosition = HandPosition.RaisedDiagonallyDown;
}
We are done! Now, our algorithm is able to recognize four positions of each hand. Applying the same for the second hand, our algorithm will provide the following results for those four hands gestures:
- Left hand is not raised; right hand is not raised;
- Left hand is raised diagonally down; right hand is not raised;
- Left hand is raised straight; right hand is not raised;
- Left hand is raised diagonally up; right hand is not raised.
If two not-raised hands is not considered to be a gesture, then the algorithm can recognize 15 hands gestures, which are a combination of different hand positions.
Conclusion
As we can see from the above article, we have got algorithms which, first of all, allow us to extract moving objects from a video feed, and, second, to successfully recognize hands gestures demonstrated by the object. The recognition algorithm is very simple and easy for the implementation, as is for understanding. Also, since it is based only on information from histograms, it is quite efficient in performance, and does not require a lot of computational resources, which is quite important in cases where we need to process a lot of frames per second.
To make the algorithms easy to understand, I’ve used generic image processing routines from the AForge.Imaging library, which is a part of the AForge.NET framework. This means that going from generic routines to specialized ones (routines which may combine several steps in one), it is easily possible to improve the performance of these algorithms even more.
Possible areas of improvements for these algorithms:
- More robust recognition in the case of hand shadows on walls;
- Handling of dynamic scenes, where different kinds of motions may occur behind the main object.

