Introduction
Base64 is used to store binary data such as images as text. It can be used in web pages but is more commonly seen in email applications and in XML files.
The .NET Framework includes a base64 encoder in its Convert class. Since it represents a fair degree of bit manipulation and can be done in parallel, is it perhaps
a task that can be better handled by a graphics processing unit?
Background
Base64 uses 64 characters as its base (decimal uses 10, hex uses 16). The 64 characters are A-Z, a-z, 0-9, and '+' and '/'. Three bytes can be represented
by four base64 digits. If the total number of bytes is not a multiple of three, then padding characters are used. The padding character is '='. The total length
of the base64 string for a given number of bytes n is 4 * (n/3). Per block of three bytes, we have in total 24-bits (3 * 8-bits). 64 different values can be represented
by 6-bits, so we need in total four 6-bit values to contain the 24-bits. Base64 encoding consists of this processing of blocks of three bytes and since each block
is independent of any other block, it would appear to be a suitable task for a GPU.
Though it is becoming more common, the use of GPUs for non-graphics, general purpose programming remains a niche. Typical business and web programming still rarely
makes use of GPUs and there are a number of good reasons for this. Finding suitable performance bottlenecks and then porting an algorithm or business logic to make use
of a GPU can be time consuming, and the pay-off can be uncertain. Furthermore, the target hardware platform may not have a suitable GPU. Despite this, GPUs can have,
given the right task, massive performance gains.
NVIDIA still leads the way with general purpose GPU (GPGPU). Their CUDA language and associated tools and libraries make it relatively easy to get started in C/C++.
In .NET, it is a different story, requiring the use of PInvoke and the so-called CUDA driver API. This is rather cumbersome. CUDA.NET simplified matters a little,
however the programming model remained that of the driver API, and kernel (GPU device) code still needed to be written in CUDA C. CUDAfy.NET goes a stage further
and hides much of the complexity of the driver API, allows kernel code to also be written in .NET, and uses standard .NET types (e.g., arrays of value types).
Configuring your PC
First, be sure you have a relatively recent NVIDIA Graphics Card, one that supports CUDA. You'll then need to go to the NVIDIA CUDA website and download
the CUDA 5.5 Toolkit. Install this in the default location. Next up, ensure that you have the latest
NVIDIA drivers. These can be obtained through an NVIDIA update or from the NVIDIA website.
The project here was built using Visual Studio 2010 and the language is C#, though VB and other .NET languages should be fine. Visual Studio Express can be used
without problem - bear in mind that only 32-bit apps can be created though. To get this working with Express, you need to visit the
Visual Studio Express website:
- Download and install Visual C++ 2010 Express (the NVIDIA compiler requires this)
- Download and install Visual C# 2010 Express
- Download and install CUDA 5.5 Toolkit (32-bit and/or 64-bit)
- Ensure that the C++ compiler (cl.exe) is on the search path (Environment variables)
This set-up of the CUDA compiler (NVCC) is actually the toughest stage of the whole process, so please persevere. Read any errors you get carefully - most likely they
are related to not finding cl.exe or not having either the 32-bit or 64-bit CUDA Toolkit. Try to get NVCC working without CUDAfy. If you still have problems, then please let me know.
The Code
The simplest way of converting to base64 in .NET is to use the Convert.ToBase64 method. However, let's look at how we can implement such a method ourselves.
Below is a method that takes a byte array and converts to a base64 string. The code is based on C code from René Nyffenegger.
public static string base64_encode(byte[] bytes_to_encode)
{
int i = 0;
int j = 0;
int ctr = 0;
StringBuilder sb = new StringBuilder((bytes_to_encode.Length * 4) / 3);
int[] char_array_3 = new int[3];
int[] char_array_4 = new int[4];
int in_len = bytes_to_encode.Length;
while (in_len-- > 0)
{
char_array_3[i++] = bytes_to_encode[ctr++];
if (i == 3)
{
char_array_4[0] = (char_array_3[0] & 0xfc) >> 2;
char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4);
char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) +
((char_array_3[2] & 0xc0) >> 6);
char_array_4[3] = char_array_3[2] & 0x3f;
for (i = 0; (i < 4); i++)
{
char c = base64_chars[char_array_4[i]];
sb.Append(c);
}
i = 0;
}
}
if (i != 0)
{
for (j = i; j < 3; j++)
char_array_3[j] = 0;
char_array_4[0] = (char_array_3[0] & 0xfc) >> 2;
char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4);
char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6);
char_array_4[3] = char_array_3[2] & 0x3f;
for (j = 0; (j < i + 1); j++)
{
char c = base64_chars[char_array_4[j]];
sb.Append(c);
}
while ((i++ < 3))
sb.Append('=');
}
string s = sb.ToString();
return s;
}
The GPU Kernel Code
We will use this code as a basis for our GPU kernel. This is the code that will actually run on the GPU. Methods that can run on the GPU must be static and decorated
with the Cudafy attribute. Thousands of instances of device methods can run in parallel, so we need a means of identifying threads from within the method.
The GThread parameter is how this can be done. The two other parameters are the input and output arrays. The method Gettid returns the unique
ID of the thread. Threads are launched in a grid of blocks, where each block contains threads. Hence we calculate the ID by multiplying the block ID by
the block size (dimension) and adding the thread ID within the block. Grids and blocks can be multidimensional, but here we only use one dimension, signified by x.
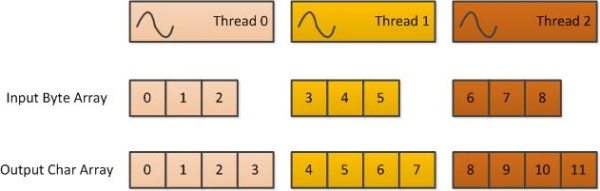
Since each thread will process a group of three bytes, the offset into the input array is three times the thread ID. The offset into the output array is four times
the thread ID. What follows is a fairly straightforward port of the code discussed above. Since String is not supported in kernel code, we simply place
the string as a constant in the code.
[Cudafy]
public static void ToBase64String(GThread thread, byte[] input, char[] output)
{
int tid = Gettid(thread);
int itid = tid * 3;
int otid = tid * 4;
if (itid + 2 < input.Length)
{
byte a0 = 0;
byte a1 = 0;
byte a2 = 0;
byte b0 = 0;
byte b1 = 0;
byte b2 = 0;
byte b3 = 0;
a0 = input[itid];
a1 = input[itid + 1];
a2 = input[itid + 2];
b0 = (byte)((a0 & 0xfc) >> 2);
b1 = (byte)(((a0 & 0x03) << 4) + ((a1 & 0xf0) >> 4));
b2 = (byte)(((a1 & 0x0f) << 2) + ((a2 & 0xc0) >> 6));
b3 = (byte)(a2 & 0x3f);
output[otid] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"[b0];
output[otid + 1] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"[b1];
output[otid + 2] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"[b2];
output[otid + 3] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"[b3];
}
}
[Cudafy]
public static int Gettid(GThread thread)
{
int tid = thread.blockIdx.x * thread.blockDim.x + thread.threadIdx.x;
return tid;
}
The GPU Host Code
The code for interacting with the GPU is implemented in the class named GConvert.
A reference is made to Cudafy.NET.dll and the following namespaces included:
using Cudafy;
using Cudafy.Host;
using Cudafy.Translator;
There are two methods implemented for performing the conversion. Both do the same thing, taking the byte array to be encoded and a Stream for the output.
We'll look at the most straightforward.
Writing to the output stream is done asynchronously. Since StreamWriter does not contain Begin and End methods for asynchronous writing, a delegate is used.
The class member _gpu refers to the CUDAfy GPGPU class and represents a single GPU device. It is passed into the GConvert constructor.
The process of working is now as follows:
- Transfer a chunk of the input data to the GPU device.
- Process the chunk (Launch).
- Transfer the resultant chunk back to the host.
- Write the results asynchronously to the output stream.
- If more data is available, then return to step 1.
- Once all chunks have been processed, check for any remaining bytes and encode on host.
public void ToBase64Naive(byte[] inArray, Stream outStream)
{
int totalBytes = inArray.Length;
int ctr = 0;
int chunkIndex = 0;
int threadsPerBlock = 256;
StreamWriter sw = new StreamWriter(outStream);
BeginWriteDelegate beginWrite = new BeginWriteDelegate(BeginWrite);
IAsyncResult res = null;
while (totalBytes > 0)
{
int chunkSize = Math.Min(totalBytes, MAXCHUNKSIZE);
int outChunkSize = (chunkSize * 4) / 3;
_gpu.CopyToDevice(inArray, ctr, _inArrays_dev[chunkIndex], 0, chunkSize);
int blocksPerGrid =
(chunkSize + (threadsPerBlock * 3) - 1) / (threadsPerBlock * 3);
_gpu.Launch(blocksPerGrid, threadsPerBlock, "ToBase64String",
_inArrays_dev[chunkIndex], _outArrays_dev[chunkIndex]);
_gpu.CopyFromDevice(_outArrays_dev[chunkIndex], 0,
_outArrays[chunkIndex], 0, outChunkSize);
if (res != null)
beginWrite.EndInvoke(res);
res = beginWrite.BeginInvoke(sw, _outArrays[chunkIndex], 0,
outChunkSize, null, null);
chunkIndex++;
totalBytes -= chunkSize;
ctr += chunkSize;
if (chunkIndex == MAXCHUNKS)
chunkIndex = 0;
}
if (res != null)
beginWrite.EndInvoke(res);
int remainder = inArray.Length % 3;
if (remainder != 0)
{
string s = Convert.ToBase64String(inArray,
inArray.Length - remainder,
remainder).Remove(0, remainder);
sw.Write(s);
}
sw.Flush();
}
Of interest here are the following variables:
MAXCHUNKSIZE: A constant that must be a multiple of 3.MAXCHUNKS: The maximum number of chunks._inArrays_dev: On the GPU, MAXCHUNKS number of arrays each of MAXCHUNKSIZE bytes._outArrays_dev: On the GPU, MAXCHUNKS number of arrays each of MAXCHUNKSIZE * 4/3 chars._outArrays: On host, MAXCHUNKS number of arrays each of MAXCHUNKSIZE * 4/3 chars.
These arrays are instantiated in the GConvert constructor. The process of Cudafying is detailed in an earlier article.
Using Cudafy for GPGPU Programming in .NET.
Basically, the GPU code is contained in the class GPUConvertCUDA and we create a module with the name of that class. Using the IsModuleLoaded method,
we check if the module is already loaded. If not, we try to deserialize the module from an XML file named 'GPUConvertCUDA.cdfy'. If the file does not exist
or the serialized module was created from a different version of the assembly, then we Cudafy again. We pass the auto platform (x86 or x64),
CUDA 1.2 architecture (the latest NVIDIA devices are 2.0) parameters along with the type of the class we want to Cudafy. To save time, next time the program
runs, we serialize the module to an XML file.
public GConvert(GPGPU gpu)
{
_gpu = gpu;
string moduleName = typeof(GPUConvertCUDA).Name;
if (!_gpu.IsModuleLoaded(moduleName))
{
var mod = CudafyModule.TryDeserialize(moduleName);
if (mod == null || !mod.TryVerifyChecksums())
{
Debug.WriteLine("Cudafying...");
mod = CudafyTranslator.Cudafy(ePlatform.Auto,
eArchitecture.sm_12, typeof(GPUConvertCUDA));
mod.Serialize(moduleName);
}
_gpu.LoadModule(mod);
}
_inArrays_dev = new byte[MAXCHUNKS][];
_outArrays_dev = new char[MAXCHUNKS][];
_outArrays = new char[MAXCHUNKS][];
_inStages = new IntPtr[MAXCHUNKS];
_outStages = new IntPtr[MAXCHUNKS];
for (int c = 0; c < MAXCHUNKS; c++)
{
_inArrays_dev[c] = _gpu.Allocate<byte>(MAXCHUNKSIZE);
_outArrays_dev[c] = _gpu.Allocate<char>((MAXCHUNKSIZE * 4) / 3);
_inStages[c] = _gpu.HostAllocate<byte>(MAXCHUNKSIZE);
_outStages[c] = _gpu.HostAllocate<char>((MAXCHUNKSIZE * 4) / 3);
_outArrays[c] = new char[(MAXCHUNKSIZE * 4) / 3];
}
}</char></byte></char></byte>
_inStages and _outStages are used by the optimized version of the ToBase64Naive method, ToBase64. This method makes use of pinned
memory for faster transfers and for performing asynchronous transfers and kernel launches. Use HostAllocate for allocating pinned memory.
Remember, pinned memory is limited compared to unpinned memory and that you will need to clean it up manually using HostFree. The performance increase
gained by using pinned memory for transfers can be around 50%, however this is offset by the need to transfer from managed memory into pinned memory.
Ultimately, the speed increase can be insignificant compared to normal transfers as in the ToBase64Naive method. However, it does permit another
benefit and that is asynchronous transfers and kernel launches. Transfers do not occur in parallel with each other though; instead they are placed in a queue.
Transfers can be in parallel with launches. Correct usage of stream IDs is required. Do not use stream ID 0 for this purpose - stream 0 synchronizes all streams
irrespective of ID. All operations of the same stream ID are guaranteed to be performed in sequence.
Using the GConvert Class
Get a GPU device using the static CudafyHost.GetDevice method. The device is passed to the GConvert constructor.
Conversion takes two arguments, the byte array and the output stream.
GPGPU gpu = CudafyHost.GetDevice(eGPUType.Cuda);
GConvert gc = new GConvert(gpu);
gc.ToBase64(ba, gpuStream);
Benchmarks
We want to compare a number of different ways of doing base64 encoding. The following benchmarks were run on an Intel Core i5-450M with NVIDIA GeForce GT 540M GPU:
- Our own base64 encoder.
- GPU Naive
- GPU Asynchronous
- .NET Convert
| Test | 1MByte (ms) | 12MByte (ms) | 24MBytes (ms) | 36MBytes (ms) |
| Base64 encoder | 52 | 612 | 1232 | 1826 |
| GPU Naive | 5 | 43 | 85 | 141 |
| GPU Asynchronous | 5 | 39 | 76 | 113 |
| .NET Convert | 3 | 53 | 106 | 349 |
And now as a graph; lower is better.

Discussion
For small amounts of binary data, the differences in speed are relatively small. For large data sets, the GPU provided a massive performance gain over our
own base64 implementation. The differences between the simpler naive GPU implementation and the asynchronous pinned memory version were useful but not earth
shattering. If you need to squeeze every last bit of performance out of the GPU, then it's worthwhile. However, what is significant is the fantastic result
of the out of the box .NET implementation. For the vast majority of cases, it will be almost as fast as the GPU, only being beaten for much larger arrays.
If when you run the application your GPU runs much slower compared to the .NET version that the results here showed, then there is likely a good reason
for this. These benchmarks are run on the NVIDIA Fermi architecture. This recent design gives far better performance when accessing small, irregular blocks
of global memory as we do here when reading three individual bytes per thread. There are ways of circumventing this issue by clever use of shared memory,
however as in any programming task, one has to draw limits to the time spent implementing. The code here was a simple port of the CPU version.
So, why is the .NET base64 encoder so much faster than our own CPU version? Well, it is extremely unlikely that it is implemented in straightforward
C# as we did. Most likely, it makes use of special low-level SSE commands, much the same as FFTW (Fastest Fourier Transform in the West) can perform an FFT faster
than we can step through an array of the same length, doing a simple multiplication on each element. Due to the simple, sequential, in order nature of base64 encoding,
an optimized CPU version can match a GPU. Note that the .NET version could likely be made even faster by explicitly breaking up the data and performing in multiple threads,
say one per core. Be aware also that the writing to the stream does not become the bottleneck. Remove that step if necessary to ensure a true comparison.
Writing with a StreamWriter is not as fast as writing with a BinaryWriter.
Can base64 encoding still be useful on a GPU? Yes, for very large data sets, and if the data to be encoded is already on the GPU. This would remove the need
to copy the data first to the GPU. Furthermore, it would reduce the load on valuable CPU resources.
License
The Cudafy.NET SDK includes two large example projects featuring, amongst others, ray tracing, ripple effects, and fractals. It is available as a dual license software library.
The LGPL version is suitable for the development of proprietary or Open Source applications if you can comply with the terms and conditions contained
in the GNU LGPL version 2.1. Visit the Cudafy website for more information.
History
- 2nd November, 2011
- 17th September, 2013
- Updated to use CUDAfy V1.26 and CUDA 5.5

