This articles tries to explain in steps how to build a virtual machine and a C# like compiler for a virtual machine that has assembler(-like) instructions.
POLAR - Paulo's Object-oriented Language with Assembly-like Runtime
Before starting, I must say that this is an advanced topic. I tried to make it simple and correct what, in my opinion, are common errors when explaining the process of compilation.
But, either way, the virtual machine has assembler(-like) instructions. So, being assembler, it is a hard topic. Knowing any other assembler programming language will really help understand this article.
So, if you feel comfortable with assembler, or want to see if my explanation is good, continue reading.
In this article, I will try to explain step-by-step about how to build a virtual machine and a C# like compiler for such a virtual machine.
The name (POLAR) was chosen because it is easy to remember, because I like freezing temperatures and because I managed to create a meaning for it.
If my site is not down, the application should load when you click on the link below:
Note: At the end of the article, there is a How to Use POLAR in Your Own Projects. So, if you are not interested in how it works but want to add scripting support to your projects, take a look.
Background
I like to recreate things. Many say that it is useless, but it helps me understand how things work and possibly why they are how they are. This also helps me solve problems to which I can't find built-in solutions or put in practice some of my theories. I do that so often that many of my friends say that I should create a new language or a new operating system.
Well... I don't expect to create a very popular language, but why not give it a try?
Knowing the Result before Doing any Code
I already helped some friends that needed to create "compilers" for educational purposes. But something I didn't like in the normal approach is the flow of things.
In general, people start by the text, something like this:
public static long Test(long x, long y)
return (x+x)/y;
Then they must transform such text into "tokens", composed of type and possibly a content, something like:
| Type | Content |
| public | |
| static | |
| long | |
| Name | Test |
| ( | |
| long | |
| Name | x |
| , | |
| long | |
| Name | y |
| ) | |
| return | |
| ( | |
| Name | x |
| + | |
| Name | x |
| ) | |
| / | |
| Name | y |
| ; | |
And finally, they interpret or further compile such code.
What's Wrong with that Approach?
Those steps are necessary, but my problem is the order in which they are done.
First, many people don't understand why it is important to transform text into tokens. At first look, the tokens are harder to understand than the text representation (at least for most humans).
Second, we don't have a "target" defined. Will we start interpreting the tokens directly? Will we create something else with those tokens that we will call as "compiled code"?
Third, and this is the worst: After converting text into tokens, we can't test anything as those tokens are a mid-step. Until we create some kind of interpreter, the tokens look like a complete waste of time.
So, my approach is different:
- We start by the result. The "runnable code". For me, that means starting with the virtual machine instruction set and architecture.
- Then we test some instructions and further develop the instructions and the virtual machine.
- Finally, we create the text parser that will compile to such code, so other programmers will be able to use our virtual machine without knowing assembler.
The Very Final Result
If my site is working, you probably saw the very final result. But let's explain it:
My personal approach was to create the virtual machine before everything else. I really did that. But in the article, I decided to go one step further. What I will present to you is a language which the following features:
- Compiled and (pseudo-)interpreted. It is never converted to real machine code, but it does not interpret bytes. It simply calls "virtual methods"
- Can be used as a script language even under restricted environments (like Silverlight)
- Is 64-bit by default (in fact, the only numeric value supported at this moment is
long) - Can access .NET classes (it runs under .NET, but to access .NET classes those must be explicitly registered)
- Can create new classes (but does not support inheritance at this moment)
- Supports
var item = new Class(); (like C#) or Class item = new(); (not supported by any other language that I am aware of - well, this was written in 2011, at the time C# didn't support it, and many people said it was dumb to support it... now it is supported in C# and I was told also in Java... things change); - Supports exception handling and has access to the actual exception at any time by the
actualexception keyword (so inner exceptions can be used by default and a method without parameters can know if it was called by an exception); - Supports
yield return at assembly(-like) level. This is done by creating a "save point" to which any method (even void methods) can return at any moment. The stack from the call until the return is saved so the method can continue later. This allows very versatile cooperative-threading and helps a lot in animations. I already discussed that in my article Yield Return Could Be Better and yield return can be called by finally clauses - Allow parameters to be marked as
required, so if they come null an ArgumentNullException is thrown with the right parameter name - Supports default parameters at assembly level. OK, I don't allow multi-libraries at this moment, but the real purpose is that. When assembly A uses default values of assembly B, in .NET or C++, it is compiled with an explicit call using those default values. If in the future assembly B changes the defaults, assembly A will still use the old defaults until it is recompiled. When defaults are at the assembly level, this does not happen
- It is not stack based. It has a stack (so a method knows how to return to its caller) but any operation that requires parameters or creates new parameters is based on locals. Maybe this is too technical, but this avoids unnecessary loads and store calls and simplifies understanding the "assembler" code, as instead of counting stacked values we see operations over locals (the most common case)
- OK... there are a lot of things missing yet... but I will present how something simple like this...
What's your name?
<<You write your name here>>
Your name is: <<The name you wrote>>
...was made from instructions like this:
.localcount 2
PutValueInLocal "What's your name?", 0
PrepareDotNetCall Script:WriteLine
SetParameter 0, 0 // sets the parameter 0 with the value at local 0.
CallMethodWithoutReturn
PrepareDotNetCall Script:ReadLine
CallMethodWithReturn 1 // put the result at local 1.
PrepareDotNetCall Script:Write
PutValueInLocal "Your name is: ", 0
SetParameter 0, 0
CallMethodWithoutReturn
PrepareDotNetCall Script:WriteLine
SetParameter 0, 1 // set the parameter 0 to the local 1 (the name)
CallMethodWithoutReturn
ReturnNoResult
Which started as code like this:
public static void Main()
{
Script.WriteLine("What's your name?");
string name = Script.ReadLine();
Script.Write("Your name is: ");
Script.WriteLine(name);
}
And, after making that simple example work, adding new functionalities and testing, it is possible to create a game like:
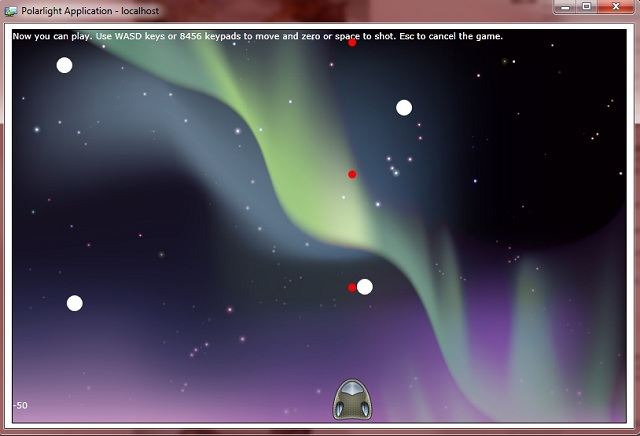
The Virtual Machine - How I Started Things (Maybe Not the Best Way)
When I first thought about the Virtual Machine, I thought about many instructions using a byte representation, so I could easily interpret it using a switch statement or by having a list of "actions" and using the byte value as the index of the instruction to run.
I certainly prefer the object oriented approach, so a list of Actions (or an object of some interface) will do the job.
So, in a very resumed way, I could have something like this:
Byte Sequence: 0 0 1
The first byte will mean: Put Value. Such instruction should know how to read the next two bytes.
The second byte means: At register 0.
The third byte means the value. 1. So, put the value 1 at register 0.
But even before writing a single line of code, I already found new problems:
- I will be reading a byte to get an instruction. Isn't it possible to know the instruction directly?
- Not all bytes will be instructions. The first byte is a instruction and the other two bytes are not. Depending on the number parameters of the instructions, and even on the value, that amount changes. That makes it hard to jump to some part of the code and be sure a byte means an instruction. It could be an argument or an integer value, for example.
How Did I Solve That?
Simple - The binary representation is not the runnable representation.
In memory, instructions will be full objects with all parameters they need. Surely when writing "executables" we can use binary representations, but in memory a method is composed of a list of instructions with all they need (information on the method to call, values to set, or more commonly locals to read from and write to).
An instruction, then, is any class that implements a "Run" method.
Doing the Very First Test
Finally (at that moment, it was finally... but far from final), I decided to write some code.
I created the PolarVirtualMachine class that received a list of IPolarInstructions and had 256 registers (a long array with 256 positions) and, of course, I created the IPolarInstruction interface, with a Run method that received a reference to the virtual machine, so it could access the registers.
The body of the virtual machine was something like this:
public sealed class PolarVirtualMachine
{
public int InstructionIndex { get; internal set; }
internal long[] _registers = new long[256];
public void Run(List<IPolarInstruction> instructions)
{
int count = instructions.Count;
while(InstructionIndex < count)
{
IPolarInstruction instruction = instructions[InstructionIndex];
InstructionIndex++;
instruction.Run(this);
}
}
}
I needed some instruction to test, so I created the PutValueInLocal and the Add instructions. I needed to look at the _registers to see if that worked, but that's enough for the first test.
Then, next, I created the GotoDirect and the conditional Gotos, already preparing to support ifs, whiles and fors.
Want to Know How Add or GotoDirect Looked Like?
Here they are:
public sealed class Add:
IPolarInstruction
{
public byte Register1 { get; set; }
public byte Register2 { get; set; }
public byte ResultRegister { get; set; }
public void Run(PolarVirtualMachine virtualMachine)
{
long[] registers = virtualMachine._registers;
registers[resultRegister] = registers[Register1] + registers[Register2];
}
}
public sealed class GotoDirect:
IPolarInstruction
{
public int InstructionIndex { get; set; }
public void Run(PolarVirtualMachine virtualMachine)
{
virtualMachine.InstructionIndex = InstructionIndex;
}
}
This Is Useless
Maybe you are already thinking this is useless. I am writing a lot of code only to add some values.
But, hey, that's what happens with any interpreted language. A lot of instructions are needed to interpret a single virtual instruction and then execute it. Our advantage, at this moment, is that we can already see some results. We didn't do a text parser and we can already see the instructions working (well... thanks to the debugger... but...) we are going in the right direction.
What Else?
At this moment, there's a lot of things to do. We need a lot of instructions to make the virtual machine usable.
We need some way of presenting things. I can dedicate a "virtual address" as its screen, or I can create instructions to interact with .NET already existing classes (well, by seeing the sample, you can imagine what I decided to do).
And at that moment, I wanted so much to see some results that I even forgot to think about the "Virtual Machine architecture".
Did you see that I used 256 registers? Well, .NET IL and Java don't have registers. They are completely based on the stack. For a simple task like add, they stack values and call Add. Then, the values are unstacked and the result is stacked.
The actual Virtual Machine doesn't have any kind of stack. It is simply incapable of calling another method and, even if I add such instruction, how will I save the local variables of the actual method?
Choosing the Architecture
So, even if I had a lot of instructions to create yet, I decided it was time to chose an architecture.
Seeing that .NET and Java are stack-based made me think about that... but I really like registers. They were my initial thinking about local variables.
Maybe that was not the best decision (should I say... again?), but I decided to use stack-frames and locals without making the machine stack-based.
The basic decision is:
- Any operation that consumes or generates values works over locals
- The Virtual Machine does not have registers anymore - it has the notion of the actual stack frame
- And each stackframe knows its locals (today only the number of locals is important), the previous stack frame and, when preparing a method call, the next stack frame
.NET already uses the concept of locals, but it needs to load locals (push them to the stack) and store them (pop the value from the stack to a local). Also, in .NET, a method argument is not a local (it requires another instruction to load it [stack it]).
But, when I program in C#, C, Pascal and others, a method parameter is a local and I can even change its value. So I think my decision is more similar to how people usually see the variables. If they come from a parameter or if they are declared inside the method body, they are simply a "local" variable.
And, by preparing a method call before calling it, I have the option to fill all default values. So, default values will be supported at the "compiled" level. This contrasts with .NET, that supports default values at compile time, but at run-time they must be explicitly set by the caller.
So, the new Virtual Machine, Add and GotoDirect classes look like this:
public sealed class PolarVirtualMachine
{
internal _PolarStackFrame _actualFrame;
public void Run(PolarMethod method)
{
if (method == null)
throw new ArgumentNullException("method");
_actualFrame = new _PolarStackFrame();
_actualFrame._method = method;
if (method.LocalCount > 0)
_actualFrame._locals = new object[method.LocalCount];
while(true)
{
var instructions = method.Body;
int instructionIndex = _actualFrame._instructionIndex;
_actualFrame._instructionIndex++;
var instruction = instructions[instructionIndex];
instruction.Run(this);
if (_actualFrame == null)
return;
method = _actualFrame._method;
}
}
}
public sealed class Add:
IPolarlInstruction
{
public int FirstLocalIndex { get; set; }
public int SecondLocalIndex { get; set; }
public int ResultLocalIndex { get; set; }
public void Run(PolarVirtualMachine virtualMachine)
{
var actualFrame = virtualMachine._actualFrame;
var locals = actualFrame._locals;
long value1 = (long)locals[FirstLocalIndex];
long value2 = (long)locals[SecondLocalIndex];
long result = value1 + value2;
locals[ResultLocalIndex] = result;
}
}
public sealed class GotoDirect:
IPolarlInstruction
{
public int InstructionIndex { get; set; }
public void Run(PolarVirtualMachine virtualMachine)
{
virtualMachine._actualFrame._instructionIndex = InstructionIndex;
}
}
And we also have the PrepareCall, SetParameter and CallWithoutResult. I will not present all of them, as looking at the source code will probably be enough. The most important thing is to know that PrepareCall creates the next stack frame, but does not make it the active one. The SetParameter copies a value from the actual stackframe to the next one and the CallMethod (be with or without result) will make the next frame the active one.
Testing It
To test it, I was creating two lists of instructions as the methods, and one of them was calling the other. The PrepareCall, at that moment, received a List<PolarInstruction> as the method. Later, I changed it to the actual one. I really believe that if you want to look at it, then load the appropriate sample in the download section, as that will occupy too much space here in the article.
What Else - Part 2
Now we can call other methods. The default values are loaded by default, we can still set the non-default values and then call the method.
But we don't have the concept of classes in our language. In fact, our methods are simple functions. I am sure I need to add support for classes, methods, fields, virtual methods and so on.
We also don't have exception handling; We don't have stack manipulation (well, except from real assembler, I think no language has it, but I wrote an article about it and wanted to prove the concept).
In fact, there is not a single way to follow. I can finish all of that, without making a compiler, or I can create the compiler, even if the Virtual Machine is not complete yet.
Guess what I am going to do.
Exception Handling and the StackSaver
I thought about writing the compiler... but... I like to prove things. I published the article Yield Return Could Be Better in which I say that yield return could be simpler to implement and more versatile if stack manipulation was available.
As stack manipulation is similar to Exception Handling, but more complete, I decided to start by exception handling.
Exception Handling
Exception handling is, well, an exception in the natural control flow. When an exception is thrown, the machine "returns" until it finds the next catch or finally block. It does not care if it will simple jump to the appropriate instruction or if it will need to discard many stackframes.
In my implementation, the "try" is the PushCatchFinally. To make it work, I needed to add the notion of the "CatchFinallyHandler" in the stackframe. Considering a method can have a try inside a try, the tries are "pushed" or "stacked" (but it uses references to the old one, not a real Stack object).
After finishing a try block, a PopCatchFinally should be called and, as there is a "finally" block, it gets unstacked and is then made as the active instruction. The PushCatchFinally already told which instruction to call in case of an error, a PopCatchFinally or a return.
In fact, there is only a finally block. But inside such finally block, the exception can be checked and, at the end, the exception can be killed or rethrown. So, it is possible to simulate catch and finally with it.
The StackFrame also has the "actual exception" there. At any moment, the actualexception could be checked, even on methods that do not receive the exception as a parameter.
The instructions to deal with the exceptions are:
PushCatchFinally - Tell the instruction to call on exception or returnRethrow - Does nothing if there is no exception or rethrows the active exception if this is a catch or finally block... such instruction is added by default at the end of finally blocks, so they clean things up and let the exception continue to other catch/finally blocksPutActualExceptionInLocal - Puts the actual exception, even null if there is no exception, into an specific local variableFinishCatchFinally - Kills the actual exception and continues the execution using the next instructions
Stack Manipulation
My idea on the stack manipulation is to "call a method creating a save point". So, at any moment the called method can return to its caller, independently on how many stack levels it needs to go back.
This is similar to an exception. But when an exception happens, we lose all the stack frames from which we've returned from. With the stacksaver, we keep such stack frames saved, so we can continue on such method later.
To make that possible, there is a StackSaver class, which knows where the method started (the first stackframe for a given method), where it is now (as we can return from the middle of an inner method) and then the return should be changed to check if it is inside a stacksaver (to consider it as ending). To change the return, I also changed the stackframe to know if it is the first stackframe of a stacksaver.
Even if it looks hard by the explanation, it is something like this:
Imagine that method A calls method B. Method B then creates a stacksaver for method C.
It then calls method C, which calls method D, which in turn yield returns.
When yield returning, we return to method B, skipping the rest of the method D and C, but such return saves the stack-frame of D and tells that there is more to execute. Method B can then run naturally, and when it calls the stacksaver again, method D will continue. If method D returns (not yield returns), it will return to C. If C returns, then it will mark the stacksaver as finished, and will return the call with the value of false, telling that it has finished.
What happens if the method B loses the reference to the StackSaver
One of the possible problems of yield returning is that we are returning a method before it is really finished, and are ignoring any finally blocks when doing so. This can lead to resource leaks.
Well... in my actual implementation, B could return the stacksaver to A (the original method), so I should not check for "lost" stacksavers at the end of B. But when finishing the first method (the Main method) of the application, I check for such stacksavers.
My solution was to simply run them until they finish. Maybe a better approach will be to throw something like ThreadAbortException while executing them, so they execute the finally blocks without executing everything, after all they were lost. Well... I didn't do that... but maybe if I have enough requests, I will change such approach.
Compiling
Well... before compiling, I personally added a lot of other instructions and tested them directly. But... I think there are too many instructions to show them individually, so I will continue with the compilation process, as it is the one that makes the virtual machine really usable.
The process of compiling is the process of making text become instructions. Note that saving such instructions to disk is not part of the compilation.
Usually people compile to a binary representation and, specially when generating native code, that's completely correct.
But I am not generating native code as the "list of instructions" in memory is the most "natural" representation that the Polar Virtual Machine understands.
Transforming such instructions to bytes and vice-versa is a process of serialization. Surely I could've made my compiler compile directly to bytes... but I haven't even decided how the "executables" will look like. So, I prefer to compile to instructions and, at another time, I decide how the binary will look like, how to convert from instructions to bytes and from bytes to instructions.
The Compilation is divided into two big phases:
- Token Recognition
- Validation and Instruction Generation
Why is Token Recognition Needed?
To simplify things. When we see "long someVariable = 10;" we see the entire "long" as one entity, then the "someVariable" as another entity, the = as another one, the 10 as another one and the ";" (semi-colon) as the last one.
Well, that's what the token recognition tries to do for the computer. It doesn't matter the size of the word or value we are dealing with (be it 1, 100 or even more characters), it makes it become a single Token.
For the compilation, when we are expecting a name we won't need to deal with a random number of characters. We will simply read the next token, if it is not a name then we generate an error, and if it is a name, it is OK. That's only possible because the tokens were discovered by another "step" that usually comes earlier. I say usually because it is possible to make them work together, as when generating enumerators, but that complicates things again and I wanted it to be simple.
So, what should the tokenizer identify?
Keywords, arithmethic operations, "block" constructs and so on.
I decided to make my programming language similar to C#, so I already had an idea of the keywords, symbol constructs and so on. For personal reasons (that I will explain later), I decided to divide names that start with lowercase and uppercase into two different types of tokens.
Recognizing tokens is like this:
Read a character.
While it is a space or tab, continue reading.
When it is an enter, increase the line number.
As soon as we see a different thing, we try to analyze it further:
- 0-9 it is a number. So call another method (to avoid giant methods that have a
switch inside a switch) to further process it - A-Z it is an uppercase name. So call another method to read the name
- ( - Open parenthesis, ) close parenthesis and many other symbols are considered a token directly
- For other symbols, like +, I must also try to read the next one to identify it is a normal +, a ++, a +=. Each of those have an special token type and are in separate methods
- The / has the same possibility of being a mathematical operator, but it can also be a single-line comment // (so we must read until the end of the line) or a multi-line comment /* so I read until I find a */ and then I simply never add them to the token list (it is a comment, after all)
- a-z it is a lowercase name. So call another method to read the name. In many parsers, as soon as an "
i" is found, it calls a special path to try to identify if that's an "if" or an "int" (a keyword) or another word that starts by "i". I simplify that thanks to .NET switch. After reading a full name, I use a switch statement over such name to identify keywords. If it is a keyword, a token with the appropriate token type is returned (yes, there is a token type for each keyword). If it is not a keyword, then it is a lowercase name, so simply return a token with the type LowerName with its value set to the name read.
Even if the parsing to token process is not hard, I consider such work to be very, very boring.
Some Code
Probably you want to see some code. Well, I will not show the entire code here, but to give you an idea, here is a small part of it:
private void _CreateTokens()
{
_lineNumber = 1;
for(_position=0; _position<_length; _position++)
{
char c = _unit[_position];
switch(c)
{
case '\n':
_lineNumber++;
continue;
case '\r':
case ' ':
case '\t':
continue;
case '{': _AddToken(_TokenType.OpenBlock, "{"); continue;
case '}': _AddToken(_TokenType.CloseBlock, "}"); continue;
case '(': _AddToken(_TokenType.OpenParenthesis, "("); continue;
case ')': _AddToken(_TokenType.CloseParenthesis, ")"); continue;
case '[': _AddToken(_TokenType.OpenIndexer, "["); continue;
case ']': _AddToken(_TokenType.CloseIndexer, "]"); continue;
case '.': _AddToken(_TokenType.Dot, "."); continue;
case ',': _AddToken(_TokenType.Comma, ","); continue;
case ';': _AddToken(_TokenType.SemiColon, ";"); continue;
case ':': _AddToken(_TokenType.Colon, ":"); continue;
case '~': _AddToken(_TokenType.BitwiseNot, "~"); continue;
case '+': _Add(); continue;
case '-': _Subtract(); continue;
case '*': _Multiply(); continue;
case '/': _Divide(); continue;
case '^': _Xor(); continue;
case '>': _Greater(); continue;
case '<': _Less(); continue;
case '&': _And(); continue;
case '|': _Or(); continue;
case '%': _Mod(); continue;
case '=': _Equals(); continue;
case '!': _Not(); continue;
case '\"': _String(); continue;
case '\'': _Char(); continue;
case '0': _FormattedNumber(); continue;
}
if (c >= 'a' && c <= 'z')
{
_Name(_TokenType.LowerName);
continue;
}
if (c >= 'A' && c <= 'Z')
{
_Name(_TokenType.UpperName);
continue;
}
if (c >= '1' && c <= '9')
{
_Number();
continue;
}
throw new PolarCompilerException
("Parser exception. Invalid character: " + c + ", at line: " + _lineNumber);
}
}
private void _Add()
{
int nextPosition = _position + 1;
if (nextPosition == _unit.Length)
{
_AddToken(_TokenType.Add, "+");
return;
}
char c = _unit[nextPosition];
switch(c)
{
case '+':
_position++;
_AddToken(_TokenType.Increment, "++");
return;
case '=':
_position++;
_AddToken(_TokenType.Add_Here, "+=");
return;
}
_AddToken(_TokenType.Add, "+");
}
Tokens Are Gone - Let's Create Instructions
Fortunately, we have already tested our instructions. Because now we can only see the list of tokens, but can't show anything with them without further processing to create the instructions.
So, we should start creating instructions, but we start to have problems again. A normal unit starts by the using's clauses, then it has the namespace declarations, the type declarations and finally the members, which include the methods.
If I parse all of them, I will need to further implement the parser. If I don't, then at a later time, I will need to do it. Well, I did a little of each, but I consider that it is best to start by the compilation of a method. The parsing of a method body is inside the method _ParseSingleOrMultipleInstructions.
So, let's try to compile this:
Console.WriteLine("Test");
I am sure that Console is a class. But, what if it was a property?
Or a field? Or a namespace name?
In fact, we have two problems here:
- We don't have OO support yet. We don't have instructions to create classes or to access .NET classes.
- We used tokens to simplify our reading. In general, the first character told us what the token was, but in some cases (like + and +=) we had to read the next character to know what to do. Even having isolated tokens, we still have a similar problem. In C#, if I have a class named
Console and a property named Console, I will only discover what I am really accessing after reading the next token, identifying if it is was accessing a static member or an instance member.
Well. To keep things simple, I wanted to avoid any kind of ambiguity. I wanted to read a token and know immediately if:
- It is setting a local variable
- It is referencing a class name, to then set a property
- It is referencing a full class name (namespace + type name) to call a method
- Or many other possibilities
In fact, to do that, I will end-up creating a very different language. I will probably have a language like this:
callstaticmethod Console.ReadLine();
setlocal x = 10;
Or anything similar to that, having to start every line by a keyword that told the compiler what the line should be doing. But I didn't want to change the language completely.
So, even if I can't discover everything from the very first token, I wanted to reduce ambiguity to make things easier and more organized. So I decided to use some good practices as rules:
- Use of
this. is mandatory to access members of the actual class - A lowercase name represents the access to a local variable. By the first rule, to access a field we must do
this.field instead of field directly - An uppercase name represents a class name. So
Console can't be a property - To access a type by its full name, we start by
namespace. So, System.Console will try to use a class named System. To access System.Console correctly, we must use namespace.System:Console - Ok, I already presented another rule. When accessing a namespace, a dot (.) represents an inner-namespace, while a colon (:) represents the class name
- When already accessing a local variable, like
this., the next item can be an upper-case name, to identify a property or a method, or a lower-case name to identify a field. OK, methods and properties can have conflicting names, but fields will never have conflicting names - This does not help the parser, but I decided that fields can be only
internal or private. So, it is mandatory to create properties to make the fields visible to the outside - To access
static members of the actual class, we must start by static.. So, we must always use "this." or "static." to access members of the actual class without retyping the class name - Casts are preceded by the
cast keyword, then there is the expression followed by a to or as and finally the type. The cast was one of the last things I added to the compiler and I didn't want to change the parsing of expressions completely. To me, an open-parenthesis has the only function of determining the order of evaluation, it is not a possible cast. Also, I really think C-style casts are ugly. The C++ dynamic_cast is much cleaner to me and I wanted an easy syntax. The cast to throws an InvalidCastException if the cast is invalid, while the cast as returns null if the cast is invalid - There are other rules... some of them that appeared as side effects by the way I did the parser. You will probably find them if you use the language.
Having all those ideas in mind (and writing some code, then revisiting it and changing things that are not quite right), the _ParseSingleOrMultipleInstructions is like this:
- If the token is a
{ (I call it OpenBlock), then we should call _ParseMultipleInstructions. Such method will check for a } and, if it is not such token, then will call an inner _ParseSingleOrMultipleInstructions - If it finds any of the keywords that are built-in types (like
object, string, long and so on), then it calls the Parser for a variable declaration, passing the right type for the new local - If it finds an
UpperName directly (this.Name start by "this" which calls another path), then it considers it as a type name. So, it call a method that will try to find that type and, maybe declare a variable, call a method or set a property. That's why it is another method to process it - If it is a
return, then it calls a method to parse the return. For a void method, the return should be followed by a semicolon (and will add the ReturnNoResult instruction to the method), but for a non-void method, the return must be followed by an expression - You may imagine that I must check that if the line starts by a
this keyword or by a lowername, it is a call to a local variable. In fact, there is no check for readonly variables and the this keyword works like a normal variable. You can assign another value to it (even if that usually only causes problems)
The other method that I consider very problematic, big and hard to understand is the parsing of expressions. What should happen by this:
return 1 + 2 * 3;
- In a stack based machine, the
1 will load the constant 1. As here every operation is over a local, I must create a local (even if temporarily) to put the value one in it - When the + sign is read, it does a sub-parsing (recursively calls the
_ParseExpression). It does not process the + directly - But, when parsing the Multiply, such multiply is done directly over the next value. This is what makes the
2 * 3 evaluate before the 1 - And possibly here is where a lot of optimizations should happen. After all, when I use "
1", I allocate a temporary local. But if I use "a", which is already a local, should I use it directly or should I allocate a new variable and copy the values? When only reading, I am sure I should use it directly... but I am sure I am creating excessive locals and maybe I can be changing the value of a local when I shouldn't (and that will be a bug).
A Brief Explanation On How to Implement The "if"
OK, explaining each one of the possible keywords is too much for an article. But then, not explaining any is too little. So, I will try to explain how the if works.
There are two main points in how the if works. First, we need to know exactly what it does, so, how it will need to look like in "assembler" instructions.
Then, we need to know how to parse the tokens.
So, let's see a simple example:
if (value)
{
}
In assembler instructions, let's consider that value is the local at index 1. It will look like:
GotoIfFalse 1, endInstructionIndex
Important Things to Note
The GotoIfFalse must know to which instruction index to jump. That depends on the number of assembler instructions in "Do something". To do that, as soon as we identify the if, we add the GotoIfFalse instruction, but we don't fill the InstructionIndex property. After parsing the if content, we set the index.
Noticed that I used the GotoIfFalse instruction? When the condition is if(true) we, in fact, do a goto if the condition is false. An instruction like "if (!value)" could be optimized as GotoIfTrue, but I don't optimize at this moment. I get the value, invert it and then call GotoIfFalse.
The method to do that simple if could be something like this:
void _ParseIf()
{
var token = NextToken();
if (token.Type != TokenType.OpenParenthesis)
throw new CompilerException("( expected.");
token = NextToken();
if (token.Type != TokenType.LowerName)
throw new CompilerException("A variable name is expected.");
var localDefinition = GetLocal((string)token.value);
var instruction = new GotoIfFalse { LocalIndex = localDefinition.Index };
_instructions.Add(instruction);
_ParseSingleOrMultipleInstructions();
instruction.InstructionIndex = _instructions.Count;
}
Well, it is similar, not the real code. In the real code, I check for an else after finishing the if. Considering an else exists, the GotoIfFalse will jump to the elses content, and at the end of the ifs content, it will need to add a goto to the end of the else.
I don't consider this to be real hard, but it is not easy either. The hardest part is debugging this code if something goes wrong, after all the instructions will be generated, and we will notice the error only when running.
I really hope the explanation of the if is enough to get the idea. The while is very similar to the if, but at the end of the block it does a goto to the beginning, re-evaluating the condition.
Compiling in Many Steps
I started by the method body. But when parsing a unit, the compiler should start by the outer declarations and then find the inner declarations.
I can't simply identify a method and start parsing it directly. I must first identify all the methods, so when parsing method A, if it calls method B, I should know that it exists (even if it was not parsed yet).
C, C++ and Pascal solve such problem by forward declarations. If method A comes before B and nothing told the compiler that it should exist, then it is an error.
But forward declarations are ugly. They increase the amount of code the programmer should write, they increase the number of validations done, as the forward declaration can have different parameters than the effective implementation. So, to make that work, as soon as I identify that I am processing a method, I "store" all their tokens without validating them.
To identify which are the tokens is very simple: If I find a semicolon (;) before finding an open-bracket ({), then the block ended. If I find an open-bracket, then I start counting the open-brackets and close-brackets. When the count reaches 0, the block ended. At that moment, it is not needed to know what the inner tokens are or if they are valid.
And, in fact, the method to identify the beginning/ending of blocks is not limited to method, it identifies any block, be it a type declaration, an inner namespace and so on.
The real unit parsing is like this:
- Identify Usings, Namespaces and Types. Usings are simply stored, types have only their header identified and are stored and Namespaces are further processed, identifying inner usings, namespaces and types.
- Validate usings. We already know all namespaces that exist, so it is possible to validate invalid usings.
- Identify all members that exist, validate their types (we already stored all types that exist) and store their bodies (for methods or properties).
- Now we finally start processing the method bodies. Now, if we see a reference to a field, method or property, we already know if such member exist, even if it is declared later.
- Even on the methods, we have many steps, as when starting an
if we already prepare the "goto" to the end of such if without knowing how many instructions we need to step over, as already shown. After processing the if body, the gotos are changed. - And at the final step, we correct the methods. When compiling, we are compiling a list of instructions that may be referencing a method that does not exist yet. So, the instructions that do those member references are created, with a
null member and, after finishing all the types, those instructions receive their real target.
DEBUG
To make the code debugable, the compiler must generate some extra information. Such extra information may be a separate list binding instructions to line and column indexes or the instructions may be changed to have that information.
I didn't want to change the IPolarInstruction interface because that will force me to change all already created instructions and will add unnecessary information for non-debugable code. I also didn't want to create a dictionary to bind instructions to line numbers. My solution was to create the _DebugableInstruction. Such instruction holds the debug information and a reference to the real instruction to be run. This way when compiling debugable code we have that extra information and the instruction will call the Debugging event and when compiling non-debugable code, we simply avoid it completely.
Then I changed all _instructions.Add lines in _MethodParser to call _AddInstruction which checks if it is generating debugable code (creating the _DebugableInstruction) or not.
Well, with that, we can already create break-points but that's not completely useful, as we don't have the possibility to check the call-stack of the running application or see its local variables.
So, I made the actual stack frame and the local values visible. We still don't have variable names, callstack navigation or member evaluation, but it's a start.
Conclusion
Maybe I am concluding this too soon. But I really believe the big point is the explanations. To see the code, it is better to download and analyze it. There are still many things missing in the language, there are probably better ways to do the parsing (I am not really used to creating parsers) but I did add some interesting things.
For example, the break allows a count to be passed [like break(2)], so you can break many fors/whiles and similar at once. When parsing, I stack/unstack a list of actions that add the right instructions for the break and continue. So I don't have a different parser for a for (that allows break) and for a normal method body. The same method (ParseSingleOrMultipleInstructions), when it finds a break, will call the _ParseBreak. If there are no breaks stacked, it throws a PolarCompilerException.
Method parameters can start by the required keyword. With that, if the parameter comes null, an ArgumentNullException will be thrown with the right parameter name. I already asked Microsoft to add such resource but they told me that it was impossible, because they compared it to the nullable types and told me that a new type with less values will not know how to auto-initialize itself... well, I am sure they understood my request wrong, because I was asking for a parameter modifier as I did here.
Maybe another time, I explain how those items work in more detail.
How to Use POLAR in Your Own Projects
POLAR is already made as a library. The Polarlight sample simply uses that library (Pfz.Polar, but Pfz is also required) and makes some classes accessible to the PolarCompiler. If you look at the code, you will see this:
var compiler = new PolarCompiler(unit, isDebugable);
compiler.AddDotNetType(typeof(Exception));
compiler.AddDotNetType(typeof(NullReferenceException));
compiler.AddDotNetType(typeof(Script));
compiler.AddDotNetType(typeof(Player));
compiler.AddDotNetType(typeof(Shot));
compiler.AddDotNetType(typeof(Asteroid));
compiler.AddDotNetType(typeof(Message));
compiler.AddDotNetType(typeof(AnimationList));
compiler.AddDotNetType(typeof(AsteroidList));
compiler.AddDotNetType(typeof(GameComponent));
compiler.Compile();
var method = compiler.GetCompiledMethod("Polarlight", "Program", "Main");
_virtualMachine.Run(method);
In fact, PolarCompiler and PolarVirtualMachine classes are all you need. You create PolarCompiler with a source-code and telling if it will be debuggable, add the .NET classes that it will have access to and then compile it.
After it is compiled, you can get a compiled method using GetCompiledMethod and, having a PolarVirtualMachine already created, you can run that method one or more times. Such method must be static, return void and should not receive any parameters.
And the Pfz and Pfz.Polar libraries already have the normal version and the Silverlight versions. I didn't do it, but I am sure they could be compiled for Windows Phone 7 by simply creating the appropriate project and adding all the source files.
Image Sources
I got the images used in POLAR from the internet.
The Polar-Bear image was from: http://gieseke.edublogs.org/files/2011/04/cute-22291jo.jpg.
And the Aurora Borealis was from: http://vector.tutsplus.com/tutorials/illustration/make-an-aurora-borealis-design-in-illustrator/.
History
- 28th November, 2011: Made the compiled code debugable and added background images
- 11th November, 2011: Added support for the numeric keypad and explained how
cast works - 7th November, 2011: Initial version

