Introduction
LINQ to SQL is a fantastic addition to .NET 3.0! It provides a type safe, powerful, and extremely flexible way to implement data access in .NET applications.
Unfortunately, using LINQ to SQL is not quite as straightforward when using it in a multi-tier database application. This article shows the typical pitfalls of implementing the data layer with LINQ to SQL, and provides a simple, convenient, and flexible way to circumvent most of them.
The generic base class for LINQ-to-SQL Database Abstraction Layers (DAL) that comes with this article has the following features:
- Implements the Repository pattern, allowing you to conveniently implement CRUD (
Create, Update, Delete) operations with less than ten lines of code per LINQ entity type. - Works seamlessly in disconnected LINQ mode.
- Supports transparent database updates of LINQ entity hierarchies in one single database roundtrip.
- As a convenience feature, it also writes all executed SQL statements to the output console when debugging your application.
Prerequisites
This article assumes that you have a basic understanding of what LINQ to SQL (also known as DLINQ) does and how it is used. If you don't, have a look at this tutorial first, then come back to this page to see how to use LINQ to SQL in multi-tier applications.
The Problem
LINQ to SQL is incredibly easy to use if you simply hook your UI layer directly to the database with LINQDataSource objects. But, that's not very object-oriented, and certainly not an advisable architecture. That is, unless you are coding a quick and dirty application and do not plan on extending it in the long run.
Instead, most developers divide their applications into several layers; for example, the following:
- Data Access Layer
- Business Layer
- UI Layer
This is known as a multi-tier database application design. LINQ to SQL would be used in the Data Access Layer.
The problem with LINQ to SQL is that – despite its many advantages – it's not very simple to use when implementing the data layer.
Have a look at the following database scheme:
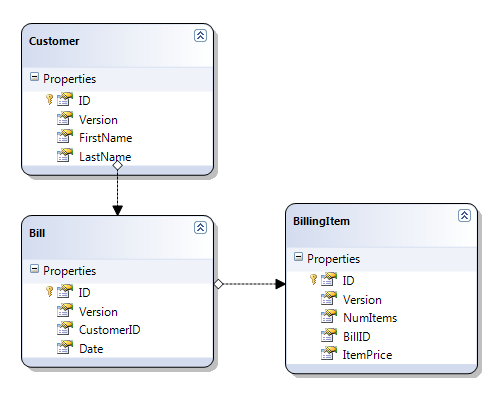
As long as you are loading and saving LINQ entities to the same data context instance (this is known as “connected mode”), implementing your data layer with LINQ is very straightforward.
For example, let's fetch the customer entity with ID==1 from the database, change its first name to “Homer”, and save it back to the database. In a multi-tier database application, the code might be somewhere in the UI or business layer, and will look like this:
CustomersRepository customersRepository = new CustomersRepository();
Customer customer = customersRepository.Load(2);
customer.FirstName = "Homer";
customersRepository.Save(customer);
The easiest way to implement the data layer Load and Save functions used above is this:
static DataClassesDataContext context=new DataClassesDataContext();
public Customer Load(int CustomerID)
{
return context.Customers.Single(c => c.ID == CustomerID);
}
public void Save(Customer toSave)
{
context.SubmitChanges();
}
This approach uses a connected LINQ mode: The data context never goes out of scope, so it can always be reused to save entities to the database which are still connected to it.
Granted, it is convenient, and works for the isolated example above. However, it has severe concurrency issues because one database context is used for all database operations: when calling Save(), SubmitChanges commits all changed entities, not just those related to the LINQ entity that the Save method received in the toSave parameter.
But, even setting this flaw aside, you can't implement the data layer in the same manner when using LINQ in a multi-tier ASP.NET application. Here, chances are that your LINQ entity is loaded with a page request, then updated and saved to the database with the next page request. Meanwhile, your original data context has gone out of scope, making your LINQ entity disconnected.
And, there are many other scenarios where you need to use a disconnected LINQ mode: for example, you might want to implement your database layer as a web service, commit previously serialized LINQ entities to your database, etc.
Implementing the Data Layer with Disconnected LINQ
So, how do we implement a data layer Save() method that works in disconnected LINQ mode?
We have to:
- Detach the entity from the old data context
- Create a new data context
- Attach the entity to the new context
- Submit changes
In source code, it looks like this:
public Customer Load(int CustomerID)
{
DataClassesDataContext context =new DataClassesDataContext();
return context.Customers.Single(c => c.ID == CustomerID);
}
public void Save(Customer toSave)
{
DataClassesDataContext context = new DataClassesDataContext();
toSave = EntityDetacher<Customer>.Detach(toSave);
if (toSave.ID==0)
{
context.Customers.InsertOnSubmit(toSave);
}
else
{
context.Customers.Attach(toSave,true);
}
}
Now, you can load and alter as many entities as you like, and only commit some of them to the database. But, due to using disconnected LINQ, this implementation does not account for associations between LINQ entities.
For example, imagine you want to do the following in your business or UI layer:
Customer customer = new CustomersRepository().Load(1);
customer.FirstName = "Homer";
Bill newbill = new Bill
{
Date = DateTime.Now,
BillingItems =
{
new BillingItem(){ItemPrice=10, NumItems=2},
new BillingItem(){ItemPrice=15, NumItems=1}
}
};
customer.Bills.Add(newbill);
new CustomersRepository().Save(customer);
The disconnected mode Save() method above would commit the change to the FirstName column, but simply forget about the new bill and billing items. In order to make it work, we also need to recursively Attach or Insert all associated child entities:
public void Save(Customer toSave)
{
DataClassesDataContext context = new DataClassesDataContext();
toSave = EntityDetacher<customer>.Detach(toSave);
if (toSave.ID==0)
{
context.Customers.InsertOnSubmit(toSave);
}
else
{
context.Customers.Attach(toSave,true);
}
foreach (Bill bill in toSave.Bills)
{
if (bill.ID == 0)
{
context.Bills.InsertOnSubmit(bill);
}
else
{
context.Bills.Attach(bill, true);
}
foreach (BillingItem billingitem in bill.BillingItems)
{
if (bill.ID == 0)
{
context.BillingItems.InsertOnSubmit(billingitem);
}
else
{
context.BillingItems.Attach(billingitem, true);
}
}
}
}
Not very complicated, but that's only for a trivial database scheme and one single entity type. Imagine you were implementing the database layer for several dozen entity types, with a few dozen foreign key relationships. You would have to write dozens of nested foreach loops for every single LINQ entity you need a DAL Repository class for. This is not only tedious, but also error-prone. Whenever you add a new table, you'd have to add a few dozen foreach loops to various DAL Repository classes.
A Solution: RepositoryBase
I implemented a class called RepositoryBase that you can use to quickly implement your data layer, that works fine with the examples shown above.
In order to use it, you must first instruct the Object Relational Mapper to generate serializable LINQ entities: open your DBML file in Visual Studio, left-click somewhere in the white area, and set “Serialization Mode” to “Unidirectional” in the “Properties” panel:

Now, you can derive from RepositoryBase to implement your own Repository:
public class CustomersRepository :
DeverMind.RepositoryBase<Customer, DataClassesDataContext>
{
override protected Expression<Func<Customer, bool>> GetIDSelector(int ID)
{
return (Item) => Item.ID == ID;
}
}
public partial class Customer
{
public static RepositoryBase<Customer,DataClassesDataContext> CreateRepository()
{
return new CustomersRepository();
}
}
Do this for each of your entity types, and you have a data layer working seamlessly in disconnected mode. Your derived Repository classes automatically implement the following methods:
As a small bonus, you can also see the SQL commands that were run against the database by ProviderBase, in your debug output console when debugging your application.
There's No Free Lunch...
There is no significant performance penalty for the Load operations, but there is a bit of Reflection going on behind the scenes when you are calling the Save or Delete methods.
For the vast majority of your DAL needs, this probably has no significant impact on your application. However, if you are performing a lot of update / insert / delete operations, especially with lots of nested child entities involved, then you might want to hand-code your own Save / Delete functions for the Repository classes of those child applications, as described above. All Save / Delete functions are virtual, so you can easily override them.
Also, please note that RepositoryBase does not support recursive save or delete operations with circular dependencies.
Conclusion
This article and the included source code provide a simple, convenient, and extensible way to implement your multi-tier LINQ data layer CRUD methods. It works in disconnected mode, and supports saving and loading of nested child entities. There is a small performance penalty on Save and Load operations, but you can override those for those Repositories where Save or Load performance is critical. For everything else, you're good to go with just a few lines of code.
If you have any questions, please let me know. And, feel free to stop by my blog for more development articles.
Version History
- 07 Oct. 2008 - V.0.1
- 26 Feb. 2008 - V.0.2
RepositoryBase now updates ID and version attributes of saved entities- Added support for multiple ID columns
Thanks!
Thanks to Kris Vandermotten for the handy DebuggerWriter component, which is used by RepositoryBase for the SQL debug output.

