Data Import Audit with SSIS
This article details with how to perform audits on merging data – checking for duplicates, and adding other validation rules, using SSIS. This method is much more efficient than writing validation code in VB or C#. I also recommend reading Deployment of Web Applications Executing SSIS Package in Web Server and Execute SSIS package (DTSX) from ASP.NET by Santosh Pujari.
Also, if you've found this article helpful, don't forget to vote/leave your comments.
Table of Contents
Data import validation is usually a pain – especially if you have to code all the validation rules, as I have in the past, using C#.
Enter SSIS.
This project goes through a simple data import, performs data validations including duplicate checking, outputs unique records, and logs errors.
While with a major SEO/SEM company, one of my past projects was to design a Yahoo! SSP (Search Submit Pro) / Paid Inclusions integration tool (using C# .NET 3.5, LINQ to XML, and LINQ to SQL) that took a list of URLs for a website, allowed content editors to generate content around them, and generate an XML data file to submit to Yahoo!. The most time consuming/tedious part of the development was writing the validation code, which included content validation in several fields, and of different keywords. Looking back at this project, this content validation could have been easily written with SSIS, and would have taken much less time.
Now, one of my projects requires similar, but less intensive validation, but still requires error logging for historical audits.
Requirements:
- SQL Server 2005 or 2008 with Business Intelligence Studio installed.
The first step is to create a test data set. For this, we want to test for null fields and duplicate records. In this case, a duplicate record will not only consist of identical user IDs, but a combination of both a user ID and a department.
After downloading article files, run TestDataset.sql to generate the data tables tbl_Errors, tbl_Users, and tbl_UsersMerge as well as the test dataset in tbl_Users.
Originally, I imported this from an Excel spreadsheet, easily done in a Data Flow, or other method.
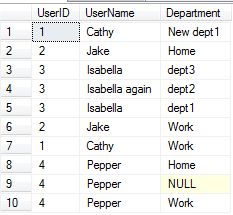
Now that the test data is loaded, the only real problem record we can see is row nine, which contains a null value for the department. We can test for duplicates by performing the data import again, once successful.
The process we will follow consists of the following:
- Create a connection to the test dataset.
- Add a Lookup Data Flow Transformation which will join on both the UserName and Department, which will render two lists – one of duplicate and one of unique records.
- Add a Conditional Split Transformation where we will write our validation rules.
- Add the appropriate error text to error records, recorded in the tbl_Errors table.
- Write all the data.

Now that we have the sample data loaded into a table, we will want to perform the data merge into a table that will contain the data set that the application will actually use, called tbl_UsersMerge.
Ensure that Business Intelligence Projects is installed/available on your system for this – usually done if you selected Integration Services on your SQL Server installation.
In Visual Studio, create a new project, select Business Intelligence (project type), then Integration Services Project (template).
Begin by dragging over a Data Flow task onto the Control Flow sheet. Clicking on the task’s text area will allow you to change its label.
Now, double-click on the task which will open the Data Flow sheet for this Data Flow Task.
Add an OLE DB Data source (drag it over) from Data Flow Sources, and double-click it. This will open the OLE DB Source Editor, where you will create a new connection (in Connection Manager) to your test database, and to the tbl_Users table, where our test dataset is stored.
Next, select all the columns after clicking on Columns.
First, it’s important to understand what the Lookup transformation does – it actually says so right on its editor screen: … enables the performance of simple equi-joins between the input and reference dataset.
Now, drag over a Lookup from the Data Flow Transformation section of the toolbox, and position this under the OLE DB Data Source. Click once on the data source to activate the red and green arrows, and drag the green arrow to the Lookup which connects the data source to the Lookup.
So far, that’s one data source connected to the Lookup. We still need to connect the reference dataset. Double-click on the Lookup Transformation, set its Cache Mode property to Full Cache. Next, set the connection to the database and use the table tbl_UsersMerge – this is the second dataset used for the joins.
Next, we want to set the columns to join on. Since we want to check for duplicates based on not just the UserName, but the UserName and Department, we will join on both of these fields.
To do this, click on Columns, where you will see two tables – Available Input and Lookup Columns.
Drag over the UserName and Department columns from the Input to the Lookup table, and select all the checkboxes in the Lookup Columns by clicking on the Name checkbox.
Next click on Error Output. This part is a little tricky, more in how you may initially expect for this to work.
Under the Error column for Lookup Match Output, click where “Fail Component” is indicated, opening a drop-down, and select “Redirect row”. What this does is creates an output data set for this condition.
Next drag over a Conditional Split Transformation and link the red error arrow from the Lookup to it.
Double-click on the Conditional Split and click on Output Name, creating a new condition, calling it Missing Data. Type (or just copy/paste the following) in the condition:
ISNULL([OLE DB Source].UserID) || ISNULL([OLE DB Source].Department) ||
LEN([OLE DB Source].Department) == 0 || ISNULL([OLE DB Source].UserName) ||
LEN([OLE DB Source].UserName) == 0
You can also grab the column names from the columns tree at the top left, and view a list of valid operators at the top right.
As you can see, we are performing several validation checks. Are some fields null or their lengths equal to zero? If any of these rules hold true, those matched rows will be redirected to a green arrow called “Missing Data” from the Conditional Split.
So, this takes care of invalid data, what about valid data? This output is created by setting the Default output name – set this to Valid Data.
Now drag over an OLE DB or SQL Server Destination and link the green Valid Data arrow from the conditional split to this. Use tbl_UsersMerge as the data destination, and under Mappings, connect matching fields from Available Input to Available Destination Columns (UserID, UserName, Department).
This step creates the connection to our output database, and since we have a few other operations to perform, we don’t want to keep opening/closing the connection.
Open the properties for the new connection, and set Retain Same Connection to true.
At this stage, we can grab valid data during data imports, but what about error logging?
Remember, we only connected the red arrow from the Lookup Transformation. We want to log the error type to the tbl_Errors table, which has two additional columns: Error (to list the error text), and Timestamp, which is a calculated GetDate() field.
The Lookup Transformation output does not yet contain the Error field. To add this column to the output, drag over a Derived Column Transformation, calling it “Add Duplicate Data Error Text”, and link the green arrow from the Lookup Transformation to it.
Double-click on the new Derived Column Transformation and add the “ErrorText” derived column, which has “Duplicate Data” as the expression. This is the error text that will be listed with the record.
Now, add an OLE DB or SQL Server destination, linking the green arrow from this transformation to it, using tbl_Errors as the connected table.
Under Mappings, link the Lookup and ErrorText fields to the destination table.
This completes the duplicate error logging, but we’re still missing error logging for missing data.
We performed our check for missing data in the Conditional Split Transformation, but only linked the valid data to a destination. We still want to record the rows that have invalid data.
Add a new Derived Column Transformation, calling it “Add Missing Data Error Text” and link the green “Missing Data” arrow from the Conditional Split Transformation.
Set the ErrorText expression to “Missing Data”.
Lastly, link up a new OLE DB or SQL Server Destination to the Derived Column Transformation’s green arrow, using the same configuration as the Duplicate Errors Destination (using tbl_Errors, and matching columns).
The first run (pressing F5) will render the following:
You can also view the data at run-time by right-clicking on an arrow, and select Data Viewers/Add/Grid.
The first run successfully places a row that contains a null Department value in the error table, and the other valid nine rows in the merge table.
Run the package again.
This time, you will notice that the one null valued row is still written to the error data, but since the other nine rows were already written to the merge table, they’re flagged as error/duplicate rows and inserted in to the error table.
Points of Interest
You can probably perform a merge on the Error Data and Duplicate Errors, but since I'm persisting the database connection, I don't think it's of any major consequence.
As most things go in development, this may not be the most optimal way of doing things, and I'm open to comments and suggestions, and hope this was useful for some.
History
None yet.

