Introduction
This is a simple probabilistic classifier based on the Bayes theorem, from the Wikipedia article. This project contains source files that can be included in any C# project.
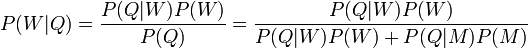

The Bayesian Classifier is capable of calculating the most probable output depending on the input. It is possible to add new raw data at runtime and have a better
probabilistic classifier. A naive Bayes classifier assumes that the presence (or absence) of a particular feature of a class is unrelated to the presence (or absence)
of any other feature, given the class variable. For example, a fruit may be considered to be an apple if it is red, round, and about 4" in diameter.
Even if these features depend on each other or upon the existence of other features, a naive Bayes classifier considers all of these properties to independently
contribute to the probability that this fruit is an apple.
Bayesian interpretation
In the Bayesian (or epistemological) interpretation, probability measures a degree of belief. Bayes' theorem then links the degree of belief in a proposition
before and after accounting for evidence. For example, suppose somebody proposes that a biased coin is twice as likely to land heads than tails. Degree of belief
in this might initially be 50%. The coin is then flipped a number of times to collect evidence. Belief may rise to 70% if the evidence supports the proposition.
For proposition A and evidence B,
- P(A), the prior, is the initial degree of belief in A.
- P(A | B), the posterior, is the degree of belief having accounted for B.
- P(B | A) / P(B) represents the support B provides for A.
Sex classification
Problem: classify whether a given person is a male or a female based on the measured features. The features include height, weight, and foot size.
Training
Example training set is shown below.
| sex | height (feet) | weight (lbs) | foot size (inches) |
|---|
| male | 6 | 180 | 12 |
| male | 5.92 (5'11") | 190 | 11 |
| male | 5.58 (5'7") | 170 | 12 |
| male | 5.92 (5'11") | 165 | 10 |
| female | 5 | 100 | 6 |
| female | 5.5 (5'6") | 150 | 8 |
| female | 5.42 (5'5") | 130 | 7 |
| female | 5.75 (5'9") | 150 | 9 |
The classifier created from the training set using a Gaussian distribution assumption would be:
| sex | mean (height) | variance (height) | mean (weight) | variance (weight) | mean (foot size) | variance (foot size) |
|---|
| male | 5.855 | 3.5033e-02 | 176.25 | 1.2292e+02 | 11.25 | 9.1667e-01 |
| female | 5.4175 | 9.7225e-02 | 132.5 | 5.5833e+02 | 7.5 | 1.6667e+00 |
Let's say we have equiprobable classes so P(male)= P(female) = 0.5. There was no identified reason for making this assumption so it may have been a bad idea.
If we determine P(C) based on frequency in the training set, we happen to get the same answer.
Below is a sample to be classified as a male or female.
| sex | height (feet) | weight (lbs) | foot size (inches) |
|---|
| sample | 6 | 130 | 8 |
We wish to determine which posterior is greater, male or female. For the classification as male, the posterior is given by:

For the classification as female, the posterior is given by:
The evidence (also termed normalizing constant) may be calculated since the sum of the posteriors equals one.
The evidence may be ignored since it is a positive constant. (Normal distributions are always positive.) We now determine the sex of the sample.
P(male) = 0.5
, where μ = 5.855 and σ2 = 3.5033e − 02 are the parameters of normal
distribution which have been previously determined from the training set. Note that a value greater than 1 is OK here – it is a probability density rather the
probability, because height is a continuous variable.
p(weight | male) = 5.9881e-06
p(foot size | male) = 1.3112e-3
posterior numerator (male) = their product = 6.1984e-09
P(female) = 0.5
p(height | female) = 2.2346e-1
p(weight | female) = 1.6789e-2
p(foot size | female) = 2.8669e-1
posterior numerator (female) = their product = 5.3778e-04
Since posterior numerator is greater in the female case, we predict the sample is female.
Using the code
DataTable table = new DataTable();
table.Columns.Add("Sex");
table.Columns.Add("Height", typeof(double));
table.Columns.Add("Weight", typeof(double));
table.Columns.Add("FootSize", typeof(double));
table.Rows.Add("male", 6, 180, 12);
table.Rows.Add("male", 5.92, 190, 11);
table.Rows.Add("male", 5.58, 170, 12);
table.Rows.Add("male", 5.92, 165, 10);
table.Rows.Add("female", 5, 100, 6);
table.Rows.Add("female", 5.5, 150, 8);
table.Rows.Add("female", 5.42, 130, 7);
table.Rows.Add("female", 5.75, 150, 9);
table.Rows.Add("transgender", 4, 200, 5);
table.Rows.Add("transgender", 4.10, 150, 8);
table.Rows.Add("transgender", 5.42, 190, 7);
table.Rows.Add("transgender", 5.50, 150, 9);
Classifier classifier = new Classifier();
classifier.TrainClassifier(table);
Console.WriteLine(classifier.Classify(new double[] { 4, 150, 12 }));
Console.Read();
public void TrainClassifier(DataTable table)
{
dataSet.Tables.Add(table);
DataTable GaussianDistribution = dataSet.Tables.Add("Gaussian");
GaussianDistribution.Columns.Add(table.Columns[0].ColumnName);
for (int i = 1; i < table.Columns.Count; i++)
{
GaussianDistribution.Columns.Add(table.Columns[i].ColumnName + "Mean");
GaussianDistribution.Columns.Add(table.Columns[i].ColumnName + "Variance");
}
var results = (from myRow in table.AsEnumerable()
group myRow by myRow.Field<string>(table.Columns[0].ColumnName) into g
select new { Name = g.Key, Count = g.Count() }).ToList();
for (int j = 0; j < results.Count; j++)
{
DataRow row = GaussianDistribution.Rows.Add();
row[0] = results[j].Name;
int a = 1;
for (int i = 1; i < table.Columns.Count; i++)
{
row[a] = Helper.Mean(SelectRows(table, i, string.Format("{0} = '{1}'",
table.Columns[0].ColumnName, results[j].Name)));
row[++a] = Helper.Variance(SelectRows(table, i,
string.Format("{0} = '{1}'",
table.Columns[0].ColumnName, results[j].Name)));
a++;
}
}
}
public string Classify(double[] obj)
{
Dictionary<string,> score = new Dictionary<string,>();
var results = (from myRow in dataSet.Tables[0].AsEnumerable()
group myRow by myRow.Field<string>(
dataSet.Tables[0].Columns[0].ColumnName) into g
select new { Name = g.Key, Count = g.Count() }).ToList();
for (int i = 0; i < results.Count; i++)
{
List<double> subScoreList = new List<double>();
int a = 1, b = 1;
for (int k = 1; k < dataSet.Tables["Gaussian"].Columns.Count; k = k + 2)
{
double mean = Convert.ToDouble(dataSet.Tables["Gaussian"].Rows[i][a]);
double variance = Convert.ToDouble(dataSet.Tables["Gaussian"].Rows[i][++a]);
double result = Helper.NormalDist(obj[b - 1], mean, Helper.SquareRoot(variance));
subScoreList.Add(result);
a++; b++;
}
double finalScore = 0;
for (int z = 0; z < subScoreList.Count; z++)
{
if (finalScore == 0)
{
finalScore = subScoreList[z];
continue;
}
finalScore = finalScore * subScoreList[z];
}
score.Add(results[i].Name, finalScore * 0.5);
}
double maxOne = score.Max(c => c.Value);
var name = (from c in score
where c.Value == maxOne
select c.Key).First();
return name;
}
The Classifier class is very easy to use, having two functions Train and Classify. To train the classifier, training data set
is created. The example shows how a set of data related to height, weight, foot-size is used to to classify sex.
Please let me know if better code is possible.

