Introduction
File streams were introduced in SQL Server 2008. They offer the capability to store binary data to the database but outside the normal database files. Earlier, varbinary used to be stored inside database files, which had many side-effects. Because SQL Server stores data in blocks, which are arranged as extents, the data in earlier varbinary columns had to conform to the block structure (although a bit different from normal data blocks).
In SQL Server 2008, if a varbinary column is defined to be stored as a file stream, the binary data is stored in a special folder structure, which is managed by the SQL Server engine. The only thing that remains inside the database is a pointer to the file along with a mandatory GUID column in order to use the file stream from the Win32 client.
File stream data can be used from the .NET Framework using the traditional SqlParameter, but there is also a specialized class called SqlFileStream which can be used with .NET Framework 3.5 SP1 or later. This class provides mechanisms, for example, for seeking a specific position from the data.
Advantages of storing binary data to the database
A typical question is: Why store binary data in a database? A very common solution is to store the actual data into the file system and only define a path or URL to the database pointing to the actual file. However, there are a few issues that should be considered.
- Backups: When data is stored apart from the database, it's not backed up by SQL Server. If these files need to be backed up, a separate mechanism must be created. This also means that these two backups are 'never' in-sync. For example, a file may be deleted when a SQL Server backup is made but the actual file is not backed up yet. When the data is stored to the database, the backup is consistent.
- Transactionality: When the file is stored outside the database, the file creation, modification, and deletion isn't part of the transaction which occurs against the database. This means that neither commit nor rollback actually guarantees that the result is consistent. When the data is stored inside the database, it's part of the transaction. So, for example, a rollback includes all traditional database operations along with binary data operations. This usually makes the client solution more robust with less code.
Setting up the database
This section describes how to create a test database capable of handling a file stream. The database contains two tables for comparing traditional varbinary columns against file streams. These scripts are provided in the sample project in the file named DatabaseCreationScript.txt. Note: Before using the script, modify the data file paths to suit your environment.
Also, remember that the filestream needs to be enabled in your SQL Server setup in order to use this feature.
Database creation
CREATE DATABASE [SqlFileStream] ON PRIMARY
( NAME = N'SqlFileStream',
FILENAME = N'C:\DATA\SqlFileStream.mdf',
SIZE = 500MB ,
MAXSIZE = UNLIMITED,
FILEGROWTH = 100MB ),
FILEGROUP [FileStreamData] CONTAINS FILESTREAM DEFAULT
( NAME = N'SqlFileStream_Data',
FILENAME = N'C:\DATA\FileStreamData\SqlFileStream_Data' )
LOG ON
( NAME = N'SqlFileStream_log',
FILENAME = N'C:\DATA\SqlFileStream_log.ldf',
SIZE = 500MB ,
MAXSIZE = 2048GB ,
FILEGROWTH = 100MB)
GO
The previous script creates a new database called SqlFileStream. When using file stream storage, you must specify the folder where the binary data will be placed. This folder is represented to SQL Server as a special file group defined to contain a file stream. The primary file and the log files are defined normally.
USE [SqlFileStream]
GO
CREATE TABLE [FileStreamTest] (
[Id] uniqueidentifier ROWGUIDCOL NOT NULL DEFAULT (NEWID()) PRIMARY KEY,
[Name] nvarchar(100) NOT NULL,
[Data] varbinary(max) FILESTREAM NOT NULL
)
GO
CREATE TABLE [VarbinaryTest] (
[Id] uniqueidentifier ROWGUIDCOL NOT NULL DEFAULT (NEWID()) PRIMARY KEY,
[Name] nvarchar(100) NOT NULL,
[Data] varbinary(max) NOT NULL
)
GO
The script creates two tables. The FileStreamTest table stores the binary data to the file stream. In order to use the data from the Win32 client, a GUID column must be present in the table. This GUID is actually used to identify the stored files in the file stream folder. The second table stores the binary data inside the database files (in this case, SqlFileStream.mdf). This table is used from the client program to test storage times against file stream data. A GUID column isn't mandatory in this case, although it's used by the client to identify a row.
Client program
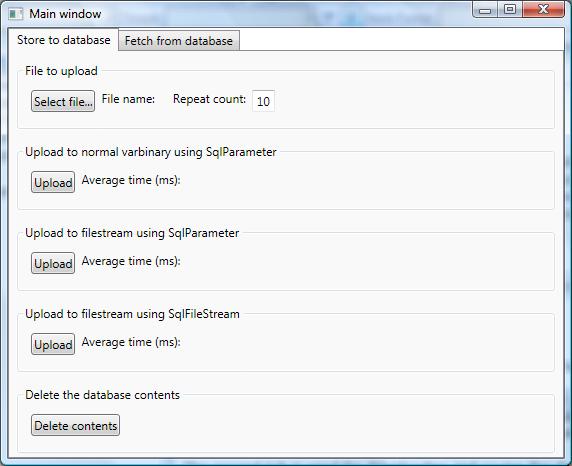
The client program is a simple WPF application. The first tab is used to upload the data with three different variations:
- Using a
SqlParameter, load the data to a traditional varbinary column - Using a
SqlParameter, load the data to a varbinary column stored as a file stream - Using a
SqlFileStream, load the data to a varbinary column stored as a file stream
During the upload, a single operation is measured, and if the upload is repeated using a repeat count, an average is calculated based on individual upload times. The second tab is used for downloading and saving the data back to a file with the same variations as when uploading.
The program consists of the main window and a static DbOperations class which handles all of the communication to the database.
Storing the data
The DbOperations class implements a method called StoreFileUsingSqlParameter to store the data to the database using SqlParameter. The code is the same whether a normal varbinary or a file stream is used, so this decision actually doesn't have any effect on the client. The code simply creates a command and sets the parameters. After that, the command is executed in a loop for a defined number of times.
command.CommandText = "INSERT INTO "
+ (tableType == TableType.Traditional ? "VarbinaryTest" : "FileStreamTest")
+ " ([Name], [Data]) VALUES (@Name, @Data)";
command.CommandType = System.Data.CommandType.Text;
parameter = new System.Data.SqlClient.SqlParameter("@Name",
System.Data.SqlDbType.NVarChar, 100);
parameter.Value = file.Substring(file.LastIndexOf('\\') + 1);
command.Parameters.Add(parameter);
parameter = new System.Data.SqlClient.SqlParameter("@Data",
System.Data.SqlDbType.VarBinary);
parameter.Value = System.IO.File.ReadAllBytes(file);
command.Parameters.Add(parameter);
The StoreFileUsingSqlFileStream method does the same thing, but this time, using a SqlFileStream. There are a few gotcha's when using the SqlFileStream.
When inserting a new row, the file storing the data for SQL Server should be created at the same time. However, if the column containing the file stream data is omitted in the INSERT statement, it's interpreted as NULL. In that case, the file is not created, and it would be harder to use the row afterwards. For that reason, the INSERT statement adds (0x) (empty data) to the varbinary column.
insertCommand.CommandText =
"INSERT INTO FileStreamTest ([Id], [Name], [Data]) VALUES (@Id, @Name, (0x))";
insertCommand.CommandType = System.Data.CommandType.Text;
Because the row is inserted first and the binary data is updated to the row afterwards, the program must start a transaction and fetch the transaction context that will later be used when an instance of SqlFileStream is created.
insertCommand.Transaction = connection.BeginTransaction();
helperCommand.Transaction = insertCommand.Transaction;
helperCommand.CommandText = "SELECT GET_FILESTREAM_TRANSACTION_CONTEXT()";
transactionContext = helperCommand.ExecuteScalar();
The row is first inserted as a normal row, but after that, a path to the file is fetched from SQL Server. This path, along with the transaction context, is used to initialize the SqlFileStream. Once initialized, the data is written to the SqlFileStream as a byte array. Note, the code is in different order in the program for efficiency.
helperCommand.CommandText = "SELECT Data.PathName() FROM FileStreamTest WHERE [Id] = @Id";
parameter = new System.Data.SqlClient.SqlParameter("@Id",
System.Data.SqlDbType.UniqueIdentifier);
helperCommand.Parameters.Add(parameter);
helperCommand.Parameters["@Id"].Value = insertCommand.Parameters["@Id"].Value;
filePathInServer = (string)helperCommand.ExecuteScalar();
sqlFileStream = new System.Data.SqlTypes.SqlFileStream(filePathInServer,
(byte[])transactionContext,
System.IO.FileAccess.Write);
sqlFileStream.Write(fileData, 0, fileData.Length);
sqlFileStream.Close();
Using the code
In order to use the code, you need to install a SQL Server instance and create the database and tables into it. After that, the SQL Server instance name and database name are configured via app.config. It would look something like:
...
<applicationSettings>
<TableValuedParameters.Properties.Settings>
<setting name="DataSource" serializeAs="String">
<value>SqlServerMachine\SqlServerInstanceName</value>
</setting>
<setting name="DatabaseName" serializeAs="String">
<value>SqlFileStream</value>
</setting>
</TableValuedParameters.Properties.Settings>
</applicationSettings>
...
Downloading
The download tab is used to fetch binary data from a single, user selected row. It uses the same techniques as the upload. The download tab is included for two reasons: to make sure that the data wasn't modified in any way, and to investigate fetching using SqlFileStream.
So, that's about it. Download the program, and use it freely to investigate the efficiency of these technologies using your setup and to explore the usage of a file stream.
History
- January 3rd, 2009: Created.
- December 11th, 2016: Code converted to Visual Studio 2015.

