Introduction
The Simple Object Collaboration Framework is a simple library that enables complex interactions between objects, possible by providing a new mechanism of instance discovery and lifetime management. It is an extension of the .NET CallContext or HTTPContext mechanism that provides a way of sharing objects within an execution code path.
What is Collaboration?
The OMG UML Specification defines a ‘Collaboration’ as follows:
Collaboration:
The specification of how an operation or classifier, such as a Use Case, is realized by a set of classifiers and associations playing specific roles used in a specific way. The collaboration defines an interaction.
Collaboration Diagram:
A diagram that shows interactions organized around the structure of a model, using either classifiers and associations or instances and links. Unlike a sequence diagram, a collaboration diagram shows the relationships among the instances. Sequence diagrams and collaboration diagrams express similar information, but show it in different ways.
UML treats collaborations as separate entities that are designed to perform a specific task, and groups them into two levels; Specification Level and Instance Level. Specification level collaboration defines a more general perspective of a repeating 'pattern' in a system. Design Patterns usually use collaboration diagrams to demonstrate the interaction between classifier roles instead of object instances. So you can just plug in the actual object instances at runtime.
How do collaborating objects find each other?
Although UML collaboration diagrams are very useful, there is an important missing information that they don't carry. First, they don't mention how objects discover each other in order to interact, and second, they don't mention how their lifetimes are managed. A sequence diagram, on the other hand, can illustrate the flow of events along a time axis, so it shows object lifetime as well, at least for a particular operation. However, a sequence diagram still doesn’t mention how the life time management is actually achieved. With .NET garbage collection and reference tracking, it seems lifetime management is just the responsibility of the runtime. But, the runtime can do it based on how you decide to reference your objects, or release them. So the life time management that is mentioned in this article specifically emphasizes the necessary responsibility assignment for objects to control the lifetime of other objects.
Following is a list of instance discovery mechanisms that are currently available in .NET:
- New instantiation.
- Local variables and parameters.
- Factory methods.
- Object relationships (Composition, Aggregation, or Association).
- Cache based (Static, ASP.NET cache objects like Session and Cache).
- Persistence (data access or serialization).
- Remoting
CallContext, HTTPContext.Current.
There are also some derivative mechanisms like Singletons, Dependency Injection Containers, and Identity Maps. But these aren't part of the .NET framework. You can find tons of code samples around these concepts.
Each of these mechanisms of discovering object instances also has object lifetime management implications. For instance, when you use local variables, you imply that the object lifetime should be limited to the current method scope. If you use some sort of compositional model, then the assumption is that the parent (or container) is responsible for controlling the lifetimes of its children. Caching mechanisms like Session and Application cache, or static variables, imply that the object’s lifetime is controlled by the cache. Session makes sure objects live at least as long as the user is active, and the Application cache or a static variable makes sure the object lives as long as the process lives.
The following diagram shows the caching scopes provided by ASP.NET:
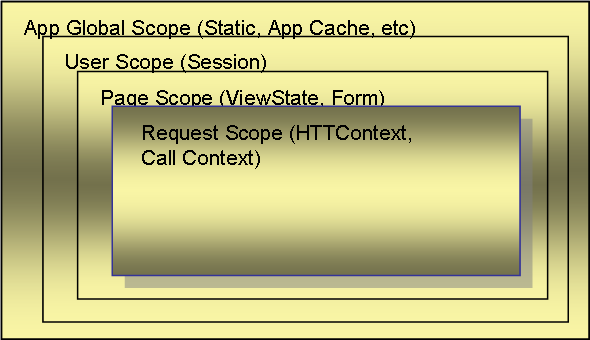
If you are developing complex line-of-business applications, chances are you've already used all or most of the above methods. Probably, the least known of them all are the CallContext and HTTPContext. These two provide a mechanism for creating a shared context that all objects can share during a method call (CallContext) or a single request (HTTPContext). Whatever you put into context has lifetime and instance sharing implications. Any object that you put into the HTTPContext will live at least until the current request completes, and will be accessible by any method call that is made within the current request and the current thread. CallContext is pretty much similar to HTTPContext. The main difference is that the CallContext is tied to the current thread while the HTTPContext is tied to the current HTTP request. Although ASP.NET can run one part of the code in one thread (like page init) and part of it in another (like page render), it makes sure that the HTTPContext is always properly migrated to the current thread. So, HTTPContext is much more reliable within ASP.NET than CallContext.
When objects are instantiated and put to those call contexts, their lifetimes are limited by the call. Of course, if you have other references to an object in the context, it will outlive the context. But the point is, the lifetimes are really controllable by this mechanism without having to explicitly write code for it. Just think about what you would have to do if you were to use Session instead of HTTPContext. You would either prefer not managing the lifetime at all and keep all the objects around until the session ends, or you would have to add when you need them and remove when you want to get rid of them. This would be a manual lifetime management task, which would probably be misused or forgotten in most cases. On the other hand, HTTPContext just makes sure that you don’t even need to think about neither the lifetime nor the sharing. It magically handles it all for you.
Why do we need contextual instance discovery?
If you aren’t still convinced that such shared and lifetime managed context mechanisms are really useful, here are some examples that you are probably using already with or without noticing that they are there:
- Transaction context (Enterprise Services transactions): The system automatically creates a transaction, shares it all for the whole call, and makes sure the transaction is either committed or rolled back when the call completes.
- Security context (Principal, Identity, Role): The system automatically makes security related information available for use during the call, and can also stop execution when security demand is not satisfied for some method call.
- Request/Response streams, Form data etc.: The system makes sure that incoming and outgoing message streams are available for all methods during an HTTP request.
- ASP.NET Trace: You can just log trace information during a call, and the system makes sure that all messages related to this page are accumulated in a central place specific to the request.
If such contextual sharing mechanisms weren't available, what would you do? Probably, you could use method parameters, or just set properties of your objects to let them know about such information. This means, you would have to write a lot of data transfer code, only taking parameters from one method and passing them to another. Either the class contract or the method contract would have to change as the system evolves, by adding more contextual information. But, imagine a system with many layers and a large object model. With the availability of call context, it is now possible to change such a system by just adding more information into the context and the consumer code that uses it at any method/layer. In an ASP.NET application, you could be calling a method that does 10 other nested calls, and you are still able to access the current transaction or the security context without having to pass those from one method to another. Isn’t that nice?
We can think of many other cases where we could use such contextual sharing of objects. Here are some examples:
- Validation context: Objects that contribute the same validation context could just do their validations and accumulate errors and warnings in a validation context object rather than throw single exceptions or return results. You could even have the validation context optionally, thus enabling validation logic to execute when such context is made available by the caller.
- Operation trace logging context: Objects that perform operations could log trace information that has more than just text messages. The calling code could investigate the log, and perform extra operations based on the logged information. Imagine that all operations within a transaction are logged into such a context object, you could do post transactional processing based on each entry in the log.
- Reducing DB roundtrips caused by on-demand object load, or any other costly object initialization, by reusing instances that are already in the context (Identity Map).
- Text message translation context that uses the current user's language to lookup localized message texts. When this context is made available, any layer would be able to do something like
UserLanguage.Translate(…). - Extending the behavior of sub-layers without having to change intermediary contracts: You could just add new extensions at any layer. Then, just change the client code that wishes to use this additional behavior, and provide a new context.
The list can go on and on. But, notice most of what we tend to think of are all operations that are orthogonal to the application’s main functionality. Indeed, this is a very good reason why we should prefer context objects rather than mess up with the application specific contracts. Thus, we can always keep the domain object model and all contracts clean and undisturbed by these orthogonal functions. The system could evolve vertically and horizontally with the minimal possible entanglement.
What's missing?
Although the CallContext and HTTPContext provide a pretty good way of handling context sharing, they give us a single shared context and single scope for managing object lifetime for the whole request. In other words, once you put something into CallContext, it'll be there until the request ends. Here's a nice article if you want to learn more about CallContext and HTTPContext. If only there was a way to generalize this same idea and make it more granular, and give the programmer the ability to just start a new context and control the sharing and lifetime of such contextual information. Well, now there is such a library: SOCF.
What is SOCF?
Simple Object Collaboration Framework (SOCF) is a lightweight framework that is based on CallContext and HTTPContext, and extends the concept to control object sharing and lifetime more granularly in a hierarchical fashion. Although it is based on a very simple idea and has a very compact library, it actually could create a new style of programming on the .NET platform. This new style of programming makes it possible to start a collaboration within a using() block, and allows all nested calls to access shared data in a strongly typed fashion. Collaboration contexts of the same type can be nested. When nested, some collaboration contexts just override the parent (like validation and logging), while others (like IdentityMap) can merge their content with the parents or delegate some of their behavior to the parent. A collaboration context object and all the objects cached in it live until the using block is exited. This provides more granular and explicit control over the scope and lifetime.
Following is a diagram that shows how the proposed mechanism extends ASP.NET caching as well as the HTTPContext request scope:

The red rectangles represent the new collaboration context objects that can be organized in a hierarchical fashion depending on how they are nested within the code execution path. For ASP.NET applications and Web Services, the collaboration context objects just use the more reliable HTTPContext.
For Windows applications, the same diagram actually becomes simpler:
For Windows applications, CallContext is a reliable way to handle thread specific data.
The attached source code includes a simple library that implements various collaboration context classes (Named, Typed, Custom, IdentityMap), and some sample code that shows how to use them.
This is a class diagram of the collaboration context model implemented by the SOCF:
Examples of using collaboration context entities
The attached sample code demonstrates a simple order processing system that relies on contextual object sharing to do collaboration. The simplest way to start collaboration is to just start a using block as follows:
using (var validation = new ValidationContext())
{
try
{
TestOrderConfirmation();
}
finally
{
validation.Dump();
}
}
TestOrderConfirmation performs multiple steps to process the order. Each step could be implemented in a service method, or some other handler object. The magic of collaboration context makes it possible to access the ValidationContext inside any nested call throughout the execution code path. Here's how you would access the validation context at any point in the code:
if (ValidationContext.Current != null)
{
if (order.Order_Details.Count == 0)
ValidationContext.AddError(order, "No order details!");
}
You could even call other methods that do their own validation, which should be treated entirely on their own. The collaboration context mechanism provided by SOCF ensures that there is only one current context object for a given type at any time. The last instantiated object just replaces any older instances. But, it also points back to the old instance. We'll call this old instance the super context or the parent context. If the context block shown in the example was nested within a different collaboration context of the same type, the following property would return the parent context (or super context):
ValidationContext.Current.SuperContext
Notice that the validation code within the order processing service is executed only when a ValidationContext is available. So, if you remove the using block, the system won't even do any validation. This is a good example of controlling orthogonal system behavior without having to change class contracts.
Another very common example of this kind of a context object is a logger. ASP.NET Trace behaves in a very similar fashion with the current request. However, it is only available within ASP.NET code. If you have a multi-layered architecture, you need to invent a similar mechanism. The example code actually provides one such logging context object which uses the proposed style of programming. So, you can just start a collaboration context for logging at any point in your code, like this:
using (var log = new LoggingContext())
{
try
{
TestOrderConfirmationWithAdditionalValidationContext();
}
finally
{
log.Dump();
}
}
And, inside any of the called methods, you can now access the logging context using:
LoggingContext.Add("Processing order");
The implementation of the LoggingContext makes sure that there is a logging context before actually processing it. So, it is up to the client to decide whether the logging should be done or not. The rest of the system doesn't have to change. And notice, this is all done without changing any class contracts, and without affecting or being affected by other running threads. All related messages will be accumulated into one log object, and later dumped out to the debug window, or could be used to log into the standard Trace output. If you were to use the Trace output, all the parallel running code in other threads would put their messages at arbitrary times into the log, and you would see the result as an interwoven sequence rather than a contiguous one. The LogginContext, on the other hand, makes sure all the messages are related to the operations of the currently executing code path and only enclosed by the logging context.
Following is a sequence diagram that illustrates the order and life time of collaboration context objects as well as their accessibility from each method.
Blue lifelines represent method scope. The red lifelines represent collaboration contexts started by methods. Dashed arrows pointing backwards represent what a method can access (not method return). So, the method that is at the deepest level of nesting can access all collaboration contexts enclosing its call.
How to implement your own custom collaboration context?
SOCF allows you to create your own custom collaboration entities. Here's a sample ConfirmationCollaboration object that is taken from the sample code:
public class OrderConfirmation : CustomCollaboration
{
public Customer Customer { get; set; }
public Order Order { get; set; }
public IEmailService EmailService { get; set; }
public static OrderConfirmation Current
{
get { return Get<OrderConfirmation>(); }
}
}
Here’s how the class diagram for this collaboration entity looks like:
Contrary to Logging and Validation context, the OrderConfirmation represents a domain specific collaboration. So, it is not orthogonal to the tasks performed. Usually, object models contain only entities and services, but don't have higher level abstractions that are built on top of them. I think this is mostly caused by a sense of economy against class explosion. You already have a lot of entities, services, and perhaps, many other generated classes to fill your project. Don’t you? Why add more classes? But, if you think about it, the above class is actually just a contract that could be shared. So, instead of passing the same set of objects from one method to another, you could just create a class, put all the necessary objects there, and pass a single object around. That would make the code briefer, much more readable, and controllable. Of course, if you take it to an extreme, it could also be dangerous. You could just start using the same contract for every method. So, there is a tradeoff between brevity and precision. Either you'll design all your methods precisely to accept parameters that they require, or have a single object to use as a contract for a well known set of operations that usually go together. If you have a complex object model, you may prefer the latter. Effectively, what we are doing is just defining the set of objects that will contribute to a particular domain specific collaboration.
Furthermore, with the usage of a simple collaboration framework, we are now able to provide a collaboration context accessible to all the methods in the execution path. So, we don't even have to pass it as a parameter. This is pretty much similar to the ASP.NET Request or Response objects. We already know that we'll be using Request and Response during the processing of a request, so there's no point of passing the same objects to every single method in the code. These are just made available by the runtime, and your code can access them at any time, in any method. Similarly, we can do the same with OrderConfirmation, except we can also control when it starts and when it ends:
using (var orderConfirmation = new OrderConfirmation())
{
...
orderConfirmation.Order = order;
orderConfirmation.Customer = customer;
orderConfirmation.EmailService = new EmailService();
...
InitialValidate();
Calculate();
CompleteOrder();
Validate();
InsertOrder();
SendConfirmation();
}
Inside the ConfirmOrder service method, the first thing we do is to start a collaboration context. We then prepare the contents of the collaboration context object by setting its properties. This could also be done using the object initializer syntax of C# 3.0. After this point, we just do calls to methods to do processing without passing any parameters. Those methods could also be implemented by separate handler classes. The methods that perform the processing steps can easily access the order confirmation and use all the objects that contribute to the collaboration. They could even talk to each other and handle events. Imagine a transaction object that is in the collaboration context that can trigger events when it is committed or rolled back. Any object that is part of this collaboration could handle those events and perform extra steps based on the transaction result. In an ordinary transaction handling code, objects that are used in the transaction have no idea what happens to the transaction after they are persisted. Problem is, they could have changed their state during persistence, but the transaction could have rolled back after those changes. Existing transaction mechanisms don't allow code to compensate for such cases. The proposed programming style can be used to give objects the ability to contribute to the handling of transactions. Following is just a pseudo code that shows how it would look like:
SaveOrder
{
TransactionContext.Current.OnRollback +=
new EventHandler(transactionRolledBack);
...
void transactionRolledBack(object sender, EventArgs args)
{
}
}
IdentityMap
The SOCF library also provides a simple implementation of a generic identity map. An identity map allows you to cache objects by a key and retrieve them. An identity map pattern is usually employed for objects that are costly to initialize (like entities loaded from a database, or received from a service) and are also large in number. Generally, identity map implementations don’t care about the mentioned contextual handling of the map. The simple generic identity map provided by the SOCF is actually a custom collaboration entity that also does contextual handling.
You can start an identity map context for a type at any point in your code, and all the code that is enclosed will just be able to access objects in this local scope.
using (var map = new IdentityMap<Product>(IdentityMapScope.Local))
{
...
You can now use the identity map within this block and all its nested calls. To set an object by key into the identity map, use:
IdentityMap<EntityType>.Set(key, entity);
Here’s an example:
IdentityMap<Product>.Set(productID, new Product()
{ ProductID = productID, ProductName = "Product " +
productID.ToString(), UnitPrice = productID * 10 });
To get an object from the identity map:
IdentityMap<EntityType>.Get(key);
Here’s an example:
Product product = IdentityMap<Product>.Get(productID);
You can even nest such identity map blocks:
using (var map1 = new IdentityMap<Product>(IdentityMapScope.Local))
{
...
using (var map2 = new IdentityMap<Product>(IdentityMapScope.AllParents))
{
...
The nested block could be in the same method like the one shown above, or in a nested method call. Each identity map manages its own objects, and has a lifetime controlled by its using block. When you set an object into the identity map, it’ll use the last started context to cache the object. But, when you get an object, you can decide how the identity map should search for it. This is determined by the scope parameter that you pass to the constructor called when you start the identity map. Scope = Local means that the identity map should only search for its own cached objects. Scope = Parent means that the identity map should search for its own cached objects first, but if it can’t find the object, it should continue searching its immediate parent identity map. In other words, it’ll search the identity map that encloses the current one. This is similar to class inheritance, except here, the inheritance behavior is determined by the execution path. So, the parent could be different in one method call than the other depending on how the program flows. Scope = AllParents means that the identity map should search for its own cached objects first, but if it can’t find the object, it should continue searching up the chain of parents one by one until there is no more parent, or the parent is allowed to use a local scope.
Notice that the search behavior can be determined by both the starter of the identity map and its nested identity maps. So, if you want to prevent the usage of a possibly existing parent identity map context, you can just start a new one and pass Scope = Local. Any access to this scope from this method or from nested identity maps will be restricted by the current scope.
Also note that each type has an entirely separate identity map management. So, when you nest identity maps, you don't need to consider the possible effects of identity maps of other types, because they have no effect at all.
The sample code contains a separate test class that shows examples of using the identity mapping collaboration context entity with and without nesting.
Using SOCF in ASP.NET or in Web Service projects
SOCF uses a provider model to abstract the access to the underlying call context technology. The default implementation just uses the Remoting CallContext class. If you want to use this library in an ASP.NET application or a Web Service project, you must make sure that the correct context provider is set. You can do this by setting a static property in the Global.asax Application_Start event:
protected void Application_Start(object sender, EventArgs e)
{
CallContextFactory.Instance =
new CallContextProviderForASPNET.CallContextProviderForASPNET();
}
Pitfalls of having too much contextual dependency
This concept is very powerful, and can be used very effectively, if used properly. As with any powerful tool, you can get much more benefit than harm by recognizing the potential pitfalls.
- Avoid using the collaboration context in place of method parameters in simple scenarios:
If you use the collaboration context excessively, it will only make the system very loose and fragile. Don't forget that contextual information is only available when the caller decides to provide it. So, they are more like optional parameters than parameters. The collaboration context approach is most useful for sharing objects that represent an orthogonal concern. This type of use is more obvious (logging, transactions, etc). But, it can also be used to create a common single point of access to all objects for a given task. This type of usage actually creates an implicit contract. For simple tasks that are also expected to stay simple, you had better just use conventional ways of passing objects around. On the other hand, a collaboration context will be very useful for complex models having multiple layers, or a pipeline style of processing, and will make things simpler, remain simpler, and also enhance extensibility. Such systems can be evolved by just adding code that starts collaborations, and code that consumes those collaborations only at the points of interest without touching the rest of the system.
- Avoid potential misuse of roles:
Always remember that objects are placed into the call context for one purpose, and are available for all the nested calls, where as parameters would only be available for a particular method call. One object put into the context has a specific role, and if indirect calls to other code don’t assume this, it will probably not function correctly. This is just like having a parameter but using it for a different purpose than what it was originally intended.
- Be careful about what you’re putting into the context:
Any object that you put into context will be kept alive with all of its strong references to other objects. For instance, if you have loaded a LINQ-to-SQL data object with some of its relationships, you should be aware that these related objects will also be alive as long as the object you put to session is alive. Try to keep the lifetime of such context objects as minimal as possible. In the case of IdentityMap, since the whole point is to reduce the cost of a database roundtrip or some other object initialization, you may actually want the objects around as long as possible. But still, you need to keep in mind that, not only the object but the whole object graph will be sitting in the context. In brief, you should either keep small object graphs in the context, or make sure that contexts with large object graphs have a short lifetime.
Disclaimer
Please note that the SOCF library code has not been tested under heavy load. The purpose of this article is just to propose a new style of programming. So, if you decide to use it in a commercial project, make sure you test it thoroughly on the platform that you are developing. Also, please don't forget to put your feedback on either the technical or conceptual aspects.

