Introduction
The Open Source Computer Vision Library (OpenCV) offers freely available programming tools to handle visual input such as images, video files, or motion data
captured by a camcorder. It contains numerous ready-to-use functions for a wide range of applications. Since the author of this piece of information is only at
the beginning of discovering this world and due to the great number of features OpenCV provides, the contents of this article will be confined to a small selection of topics.
Although one can find instructions on how to use OpenCV and many code samples, to me it seemed that useful information is spread all over the web and thus hard to
track down. It is the intention of this article to provide a more coherent picture and offer guidance for some OpenCV basics.
I am mostly interested in video processing and analyses of motion. For this reason the article discusses OpenCV functions for loading and playing video files, it
gives some examples of how this data can be manipulated and it presents (possibly ‘immature’) sample code that shows how to set up such procedures. Although the OpenCV function
calls introduced here are pure C code, I packed them into a single C++ class. This might not seem very elegant but I considered it convenient to have most of the OpenCV
specific code at one place. In order to be able to implement a Windows GUI, I built a Win32 program around the OpenCV code using Visual C++ 2010 Express Edition.
The contents presented here and in the source code files are based on code snippets found on the web, on samples that come with the OpenCV set up, and partly on the
book ‘Learning OpenCV’ by Gary Bradski and Adrian Kaehler.
In order to create an executable program, the OpenCV2.3 libraries (http://opencv.willowgarage.com) have to be installed
and it is necessary to include the correct libraries and header files. This requires some instructions to be followed, which are described on top of the UsingOpenCV.cpp source
code file. Detailed descriptions (including pictures) on how this needs to be done can be found on the web also (e.g., by searching for ‘Using OpenCV in VC++2010’).
The article is divided into three parts. In the first section I will explain how to load and play a video file. Section two and three will build on this but also add further information on
pixel manipulation, frame subtraction, and optical flow.
Load and Play Video Files
OpenCV provides several functions for loading and playing video files. These have to be called in a relatively strict order (also be sure that corresponding video codecs
are installed on your computer).
In order to capture frames (i.e., single images) from a video file, it is necessary to use the command line CvCapture* cvCreateFileCapture(const char* filename ); first.
It provides a pointer to a CvCapture structure (returns NULL if something went wrong). In the sample code I wrote, this function is embedded in the class method
bool Video_OP::Get_Video_from_File(char* file_name);.
Once there is a valid CvCapture object, it is possible to start grabbing frames using the function IplImage* cvQueryFrame(CvCapture capture),
which returns a pointer to an IplImage array. How this needs to be implemented will be explained below on the basis of sample code.
In order to access the properties of a video file (e.g., length, width of a frame, etc.), use cvGetCaptureProperty(CvCapture* capture, int property_id);.
Sample code on how to apply this can be found in the class methods int Video_OP::Get_Frame_Rate(); and int Video_OP::Get_Width();.
In order to set various properties of a video file (e.g., starting frame), use cvSetCaptureProperty(CvCapture* capture, int property_id, double value);. Sample code on how
to change the starting frame can be found in the class method int Video_OP::Go_to_Frame(int frame).
Using the Code
The main steps to load and play a video file are:
- Capture a video file with
cvCreateFileCapture(); by invoking this->Get_Video_from_File(char* file_name);. - Invoke
this->Play_Video(int from, int to); with from being the starting frame and
to the stopping frame (find the insides of the method in the skeleton code below). - Determine frame rate of video, create window to depict images, and push video forward to
a frame from which you want it to start.
- Set up loop to process successive frames (or images) of a video file.
- Grab frames by calling
cvQueryFrame(CvCapture*);. - Depict images in a window by calling
cvShowImage(char*,IplImage);. - Define the delay of presentation by invoking
cvWaitKey(int);.
The example in the file (OpenCV_VideoMETH.cpp) has the same structure as the code below, but also has some lines added, which gives further information.
void Video_OP::Play_Video(int from, int to)
{
this->my_on_off = true;
int key =0;
int frame_counter = from;
int fps = this->Get_Frame_Rate();
cvNamedWindow( "video" , CV_WINDOW_AUTOSIZE );
this->Go_to_Frame(from);
int frame_counter = from;
while(this->my_on_off == true && frame_counter <= to) {
this->my_grabbed_frame = cvQueryFrame(this->my_p_capture);
if( !this->my_grabbed_frame ) break;
cvShowImage( "video" ,my_grabbed_frame);
frame_counter++;
key = cvWaitKey(1000 /fps);
}
cvReleaseCapture( &my_p_capture );
cvDestroyWindow( "video" );
}
...
Pixel Manipulation and Frame Subtraction
Explanations in this section provide information about a selection of OpenCV commands that can be used for image manipulation. I present a simple way of
accessing single pixels, how to subtract successive frames, how to draw onto an image, and give an idea for which kind of applications this might be useful.

Using the Code
The basic structure of the code presented in the following builds on the sample shown in the first section. I just explain the most important parts that have been
added. For details and a better understanding, also study the file OpenCV_VideoMETH.cpp.
The most important steps in the code sample below are:
- Grab a frame using
cvQueryFrame(cvCapture);, clone this frame, and turn it into a grey-scale image. - Set up loop to process successive frames.
- Grab next frame and also turn it into a grey-scale image.
- Subtract grey scale frame grabbed first from the grey scale frame grabbed afterwards (see
cvAbsDiff(CvArr *src,CvArr* src2,CvArr *dst);) . The result yields
a grey-scale image with different levels of grey (i.e., 0 is black and 255 is pure white) at the spots where a change in pixel color between frame(t) and the previous frame(t-1)
has taken place. In other words, these changes give an estimate of the motion occurring. - Search the image arrays for pixel values above a certain threshold (here 100) by invoking
cvGet2D(CvArr*,int,int);. - Calculate mean x-positions and mean y-positions of the pixels found and draw a circle at that spot.
- Clone the grabbed frame, thereby storing its information for the next subtraction (i.e., frame(t) becomes
the new frame(t-1)).
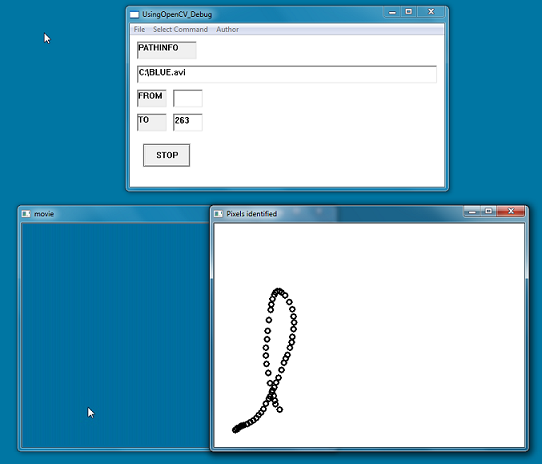
As already shown in the first section, the program runs through a video file stepwise (i.e., frame by frame) but this time it also subtracts each single frame from its
predecessor. This is a simple technique to give a rough estimate of the amount of motion that has occurred between two frames. Also, it is possible to track
the path along which a single object moves (as it is done here by determining the average position of the pixels above a certain threshold; see pictures
above and on top of page). For some applications, this might suffice, but if it is necessary to track the path of several objects, only a more elaborated
methodology will do the job. It will not be discussed here (admittedly, I am not yet familiar with it), but the OpenCV library even offers solutions for such
complex problems (e.g., algorithms to detect blobs).
void Video_OP::Subtract_Successive_Frames(int from, int to)
{
CvScalar color_channels;
this->my_grabbed_frame = cvQueryFrame(this->my_p_capture);
cvCvtColor(this->my_grabbed_frame, first_frame_gray, CV_RGB2GRAY );
cloned_frame =cvCloneImage(first_frame_gray);
while(this->my_on_off == true && frame_counter <= to) {
my_grabbed_frame = cvQueryFrame( my_p_capture);
cvCvtColor(my_grabbed_frame, running_frame_gray, CV_RGB2GRAY );
cvAbsDiff(cloned_frame,running_frame_gray,subtracted_frame );
for ( double i = 0; i < subtracted_frame->width; i++){
for ( double u = 0; u < subtracted_frame->height; u++)
{
color_channels = cvGet2D(subtracted_frame,u,i);
if( color_channels.val[0] > 100){
pixel_count++;
sum_x += i;
sum_y += u;
}
}
}
mean_x = sum_x/pixel_count;
mean_y = sum_y/pixel_count;
if (mean_x < subtracted_frame->width && mean_y < subtracted_frame->height)
cvCircle(pixels_frame, cvPoint(mean_x,mean_y ),4,cvScalar(0,255,0,0), 2,8,0);
cvShowImage("subtraction",subtracted_frame);
cvShowImage( "movie", my_grabbed_frame );
cvShowImage("Pixels identified",pixels_frame);
cloned_frame = cvCloneImage(running_frame_gray);
key = cvWaitKey( 1000 / fps );
}
}
...
Optical Flow
In the example above, I presented code that filters changes in pixel color between two frames. These changes can be used to assess the amount of motion and find out where
something interesting is happening. The code in this section will be based on this and present an alternative (and more refined and complicated) methodology to detect and analyze motion.
Optical flow is a way to trace the path of a moving object by detecting the object’s position shifting from one image to another. This is mostly done by the analyses of pixel
brightness patterns. There are several methodologies to calculate optical flow, but in this article I only provide code based on the Lucas-Kanade
method. Since I am not an expert on the underlying mathematics and the insides of the applied functions, I do not elaborate on such details. I only give a very
superficial description of how it works and focus on the OpenCV functions that have to be invoked to create a useable program. If you feel a
need for more information, you may find it in an expert article or a book dealing with such topics.
The Lucas Kanade algorithm makes three basic assumptions. First, the brightness of a pixel (i.e., its color value) remains constant as it moves from
one frame to the next. Second, an object (or an area of pixels) does not move very far from one frame to the next. Third, pixels ‘inhabitating’
the same small area belong together and move in a similar direction.
One problem of such a procedure is to find good points to track. A good point should be unique, so it is easy to find it in the next frame of a movie (i.e., corners mostly
fulfill such requirements). The OpenCV function cvGoodFeaturesTrack() (based on
the Shi-Tomasi algorithm) was built to solve this problem and the obtained results can be further
refined by cvFindCornerSubPix();, which takes accuracy of feature detection to the sub-pixel level.
The functions needed for the example below have numerous parameters, which will not be explained in great detail. Please read the comments in OpenCV_Video_METH.cpp,
study a book on OpenCV or an OpenCV documentation for more information.
Using the Code
The most important steps in the code sample below are:
- Define a maximum of points (or corners) for the Shi Tomasi algorithm (will be overwritten with the number of corners found after
cvGoodFeaturesToTrack(); is left). Also
provide an array to store the points the function finds. - Define image pyramids for the Lucas-Kanade algorithm. Image pyramids are used to estimate optical flow iteratively by beginning at a more or less coarse level of analysis and refining
it at each step.
- Call
cvGoodFeaturesToTrack();. The function needs the image to be analyzed in an 8 bit or 32 bit single channel format. The parameters eigImage
and tempImage are necessary to temporarily store the algorithm’s results. Similarly, a
CvPoint2D32f*
array is used to store the
results of corner detection. The parameter qualityLevel defines the minimal eigenvalue for a point to be considered as a corner. The parameter minDistance is
the minimal distance (in number of pixels) for the function to treat two points individually. mask defines a region of interest and blockSize
is the region around a pixel that is used for the function’s internal calculations. - Call
cvFindCornerSubPix();. Pass the image array to be analyzed and the
CvPoint2D32f*
array, which has been filled with values found
by the Shi Tomasi algorithm. The parameter win defines the size of the windows from which the calculations start.
CvTermCriteria defines the criteria for termination of the algorithm. - Draw tracked features (i.e., points) onto the image.
- Set up loop for processing frames of the video.
- Call
cvCalcOpticalFlowPyrLK();. The most important parameters of this function are:
the previous frame, the current
frame (both as 8 bit images in the example here), an identical pyramid image for the current and the previous frame, the CvPoint2D32f* array,
which has been filled with the points identified as good features, and an additional CvPoint2D32f* array for the new positions of these points.
Furthermore, winSize defines the window used for computing local coherent motion. The parameter level sets the depth of stacks used for the image pyramids (if set
to 0, none are used), and CvTermCriteria defines the criteria for termination of the computations. - Draw a line between points of the former frame (stored in the
CvPoint2D32f* array) and their new positions in the current frame. - Turn data of the current frame into ‘previous’ data for the next step of the loop.
void Video_OP::Calc_optical_flow_Lucas_Kanade(int from, int to)
{
const int MAX_COUNT = 500;
CvPoint2D32f* points[2] = {0,0}, *swap_points;
char* status = 0;
pyramid = cvCreateImage( cvGetSize(running_frame), IPL_DEPTH_8U, 1 );
prev_pyramid = cvCreateImage( cvGetSize(running_frame), IPL_DEPTH_8U, 1 );
points[0] = (CvPoint2D32f*)cvAlloc(MAX_COUNT*sizeof(points[0][0]));
points[1] = (CvPoint2D32f*)cvAlloc(MAX_COUNT*sizeof(points[0][0]));
IplImage* eig = cvCreateImage( cvGetSize(grey), 32, 1 );
IplImage* temp = cvCreateImage( cvGetSize(grey), 32, 1 );
double quality = 0.01;
double min_distance = 10;
count = MAX_COUNT;
cvGoodFeaturesToTrack(prev_grey, eig, temp, points[0], &count,quality, min_distance, 0, 3, 0, 0 );
cvFindCornerSubPix( prev_grey, points[0], count, cvSize(win_size,win_size), cvSize(-1,-1),
cvTermCriteria(CV_TERMCRIT_ITER|CV_TERMCRIT_EPS,20,0.03));
cvReleaseImage( &eig );
cvReleaseImage( &temp );
for (int i = 0; i < count; i++)
{
CvPoint p1 = cvPoint( cvRound( points[0][i].x ), cvRound( points[0][i].y ) );
cvCircle(image,p1,1,CV_RGB(255,0,0),1,8,0);
}
cvShowImage("first frame",image);
status = (char*)cvAlloc(MAX_COUNT);
while(this->my_on_off == true && frame_counter <= to) {
cvCalcOpticalFlowPyrLK( prev_grey, grey, prev_pyramid, pyramid, points[0], points[1], count,
cvSize(win_size,win_size), 5, status, 0,
cvTermCriteria(CV_TERMCRIT_ITER|CV_TERMCRIT_EPS,20,0.03), flags );
for( int i=0; i < count; i++ ){
CvPoint p0 = cvPoint( cvRound( points[0][i].x ), cvRound( points[0][i].y ) );
CvPoint p1 = cvPoint( cvRound( points[1][i].x ), cvRound( points[1][i].y ) );
cvCircle(prev_grey,p0,1,CV_RGB(0,255,0),1,8,0);
cvCircle(grey,p1,1,CV_RGB(0,255,0),1,8,0);
cvLine( image, p0, p1, CV_RGB(255,0,0), 2 );
}
prev_grey = cvCloneImage(grey);
CV_SWAP( prev_pyramid, pyramid, swap_temp );
CV_SWAP( points[0], points[1], swap_points );
key = cvWaitKey(40);
}
}
Points of Interest
If you want to see how all this looks like in a real application, please download the UsingOpenCV.exe file, install the necessary DLLs (see UsingOpenCV.cpp),
load the example video, and see what happens when applying the different commands. The example video is very simple. It produces
little noise and thus ‘beautiful’ results, but it perfectly does what it has been created for. It gives a good impression of how the code works.
There is no guarantee that the examples are free of bugs and there are parts that surely can be ironed out. I also sometimes defined unnecessary variables, in order to provide
more clarity (hopefully).

