Introduction
Building effective reader/writer synchronization objects is an important issue when developing multi-threaded applications. Its importance increases along with the development and spreading of multiprocessor/multi-core computing platforms.
An important case of this problem is a scenario where one or two writers compete with multiple readers. This scenario is simpler than the general reader/writer problem. But, if a high lock contention occurs, performance may not be acceptable even when using the new superior Windows Vista SRWLOCK and when the writer's performance matters [1]. We will be looking for a solution that compromises between maximum performance of multiple readers (as SRWLOCK does) and an acceptable performance of a writer (as, for example, RWLockFavorWriters [2] does).
The development of such an efficient and integral locking algorithm is hard. Instead, we might try a heuristic combination of two algorithms - one, a fast locking algorithm acquiring exclusive/shared locks, and a second one, a helper algorithm, which would improve the overall performance. As for the locking algorithm, we will use quite a straightforward reader/writer spin-lock. A status variable, m_rw_status, is used to control the status of one writer and multiple readers. The HIWORD of this variable is the writer active flag; and the LOWORD is the active readers count. Both HIWORD and LOWORD are changed in an atomic fashion. The critical section, m_cswriters, is only used by multiple writers, which works well when the number of writers is small (one or two). The following pseudo-code illustrates the reader/writer spin-lock:
Figure 1. Reader/writer spin-lock.
class CACHE_ALIGN SpinRWLock
{
public:
void acquireLockShared()
{
LONG i, j;
j = acquire_read(m_rw_status );
do {
i = j & 0xFFFF;
j = acquire_interlocked_compare_exchange(&m_rw_status, i + 1, i);
pause
} while (i != j);
}
void acquireLockExclusive()
{
::EnterCriticalSection(&m_cswriters);
while(acquire_interlocked_compare_exchange(&m_rw_status,
0x1+0xFFFF, 0x0) != 0x0)
{
pause
}
}
void releaseLockShared()
{
interlocked_decrement_release( &m_rw_status );
}
void releaseLockExclusive()
{
interlocked_Xor_release(&m_rw_status, 0x1+0xFFFF);
::LeaveCriticalSection(&m_cswriters);
}
SpinRWLock()
{
::InitializeCriticalSection(&m_cswriters);
m_writers_readers_flag = 0;
}
~SpinRWLock()
{
::DeleteCriticalSection(&m_cswriters);
}
private:
CACHE_PADDING
volatile LONG m_rw_status;
CACHE_PADDING
CACHE_ALIGN
CRITICAL_SECTION m_cswriters;
};
SpinRWLock may work on a multi-core PC, but it does not on a Uniprocessor PC. As a matter of fact, a writer may completely live-lock while the readers are holding a highly contended shared lock. In order to improve writer performance, we introduce a helper heuristic code, notifying the readers that a writer is waiting for a lock. A simple solution is to notify readers by setting an additional helper variable m_helper_flag. The helper flag is set to HELPER_SIGNAL_SLOWDOWN, if a writer could not acquire an exclusive lock for a given number of attempts MAX_WRITER_SPIN. This flag is used to prevent readers from acquiring a shared lock in their next turn. Upon the active reader releasing the lock, the writer waits on the event m_helper_wait_event being set by the readers at lock release. The following pseudo-code illustrates notifying the readers by a writer:
Figure 2. Using a helper flag to notify readers.
void acquireLockExclusive()
{
…
while(acquire_interlocked_compare_exchange(&m_rw_status, 0x1+ 0xFFFF, 0x0)!= 0x0)
{
if (++spin_count == MAX_WRITER_SPIN)
{
…
write_release(m_helper_flag,HELPER_SIGNAL_SLOWDOWN);
while(acquire_interlocked_compare_exchange(&m_rw_status,
0x1+0xFFFF,0x0)!=0x0)
{
wait_conditionally(m_rw_status,0x0,m_helper_wait_event);
}
…
write_release(m_helper_flag, HELPER_UNDEFINED_STATE);
…
return;
}
else
{
pause
}
}
…
}
The operations controlling the reader/writer lock status variable are atomic, but the helper operations (such as checking the lock status variable, reading/writing the helper flag, setting events) are not. There are some standard techniques letting a program sequence be completed in atomic fashion. An example might be: using a critical section as an “atomizer”[3]. In our case, doing this would likely end up creating another object, similar to the compound reader/writer locks [2,3]. Instead, we will try the following non-atomic waiting function with additional checking of the lock status variable:
Figure 3. Waiting for the wait_event conditionally when the event and the condition variable are set other than atomically.
void wait_conditionally(volatile LONG& cond_variable, int cond_min, HANDLE wait_event)
{
while(acquire_read(cond_variable) > cond_min)
{
::WaitForSingleObject(wait_event, INFINITE);
}
}
Controlling cond_variable and wait_event in a non-atomic way incurs a performance penalty. If readers falsely set m_rw_status > 0 and m_helper_wait_event in a signaled state (see figure 4), a writer spins at least once, wasting processor time. This situation is possible, if one reader sets m_helper_wait_event in the releaseLockShared() function while the other reader threads are incrementing m_rw_status in the try_interlocked_increment_reader() function. The function try_interlocked_increment_reader() in figure 4 is similar to SpinRWLock::acquireLockShared() (the only difference is that the former function returns false if a reader could not acquire a shared lock for MAX_READER_SPIN attempts). If two readers false signal the m_helper_wait_event once, the writer overhead can be ~ 2000-3000 processor tacts. The maximum overhead we get for a writer (before the latter will finally have acquired the lock) is ~ (active_readers_count-1)*2000-3000 processor tacts. The overhead of a reader, spinning and checking the false signaled m_writer_release_event in the function acquireLockShared(), can be higher. The readers will waste processor time, until the writer has reset the m_writer_release_event. However, a heuristic assumption is that such harmful behavior is not going to happen very often. Another heuristic assumption is that the overall performance penalty would not overcome the performance benefit that the helper code might offer. The full code of this reader/writer lock SHRW is attached to the article.
Figure 4. Acquiring and releasing a shared lock by readers.
void acquireLockShared()
{
if(HELPER_UNDEFINED_STATE != acquire_read(m_helper_flag))
{
wait_conditionally(m_helper_flag, HELPER_UNDEFINED_STATE,
m_helper_slowdown_event);
}
else
{
}
while( false == try_interlocked_increment_reader() )
{
wait_conditionally(m_rw_status, 0xFFFF, m_writer_release_event);
}
}
void releaseLockShared()
{
if(interlocked_decrement_release(&m_rw_status) == 0 )
{
if (acquire_read(m_helper_flag) == HELPER_SIGNAL_SLOWDOWN)
{
::SetEvent(m_reader_release_event);
}
else
{
}
}
else
{
}
}
In order to improve the SHRW object, we may use an additional bit of the m_rw_status HIWORD as a helper flag (instead of using a separate variable m_helper_flag). The improvement is that all the bits of the status variable, including the helper bit, can be set atomically. The solution will be even simpler, if we use the same HIWORD bit for both the helper and the active writer flag:
Figure 5. Reader/writer spin-lock SHRW2 with one status variable for all three: active writer status, the reader count, and the helper flag.
class CACHE_ALIGN SHRW2
{
public:
void acquireLockShared()
{
while(false == try_interlocked_increment_reader())
{
wait_conditionally(m_rw_status, 0xFFFF, m_writer_release_event);
}
}
void acquireLockExclusive()
{
::EnterCriticalSection(&m_cswriters);
int spin_count = 0;
while(acquire_interlocked_compare_exchange(&m_rw_status,0x1+0xFFFF,0x0) != 0x0)
{
if (++spin_count == MAX_WRITER_SPIN)
{
::ResetEvent(m_writer_release_event);
interlocked_Or_release (&m_rw_status, 0x1+0xFFFF);
wait_conditionally(m_rw_status, 0x1+0xFFFF, m_reader_release_event);
return;
}
else
{
pause
}
}
::ResetEvent(m_writer_release_event);
}
void releaseLockShared()
{
if(interlocked_decrement_release(&m_rw_status) == 0x1+0xFFFF )
{
::SetEvent(m_reader_release_event);
}
else
{
}
}
void releaseLockExclusive()
{
interlocked_Xor_release(&m_rw_status, 0x1+0xFFFF);
::SetEvent(m_writer_release_event);
::LeaveCriticalSection(&m_cswriters);
}
SHRW2()
{
m_rw_status = 0;
::InitializeCriticalSection(&m_cswriters);
m_writer_release_event = ::CreateEvent(NULL, TRUE, FALSE, NULL);
m_reader_release_event = ::CreateEvent(NULL, FALSE, FALSE, NULL);
}
~SHRW2()
{
::DeleteCriticalSection(&m_cswriters);
::CloseHandle(m_writer_release_event);
::CloseHandle(m_reader_release_event);
}
private:
bool try_interlocked_increment_reader()
{
LONG i, j;
j = acquire_read(m_rw_status);
int spin_count = 0;
do {
if (spin_count == MAX_READER_SPIN)
{
return false;
}
else
{
i = j & 0xFFFF;
j = acquire_interlocked_compare_exchange(&m_rw_status, i + 1, i);
spin_count ++;
}
} while (i != j);
return true;
}
inline void wait_conditionally(volatile LONG& cond_variable,
int cond_min, HANDLE wait_event)
{
while( acquire_read(cond_variable) > cond_min)
{
::WaitForSingleObject(wait_event, INFINITE);
}
}
enum { MAX_WRITER_SPIN = 1000, MAX_READER_SPIN = 1000 };
CACHE_PADDING(1)
volatile LONG m_rw_status;
CACHE_PADDING(2) CACHE_ALIGN
CRITICAL_SECTION m_cswriters;
HANDLE m_writer_release_event;
HANDLE m_reader_release_event;
};
The test results of the SHRW and SHRW2 objects are summarized in Figure 6 and Figure 7. Testing scenarios and the program code are practically the same as the ones used in the article[1]. In order to compare lock performance, the new Windows Vista API user-space lock SRWLOCK and the “RWLockFavorWriters” object [2] were also tested.
Figure 6. Testing one writer and multiple readers on a Uniprocessor PC, AMD Sempron(tm) 3000+, 2.00 GHz, 32-bit Windows XP Home Edition SP3, compiled in VC++ 2005 Express. Duration per operation in microseconds and the coefficient of variation, %.
Number of readers 1 2 4 8 4 (no writers)
RWFavorWriter
reader 0.93 1.12 1.64 2.60 1.12
writer 6.50 17.00 25.78 49.36 -
reader RSTD % 2.87 12.23 19.52 31.92 20.74
writer RSTD % 2.71 22.4 11.4 13.34 -
SHRW
reader 0.59 0.87 1.46 2.65 1.17
writer 7.36 11.33 23.32 48.06 -
reader RSTD % 5.41 13.06 24.44 25.11 7.19
writer RSTD % 5.02 6.8 7.68 7.91 -
SHRW2
reader 0.59 0.87 1.47 2.64 1.15
writer 7.38 11.46 23.48 48.06 -
reader RSTD % 6.49 12.02 24.7 24.61 5.99
writer RSTD % 6.48 6.51 8.78 9.93 -
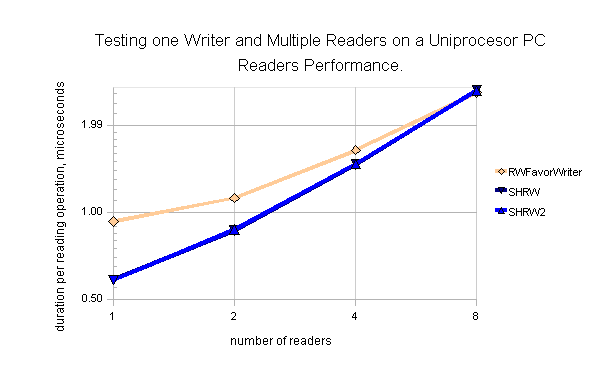

Figure 6 shows that there is not much difference in the performance of the locks running on a Uniprocessor PC. Performance of the SHRW and SHRW2 locks is the same and slightly better than the RWFaivorWriters for both the reader and writers. Kernel CPU usage of the RWFaivorWriter object is a bit higher (~10-20%) as compared with the SHRW and SHRW2 locks which may indicate RWFaivorWriter's more frequent falling into kernel mode.
Test results on a Multi-core PC are summarized in Figure 7. Some of the results were filtered out for the SRWLOCK and RWFaivorWriter objects. When a SRWLOCK reader competes with a writer, the former has live-locked in ~10% tests; the writer has live-locked in ~7% tests when competing with two SRWLOCK readers. Without filtering abnormal results, comparison of the locks' performance would be impossible. The test report “Results\vista_tests.html” illustrates deviation in the SRWLOCK performance within individual threads and tests, including abnormal results filtered out for analyses; see the article attachment. Figure 7 shows an inconsistent behavior of the SRWLOCK. The coefficient of variation ~120-294% indicates that the performance of the individual reader/writer threads varies in a large extent. Some of the RWFaivorWriter test results were filtered out because of the deadlocks that occurred at the acquireLockShared() function when one writer was competing with four readers.
Figure 7. Testing one writer and multiple readers on a Quad-CPU PC, Intel Q6700, 2.66 GHz, Hyper-Threading disabled, 64-bit Windows Vista SP1, compiled in VC++ 2008 Express. Duration per operation in microseconds and the coefficient of variation, %.
Number of readers 1 2 4 8 4 (no writers)
SRWLOCK
reader 1.36 0.24 0.57 1.17 0.59
writer 4.9 166.05 278.17 551.63 -
reader RSTD % 293.85 6.78 11.83 17.41 2.32
writer RSTD % 121.92 131.86 34.38 32.62 -
RWFavorWriter
reader 4.37 3.92 5.28 7.02 0.90
writer 6.26 13.72 20.12 54.00 -
reader RSTD % 27.25 31.96 4.41 4.74 7.78
writer RSTD % 51.33 17.37 3.64 13.29 -
SHRW
reader 0.67 1.24 1.84 2.54 0.84
writer 2.65 3.01 4.35 8.60 -
reader RSTD % 3.35 6.9 11.7 7.89 6.99
writer RSTD % 2.86 1.53 8.94 6.2 -
SHRW2
reader 0.66 1.19 1.42 2.21 0.81
writer 2.65 3.04 5.20 10.88 -
reader RSTD % 2.33 7.09 11.96 10.76 -
writer RSTD % 2.15 0.97 6.37 9.52 -
Writer and reader performance of SHRW/SHRW2 is better as compared with the RWFaworWriter object. Variation of the results is small ~1-12 %. The locks generate a relatively small number of thread context switching per second ~200-2000, loading the kernel CPU ~5-10%. Reader performance of the SHRW/SHRW2 locks might be further improved up to ~20-45% on a Multi-core PC. For this purpose, writers might check the status variable m_rw_status before performing CAS operations in the loop at the acquireLockExclusive() function (the downside would be degradation of the writer performance ~100-200%, and increasing the coefficients of variation up to 20-50% for writers and readers). A disadvantage of the SHRW/SHRW2 objects is that they use atomic memory primitives which may not be available on all processor architectures. This limits portability of the code. Read/write memory operations, having acquire/release semantics, should be reviewed. Their atomicity and ordering should be considered when the SHRW/SHRW2 are ported on different hardware platforms and compiled using non-Microsoft compilers. Secondly, as many threads are spinning on the same memory location m_rw_status, cache invalidations and memory traffic become excessive and should be taken into account. In order to minimize false sharing, the hardware dependent alignment CACHE_ALIGN and cache padding CACHE_PADDING values ought to be adjusted. It also may be necessary to adjust the MAX_WRITER_SPIN and MAX_READER_SPIN constants on Uniprocessor and Multi-core PCs.
Conclusion
- The
SHRW/SHRW2 locks are high performance synchronization objects for application development with Microsoft compilers VC++8.0/9.0 for Microsoft Windows XP/Vista running on 32x/64x Uniprocessor/Multi-core x86-architecture platforms. - Using the
SHRW/SHRW2 objects on different hardware/software platforms and with non-Microsoft compilers requires porting the code with respect to specific cache/memory model, atomic memory primitives, hardware and compiler specific operation ordering. - The
SHRW/SHRW2 objects are designed for highly contended locks with a small number of writes (one or two) and multiple readers. For writers, there is a potential performance regression, lock convoy, and starvation along with increase in the number of multiple writers.
References:
- Valery Grebnev. "Testing reader/writer locks", testing_rwlocks.aspx
- Robert Saccone and Alexander Taskov. “CONCURRENCY: Synchronization Primitives New To Windows Vista”, http://msdn.microsoft.com/en-us/magazine/cc163405.aspx
- Ruediger R. Asche. “Compound Win32 Synchronization Objects”, http://msdn.microsoft.com/en-us/library/ms810427.aspx

