Introduction
The concept of verifying the integrity of encrypted data appeared in the 1970s in the banking industry. The problem was studied in detail by the ANSI X9 committee, and later formalized by Katz and Yung [13]. Banks did not want to transmit data and allow an attacker to flip a bit undetected. In this situation, the attacker would not decrypt the message, instead he would only flip a bit so that the encrypted message "Post $100" would be changed to "Post $700".
 Although the concept of data authentication has been known for some time, it is only in the last decade that authenticated encryption has become a 'single cryptographic operation' rather than a composition of two distinct operations. This article will present three authenticated encryption modes offered in Crypto++: EAX, CCM, and GCM. The article will also examine examples of incorrectly composing encryption and authentication.
Although the concept of data authentication has been known for some time, it is only in the last decade that authenticated encryption has become a 'single cryptographic operation' rather than a composition of two distinct operations. This article will present three authenticated encryption modes offered in Crypto++: EAX, CCM, and GCM. The article will also examine examples of incorrectly composing encryption and authentication.
Many beginners who have not had a formal introduction to cryptography often make the mistake of only encrypting data. The apparent reason for not including authentication data is that most sample code only offers an example of the encryption (and perhaps decryption) function, void of any context. The authentication step is another topic elsewhere in the documentation. The beginner simply has no knowledge that encryption must be married to authentication.
For those who include authentication assurances, it can be difficult to incorporate correctly. As Bellare, Rogaway, and Wagner wrote in A Conventional Authenticated-Encryption Mode:
...people had been doing rather poorly when they tried to glue together a traditional (privacy-only) encryption scheme and a message authentication code (MAC). [1]
And in The CWC Authenticated Encryption (Associated Data) Mode, Kohno, Whiting, and Viega write:
...it is very easy to accidentally combine secure encryption schemes with secure MACs and still get insecure authenticated encryption schemes. [12]
Many have said that cryptography is rarely the weakest part of a system. This is usually true for a good implementation. But the reason this article is being offered is that there's a lot of bad cryptography in the field due inexperienced programmers implementing systems which they do not understand (reviewing MSDN samples is not adequate for designing the security components). There are lots of ways to get this stuff wrong, sometimes in subtle ways that are not readily apparent. Because cryptography is easy to get wrong, I do not want to lead folks down the road of another bad implementation. But the less experienced should be introduced to cryptographic best practices. Much of what this article addresses is what I have encountered in the field.
Finally, if you really have a viable application, you should consider consulting with a practicing cryptographer or security consultant. Many can be found at Universities and on Usenet's sci.crypt.
Background
Authenticated encryption, also known as authenc, is the process of both encrypting and authenticating data. The process will associate an authenticator, also known as a tag, with the data. Plain text is transformed into cipher text with an authenticator. So the output of an authenticated encryption operation is a { ciphertext, tag } pair. When it comes time to decrypt the data, the cipher text is validated using the tag. The easiest way to envision an authenticator is to view it as a digital signature in a shared key or symmetric key system.
There are two major families of authenticated encryption: AE [13,14] and AEAD [15]. The AE family is an authenticated encryption scheme using a symmetric key transforming a message M into cipher text C such that C provides both confidentiality and authentication assurances. Later, it was realized that not all data needed to be encrypted, which lead to the development of AEAD schemes. The AEAD systems provide customary authenticated encryption as with the AE schemes, as well as authentication assurances over associated data (the 'AD' in AEAD). The associated data is also known as a header, additional data, and additional authenticated data. The additional data is not encrypted - it is only authenticated - and sent in clear text.
EAX, CCM, and GCM are all AEAD schemes. If we only need authenticated encryption, or only authentication, we can still use the modes. We simply specify 0 as the length of the missing member. The schemes were designed to provide this level of flexibility. Finally, the modes usually specify a default tag size for interoperability. The default size is typically 12 or 16 bytes (96 or 128 bits). When using a smaller tag, a simple truncation occurs on the full tag size. It is up to the receiver to determine whether to accept a tag which is truncated (but otherwise valid).
NIST and FIPS
In the field, there are many modes of authenticated encryption available - a visit to NIST's Modes Development page list 11 alone. Note that not all 11 are approved for use by the US federal government. The proposed modes include EAX, CWC, and OCB. But only CCM and GCM are approved for use by the US federal government. CCM mode is specified in SP 800-38C and GCM is specified in SP 800-38D.
Authenticated encryption is an algorithm which specifies the operation of a block cipher - hence the reason it is called a mode of operation. Most modes, such as ECB, CBC, OFB, CFB, and CTR, are already familiar to us. These five modes are known a encryption modes - they only provide privacy. In addition to the encryption modes and authenticated encryption modes, there is also an authentication mode (void of encryption) recognized by NIST. The mode is CMAC and it is specified in SP 800-38B.
Crypto++
 Crypto++ was written by Wei Dai. The source files can be downloaded from www.cryptopp.com, or fetched from the SourceForge SVN repository. The article requires use of library version 5.6. For compilation and integration issues, visit Integrating Crypto++ into the Microsoft Visual C++ Environment. This article is based upon assumptions presented in the previously mentioned article. For those who are interested in other C++ Cryptographic libraries, please see Peter Gutmann's Cryptlib or Victor Shoup's NTL.
Crypto++ was written by Wei Dai. The source files can be downloaded from www.cryptopp.com, or fetched from the SourceForge SVN repository. The article requires use of library version 5.6. For compilation and integration issues, visit Integrating Crypto++ into the Microsoft Visual C++ Environment. This article is based upon assumptions presented in the previously mentioned article. For those who are interested in other C++ Cryptographic libraries, please see Peter Gutmann's Cryptlib or Victor Shoup's NTL.
Folks seem to have the most problems getting the headers and library on path, so please read the above article. If you receive a compile or link error, the above article lists nearly all that issues that can be encountered and the resolution. For an examination of Crypto++'s other supported confidential modes of operation, see Applied Crypto++: Block Ciphers.
When working with Crypto++, understand that the library uses a pipelined design: data flows from sources to sinks. This is a design similar to Unix pipes. In between the sources and sinks are filters which transform data. Below, the source and sink are fairly obvious, as is the filter. The
true argument in the StringSource simply instructs the source to send in all data immediately - do not buffer data. Finally, filters require an encryption or decryption object as an argument - the objects are similar to a function pointer without the unpleasant declarations and syntax.
GCM<AES>::Encryption encryptor;
encryptor.SetKeyWithIV(...);
StringSource( plaintext, true,
new AuthenticatedEncryptionFilter(
encryptor,
new StringSink( ciphertext )
)
);
In the code above, the AuthenticatedEncryptionFilter handles everything for us: from padding to sizing the output buffer. We access the bytes of the cipher text through
ciphertext.data(), which has a size of ciphertext.size(). The cipher text may have embedded
NULLs, but it does not matter to a standard library string - the string has an explicit length. Finally, the objects created with
new are automatically destroyed. There is no need to manage the pointers.
Encryption Alone is Not Enough
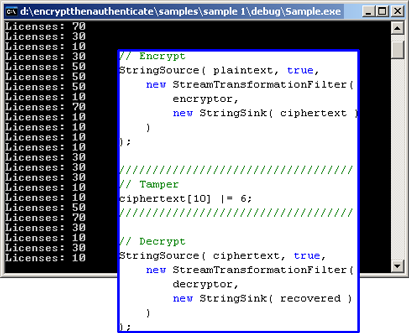
If you are new to authenticated encryption, consider the following example using encryption only. Our goal is simply to send an encrypted message or persist encrypted data to disk. To emphasize the importance of the authentication of messages, the example will be framed in that of a licensing system. Since .NET/XML is popular, we will also use a human readable string to simulate an XML document. Our string is: Licenses: 10. I have found that this example always gets management's attention.
The code below is available as Sample 1. We encrypt the license string using Crypto++ under a random key and random IV. We use a NIST approved block cipher (AES), and a NIST approved mode of operation (CFB). We then tamper with byte 11. Finally, we examine the recovered text.
|
Figure 1: Recovered Plain Text after Tampering
|
Though we encrypted Licenses:10, we recovered Licenses: 30. Most alarming is that there is no way to detect the modification - the cipher text always decrypts to either Licenses: 10 or Licenses: 30, each of which appears valid. If the attacker chooses
ciphertext[10] |= 4, he can force recovery to Licenses: 50.
|
Figure 2: Effects of Modifying 1 bit of Ciphertext
|
Figure 2 shows multiple runs of the first sample. Notice that a non-printable character is never encountered. To make matters worst, the probability is not even 50%: the attacker can get Licenses: 30 out of the system over 60% of the time (and it gets worst as more fiddling occurs with bits in byte 11). In Figure 3, two bits in the ciphertext were modified:
ciphertext[10] |= 6. This change resulted in a upsize 87% of the time, and introduced two additional values: 30 and 70!
|
Figure 3: Effects of Modifying 2 bits of Ciphertext
|
Anyone using the method of "if it decrypts properly, it is valid," is gravely incorrect. In fact, the Handbook of Applied Cryptography explicitly warns us of the method:
A common misconception is that encryption provides data origin authentication and data integrity, under the argument that if a message is decrypted with a key shared only with party A, and the message is meaningful, then it must have originated from A. [2]
Another side effect of bad cryptography is the compromise of a host. Suppose we encrypt a message which is defined as
struct {
int length;
byte* data
} MESSAGE, PMESSAGE;
We chose AES, and operate the cipher in CBC mode. Since the attacker does not need to decrypt the message to tamper with the message, he fiddles with the bytes [0-3] to modify the length, and perhaps modifies the cipher text with shell code. The application performs the decryption and uses the data even though the length has not been validated. The application's internal parser, which will be interpreting the message, does not have a chance.
If your line of business is in the secure software sector, this is the last thing you want to see reported on Security Focus' BugTraq mailing list. Just imagine the thought of an encrypted message - without assurances - being exploited to cause a buffer overflow so the attacker can subsequently get root. It sounds like a 'get your resume together' moment to me.
While it is easy to correct the initial short comings of the system with other modes of operations and redundancy information, the example should serve as a warning: Encryption alone is not enough. More sophisticated attacks exist which will dismantle other modes of operation and modify the built in redundancy so that the tampering cannot be detected.
Integrity Checking is Not Enough
Before we examine why authenticated encryption is required, we should take a quick look at two mechanisms which are usually not secure. The first method uses a MAGIC value, the second uses hashing.
In the examples above, we fiddled with byte 11 leaving bytes [0-9] untampered. In this respect, the first 10 bytes were a MAGIC value which attested to the integrity of the recovered text. As was trivially shown under the construction, the mechanism is flawed (as is
C = Enc(MAGIC||m)).
For the construction offered in the HAC, encrypting the concatenation of the message and its hash probably not secure. According to Dr. Wagner of UC Berkeley, "For some modes of operation for Ek, Ek(h(m)||m) may be secure, but the details may be a bit tricky" [16]. So its probably best not to use the mechanisms.
Note that when the HAC was originally written, the practice of appending a hash for integrity verification was acceptable. Unfortunately, the landscape has changed and the section requires a revision. For a discussion of the extension attack suffered by the method, see Message Confidentiality and Integrity - Prepend Hash versus Append Hash [16] on sci.crypt.
In the table below, Enc(x) is encryption, and Hash(x) is an unkeyed hash (such as SHA or Whirlpool). Note that the list below does not include simple encryption.
| Method | Protocol | Operation | Transmit |
| MAGIC | - | C = Enc(m||MAGIC) | C |
| HAC, 9.6† | - | h = Hash(m), C = Enc(m||h) | C |
†Handbook of Applied Cryptography, Section 9.6
Encrypt Then Authenticate
In 2001, Hugo Krawczyk published The Order of Encryption and Authentication for Protecting Communications. In the paper, Krawczyk proposed the concept known of Generic Composition. Generic composition essentially combines standard CTR mode encryption with variants of CBC-MAC message authentication. Using generic composition, an authentication mechanism can be proved either secure or insecure.
During the course of the paper, Krawczyk examined three commonly used methods of ensuring data authenticity (which implies data integrity). Each method was used in a well known protocol and is shown below. Note that the list below does not include simple encryption.
- Authenticate then Encrypt (AtE) - SSL
- Encrypt then Authenticate (EtA) - IPSec
- Encrypt and Authenticate (E&A) - SSH
The results of the paper proved that Encrypt then Authenticate (IPSec) was secure, as was Authenticate then Encrypt (SSL) under certain constructions. However, the paper also showed that Encrypt and Authenticate (SSH) was insecure. The two provably safe Authenticate then Encrypt constructions are:
- Block ciphers operated in CBC mode
- Stream ciphers which XORs data with a pseudorandom pad
The operations performed by the protocols are listed below. Enc(x) is encryption, and Auth(x) is a message authenticity code (also known as a MAC or keyed hash).
| Method | Protocol | Operation | Transmit |
| AtE | SSL | a = Auth(m), C = Enc(m||a) | C |
| EtA | IPSec | C = Enc(m), a = Auth(C) | C||a |
| E&A | SSH | C = Enc(m), a = Auth(m) | C||a |
Under Krawczyk's model, counter mode encryption with a CBC-MAC (properly constructed) is provably secure. It is also important to understand what is not being said. For example, it is not the case that CFB and OCB modes are insecure. To determine the security of the other modes, the interaction of the components and the system as a whole should be analyzed.
CBC-MAC
A MAC is a Message Authentication Code. It is the symmetric key equivalent of a digital signature (a digital signature exists in the Public Key/Private Key realm). MACs provide assurances on authenticity and origin. If we receive a ciphertext and the MAC over the ciphertext is valid, we presume with very high probability that the message came from our peer and has not been tampered.
A CBC-MAC uses the residue of CBC encryption under a known IV to create a MAC. The residue is the feedback block remaining after all plaintext has been encrypted. Even though there is no plain text remaining, there is still a feedback block ready to be used for the next encryption operation. The residue would would be XOR'd with the key to produce the MAC. Both Wiki and the Code Project include discussions of CBC-MACs.
Before encryption and authentication were joined as a single cryptographic operation, a system would usually encrypt the data under a first key, and then make a second pass over the data using a second key. History has shown that there are lots of ways to get a CBC-MAC wrong. Indeed, the Handbook of Applied Cryptography again warns us:
Care must be exercised to ensure that dependencies between the MAC and encryption algorithms do not lead to security weaknesses, and as a general recommendation these algorithms should be independent. [5]
When using CBC-MACs, there are quite a few things that must be considered. CBC-MACs are secure for fixed-length messages; but used alone, a CBC-MAC is not secure for a variable-length message. The HAC has an excellent treatment of these considerations and is the source for the list below. Since all the information below is from the Handbook of Applied Cryptography, only the page number is cited.
- Neither the encryption operation nor the MAC operation compromises the other - if a weakness is found in the authentication mechanism, there should be no compromise of the encrypted data (and vice-versa) [p.367]
- Keys must be independent - using the same key to both encrypt the data and authenticate the data (which would allow a single pass over the data) causes the ciphertext to be independent of the plaintext. So the authentication mechanism is rendered completely insecure [p.367]
- CBC with XOR Checksum (CBCC) - insecure due to defects in the authentication mechanism [p.368]
- CBC with mod 2n-1 Checksum - insecure due to chosen-plaintext attacks [p.368]
- Plaintext-Ciphertext Block Chaining (PCBC) - insecure due to known-plaintext attacks [p.368]
- CBC-Pad - insecure for variable message lengths [17]
Semantic Authentication
In 1996, David Wagner and Bruce Schneier published Analysis of the SSL 3.0 Protocol. In the paper, Wagner and Schneier introduced the Horton Principal which is the notion of Semantic Authentication. Semantic authentication simply means to authenticate what was meant, and not what was said.
For example, suppose there is plain text which is to be protected. The plain text is padded to the size of the block cipher and then encrypted. The operation of padding begs the question, What should be authenticated? The plain text alone or plain text and padding? According to Wagner and Schneier, both the plain text and padding would be authenticated (what was meant), and not just the plain text (what was said). And the contrapositive leads helps us find extraneous data: if the data does not need to be encrypted or authenticated (i.e., it has no value), then the data does not need to be persisted or communicated.
Below are two examples of how we would apply the Horton principal. The following presumes a shared key exists between the parties. What is encrypted or authenticated in the scenarios is not a complete inventory. When using the Internet over TCP/IP, you also have to worry about deletions, injections, re-orderings, and playbacks. TCP, though a connection-oriented service, is not cryptographically secure.
| Medium | To Be Encrypted | To Be Authenticated |
| Disk File | Plaintext Message,
Message Length | IV, Disk Sector |
| Internet Datagram | Plaintext Message,
Message Length | IV, Source IP/Port,
Destination IP/Port |
In the list above, notice that the length is encrypted and not authenticated. This is done so that the actual size of the plaintext is not leaked (as would be the case if the length were authenticated only). Handling of length (encryption versus authentication) is just one of the details that does have implications in the overall security of an implementation. If we were to use a padding system such as PKCS #5, we would not need an explicit length field since the padding could be removed in an unambiguous manner. Depending on the scenario, either the { length, plain, padding } or the { plain, padding } is encrypted and authenticated.
Crypto++ Implementations
If you've gotten this far, you're probably convinced that Authenticated Encryption is a good thing, CBC-MACs are tricky (but have provable security with appropriate counter mode encryptors), and it is best to use a canned solution. Here are the canned solutions. The samples use AES since it is the only block cipher approved by NIST. If preferred, a NESSIE or ISO approved block cipher such as Cameilla can be used. Also, the code only performs authenticated encryption - it does not encrypt additional data. For examples of using both channels (the full AEAD), visit the Crypto++ wiki.
We also take the liberty of assuming secret keys exist between the parties. The excerpts omit keying, but the samples use a random key and IV. In practice, key exchange, key transport, and key management is thorny at best. Recall from the discussion of CBC-MAC, two independent keys are required: one for the encryption process and one for the authentication process. Fortunately, EAX, CCM, and GCM modes of operation only require a single key (just as with using confidentiality modes). The authenc modes will derive keys for the components per their respective specification.
AutoSeededRandomPool rng;
byte key[AES::DEFAULT_KEYLENGTH];
rng.GenerateBlock( key, sizeof(key) );
byte iv[AES::BLOCKSIZE];
rng.GenerateBlock( iv, sizeof(iv) );
EAX
The first mode to be examined is Bellare, Rogaway, and Wagner's EAX. The code is available in Sample 2. EAX was proposed to NIST during the selection process of an authenticated encryption mode. The mode was not selected as a FIPS standard. The finer details of using EAX, such as specifying authenticator tag length, use of arbitrary size IVs, and use of additional data, can be found in the Crypto++ wiki under EAX Mode.
EAX<AES>::Encryption encryptor;
encryptor.SetKeyWithIV(key, sizeof(key), iv, sizeof(iv));
StringSource( plaintext, true,
new AuthenticatedEncryptionFilter(
encryptor,
new StringSink( ciphertext )
)
);
In the code above, the AES/EAX encryptor is used to create a { ciphertext, tag } pair. The filter handles padding for us as required, so there is no need to pad on your own. As with traditional Crypto++ modes such as CBC, we can use
SetKeyWithIV(key, sizeof(key), iv) to key the cipher. However, EAX offers an unlimited IV, so it is a good practice to use the overload:
SetKeyWithIV(key, sizeof(key), iv, sizeof(iv)). Decryption is equally easy to perform as shown below.
StringSource( ciphertext, true,
new AuthenticatedDecryptionFilter(
decryptor,
new StringSink( recovered )
)
);
If the operation does not throw an exception, the data is genuine and is ready to be used. All Crypto++ exceptions derive from std::exception, so either a CryptoPP::Exception or std::exception should be caught.
GCM
GCM is Galois/Counter Mode created by McGrew and Viega. It is a NIST approved mode which operates over a Galois field. The code is available in Sample 3. GCM implementations are unique in that the mode's throughput can be increased by using larger precomputation (at the cost of a memory tradeoff). The finer details of using GCM, such as specifying authenticator tag length, use of arbitrary size IVs, specifying table sizes, and use of additional data, can be found in the Crypto++ wiki under GCM Mode.
The beauty of Crypto++ is the ease in which components can be swapped in and out. Below, the only change in the code was that of swapping in GCM. So we now have an AES/GCM cipher:
GCM<AES>::Encryption encryptor;
encryptor.SetKeyWithIV(key, sizeof(key), iv);
StringSource( plaintext, true,
new AuthenticatedEncryptionFilter(
encryptor,
new StringSink( ciphertext )
)
);
GCM<AES>::Decryption decryptor;
decryptor.SetKeyWithIV(key, sizeof(key), iv);
StringSource( ciphertext, true,
new AuthenticatedDecryptionFilter(
decryptor,
new StringSink( recovered )
)
);
CCM
CCM is Counter with CBC-MAC and was proposed by R. Housley, D. Whiting, and N. Ferguson in 2002. CCM uses a formatting function to create a formatted header describing both the plain text data and the additional data. This means both the plain text data and the additional data must be ready for encryption - data cannot be streamed into the encryptor. This is known as Offline. Both EAX and GCM are online modes of operations.
Unlike EAX and GCM, we must call SpecifyDataLengths(...) before encrypting or decrypting due to the formatting function. Since we are only investigating authenticated encryption, the
aad length and footer length parameters will be 0. We also specify a tag size even though Crypto++ default tag size is fine. We do this because we need to account for its size during decryption:
SpecifyDataLengths( 0, ciphertext.size()-TAG_SIZE ), and this is one of the easiest ways to control the tag size.
const int TAG_SIZE = 12;
CCM<AES,TAG_SIZE>::Encryption encryptor;
encryptor.SetKeyWithIV(key, sizeof(key), iv);
encryptor.SpecifyDataLengths( 0, plaintext.size() );
StringSource( plaintext, true,
new AuthenticatedEncryptionFilter(
encryptor,
new StringSink( ciphertext )
)
);
...
CCM<AES, TAG_SIZE>::Decryption decryptor;
decryptor.SetKeyWithIV(key, sizeof(key), iv);
decryptor.SpecifyDataLengths( 0, ciphertext.size()-TAG_SIZE );
StringSource( ciphertext, true,
new AuthenticatedDecryptionFilter(
decryptor,
new StringSink( recovered )
)
);
The code is available in Sample 4. If you choose this mode, please visit the Crypto++ wiki for a detailed examination of CCM Mode. This mode imposes other restrictions such as maximum plain text length and invocations of the block cipher under a specific key.
Other Libraries
If you are using other libraries, you have my heartfelt sympathies. Below we examine features available to Microsoft CAPI, Microsoft CNG, Java JCE, OpenSSL, and Certicom's SecurityBuilder.
Microsoft CAPI and CNG
Microsoft Windows CAPI 1.0 and 2.0 only offers confidentiality modes (ECB, CBC, etc). The CNG algorithms shipped with Vista and Server 2008 support both CCM and GCM modes [6,7].
Java JCE
According to the Java" Cryptography Architecture (JCA) Reference Guide for Java 6, there is no support for CCM or GCM[8]. This is most likely a case where the documentation has not been revised.
OpenSSL
According to the OpenSSL mailing list, GCM mode has been committed to HEAD (circa early 2010), so GCM will most likely be available in OpenSSL 1.1. There does not appear to be plans to include CCM, or other modes such as EAX.
Certicom SecurityBuilder
Certicom's SecurityBuilder does support CCM and GCM modes even though the data sheets do not explicitly state the fact.
Acknowledgements
- Wei Dai, author and maintainer of Crypto++
- Dr. David Wagner, for contributions and help on sci.crypt
- Dr. Brooke Stephens, my former cryptography instructor
References
Usually the reference section provides only a bibliography. For this article, the reference section is extended to include where to find good references, and where you might expect to find bad information.
Good References
Bruce Schneier wrote Applied Cryptography, which is a nice warm up to the HAC. I find it lacks most detail and substance needed for an implementation. Though a bit dated, the Handbook of Applied Cryptography is the bible.
If working with specific algorithms such as AES, fetch the reference implementation and test vectors from the author. Finally, sci.crypt and academia offer a wealth of information. For sci.crypt, you will learn who consistently offers good advice.
Bad References
There are lots of bad references out there, especially when a search engine's only criteria is popularity, so be careful. Be wary of the network security folks holding Security+, CISSP certifications, and the like. While they are probably very good white-hat hackers, their curriculum leaves something to be desired. I've read the study guides, and nearly all have failed miserably in the cryptography domain (in our case, achieving an 80% does not mean passing - it means 20% is torqued and requires attention).
You should also question anything on Wiki since it is generally unedited. Don't make the mistake of the fellow posting on sci.crypt who claimed Dr. Adler's reference implementation of ADLER-32 was wrong because there was a discrepancy in Wiki. From Need peer review: May have found mistake in Adler-32!:
This is going out the Mr. Adler, his friends at zlib, the related newsgroups comp.compression and sci.crypt, and the newsgroups sci.math and sci.math.num-analysis... This post relates to suspect calculations... [11]
Confirm everything you've read in this article. I'm not a PhD, but I do have the luxury of discussing detailed topics with my former cryptography instructor. If you find an error or omission, point it out so that it can be corrected for the next reader.
Citations
[1] M. Bellare, P. Rogaway, and D. Wagner. A Conventional Authenticated-Encryption Mode, http://csrc.nist.gov/groups/ST/toolkit/BCM/documents/proposedmodes/eax/eax-spec.pdf[^], 2003.
[2] A. Menezes, P. van Oorschot, and S. Vanstone. Handbook of Applied Cryptography, ISBN 0-8493-8253-7, p. 364.
[3] H. Krawczyk. The Order of Encryption and Authentication for Protecting Communications, http://www.iacr.org/archive/crypto2001/21390309.pdf[^], 2001.
[4] D. Wagner and B. Schneier. Analysis of the SSL 3.0 Protocol, http://www.schneier.com/paper-ssl.html[^], 1996.
[5] A. Menezes, P. van Oorschot, and S. Vanstone. Handbook of Applied Cryptography, ISBN 0-8493-8253-7, p. 367.
[6] Cryptography Primitive Property Identifiers, http://msdn.microsoft.com/en-us/library/aa376211(VS.85).aspx[^].
[7] CNG Features, http://msdn.microsoft.com/en-us/library/bb204775(VS.85).aspx[^].
[8] Java" Cryptography Architecture, http://java.sun.com/javase/6/docs/technotes/guides/security/crypto/CryptoSpec.html[^].
[9] openssl(1), http://openssl.org/docs/apps/openssl.html[^].
[10] crypto(3), http://openssl.org/docs/crypto/crypto.html[^].
[11] D. Walker. Need peer review: May have found mistake in Adler-32!, Usenet posting, http://groups.google.com/group/comp.compression/browse_thread/thread/5a37a9fcd32786fd[^], 2008.
[12] Kohno, Viega, Whiting. The CWC Authenticated Encryption (Associated Data) Mode, http://csrc.nist.gov/groups/ST/toolkit/BCM/documents/proposedmodes/cwc/cwc-spec.pdf[^], 2003.
[13] J. Katz and M.Yung. Unforgeable encryption and chosen ciphertext secure modes of operation, 2000.
[14] M. Bellare and C. Namprempre. Authenticated encryption: Relations among notions and analysis of the generic composition paradigm, 2000.
[15] P. Rogaway. Authenticated Encryption with Associated Data, http://www.cs.ucdavis.edu/~rogaway/papers/ad.ps[^], 2002.
[16] D. Wagner, Message Confidentiality and Integrity - Prepend Hash versus Append Hash, http://groups.google.com/group/sci.crypt/browse_thread/thread/c6c5329f7793e4f4[^], 2007.
[17] S. Vaudenay. CBC Padding: Security Flaws in SSL, IPSEC, WTLS, ..., http://infoscience.epfl.ch/record/52417[^], 2002.

