Introduction
Excerpt from The Algorithm Design Manual by Steven S. Skiena: The abstract data type "dictionary" is one of the most important structures in Computer Science. Dozens of different data structures have been proposed for implementing dictionaries including hash tables, skip lists, and balanced/unbalanced binary search trees -- so choosing the right one can be tricky. Depending on the application, it is also a decision that can significantly impact performance. In practice, it is more important to avoid using a bad data structure than to identify the single best option available.
This article explains a data-structure that can be used to store a dictionary (words and their definitions) in memory.
Background
A "Tree", which is a very elementary data structure, has been brought into application here.
Using the Code
The code consists of the CharacterNode class that stores a char value along with references to 26 other CharacterNodes. The notion behind choosing 26 as the number of references is that this code presently is restricted to only storing the 26 English alphabets.
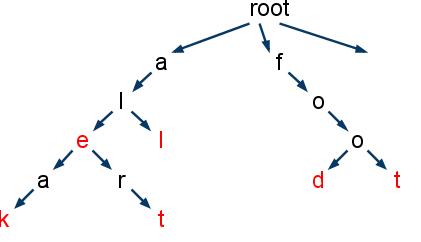
As can be seen in the diagram, the root object of CharacterNode points towards 'a' and 'f'. The nodes corresponding to the characters 'a' and 'f' further point towards other letters, which further follow the same. The code snippet that describes the CharacterNode class is given:
class CharacterNode
{
char c;
CharacterNode next[]=new CharacterNode[26];
CharacterNode()
{
c='a';
for(int i=0;i<26;i++)
{
next[i]=null;
}
}
}
The root (see the diagram) always holds the character 'a' (not shown in the diagram). This is because it is the first object formed (as shown below), and any object will always hold 'a' as the initial character (see the constructor above).
public class CharacterNodeTree
{
public static void main(String args[]) throws IOException
{
CharacterNode root=new CharacterNode();
The insert() routine describes how a character will be stored in the dictionary.
void insert(char ch)
{
this.c=ch;
}
The insert() routine from main() is called in the following manner:
CharacterNode temp=null;
String str=null;
System.out.print("Enter the string to insert:");
BufferedReader br1=new BufferedReader(new InputStreamReader(System.in));
str=br1.readLine();
root.next[str.charAt(0)-97]=new CharacterNode();
temp=root.next[str.charAt(0)-97];
for(int i=0;i<str.length();i++)
{
temp.insert(str.charAt(i),i);
try
{
temp.next[str.charAt(i+1)-97]=new CharacterNode();
temp=temp.next[str.charAt(i+1)-97];
}
catch(StringIndexOutOfBoundsException e) {}
}
Hence, a simple calculation allows the insertion of an alphabet from the string. This calculation is nothing but the position of the alphabet in the alphabetical sequence (like 0 for 'a', 1 for 'b', 25 for 'z', etc.). So forth, the other alphabets from the string can be inserted, and therefore the whole of the string can be inserted.
The find() routine describes how a complete string will be retrieved from the dictionary.
boolean find(String str)
{
CharacterNode temp=this;
for(int i=0;i<str.length();i++)
{
if(temp.next[str.charAt(i)-97]==null)
{
return false;
}
else
{
temp=temp.next[str.charAt(i)-97];
continue;
}
}
return true;
}
The find() routine from main() is called in the following manner:
System.out.print("Enter the string to find:");
BufferedReader br2=new BufferedReader(new InputStreamReader(System.in));
str=br2.readLine();
if(root.find(str)==true)
{
System.out.println("FOUND");
}
Again, a simple calculation allows the retrieval of a string (or even a part of it).
Points of Interest
Looking at the diagram, the code can be further modified:
- A boolean value can be added to the
CharacterNode class definition to indicate whether a particular character ends with a meaningful word or not. For example, in the diagram, all the leaves end (and must end due to the structure of the code) with a meaningful word ('aleak', 'alert', 'all', 'food', 'foot' are the words that have been shown added in the diagram). However, 'ale' is a word that does not end with a leaf but is still a meaningful word and is shown added. Therefore, the leaves ('k', 't', 'l', 'd', 't') and the non-leaf node ('e') must have boolean values as true. - It is easier to find a word with special properties, like starting with a particular character(s) or ending with a particular character(s) (think about links that directly refer leaves!), or having a fixed length (since all the words with the same length occur at the same level, and it should not be difficult to code a link between all these words!).
- A recursive routine (using a stack preferably) may provide a way to retrieve all the words lexicographically.
History
- 25th April, 2009: Initial post
- 26th April, 2009: Uploaded source code

