Bloom effect benchmark pits different parallel for loop technologies like OpenMP, Parallel Patterns Library, Auto-Parallelizer and the latest contender C++17 Parallel for_each against one another.
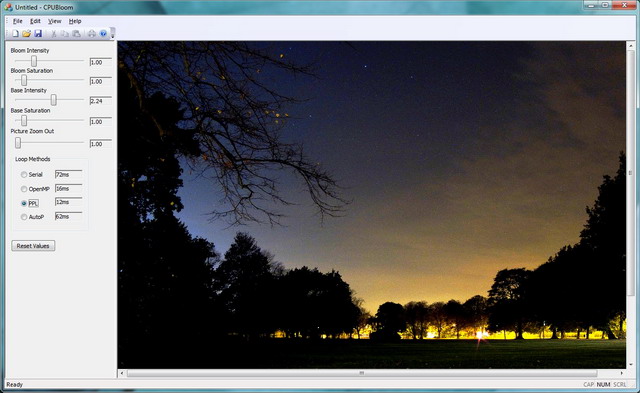
Table of Contents
Introduction
Visual Studio 11 Beta was released in February 2012 and was updated in April 2012. Among its many new features like ISO C++11 concurrency features and C++ AMP, the most interesting of them are Auto-Vectorizer and Auto-Parallelizer. Auto-Vectorizer is turned on by default and generates SIMD code for for-loop by executing multiple iterations at the same time, while Auto-Parallelizer (not turned on by default) runs the for-loop in parallel using multiple threads. This is what MSDN has to say about their difference.
There are some key differences between auto-vectorization and auto-parallelization. Auto-vectorization is always on and requires no user interaction, but auto-parallelization requires the programmer to decide which loops are to be parallelized. Also, vectorization improves the performance of loops on single-core CPUs that support SIMD instructions, but parallelization improves the performance of the loop on multiple CPUs and multi-core CPUs. The two features can work together so that a vectorized loop is then parallelized across multiple processors.
The reader may ask why I am not doing an article on Auto-Vectorizer: I found out that for the particular floating point computation I am doing, auto-vectorized code is only providing marginal improvement (~10% instead of 4x) over the VS2010 non-vectorized code: it could be seen in the generated assembly list that the code is indeed vectorized. And handcrafted vectorized code is only providing ~10% improvement over auto-vectorized code.
For this article, we will briefly look at OpenMP, Parallel Patterns Library and Auto Parallelizer methods available to parallelize for-loops. We do not look at features which are not related to for-loop. Without further ado, let's begin our article!
Bloom Effect
For our benchmark application, we make use bloom effect which is workload intensive enough for our purpose. Bloom effect is described on Wikipedia as "Bloom (sometimes referred to as light bloom or glow) is a computer graphics effect used in video games, demos and high dynamic range rendering (HDR) to reproduce an imaging artifact of real-world cameras." and is usually implemented using graphics shaders. The bloom efect is most beautiful on photos of dark scene with few lights. I simply port the Direct3D Bloom pixel shader from the excellent WPF Shader Article. The original source is presented below:
float BloomIntensity : register(C0);
float BloomSaturation : register(C1);
float BaseIntensity : register(C2);
float BaseSaturation : register(C3);
sampler2D implicitInputSampler : register(S0);
float3 AdjustSaturation(float3 color, float saturation)
{
float grey = dot(color, float3(0.3, 0.59, 0.11));
return lerp(grey, color.rgb, saturation);
}
float4 main(float2 uv : TEXCOORD) : COLOR
{
float BloomThreshold = 0.25f;
float4 color = tex2D(implicitInputSampler, uv);
float3 base = color.rgb / color.a;
float3 bloom = saturate((base - BloomThreshold) / (1 - BloomThreshold));
bloom = AdjustSaturation(bloom, BloomSaturation) * BloomIntensity;
base = AdjustSaturation(base, BaseSaturation) * BaseIntensity;
base *= (1 - saturate(bloom));
return float4((base + bloom) * color.a, color.a);
}
I am not going to show the C++ source here because C++ bloom source is more verbose due to Direct3D shader has better support for vector operation. float3 and float4 are examples of an vector float type. Note: Vector here does not refer to STL vector. In order to write the C++ version, I have to manually implement the following functions dot product (dot), saturate to clamp the values between 0.0 to 1.0 and linear interpolation (lerp). lerp function in Direct3D shader is implemented as x + s(y-x) where x and y is first and second vector, and s is the value to do interpolation.
color.rgb begs some explanation; the readers might have difficulty in understand the swizzling syntax in the form of color.rgb. color is a variable of float4 type which is a vector of 4 float elements. Basically, color.rgb tells the shader compiler to take the r, g and b elements to form a new float3 variable (vector of 3 float elements) in the same rgb order. Whereas color.a tells the compiler to take the a element of color into a scalar float variable.
Serial Loop
This is the reference source code for the for-loop we will be using to parallelize. One thing to note, is that when we execute the for-loop in parallel, the for-loop is not longer executed in sequence and we do not know which sequence it might be. Therefore, only loops with no loop dependencies can be executed correctly in parallel. To extract good performance, the number of iterations must be sufficiently large enough and/or the amount of work to done in each iteration must be intensive enough. However, the performance will never match the ratio of available CPU cores as there is always some overhead to create and schedule threads.
DWORD startTime = timeGetTime();
for(UINT row = 0; row < bitmapDataDest.Height; ++row)
{
BloomEffect effect(m_fBloomIntensity, m_fBloomSaturation,
m_fBaseIntensity, m_fBaseSaturation);
for(UINT col = 0; col < bitmapDataDest.Width; ++col)
{
UINT index = row * stride + col;
pixelsDest[index] = effect.ComputeBloomInt(pixelsSrc[index]);
}
}
DWORD endTime = timeGetTime();
OpenMP Loop
OpenMP 2.0 has been in Visual C++ since version 8.0. It is supported by other C++ compilers as well. By default, OpenMP is not turned on in Visual Studio. To turn OpenMP on, we need to go the project properties, under the Language of C/C++ section and select Yes (/openmp) for Open MP Support. Please note: OpenMP does not have the mechanism to handle exception thrown in its loop.

DWORD startTime = timeGetTime();
#pragma omp parallel for
for(int row = 0; row < bitmapDataDest.Height; ++row)
{
BloomEffect effect(m_fBloomIntensity, m_fBloomSaturation,
m_fBaseIntensity, m_fBaseSaturation);
for(UINT col = 0; col < bitmapDataDest.Width; ++col)
{
UINT index = row * stride + col;
pixelsDest[index] = effect.ComputeBloomInt(pixelsSrc[index]);
}
}
DWORD endTime = timeGetTime();
To parallelize the for-loop, we put a #pragma omp parallel for before the for-loop to indicate to OpenMP that we wish to parallelize that for-loop.
Parallel Patterns Library Loop
Parallel Patterns Library (PPL) is a task-based concurrency library introduced in Visual Studio 2010. Before using PPL, we have to include its header ppl.h and use its Concurrency namespace.
#include <ppl.h>
DWORD startTime = timeGetTime();
using namespace Concurrency;
parallel_for((UINT)0, bitmapDataDest.Height, [&](UINT row)
{
BloomEffect effect(m_fBloomIntensity, m_fBloomSaturation,
m_fBaseIntensity, m_fBaseSaturation);
for(UINT col = 0; col < bitmapDataDest.Width; ++col)
{
UINT index = row * stride + col;
pixelsDest[index] = effect.ComputeBloomInt(pixelsSrc[index]);
}
});
DWORD endTime = timeGetTime();
The first parameter is the starting value of the index and the second parameter is one past the maximum value to iterate. The third parameter is a lambda to execute for each iteration. [&] indicates that we are capture the variables used in the lambda by reference. For more information on C++ lambdas, readers can refer to this link. Reader should note that the operation to invoke the lambda has some overheads. For the example below, PPL would fare several orders in magnitude behind OpenMP and Auto Parallelizer and serial code because the lambda invocation is more expensive than the add operation.
using namespace Concurrency;
parallel_for(0, 1000000, [&](UINT i)
{
c[i] = a[i] + b[i];
});
Auto Parallelizer Loop
Auto Parallelizer is designed to work in tandem with the Auto Vectorizer, meaning Auto Parallelizer can parallelize loops which are auto-vectorized. For loops which have been auto-vectorized, user can expect a 4X increase of performance because 4 elements are executed using SSE in a single iteration. Combined with Auto Parallelizer which say is running on a 4 core machine, the performance could theoretically be 16X!
Auto Parallelizer in Visual Studio 11 Beta is not turned on by default. To turn Auto Parallelizer on, we need to go the project properties, under the Code Generation of C/C++ section and select Yes (/Qpar) for the Enable Parallel Code Generation. To enable Auto Parallelizer for the for loop, we add a pragma in the form of #pragma loop(hint_parallel(N)) where N is a literal constant. If user tries to replace it with a integer constant variable based on the number of CPU cores detected during the runtime, the compiler will complain that hint_parallel has to be literal constant.
DWORD startTime = timeGetTime();
#pragma loop(hint_parallel(8))
for(UINT row = 0; row < bitmapDataDest.Height; ++row)
{
BloomEffect effect(m_fBloomIntensity, m_fBloomSaturation,
m_fBaseIntensity, m_fBaseSaturation);
for(UINT col = 0; col < bitmapDataDest.Width; ++col)
{
UINT index = row * stride + col;
pixelsDest[index] = effect.ComputeBloomInt(pixelsSrc[index]);
}
}
DWORD endTime = timeGetTime();
Auto Parallelizer does not seem to work in the benchmark application. This is why I attached a console project to show Auto Parallelizer works. I have reported the bug at Microsoft Connect. The console application makes use of an array while the MFC application makes use of an aliased pointer to an array. My guess is it did not work probably because an aliased pointer to array is used, instead of an array.
Parallel for_each Loop
C++17 added support for parallel algorithms to the standard library, to help programs take advantage of parallel execution for improved performance. In GUI benchmark as seen below, a vector has to be constructed and initialized for the purpose of no other than filling its std::begin and std::end parameters. I did not include the vector construction in the overall timing. Original benchmark code for other parallel methods remained unchanged in VS2017 15.8 as they were in VS2012.
std::vector<UINT> vec_cnt(bitmapDataDest.Height);
std::iota(std::begin(vec_cnt), std::end(vec_cnt), 0);
DWORD startTime = timeGetTime();
std::for_each(std::execution::par, std::begin(vec_cnt), std::end(vec_cnt), [&](UINT row)
{
BloomEffect effect(m_fBloomIntensity, m_fBloomSaturation,
m_fBaseIntensity, m_fBaseSaturation);
for (UINT col = 0; col < bitmapDataDest.Width; ++col)
{
UINT index = row * stride + col;
pixelsDest[index] = effect.ComputeBloomInt(pixelsSrc[index]);
}
});
DWORD endTime = timeGetTime();
Console Benchmark Results
The benchmark is done on 8 core hyperthreading Intel i7 870 running at 2.93GHz. Since i7 870 is a CPU with hyperthreading support, it has effectively 4 real cores (We divide the number of cores by 2 if it is hyperthreading CPU). Below is the benchmark results for running release mode with no other intensive programs running on the system.
Serial : 72ms
OpenMP : 16ms
PPL : 12ms
AutoP : 62ms
The reader may want to run the benchmark with his/her usual programs running to see how his/her program would fare under the real-life condition in which his/her users will be using their program.
The updated benchmark is redone on another machine: its CPU is 12 core hyperthreading CoffeeLake Intel i7 8700 running at 3.20GHz. It has 6 physical cores.
Serial : 27
OpenMP : 10
PPL : 20
AutoP : 34
PForEach :151
On the console test with the maximum optimization settings(Ox), C++17 parallel for_each fared very badly, I believe to the lambda overhead, while its performance in GUI benchmark is on par with other parallel methods like OpenMP and PPL. In GUI benchmark, the lambda overhead is less of a factor because the lambda body executes substantial work compared to lambda invocation. Before deciding to use which parallel loop, we should proceed with caution and benchmark with the typical workload.
Conclusion
We have looked at the performance of OpenMP, Parallel Patterns Library and Auto-Parallelizer. Sadly, Auto Parallelizer is not working in the benchmark application. There is no reason to choose one over the other though we have to be careful about the PPL's lambda invocation overhead in comparison to the workload. On some PCs, PPL has better performance than OpenMP. For code portability, user may stick to OpenMP because it is implemented by other C++ compilers as well while PPL and Auto-Parallelizer are only found in Microsoft Visual Studio. To build the sample source code, users need to download and install Visual Studio 11 Beta. Any feedback on how I could improve the benchmark application or the article is most welcome. The source code is hosted at GitHub.
Thank you for reading!
History
- 26th April, 2020: Added SSE2 option to benchmark but it only seems to speed up the OpenMP timing. Remember to close all applications before benchmark.
- 19th November, 2018: Added C++17 Parallel
for_each in GUI bloom and console application benchmark - 30th April, 2012: Added explanation on HLSL swizzling operator
- 25th April, 2012: First release

