Introduction
This article discusses a customized SQL Server User Defined Type (UDT) for storing time span and the other artifacts that complement it. It is a wrapper to the System.TimeSpan structure of the Base Class Library, which means most of the implementations are achieved by calls to the said structure. The bulk of the discussion is on the adjustments entailed by the limitation of the SQL language and compliance with the internals of SQL Server. Among them, binary serialization warrants a dedicated section because of its complexity and profound effects on the UDT’s behavior. The complementing artifacts include an aggregate, functions, and extension methods. Their reliance on the methods of the UDT makes their implementation trivial, so this article does not delve deeper into them.
This is not a tutorial on UDT, and I expect that you already have a firm grasp on the fundamentals of .NET and databases. If you need a thorough understanding of UDTs, I refer you to another article of mine which you can find here. Although some parts of the code in this article are influenced by how the UDT is ultimately utilized in a front-end application, discussion on how to use it outside SQL Server is beyond the scope.
UDT Construction
Public Interfaces
We start our dissection of the UDT codes with the boilerplates. They're pretty much straightforward as shown here:
[Serializable]
[SqlUserDefinedType(Format.UserDefined,
MaxByteSize = 9,
IsByteOrdered = true,
IsFixedLength = false)]
public struct SqlTimeSpan : INullable, IBinarySerialize
{
#region Mandatory Members
internal System.TimeSpan SystemTimeSpan;
public override string ToString()
{
return SystemTimeSpan.ToString();
}
public static SqlTimeSpan Parse(SqlString input)
{
SqlTimeSpan udt = new SqlTimeSpan();
udt.SystemTimeSpan = TimeSpan.Parse(input.Value);
return udt;
}
bool _isNull;
public bool IsNull
{
[SqlMethod(InvokeIfReceiverIsNull = true)]
get { return _isNull; }
}
public static SqlTimeSpan Null
{
get
{
SqlTimeSpan udt = new SqlTimeSpan();
udt._isNull = true;
return udt;
}
}
#endregion
}
We merely delegate the work to the underlying TimeSpan structure. It is scoped internal to allow easy access from some methods and objects within the assembly. The adornment in the get method of IsNull ensures that querying this property when the UDT is SQL-null yields false and not "null". (From this point, I’ll be using SQL-null to refer to the null integral to SQL 3-value logic. This is different from the null in .NET context which is a reference to an empty memory.)
The System.TimeSpan object is one of those which SQL Server cannot serialize without your assistance. This necessitates the user-defined format in our attribute and the implementation of the IBinarySerialize interface.
In addition to the format, we also specify values for some of the attribute properties. The size 9 is just enough to store the 8-byte System.UInt64 (ulong in C#) equivalent of the Ticks property of the TimeSpan and the SQL-nullability flag. The UDT is byte-ordered, meaning SQL Server relies on the bits stored in the disk for the sorting. Lastly, we tell SQL Server that our UDT is of varying length so that we don’t have to use the additional 8 bytes for a SQL-null UDT. More light will be shed on these properties when we tackle the implementation of IBinarySerialize.
Since this UDT is just a wrapper for TimeSpan, it just makes sense that external applications use the underlying field instead. We have a method to return the field, but valid only if called outside SQL. The reason couldn’t be more obvious.
public TimeSpan GetSystemTimeSpan()
{
if (SqlContext.IsAvailable)
throw new NotSupportedException("GetSystemTimeSpan " +
"is not supported inside SQL Server.");
return SystemTimeSpan;
}
SQL does not support constructor calls. The constructor call is mimicked when we set a string value to the UDT which internally calls Parse. Because the argument is a string, Parse is very susceptible to typos. It wouldn't hurt if we provide another means of initializing the UDT with strong-typed parameters, like this:
static public SqlTimeSpan CreateSqlTimeSpan(int days, int hours, int minutes,
int seconds, int milliseconds)
{
System.TimeSpan ts = new System.TimeSpan(days, hours, minutes,
seconds, milliseconds);
SqlTimeSpan tsUdt = new SqlTimeSpan(ts, false);
return tsUdt;
}
Next, we provide a constructor to initialize our fields. This should be called only inside the assembly where the second parameter makes sense.
internal SqlTimeSpan(System.TimeSpan ts, bool isNull)
{
SystemTimeSpan = ts;
_isNull = isNull;
}
The methods you’re allowed to call in a UDT depends on the SQL statement you’re using. Only a mutator (setter and Sub in VB) is allowed in the UPDATE statement and SET, whereas only a query (getter and Function in VB) is allowed in the SELECT statement and PRINT. The decision on whether or not to provide two versions of a method is a coder’s discretion. In our UDT, an example of this mutator-query pair is illustrated by Negate - GetNegated.
[SqlMethod(IsMutator = true)]
public void Negate()
{
SystemTimeSpan = SystemTimeSpan.Negate();
}
public SqlTimeSpan GetNegated()
{
return new SqlTimeSpan(SystemTimeSpan.Negate(), false);
}
We can actually get away with just the query version. We can still update our UDT with it, albeit in not the most efficient way. Ideally, if you call a mutator method, what it does inside is simply change a value of at least one field. Using the query version to update a column creates another instance of the object unnecessarily as shown in GetNegated. This may not be an issue if your UDT is of native format, but with user-defined and thousands of rows to update, this can impact performance. Another advantage of sticking with mutator methods for updates is the parsimony of the codes, as shown in this example:
UPDATE TimeSpanTable SET tsCol.Negate()
UPDATE TimeSpanTable SET tsCol = tsCol.GetNegated()
Operators and overloaded methods are not supported by T-SQL. This has significant influence on your approach to creating a UDT. You have to weigh between the benefits of paired methods and its drawback – a bloated object. Fortunately, our UDT is byte-ordered, which means equality operators are readily available for us. These operators are required for sortability of our UDT, but as you'll see later, they do not yield the correct results unless we manipulate the bits during serialization. This laborious undertaking usually puts off developers who will then just content themselves with the non-byte-ordered format and implement the nominal equivalent of the symbolic equality operators. Had we gone to this path, we would have just implemented something like this:
static public bool Equals(SqlTimeSpan ts1, SqlTimeSpan ts2)
{
return TimeSpan.Equals(ts1.SystemTimeSpan, ts2.SystemTimeSpan);
}
One important thing to consider in a UDT which involves granular units or floating points is the low probability of two of them to be exactly equal to the last decimal place. It would be nice to have a lenient equals operator which can accept a certain range for a margin of error. Our UDT caters for this through the ApproxEquals operator. It’s similar to Equals except that it accepts another time span specifying the range on which the difference between the operands is considered negligible.
static public bool ApproxEquals(SqlTimeSpan ts1,
SqlTimeSpan ts2, SqlTimeSpan allowedMargin)
{
TimeSpan diff = ts1.SystemTimeSpan - ts2.SystemTimeSpan;
return (diff.Duration() <= allowedMargin.SystemTimeSpan.Duration());
}
There is not much to discuss on the remaining properties and the methods which just mirror the implementation of their TimeSpan counterparts. One thing to note though is the SqlMethodAttribute.IsDeterministic adornment on some of them. We should just rightfully do so to allow indexing of these properties. Basically, what it means is that the values of these properties are predictable from the value of the input; in this case, anything we enter to define the TimeSpan field. Here’s one of those deterministic properties:
public double TotalDays
{
[SqlMethod(IsDeterministic = true)]
get { return SystemTimeSpan.TotalDays; }
}
We’re almost done with our UDT. We just have to persist it in the disk. This is a manual process, and you better roll up your sleeves because it can get a little dirty.
Binary Serialization
SQL Server can save and retrieve your UDT from the disk all by itself only if the types of the fields are blittable. Blittable types have identical representation in both managed and unmanaged environments. Our TimeSpan is definitely not one of those, and this is why we specify "user-defined" as our UDT format. As a consequence, we also have to implement the IBinarySerialize interface. The complexity of the implementations depends on the features you want your scalar UDT to ultimately embody. If you want it to respond directly to SQL operators, participate in an index, and be sortable, then you have to take the “manual” approach, which I’ll be discussing momentarily. In the other hand, if those features are not important to you, then you can opt for the “quick” one with these simple lines:
public void Read(System.IO.BinaryReader r)
{
_isNull = r.ReadBoolean();
if (!IsNull)
SystemTimeSpan = TimeSpan.FromTicks(r.ReadInt64());
}
public void Write(System.IO.BinaryWriter w)
{
w.Write(IsNull);
if (!IsNull)
w.Write(Ticks);
}
Don’t let the simplicity of the code above fool you. You can still treat your UDT as if it’s implemented manually. The trick is to expose a property that can represent the UDT. The data type of this property should be native so that SQL Server would not have any problem dealing with it. This is only possible if your UDT is indeed a scalar. This is because a scalar UDT can be flattened to a unit without losing its value. In the case of time span, this unit is served in a silver platter - Ticks. Applying sort and other operators then is just a matter of calling this property. Index may take a little space though since you have to persist the property as a column. SQL Server does not allow indexing of a property.
CREATE TABLE t (tsCol SqlTimeSpan, Ticks AS tsCol.Ticks PERSISTED)
GO
CREATE CLUSTERED INDEX IX_T ON t (Ticks)
GO
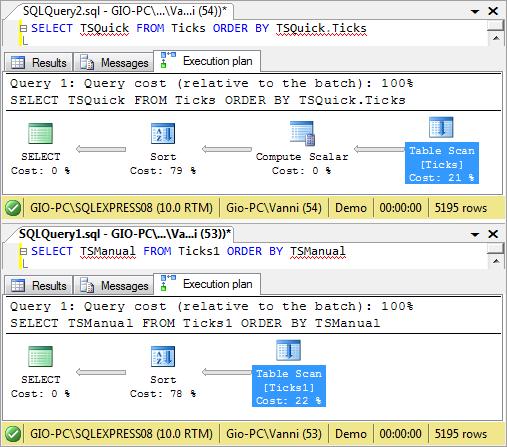
Besides features, another interesting point for comparison between the two implementations is efficiency. I examined the execution plans of the two implementations when sorting 5000 rows. The call to the Ticks property involves another step but its impact is very minimal so I thought it’s not that significant. What surprised me is the total execution time which I expected to be a no-contest in favor of the quick implementation. The quick implementation, however took, 0.280 seconds, while manual is only 0.241. There was also a significant bloat on the Estimated Row Size on the quick implementation, which increased from 15 bytes to 23 starting in the Compute Scalar step. The manual implementation retained the 15-byte estimate throughout. The increased size must be due to the call to the Ticks property which requires additional bytes for storage. Cached Plan Size also favored manual with only 8 bytes, half of that of the quick. The only statistics favoring the quick implementation is the Estimated I/O Cost during Table Scan which was expected but still very insignificant. But, bear in mind that these statistics are just all estimates, and I’ve read so many claims that they are sometimes inconsistent, misleading, or plain wrong. I still encourage you to perform your own tests to justify further coding. If you’re not convinced with the benefits of manually implementing serialization, then you can jump directly to the complementing artifacts section.
The first step in manual serialization is to make sure SqlUserDefinedAttribute.IsByteOrdered is set to true. This tells SQL Server that it can use the persisted bytes of our UDT as a basis for comparison. To make things a little easier, we only persist the Ticks property, but there's a catch. Ticks is long (System.Int64), and .NET has a weird way of persisting signed numeric types. Negative values are actually persisted as values greater than the maximum value of the type and in descending fashion. To give you a better idea of this, I included a naïve UDT called LongUDT in the source code to explore this behavior. Let’s take a look at how SQL Server handles these values using the LongUDT:

It’s obvious why we get a jumbled result when ordering by the UDT column. SQL Server depends on the stored values, which are way off their presentation values. For example, the minimum value for long is actually stored as 128, and 1 as 72,057,594,037,927,936.
I tried to trick SQL Server by off-setting the values and storing them as ulong instead. I should be assured a positive number for my ulong value if I add long.MaxValue + 1, which is (2 pow 64 / 2) + 1, to any long value. Applying the offset, however, produces an even more perplexing result:
The ulong.MinValue (first row) is stored correctly, but other values are just way off. Zero, which I expected as simply the offset value, was stored as 128, and long.MinValue + 1 (third row) which was expected to be 1 was stored as 72,057,594,037,927,936. Tinkering with all these bits is not really my cup of tea, but I just needed to investigate this outside SQL Server, so I did. The results were exactly what I predicted.
The console above clearly suggests that the bits are somehow jumbled when they are converted to bytes. Equipped with this new finding, we should be able to sort our table properly if we could maintain the arrangement of bits when they’re persisted as bytes by SQL Server.
In our UDT, the tasks of Read and Write are to offset the Ticks value and make sure the correct bits are copied to and from the disk. They rely on static helper methods that do the dirty plumbing on the bits. Apart from the methods are some helper properties which aid in the readability of the codes. All of these are self-documenting except the IsCircularOnBit32. We use this to check for circular bit shifting which can have a devastating effect to our UDT. Just imagine what could happen to the result if along the way you get 1 instead of 4,294,967,296! Shown below is the IBinarySerialize.Write implementation.
readonly static bool IsCircularOnBit32;
readonly static long TicksOffset = long.MaxValue;
readonly static int ByteLength = 8;
readonly static int UdtLength = 72;
static SqlTimeSpan()
{
IsCircularOnBit32 = (1U == 1U << 32);
}
public void Write(System.IO.BinaryWriter w)
{
if (!IsNull)
{
byte[] targetBytes = new byte[9];
targetBytes[0] = 0;
ulong sourceValue = (ulong)(Ticks + TicksOffset) + 1;
int sourceStartBit = UdtLength - 1;
for (int i = 1; i < targetBytes.Length; i++)
{
sourceStartBit -= ByteLength;
ULongToByte(sourceValue, sourceStartBit, ref targetBytes[i]);
}
w.Write(targetBytes);
}
else
{
byte isNullByteFlag = 1;
w.Write(isNullByteFlag);
}
}
The first thing the code block does is check if the UDT is not SQL-Null. There is no need to go farther if the UDT is SQL-Null. Effectively, if the UDT is SQL-Null, we only use 1 byte. This is the reason why we specified SqlUserDefinedTypeAttribute.IsFixedLength as false in our UDT adornment.
The workhorse of this method is the ULongToByte which we’ll discuss momentarily. Basically, what it does is copy bits from the ulong value to the byte value 8 bits at a time. Copying involves elementary bit operations, which you might want to refresh yourself with here.
For non-SQL-Null UDT, we use 9 bytes: 1 for the SQL-nullability and 8 for the off-set ulong value of Ticks. First, we perform a similar write to the first byte of the array, except this one is turned off to indicate not SQL-Null. This is followed by the off-setting of the Tick value. The new ulong value will then be traversed 8 bits at a time starting from bit 63 down to 0. The length of the UDT is 9 bytes or 72 bits, but since we already used bits 71 to 64 for the SQL-nullability, we should start reading from bit 63 down. The table below should make everything clear for you with regards to the bits processed per iteration.
Reading, of course, is just the opposite. We traverse each byte in the persisted byte array and copy the bits to a ulong variable. The entire code block is shown below:
public void Read(System.IO.BinaryReader r)
{
byte isNullByteFlag = r.ReadByte();
if (isNullByteFlag == 0)
{
_isNull = false;
ulong targetValue = 0;
byte[] sourceBytes = r.ReadBytes(8);
int targetStartBit = UdtLength - 1;
for (int i = 0; i < sourceBytes.Length; i++)
{
targetStartBit -= ByteLength;
ByteToULong(sourceBytes[i], ref targetValue, targetStartBit);
}
long correctedValue =
(long)(targetValue - (ulong)TicksOffset) - 1;
SystemTimeSpan = TimeSpan.FromTicks(correctedValue);
}
else
_isNull = true;
}
It starts with the reading of the first byte which is the SQL-nullability flag. Notice that the order of reading is the same as that of writing. If SQL-null, we don’t bother to read the remaining 8 bytes. If not, we traverse through the byte array and write 8 bits at a time to a ulong accumulator variable. It is an accumulator because we carry over its value to the next call. This will become clear later when we discuss the method ByteToULong in details. After accumulating, we offset to get the original long value for the ticks. The table below shows which bits are processed in every iteration:
The method ByteToULong is responsible for copying of the bits to their proper places in the memory. It’s composed of four steps:
- Creating the appropriate masks
- Dropping the non-pertinent bits from the source
- Aligning of the source and target bits
- Copying the bits to the target
The procedure is pretty much standard, but it is intimidating for those who don’t do this kind of stuff on a regular basis. Don’t fret; everything will be clear when we walk through each line using a concrete example.
static void ULongToByte(ulong source, int sourceStartBit, ref byte target)
{
ulong copyMask = 1U << (sourceStartBit + 1);
copyMask -= 1;
int bitLengthToCopy = ByteLength;
ulong dropMask = 1U << ((sourceStartBit + 1) - bitLengthToCopy);
dropMask -= 1;
dropMask ^= 0xFFFFFFFFFFFFFFFF;
copyMask &= dropMask;
if ((sourceStartBit >= 31) && IsCircularOnBit32)
source ^= copyMask;
else
source &= copyMask;
int targetStartBit = ByteLength - 1;
int shift = sourceStartBit - targetStartBit;
source >>= shift;
ulong byteMask = 1U << ByteLength;
byteMask -= 1;
target |= (byte)(source & byteMask);
}
Let us walk through the code using a Ticks value of 8,589,942,784. After the offset, this becomes 9,223,372,045,444,718,592. It is indeed a big value, but its bit representation is just enough to illustrate each action we take after checking for circular shifting. For this first walkthrough, we’ll illustrate the case when the source start bit is less than 31. This means we are already on the 7th iteration. Our ultimate objective is to extract the highlighted octet below and place it in the target byte variable.
The first step is to create the appropriate copy and drop masks. The source start is bit 15 (16th bit), and after applying the shifts, we get the following:
Next, we drop the non-pertinent bits from the copy mask. The objective is to come up with a mask with all zeroes except the second octet. (For clarity, subsequent illustrations highlight any bit value which is a result of a bit operation.)
Now that we already have the copy mask to isolate the pertinent bits, the next step is to apply this to our source. My machine is 32 bit, which means performing the AND bit operation. We should get a result which retains only the 1's in the pertinent octet.
The result above, however, cannot be masked right away because it will yield a value greater than what a byte can store. We should align it to the first octet so that it could have only 255 as its maximum value – the maximum value for a byte data type. “Align” is actually a misnomer since what we’re really doing is reducing the value by shifting the bits to the right.
And finally, we can mask the source to extract the needed value for the iteration.
The next case happens when we are in the 4th iteration (5th octet from the right). This illustrates the action taken when the source start bit is greater than 31 and codes are running in a 32 bit machine. The 34th bit is 1, which translates to a byte value of 2 for the target byte. You should be familiar with all the operations involved by now so there’s no need for a walkthrough anymore. Note the copy mask which turns out to be 255 instead of the expected 4,294,967,295. This is the effect of the circular bit shift. The distinct operation used to rectify this is the one in blue face.
That does it for the saving. The reading, in the other hand, is handled by another helper method, the ByteToULong. If the saving is complex, this one is a total opposite. The reason for this is that our target data type can accommodate more bits than what we have in the source. The only things we need to do are to align the source octet to the target octet and then perform the bit OR operation. As I’ve said earlier, we use bit OR because we’re simply adding more value to the target which I previously referred to as the accumulator. Here’s the implementation:
static void ByteToULong(byte source, ref ulong target, int targetStartBit)
{
ulong maskableSource = (ulong)source;
int sourceStartBit = ByteLength - 1;
int shift = targetStartBit - sourceStartBit;
maskableSource <<= shift;
target |= maskableSource;
}
As an example, let's assume we're already in the 4th iteration. In this iteration, our objective is to place the byte value 2 to octet 5. The steps are illustrated below:
Note that the remaining 8,192 will be taken care of by the 7th iteration. In that iteration, the value 32 will be shifted 8 bits to the left, thus producing the necessary value to come up with the original ulong value. You can verify this entire walkthrough by running this statement:
We have 18 digits in the hexadecimal value because one byte is represented by 2 hexadecimal digits. The first two zeroes in the left correspond to the SQL-nullability flag. The breakdown below shows how our ulong (off-set) value gets stored:
2 x (16 pow 3) = 8,192
2 x (16 pow 8) = 8,589,934,592
8 x (16 pow 15) = 9,223,372,036,854,775,808
Total = 9,223,372,045,444,718,592
With all the binary serialization routines in place, running the previous statements should give us the expected result.
You can readily see that the offsetting strategy works. The minimum Ticks value is stored as 0, 0 is stored as the offset plus 1, and so forth. And, since you’re now confident that your UDT can be sorted properly, you might also want to check this out:
So, why bother wading through all of these in the article? I just feel that I owe it to the reader to demystify probably the most obscure yet vital aspect in UDT programming. If you can control how the bits are laid out in the disk, you’re no longer constrained by the data types of your fields. You can do virtually everything in terms of storage and performance optimization. To top it all, you now have a bona fide UDT which responds correctly to relational semantics.
Complementing Artifacts
Aggregate
If you want to get the sum of a column defined by our UDT, you can use the Ticks property with the existing SUM() aggregate. This is not straightforward though because you have to reassemble the result into a SqlTimeSpan for proper presentation. Avoiding this is not a very compelling reason to create an aggregate just for our UDT, but if you’re interested, your code might look like this:
[SqlUserDefinedAggregate(Format.UserDefined, MaxByteSize = 10
, IsInvariantToDuplicates = false
, IsInvariantToNulls = true
, IsInvariantToOrder = true)]
public struct SumTS : IBinarySerialize{
SqlTimeSpan _accumulatedTS;
bool _isEmpty;
public void Init()
{
_accumulatedTS = new SqlTimeSpan();
_isEmpty = true;
}
public void Accumulate(SqlTimeSpan tsToAdd)
{
if (!tsToAdd.IsNull)
_accumulatedTS = SqlTimeSpan.Add(_accumulatedTS, tsToAdd);
if (_isEmpty == true)
_isEmpty = false;
}
public void Merge(SumTS group)
{
_accumulatedTS = SqlTimeSpan.Add(_accumulatedTS, group.Terminate());
}
public SqlTimeSpan Terminate()
{
SqlTimeSpan returnValue = SqlTimeSpan.Null;
if (!_isEmpty)
returnValue = _accumulatedTS;
return returnValue;
}
#region IBinarySerialize Members
void IBinarySerialize.Read(System.IO.BinaryReader r)
{
_isEmpty = r.ReadBoolean();
if (!_isEmpty)
_accumulatedTS.Read(r);
}
void IBinarySerialize.Write(System.IO.BinaryWriter w)
{
w.Write(_isEmpty);
if (!_isEmpty)
_accumulatedTS.Write(w);
}
#endregion
}
Note that we just call the Read and Write of the SqlTimeSpan accumulator during serialization. This assures us correct sorting of the results since all the necessary logic has been handled already inside the UDT.
Our aggregate has the user-defined serialization because we’re also using a user-defined artifact inside. We increase the size to 10 in order to accommodate a flag that indicates whether the table traversed by the aggregate is empty or not. We return SQL-null if the table is empty; otherwise, we return the accumulated value. This is actually a workaround for the non-functional SqlUserDefinedAggregate.IsNullIfEmpty property. According to Microsoft documentation, if this property is set to true, you should be getting a SQL-null when applying the aggregate to an empty table, but this doesn't seem to work.
Here is our aggregate in action:
User-defined Functions
We can also come up with improved versions of some SQL functions involving dates. With our UDT, there is no need to specify which part of the date is involved in the computation, and you are spared of the tedious task of formatting the results. Here is the code for these UDFs:
static public partial class SqlTimeSpanUdfs
{
[SqlFunction]
public static DateTime AddTS(DateTime dt, SqlTimeSpan ts)
{
return (dt.Add(TimeSpan.FromTicks(ts.Ticks)));
}
[SqlFunction]
public static DateTime SubtractTS(DateTime dt, SqlTimeSpan ts)
{
return (dt.Subtract(TimeSpan.FromTicks(ts.Ticks)));
}
[SqlFunction]
public static SqlTimeSpan DateDiff2(DateTime start, DateTime end)
{
TimeSpan ts = end - start;
return new SqlTimeSpan(ts, false);
}
[SqlFunction]
public static DateTimeOffset AddTSOffset(DateTimeOffset dt, SqlTimeSpan ts)
{
return (dt.Add(TimeSpan.FromTicks(ts.Ticks)));
}
[SqlFunction]
public static DateTimeOffset SubtractTSOffset(DateTimeOffset dt, SqlTimeSpan ts)
{
return (dt.Subtract(TimeSpan.FromTicks(ts.Ticks)));
}
[SqlFunction]
public static SqlTimeSpan DateDiffOffset(DateTimeOffset start,
DateTimeOffset end)
{
TimeSpan ts = end - start;
return new SqlTimeSpan(ts, false);
}
};
Below are some samples of the UDFs operating on both DateTime and DateTimeOffset.
Extension Methods
We leverage on extension methods to provide an easy way of converting from the system timespan to its UDT equivalent. The lenient equality operator we have for the UDT can also be applied on the system timespan and thus, is also included as an extension method.
static public class TimeSpanExtensions
{
static public SqlTimeSpan ToSqlTimeSpan(this TimeSpan ts)
{
return new SqlTimeSpan(ts, false);
}
static public bool ApproxEquals(this TimeSpan ts
, TimeSpan tsToCompare
, TimeSpan allowedMargin)
{
TimeSpan diff = ts - tsToCompare;
return (diff.Duration() <= allowedMargin.Duration());
}
}
With those in place, you should be able to write code like this in your front-end application:
DateTime d1 = DateTime.Today;
DateTime d2 = DateTime.Now;
TimeSpan ts = d2-d1;
SqlParameter p = new
SqlParameter("@sqlTimeSpan", SqlDbType.Udt);
p.UdtTypeName = "SqlTimeSpan";
p.Value = ts.ToSqlTimeSpan();
cmd.Parameters.Add(p);
cmd.ExecuteNonQuery();
TimeSpan AllowedMargin = TimeSpan.FromTicks(500);
TimeSpan ts1;
TimeSpan ts2;
if (ts1.ApproxEquals(ts2,AllowedMargin))
{
}
So What?
Our SqlTimeSpan is finally ready for action, but the question is: would it be fun? It depends. If you’re someone who wants to broaden your horizon on technology and get a taste of evolutionary things to come, code ahead, but be prepared for the caveats. UDT requires a significant learning curve, and the farther you tread the optimization path, the steeper the climb. The support from RAD tools is still virtually non-existent. Being an elementary artifact, its change has very extensive effects leading to some deployment hassles. As for the benefits, prose is cheap; you have to find them out yourself.
History
- 07/23/2009 - First published.
- 07/27/2009 - Added
DateTimeOffset support in the UDFs.

