Introduction
In this article, we will start with how to distribute an open source project and introduce how to use AP&RP technology. This is the second in a series of articles on beginners of distributed system design. You can click on the link below to find the first article.
In the beginner's introduction 1, we briefly introduce AP&RP technology. To fully demonstrate the amazing effects of this technology, I randomly selected a project on github.com. This project is an open source e-commerce project named shop, written by Manphil and addressed at https://github.com/Manphil/shop. Here's to thank him and all his open source authors. Without their work, I would need to spend more time writing examples of this chapter. First of all, I would like to give an overall technical introduction to this project. This is an e-commerce project developed in JAVA language. The development environment is IDEA and Tomcat 8.5. The database used is MySql. It is divided into two parts: the front end uses Bootstrap and JQuery, the back end is developed based on Spring MVC, Spring, MyBatis, and Maven is used to build the project. Because we only analyze the distribution of the server system, we will skip the construction, debugging and front-end part of the project. Although this example is in JAVA language, the techniques introduced in this paper are also applicable to server-side software systems developed in nodejs, C++, C and other languages.
Overall Product Function and System Architecture
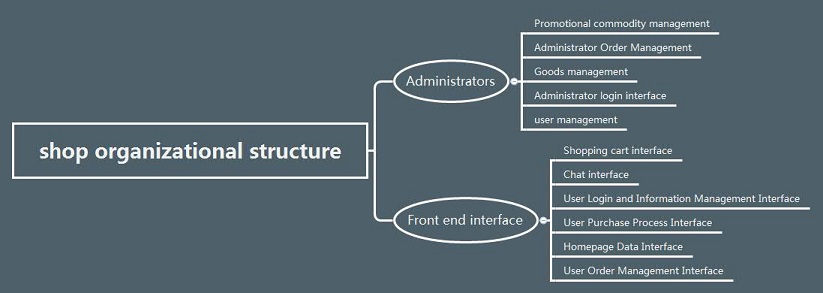
Shop is not a mature open source project, many functions are in the process of development. Through the analysis, I have come to some conclusions that surprise me. I will summarize these conclusions later. Shop project is mainly divided into two parts, the first part is system management, the second part is front-end call interface. It has 11 product functions as shown in Figure 1:
Shop system architecture is also relatively simple, divided into back-end services and database. Backend services link databases directly through MyBatis middleware as shown in Figure 2.

There are 62 callable interface links in the shop. That is to say, the whole system is composed of 62 tasks. Compared with more mature e-commerce projects with hundreds of interfaces, shop is relatively simple.
Analysis Task 1
Assuming that shop can implement AP operation through database cluster, we can know whether the project shop can carry out distributed operation only by classifying and RP analyzing the data read and written by tasks in the software system. Here, we select two more complex tasks in the shop to introduce the specific analysis process. One of them is "/info/list", which is responsible for returning user's order information. He is in the "shop/controller/front/CustomerController.java" file.
The source code is as follows:
@RequestMapping("/info/list")
public String list(HttpServletRequest request,Model orderModel){
HttpSession session=request.getSession();
User user;
user=(User)session.getAttribute("user");
if (user==null)
{
return "redirect:/login";
}
OrderExample orderExample=new OrderExample();
orderExample.or().andUseridEqualTo(user.getUserid());
List<Order> orderList=orderService.selectOrderByExample(orderExample);
orderModel.addAttribute("orderList",orderList);
Order order;
OrderItem orderItem;
List<OrderItem> orderItemList=new ArrayList<>();
Goods goods;
Address address;
for (Integer i=0;i<orderList.size();i++)
{
order=orderList.get(i);
OrderItemExample orderItemExample=new OrderItemExample();
orderItemExample.or().andOrderidEqualTo(order.getOrderid());
orderItemList=orderService.getOrderItemByExample(orderItemExample);
List<Goods> goodsList=new ArrayList<>();
List<Integer> goodsIdList=new ArrayList<>();
for (Integer j=0;j<orderItemList.size();j++)
{
orderItem=orderItemList.get(j);
goodsIdList.add(orderItem.getGoodsid());
}
GoodsExample goodsExample=new GoodsExample();
goodsExample.or().andGoodsidIn(goodsIdList);
goodsList=goodsService.selectByExample(goodsExample);
order.setGoodsInfo(goodsList);
address=addressService.selectByPrimaryKey(order.getAddressid());
order.setAddress(address);
orderList.set(i,order);
}
orderModel.addAttribute("orderList",orderList);
return "list";
}
- "
@RequestMapping (/info/list)" means the link to URI "/info/list" will trigger the call function "public String list" (HttpServletRequest request, Model orderModel).” This call does not pass parameters to the function. It may be triggered in the form of "http://localhost/info/list". - In "
HttpSession session = request. getSession ();" the data of session is read first. Data about security and permissions currently linked is stored in session. This code verifies that only logged-in users are allowed to use this interface. Note that session data as global data is also one of the data we need to analyze. - The data of all orders of the specified user is read in "
List<Order> orderList = orderService.selectOrderByExample(orderExample);". The"orderService.selectOrderByExample " is eventually transformed into a query operation in MySQL database. - After obtaining all the order information of the user, the item information in the specific order is queried by the statement "
orderItemList = orderService. getOrderItemByExample". - Query the commodity information of the item in "
goodsList = goodsService.selectByExample(goodsExample); ". - And query the address information of the corresponding order in "
address = addressService.selectByPrimaryKey(order.getAddressid());".
The above five information are stored in `address', `indent', `orderitem', `goods' and global data session respectively. Here is the use of the entire table for reading data. Note the range of data used here. Taking reading all orders of users as an example, the range of data used is the whole `indent' table. The data obtained is the user's current order. Here, the data range used is the boundary, not the data range obtained. Through the above analysis, we get the scope of '/info/list' usage data and record it as shown in Figure 3.
Analysis Task 2
I use "/orderFinish" to analyze the situation where data is written. The task of "/orderFinish" is to submit the data of the shopping cart to the order. The code is as follows:
@RequestMapping("/orderFinish")
@ResponseBody
public Msg orderFinish(Float oldPrice, Float newPrice,
Boolean isPay, Integer addressid,HttpSession session) {
User user = (User) session.getAttribute("user");
ShopCartExample shopCartExample = new ShopCartExample();
shopCartExample.or().andUseridEqualTo(user.getUserid());
List<ShopCart> shopCart = shopCartService.selectByExample(shopCartExample);
for (ShopCart cart : shopCart) {
shopCartService.deleteByKey(new ShopCartKey(cart.getUserid(),cart.getGoodsid()));
}
Order order = new Order(null, user.getUserid(), new Date(),
oldPrice, newPrice, isPay, false, false, false, addressid,null,null);
orderService.insertOrder(order);
Integer orderId = order.getOrderid();
for (ShopCart cart : shopCart) {
orderService.insertOrderItem(new OrderItem
(null, orderId, cart.getGoodsid(), cart.getGoodsnum()));
}
return Msg.success("Purchase success");
}
- First, "
@RequestMapping("/orderFinish")" maps URI to the orderFinish function. Five parameters were introduced. These five parameters are passed in at the same time when the URI is called by the front end. - In the first sentence, "
User user = (User) session.getAttribute("user");" gets the current user information through session. - User shopping cart information in the database is obtained in "
List<ShopCart> shopCart = shopCartService.selectByExample(shopCartExample);". - The shopping cart information in the database was deleted in "
shopCartService.deleteByKey(new ShopCartKey(cart.getUserid(),cart.getGoodsid()));". - In "
orderService.insertOrder(order);", the data of the shopping cart is converted into an order and submitted to the order database. - In "
orderService.insertOrderItem", the items in the order are submitted to the "orderitem" data table in the database.
Through the analysis of the range of data written and read above, we can see. "/orderFinish" reads the data in the `shopcart' table and `session'. The tables in three databases, `shopcart', `indent', `orderitem', are written. The boundaries of the written data are also all of the three tables. Note that this is inserting data instead of updating it. If the data is updated, the scope of the update will be smaller. We will discuss the nuances further in the following chapters. The results of our analysis are also recorded as shown in Figure 4.
Distributed Engineering
When we have sorted out all the data read and written by the task, we put it in the form file (see annex). We found that only a few operations in this project use database fields. Most data uses all data fields in tables. There are 6 tasks that are not valid in the project. There are 28 tasks to read data. There are 30 tasks to write data. There is one task to write data that has no atomic relationship. 29 atom-related tasks were divided into 8 groups. Removing invalid tasks, the remaining 37 groups of tasks can be distributed to 37 server containers. The ratio of distributed task group to effective task is 69.3% as shown in Figure 5.
Among them, the atomic relationship of tasks means that the read data can only be placed in the atomic server container if there is a write conflict between them. Of the 30 tasks with written data, 29 tasks have atomic relationships and are divided into 8 groups. For example, "/addCategoryResult, /saveCate, /deleteCate" are all written to the table `category'. So these three tasks have an atomic relationship and are divided into a group. These eight groups of write tasks can only be placed in eight server containers with atomic attributes at most. That's eight single-threaded server containers.
For the remaining 28 read-only tasks, it has been assumed that we are using distributed database cluster to simulate AP technology. This kind of database cluster can use Oracle, HP vertica, SAP HANA or Ocean Base. These are products of world famous companies, and I don't need to advertise. Although the efficiency of AP operation simulated by database cluster is low, in order to make it more convenient for beginners, we use database cluster instead of AP operation. In the following chapters, we will learn how to do AP operation manually. It is assumed that the database cluster can provide an additional server node for each task to handle AP operations. This project can be distributed to 74 server clusters in general.
General Distributed Technology
What surprises me is that the engineering discreteness of an e-commerce website is so high. In the absence of any other special technology, database clustering was introduced. And it expanded the server 74 times without modifying any code. If the traditional product function segmentation method can only be divided into 11 parts at most. In addition, it is time-consuming and laborious to segment software engineering and database. Here, I call the general application of this distributed technology general distributed technology. Generally distributed technology is a system distributed method based on minimum change engineering. In contrast, AP&RP technology is far more than that. For projects processed by general distributed methods, we will get a mapping table of task uri. Taking this project as an example, 37 copies of server-side software can be simply copied and put into 37 server containers. The URI is projected into different server containers using the nginx reverse proxy. Note that you don't need to split software engineering here. Just have different server containers handle different requests. For example, we configure one of the server containers 192.168.1.1 to handle write requests to the `category' table. As we learned earlier, "/addCategoryResult", "/saveCate", "/deleteCate" will be written to `category', so add the configuration to nginx as follows:
location /addCategoryResult {
proxy_pass http:
}
location /saveCate {
proxy_pass http:
}
location /deleteCate {
proxy_pass http:
}
By putting the reverse proxy together with the database cluster and replicas of 37 servers, we get the distributed shop project as shown in Figure 6.
Sequence dependence and data dependence.
GOOGLE has developed GRPC protocol to facilitate calls between micro services, but I recommend that you do not use GRPC to establish links to internal services. I mentioned earlier that the primary goal of implementing AP&RP technology is to eliminate sequence dependencies between services. The so-called performance of sequence dependency on services is the mutual invocation of services. The first problem with invoking services to each other is the complexity of data mapping. For example, there are services A1, A2. If there is no call-to-call relationship, then they are separate A1 and A2. If A1 invokes A2 in a business, it is equivalent to a task that A1 and A2 perform jointly under special conditions. The projective relationship becomes three kinds of A1, A2 and A1&A2. This composite temporal relationship is actually a conditional service merger. That is, A1 and A2, which are originally independent of each other, will be blocked simultaneously under certain conditions. This congestion results in the intermittent performance degradation of the system as a whole. As shown in Figure 7.
The most common problem with sequence dependency is the establishment of a merge relationship between services that are inherently independent of each other, which results in intermittent blockages of services. Intermittent congestion does not necessarily occur, but occurs at a specific probability. This particular probability increases with the increase of sequence dependence. Normally, when two services need to share data or data conflicts occur, we will habitually create distributed locks or new services or database transactions to deal with such conflicts. Distributed locks, service containers and database transactions are all new atomic containers, but they are called differently in different situations. That is, we unconsciously create a large number of sequence dependencies. As shown in Figure 8.
Since the modification of task functions leads to the addition of atomic relationships, the correct approach is to re-plan the distribution of tasks. Tasks of atomic relations are adjusted together. Continue to maintain task data dependency rather than sequence dependency. As shown in Figure 9.
Some Knowledge Points and Problems
- Is AP&RP safe and reliable?
First, AP&RP technology does not modify any of your business logic. No additional business and hardware levels were added. Therefore, there is no problem that the failure of AP&RP technology leads to system outage. In general distributed technology, from an intuitive point of view, it expands from a single server to multiple servers. The failure of any of these servers will not cause the whole cluster business to stop. So this extension is an improvement of cluster security. Are old distributed technologies more secure? I suggest you read the related papers of FLP theorem. Distributed systems will not bring more reliability than hardware. Here we pay tribute to the hardware engineers who have been working hard to provide us with more reliability
- Fallacy 1. There are no atomic tasks in different functional classifications.
Because the classification of functions is subjective and arbitrary. Atomic tasks are often divided into different functions. For example, the task '/update' in the active commodity management in the example needs to set up "goods (activityId)" to have an atomic relationship with the commodity management function. It would be more natural to put this task together with other atomic tasks. Here, we should put '/update' in commodity management, but it seems strange to do so from the point of view of product design.
- Fallacy 2. It can't be classified by function, but it doesn't mean right.
At present, most distributed systems are classified according to their functions. The engineer then corrects the system based on whether there is a problem. Although most of the systems divided by function work well. But I think it just works well. Because no RP conflict is triggered, that is, the conflict of atomic relations. It is very dangerous and imprecise to think that such a division is not a problem if it works well in a certain probability.
- Overlaying the system results in a heavy mental burden.
Too many layers of software functions and too many layers of hardware systems cause serious mental burden to developers. Layers created simply to make reading seem more hierarchical. The real process of software is severely separated from the trigger point. This leads to great obstacles to software reading. For example, this example jumps three files from triggering database operations to actually calling the database. In addition, the author has developed a large number of database invocation methods that are not used in the end. All these lead to the decrease of development efficiency and the increase of development cost.
- Flexible automated distributed system.
With the increase of the access flow of software system, it is necessary for the system to be broken down more and more finely, but with the breakdown becoming more and more finely, the complexity of the project will be higher and higher. When the complexity is more than the human brain can understand in a limited time range, it requires that the computer system has the ability to decompose the system automatically according to the rules. Obviously, when dealing with extremely complex systems, we can no longer rely solely on human resources. Because human resource management itself is extremely unreliable and complex. We need more flexible automated distributed systems. In future chapters, we will discuss more technical details and eventually complete a flexible automated distributed system.
- Extension from Computing-Oriented to Asynchronous Networks.
At the beginning of the establishment of distributed science, it was mainly to solve the problem of whether mathematical calculation could be decomposed or not. For example, can we use distributed method to reverse hash algorithm? At that time, computers were just tools for computing. At this time, the computer system is more like an extension of a tool in human society. You can think of it as a store, parking lot toll collector, take out caller. The human network itself is a large asynchronous system. When this asynchronous system extends to the computer system, the computer system only extends the high discreteness of the human asynchronous system. This discreteness is the basis for the distribution and boundary demarcation. We will also spend more time discussing the academic significance of distributed technology.
Thanks
First of all, I want to thank my wife for her support during my academic year. I would also like to thank Code Project website and editor for publishing my papers and teaching articles. Thank you for taking the time to read. I hope my article can help you learn about distributed technology and apply AP& RP technology to your website design. Now you can start to analyze whether your website can be distributed or not.
History
- 7th May, 2019: Initial version

