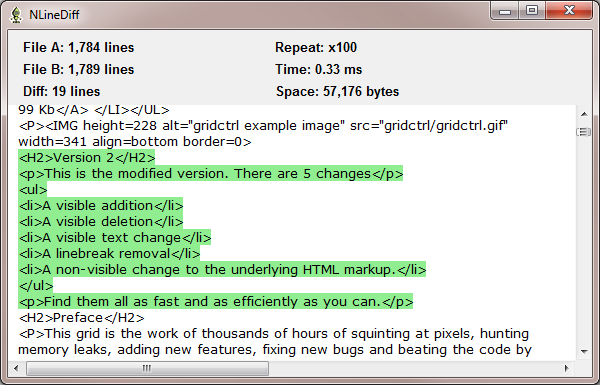

Key: Red lines are those deleted from the first file and green lines are those inserted from the second file.
Introduction
This article is an entry for the Lean and Mean competition, which ran on The Code Project during August 2009.
I have implemented a slight variation of Eugene W. Myers' diff algorithm with the linear space refinement from the paper listed in the downloads.
The algorithm is O(ND) in time and O(N) in space, where:
N = number of lines in FileA + number of lines in FileB
D = number of different lines
The output is rendered using a simple WinForms WebBrowser control.
Results
For the test files, N = 3,573 and D = 19. On my 2.5 GHz machine, the solution takes about 5 ms and uses about 450 KB of memory.
Time
A large proportion of the time is spent reading the files from disk and splitting them into string arrays. Using File.ReadAllText takes about 1.7 ms for both files, while File.ReadAllLines takes about 1.9 ms. Using File.OpenRead and StreamReader.ReadLine executes in almost identical times.
Building the HTML from the results also takes some time. Just showing the changes takes about 0.15 ms, which rises to 2.6 ms if the common lines are also included. I have chosen to include the common lines to give more useful results.
As for the diff algorithm itself, the average of 100 iterations is about 0.33 ms. The time for a single run obviously varies more than the average, but consistently takes about 0.4 ms.
These operations give the total time of 1.9 + 0.4 + 2.6 ≈ 5 ms.
The diff is run once before the timing run to allow the JIT compiler to work. This takes about 27 ms, which dwarfs the calculation time. I think that not including this time is legitimate as Chris said in the Notes:
"... there's no need to report memory usage or speed of the framework you use to support your code."
If you disagree, you can add in the JIT time to give a total time of about 32 ms.
Space
The space used is the sum of three areas:
- The files are loaded into memory, which takes about 360 KB.
- They are split into
string arrays, which takes about 30 KB. - The algorithm itself uses an
int array, which is about 60 KB.
The sum gives a maximum working memory of 450 KB.
I see that other entries have used Process.PeakWorkingSet64, but this is mostly a measure of how much memory the framework is using. Running this code reports about 900 KB being used by the Thread.Sleep call, which is obviously not correct.
static void Main( string[] args )
{
var p = Process.GetCurrentProcess();
var peak = p.PeakWorkingSet64;
Thread.Sleep( 1000 );
p.Refresh();
Console.WriteLine( String.Format( "peak: {0:N0} bytes", p.PeakWorkingSet64 - peak ) );
}
Using the Code
The binary is a single executable that has the test files included as embedded resources. It is configured to load the two texts and split them into string arrays, then time the diff algorithm.
You can also supply two file paths on the command line to use those files.
The source contains some variations which are commented out in Form1.cs. You can edit this file and recompile to verify my time and space measurements on your machine.
Points of Interest
Myers' algorithm is a work of art and I have thoroughly enjoyed learning it. It has taken me about a week to implement it because that's how long it took for me to fully understand it. It is definitely worthy of an article on its own (coming soon!)
History
- 2009 08 27: First edition
- 2009 08 28: Fixed bug with overlapping diagonal when D=1 && Δ is even

