Introduction
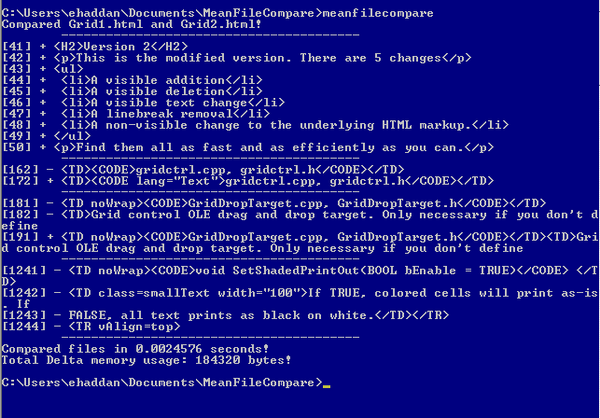
This is my entry in the Code Lean and Mean Contest. The idea of the contest is basically to create the leanest and meanest file diff program that can show the differences of Grid1.html and Grid2.html, running as fast as possible and using the least amount of memory. This article is obviously for the C++ contest which seems to have less entries than the C# category.
I was able to get this done in times less than 3ms, while using file buffer sizes of up to 2K, starting with a buffer size of 1K.
Using the Code
I used a byte-to-byte comparison to do the diff because I wanted to display line numbers as well as the text, so I needed to be able to count the number of newlines in the file. Here is the main loop of the file comparison:
void Compare::CompareFiles(LPCWSTR file1, LPCWSTR file2)
{
if (!_compareFile1.LoadFile(file1))
{
wprintf(L"Could not open:%s", file1);
return;
}
if (!_compareFile2.LoadFile(file2))
{
wprintf(L"Could not open:%s", file2);
return;
}
while (true)
{
if (_compareFile1._buffer[_compareFile1._currentBufferIndex] ==
_compareFile2._buffer[_compareFile2._currentBufferIndex])
{
if (_compareFile1._buffer[_compareFile1._currentBufferIndex] == '\n')
{
_compareFile1._currentLineNumber++;
_compareFile2._currentLineNumber++;
_compareFile1._startOfLine = _compareFile1._currentBufferIndex + 1;
_compareFile2._startOfLine = _compareFile2._currentBufferIndex + 1;
}
_compareFile1._currentBufferIndex++;
_compareFile2._currentBufferIndex++;
if (_compareFile1._currentBufferIndex == _compareFile1._totalBytesInBuffer)
{
_compareFile1.ReadMoreData();
}
if (_compareFile2._currentBufferIndex == _compareFile2._totalBytesInBuffer)
{
_compareFile2.ReadMoreData();
}
if (_compareFile1._fileCompletelyRead || _compareFile2._fileCompletelyRead)
{
if (_compareFile1.EndOfFile() || _compareFile2.EndOfFile())
{
if (!_compareFile1.EndOfFile() || !_compareFile2.EndOfFile())
{
FindDifferences();
}
break;
}
}
}
else
{
_compareFile1.ReadMoreData();
_compareFile2.ReadMoreData();
FindDifferences();
if (_compareFile1.EndOfFile() && _compareFile2.EndOfFile())
{
break;
}
}
}
_output.Display();
}
Once I find a difference, I start finding the beginnings of lines and line lengths, and then start comparing the lines of each files:
void Compare::FindDifferences()
{
_compareFile1._totalDiffPositions = 0;
_compareFile2._totalDiffPositions = 0;
long nextLineStartingPosition1 = _compareFile1._startOfLine;
long nextLineStartingPosition2 = _compareFile2._startOfLine;
_compareFile1.SetNextDiffPosition(nextLineStartingPosition1);
_compareFile2.SetNextDiffPosition(nextLineStartingPosition2);
int count = 0;
while (true)
{
if (nextLineStartingPosition1 != -1)
{
nextLineStartingPosition1 = _compareFile1.FindNextLine(nextLineStartingPosition1);
}
if (nextLineStartingPosition2 != -1)
{
nextLineStartingPosition2 = _compareFile2.FindNextLine(nextLineStartingPosition2);
}
if (nextLineStartingPosition1 != -1)
{
_compareFile1.SetNextDiffPosition(nextLineStartingPosition1);
}
if (nextLineStartingPosition2 != -1)
{
_compareFile2.SetNextDiffPosition(nextLineStartingPosition2);
}
if (nextLineStartingPosition1 == -1 && nextLineStartingPosition2 == -1)
{
_output.AddText("\t----------------\n");
_compareFile1.ReportDifferences(&_output, _compareFile1._diffPositions,
_compareFile1._totalDiffPositions - 1, '+');
_compareFile2.ReportDifferences(&_output, _compareFile2._diffPositions,
_compareFile2._totalDiffPositions-1, '-');
_compareFile1._currentBufferIndex = _compareFile1._totalBytesInBuffer;
_compareFile2._currentBufferIndex = _compareFile2._totalBytesInBuffer;
return;
}
if (count > 2)
{
if (nextLineStartingPosition1 != -1)
{
int index = CompareLinesWithOtherFileLines(&_compareFile1, &_compareFile2);
if (index != -1)
{
_output.AddText("\t----------------\n");
_compareFile1.ReportDifferences(&_output, _compareFile1._diffPositions,
count - 1, '-');
_compareFile2.ReportDifferences(&_output, _compareFile2._diffPositions,
index, '+');
_compareFile1._startOfLine =
_compareFile1._currentBufferIndex =
nextLineStartingPosition1;
_compareFile2._startOfLine =
_compareFile2._currentBufferIndex =
_compareFile2._diffPositions[index + 2];
break;
}
}
if (nextLineStartingPosition1 != -1)
{
int index = CompareLinesWithOtherFileLines(&_compareFile2,
&_compareFile1);
if (index != -1)
{
_output.AddText("\t----------------\n");
_compareFile1.ReportDifferences(&_output,
_compareFile1._diffPositions, index, '-');
_compareFile2.ReportDifferences(&_output,
_compareFile2._diffPositions, count - 1, '+');
_compareFile1._startOfLine = _compareFile1._currentBufferIndex =
_compareFile1._diffPositions[index + 2];
_compareFile2._startOfLine = _compareFile2._currentBufferIndex =
nextLineStartingPosition2;
break;
}
}
}
count++;
}
_compareFile1.RestoreNewlines();
_compareFile2.RestoreNewlines();
}
Lean and Mean Optimizations
Small Buffer Size
I create a buffer for each file of just 1K which I use to read and compare. The only time I increase this buffer size is if I have a really long line that exceeds the length or if the current differences that I am comparing exceeds the buffer size.
#define MEMORY_BLOCK_SIZE 1024
void CompareFile::IncreaseBuffer()
{
char* newBuffer = new char[_bufferLength + MEMORY_ALLOCATION_SIZE];
if (_totalBytesInBuffer > 0)
{
CopyMemory(newBuffer, _buffer, _totalBytesInBuffer);
}
delete [] _buffer;
_buffer = newBuffer;
_bufferLength += MEMORY_ALLOCATION_SIZE;
DWORD bytesToRead = _bufferLength - _totalBytesInBuffer;
DWORD bytesRead = 0;
::ReadFile(_fileHandle, &_buffer[_totalBytesInBuffer],
bytesToRead, &bytesRead, NULL);
if (bytesRead != bytesToRead)
{
newBuffer[bytesRead] = 0;
}
_totalBytesRead += bytesRead;
_totalBytesInBuffer += bytesRead;
if (_totalBytesRead == _totalFileSize)
{
_fileCompletelyRead = true;
}
}
void CompareFile::ReadMoreData()
{
if (_startOfLine == 0 && _totalBytesInBuffer == 0)
{
_startOfLine = _bufferLength;
}
if (_startOfLine == 0)
{
IncreaseBuffer();
return;
}
int bytesToCopyToBeginning = (int)(_bufferLength - _startOfLine);
if (bytesToCopyToBeginning > 0)
{
RtlMoveMemory(_buffer, &_buffer[_startOfLine], bytesToCopyToBeginning);
}
DWORD bytesRead = 0;
::ReadFile(_fileHandle, &_buffer[bytesToCopyToBeginning],
_startOfLine, &bytesRead, NULL);
if (bytesRead != (DWORD)_startOfLine)
{
_buffer[bytesToCopyToBeginning + bytesRead] = 0;
}
_totalBytesRead += bytesRead;
_totalBytesInBuffer = (int)bytesToCopyToBeginning + bytesRead;
_startOfLine = 0;
_currentBufferIndex = bytesToCopyToBeginning;
if (_totalBytesRead == _totalFileSize)
{
_fileCompletelyRead = true;
}
}
Avoided CRT File Functions
The CRT functions, such as fopen and fgets, are good for general C/C++. But if you are programming to be Lean and Mean, it would be best to avoid these functions. For example, the fopen function of the CRT does a bunch of other things before it eventually calls the Win32 API CreateFile function:
_tfopen {
_tfsopen(file, mode, _SH_DENYNO)
{
_getstream();
_openfile(file,mode,shflag,stream)
{
_tsopen_s(&filedes, filename, modeflag, shflag, _S_IREAD | _S_IWRITE)
{
_tsopen_helper(path, oflag, shflag, pmode, pfh, 1)
{
_tsopen_nolock( &unlock_flag, pfh, path,...)
{
CreateFile()
}
}
}
}
_unlock_str(stream);
}
}
The fgets function is even more bloated. There is so much processing to read the file and for all the processing to read a line of a file. This is just a brief summary of what happens when the fgets function gets called:
_TSCHAR * __cdecl _fgetts (_TSCHAR *string, int count, FILE *str) {
_lock_str(stream);
_fgettc_nolock(stream)
{
anybuf(stream);
_getbuf(stream);
_read(_fileno(stream), stream->_base, stream->_bufsiz)
{
_malloc_crt(_INTERNAL_BUFSIZ);
_read_nolock(fh, buf, cnt)
{
_textmode(fh);
_lseeki64_nolock(fh, 0, FILE_CURRENT);
ReadFile( (HANDLE)_osfhnd(fh), buffer, cnt, (LPDWORD)&os_read, NULL )
}
}
}
_unlock_str(stream);
}
These functions can save a lot of development time since they do all the work for you in parsing out the lines, but they do not do anything to make your program lean and mean.
Use Unicode Functions
I used CreateFileW to specifically use the Unicode version of the API. Internally, Windows converts all ANSI Windows API calls to Unicode. Why call the ANSI version when you can directly call the Unicode version? Here is a disassembly of CreateFileA which converts the filename to Unicode, then calls the Unicode CreateFileW function.

I could have just used CreateFile and compiled with the /UNICODE flag, but I did it this way to show how to specify the UNICODE version.
Profiling
When I thought I had things as lean and mean as possible and got the total time as fast as 8 to 12 ms, I ran the profiler in Visual Studio. I discovered that wprintf was using over 96% of the work time and that the next function using the most time was my main byte comparing function Compare::CompareFiles(), using only 1.8%.
I knew that outputting is a pretty expensive function, but I was a little surprised at just how much time it was taking. I decided I needed a way to bring that value down, so I created a class OutputText which initially creates a 1K buffer and stores the output through the OutputText::AddText() function. Then, when I finish comparing, I make a final call to OutputText::Display() which makes only one call to printf.
This brought down the total tracked time down to 42%. It's still not great, but much better than 96%. It raised Compare::CompareFiles() to 16.9%, which is a lot better. I could have cheated optimized a little more and not displayed the results while I was timing, but decided that wouldn't be right. ;)
History
- 8/29/2009 - Initial article.
- 9/1/2009 - Matches code I did for the C# version.

