Introduction
In order to see how some software manipulate the Windows Registry, I needed a tool that could take two hive files,
load them, and then compare them to show the differences between the two. I did find some code on the net that would compare
files but not two registry hives in a nice graphical way. So I thought of coding one myself in C#. (Registry Hives are binary files,
I don't mean here the .reg text based files made by regedit.exe.)
Background
Windows stores the Registry in binary files. The format of this Registry hive is not publicly available. The way data is stored in
the Registry is simple.
It begins with a Registry header of size 4096 bytes. It then starts off with Logical Data blocks - aka Cells. Based on the type of Logical
Data blocks, it will
have a list of pointers (called offsets = file offset from 4096th byte). These pointers point to another logical cell which has more information
or data in them. Broadly speaking, there are two types of cells:
- Node Key Cell
- Value Key Cell
Node keys - as the name suggests - are nodes of a tree. It's like the
directory in the Windows file system. A directory can have in it more directories and files.
This node cell has four important pieces of information.
- Number of Subkeys in this Node (or Key)
- Pointer to a Cell that stores the address of these Subkeys.
- Number of Value Key Cells in this node.
- Pointer to a Cell that stores addresses of Value Keys.
A value key cell stores data. Value keys behave like files which have different types of formats and information. Values keys are broadly categorized
into having text based information or binary information.
HIVE starts off with the ROOT node at (4096+32) address. Information is read by reading this first Node Key type cell. The subkey node information provides
us link to the sub keys present in this node. We have to iterate through all the nodes to read the entire
Registry hive. We also read the Value Keys as we iterate deeper into levels.
I have got some very good information (and coding help too) from these articles:
We then read these node information into a WinForms TreeNode and then plot them in a TreeView.
Once we have two hives loaded in two separate TreeViews, we then compare them using
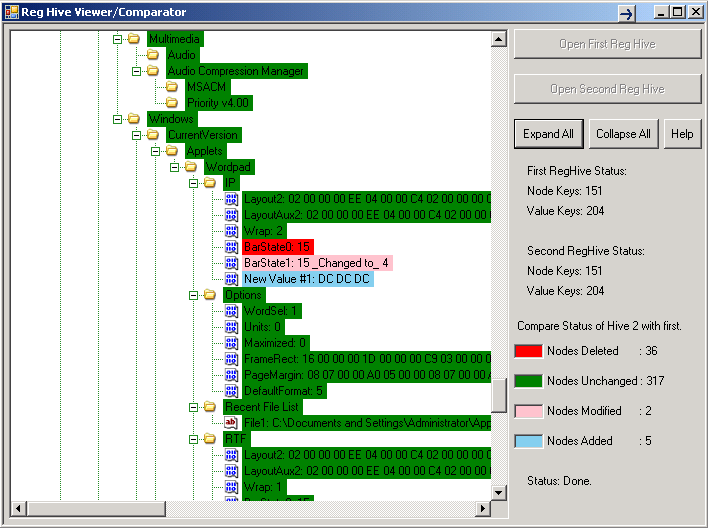
a simple iteration method. We assign color
to TreeNodes based on the search status: Green is an unchanged reg key type, red is
a key that was deleted (or not present) in the second file,
blue is a key that was added into the second file (not present in the first), and pink means a Value Key that was changed in its data.
Using the code
The code starts off by creating a WinForm and adding to it a TreeView,
Buttons, and some Labels. Labels provide information about the two
Registry hives,
Buttons just call a method to load a hive in a TreeNode. We jump straight to loading
the first registry file into memory as a byte array.
fs = File.OpenRead(InputputRegistryFile);
byte[] data = new byte[fs.Length];
fs.Read(data, 0, data.Length);
if (fs.Length < 4096) { MessageBox.Show("Not a reg hive file."); fs.Close(); return; }
fs.Close();
The node loading starts by creating the first root node.
TreeNode treenode = new TreeNode();
treenode.Text = "--Registry--Root--"
TreeView treeView1 = new TreeView();
treeView1.Nodes.Add(treenode);
The process begins by reading the first Node Key Logical cell from the Data[] array. The Node Key cell structure is as below:
[Serializable]
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Ansi)]
struct key_block {
public int block_size;
[MarshalAsAttribute(UnmanagedType.ByValArray, SizeConst = 2)]
public byte[] block_type;
[MarshalAsAttribute(UnmanagedType.ByValArray, SizeConst = 18)]
public byte[] dum1;
public uint subkey_count;
[MarshalAsAttribute(UnmanagedType.ByValArray, SizeConst = 4)]
public byte[] dum2;
public int offsettosubkeys;
[MarshalAsAttribute(UnmanagedType.ByValArray, SizeConst = 4)]
public byte[] dum3;
public int value_count;
public int offsettovaluelist;
[MarshalAsAttribute(UnmanagedType.ByValArray, SizeConst = 28)]
public byte[] dum4;
public ushort len;
public ushort du;
};
We shall create a method to which we pass on the address in data[] and read this structure. We then using the
len variable of this structure
read the name of the node. This name is stored immediately after the structure ends.
We use the
Queue in C# to iterate sub key reading
level by level. The general concept followed is:
- Add to the queue the root node address.
- Start the loop and process until the queue is empty.
- In the processing, read one node address from queue and then read the Key Node structure pointed at this address.
- Process the sub node keys information of this node. If any subkeys are present, add the address of each subkey in the
queue.
- If any Value Key is present, make a
TreeNode with the name and information and add it to
the tree node (the one that points to the TreeView).
Here, we do one more thing. In the queue, we add a structure. The structure has only two items: a pointer to
the Node Key Cell and the present TreeNode.
The idea is to preserve the 'present node' as we are continuously reading and processing subkeys. Every time we read a subkey from
the queue,
we also have its parent treenode available to us. This facilitates adding information at that address in the
TreeNode.
public struct stackobject
{
public int offset;
public TreeNode treend;
}
stackobject tstackobject = new stackobject();
public Queue<stackobject> jobstack = new Queue<stackobject>();
tstackobject.offset = 4128;
tstackobject.treend = treenode;
jobstack.Enqueue(tstackobject);
presentnode = treenode;
while(jobstack.Count!=0)
{
tstackobject = jobstack.Dequeue();
presentkey = tstackobject.offset;
presentnode = tstackobject.treend;
readkeyblock(presentkey);
tstring = getstringataddress(presentkey + 80,tmpblock.len);
TreeNode newnode = new TreeNode();
newnode.Text = tstring;
presentnode.Nodes.Add(newnode);
presentnode = newnode;
Once the name is added to the TreeNode, we now process the information stored in the key block. We start with Value Keys in this Node (or Key).
The Node Key points to an address where the address of each Value Key block is stored (like the point to pointers). From the Node key, we know the number
of Value Keys so it now reduces to simply reading the address of each Value
Key and reading the Value Key structure at that address. A Value Key block has this structure:
[Serializable]
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Ansi)]
struct value_block {
public int block_size;
[MarshalAsAttribute(UnmanagedType.ByValArray, SizeConst = 2)]
public byte[] block_type;
public ushort name_len;
public uint size;
public uint offset;
public uint value_type;
public ushort flags;
public ushort dummy;
};
The Value Key provides information about the key type using the value_type
uinteger. A value of 1, 2, 6, and 7 are treated as text based data,
4 is binary DWORD, and rest is binary data. Offset data in this structure is the address where the actual information is stored with size providing the length of this data.
(OFFSET is offset from 4096th byte- not the file start.) Here also, the name of the Value Node is stored immediately after this structure with
name_len providing the length of it.
A Value Key with zero name length becomes the 'default' value key as seen in regedit. The code below shows
the reading of Value Nodes:
if (tmpblock.value_count != 0)
{
for(int v=0;v < tmpblock.value_count; v++){
ad= (int)readuintataddress(tmpblock.offsettovaluelist + root +4 + 4*v) + root;
readvalueblock(ad);
if (tvalueblock.size > 0)
{
TreeNode newnode1 = new TreeNode();
vstring = getstringataddress(ad + Marshal.SizeOf(tvalueblock), tvalueblock.name_len);
newnode1.Tag = vstring.Length;
switch (tvalueblock.value_type)
{
Once the Value Nodes are read, it is time to process the sub nodes (or sub keys) in the present node key. Here also, we follow the same procedure.
Offset provides the address of the location where the address of each sub node key is stored. Unlike value key processing, this pointer to
the list of sub
nodes could be one dimensional or two. Which means, the address pointed by the offset data may be a list of subkey addresses or a list of addresses that stores
a list of actual addresses pointing to node keys. This is decided based on a simple
offset type structure. We simply start of by reading this
offset
type structure pointed by the Node Key offset data.
[Serializable]
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Ansi)]
struct offsets {
public int block_size;
[MarshalAsAttribute(UnmanagedType.ByValArray, SizeConst = 2)]
public byte[] block_type;
public ushort count;
};
lf or lh type offset block means a one dimensional array of Node Key addresses.
li or ri type offset block means a two dimensional addressing
of node key addresses. We simply process this structure and get to the Node Key address. For each Node Key address that we read, we just push
the address into our queue. These nodes will get processed by itself as our loop progresses and reads the
queue objects.
This way, the entire file is scanned level by level, we create a TreeNode for each object found,
and add them to the TreeNode that is also saved in the queue.
File Comparison
For comparison, we first load the hives into two separate TreeViews. The first is made visible but the second one is only for comparison purposes. treenode and
treenode2
are the respective nodes of these TreeViews.
The approach followed is similar to what regedit does for every search. Instead
of the recursive search
published at the MSDN website, we will do a level by level search using a queue managed by ourselves (and
not the system managed queue used in recursive iterations). Here is the code to
do simple level by level data handling of TreeView nodes.
public Queue<TreeNode> treequeue = new Queue<TreeNode>();
treequeue.Enqueue(treenode);
while (treequeue.Count != 0)
{
Treenode ttree = treequeue.Dequeue();
do
{
ttree.BackColor = Color.Red;
if (ttree.FirstNode != null) treequeue.Enqueue(ttree.FirstNode);
ttree = ttree.NextNode;
} while (ttree != null) ;
}
In the code above, we are changing the back color of each node of the tree. This is being done level by level.
To begin the comparison, we will make the back color of Tree1 as red and Tree2 as Blue. We will compare each node of Tree2
with every node of Tree1 level by level. There could be only two cases for this search:
- If at a given level the node is found, we change the back color of Tree one nodes to Green.
- If at a given level the node is not found, we simply copy the entire Node that we are searching into Tree1. (we had already marked the entire Tree2 as Blue,
so this makes this node as a Added Later data).
- For this entire sub node that we added to Tree1, we don't search within this sub node. This is done by not adding this sub node
to the Queue and the entire sub node is automatically removed from processing.
- If the node being searched is a Value type node, we not just compare the node name but also the data in that node.
Remember we had saved the length of Node name in the
Node.Tag key. This helps us in searching the name and data.
(Also see that we have the name and data both stored as a single string in the
Node.Text property, and we needed some place
to store the length of the key name -rest being its data).
treequeue.Enqueue(treenode2);
while (treequeue.Count != 0)
{
TreeNode ttree = treequeue.Dequeue();
do
{
stackthisnode = 1;
findthisnodeintree1(ttree);
if (ttree.FirstNode != null && stackthisnode == 1) treequeue.Enqueue(ttree.FirstNode);
ttree = ttree.NextNode;
} while (ttree != null);
}
Finally the method - Findthisnodeintree1 - takes in the Treenode from Tree2 and search for its presence in Tree1.
- To make search simple, it first checks if the Tree2 node has child elements. This is done using the
Node.Tag element. (Remember for Value type keys
we had saved the length of key name into Node.Tag). If this
Node.Tag is null, it means its a Node Key type data. - We use the
Node.Fulllength property we get the full address of the Node. We parse this name for '\\' and get the names of the nodes at each level. - For each level and with the key name available, we search in Tree1. If found we keep on going (and make the Tree1 node as green) until the last level.
If even the last one is found, we want to process the subkeys in that node and thus allow the Queuing of this Node Key.
- If its not found at any level, we simple copy the Node from that level into Tree1 and disallow the queuing of the Node for further processing.
void searchforthisnodeintree1(TreeNode tn)
{
searchqueue.Enqueue(treenode); string fullpath = tn.FullPath;
string shrt = "", nodetext="";
int index = -1, comparestatus=0, last=0, level=0;
if (tn.Tag == null) {
str2 = tn.Text;
while (searchqueue.Count != 0)
{
index = -1;
ttree = searchqueue.Dequeue();
temp = ttree; index = fullpath.IndexOf('\\'); last = 0;
if (index == -1) { shrt = fullpath; last = 1; }
else { shrt = fullpath.Substring(0, index); fullpath = fullpath.Substring(index + 1); }
do
{
found = 0;
if (ttree.Tag == null) {
nodetext = ttree.Text;
comparestatus = string.Compare(shrt, nodetext);
if (comparestatus == 0)
{
ttree.BackColor = Color.Green;
searchqueue.Enqueue(ttree.FirstNode);
found = 1; if (last == 1) searchqueue.Clear(); break;
}
}
ttree = ttree.NextNode;
} while (ttree != null);
if (found == 0) {
stackthisnode = 0; if (temp.Parent != null) { temp = temp.Parent; temp.Nodes.Add((TreeNode)tn.Clone()); }
else { treeView1.Nodes.Add((TreeNode)tn.Clone()); }
}
}
}
The Value nodes are also searched in a similar manner. Only difference being, we have to search for the name first and if found,
compare the data string. If data is not similar, we mark the tree1 object pink.
Points of Interest
This code also shows how to compare two Treenodes quickly. I think Regedit also follows a similar approach in searching for information.
History
I would like to give credit to the two links mentioned above for providing assistance in making this utility. Changes made to the software:
- Form Resize has been incorporated to make view better on bigger screen.
- Boundary condition to detect if Key node is empty. It was causing null entry in Queue and was not handled properly while dequeing.
ttree = searchqueue.Dequeue();
if (ttree == null)
{
stackthisnode = 0;
temp1.Nodes.Add((TreeNode)tn.Clone());
return;
}
- Button was added to remove the common data nodes. This makes the viewing a little easier. We actually create a new Treenode (=Finaltreenode)
and only copy in there the nodes that are not marked as Green. To make the task of deleting the same nodes, we start be deleting the value keys first.
This way we will empty the node keys that have all green marked keys.
treequeue.Clear();
newqueue.Clear();start = 1;
treequeue.Enqueue(treenode);
FinalNode.Text = "--REGISTRY--ROOT--";FinalNode.BackColor = Color.Green;
FinalNode.Tag = null;
newqueue.Enqueue(FinalNode);
while (treequeue.Count != 0)
{
ttree = treequeue.Dequeue();
tnn = newqueue.Dequeue();
do
{
if (ttree.Tag != null && ttree.BackColor != Color.Green) {
tnn1 = new TreeNode();
tnn1.Text = ttree.Text;
tnn1.BackColor = ttree.BackColor;
tnn.Nodes.Add(tnn1);
tnn1.Tag = 1;
tnn1.ImageIndex = ttree.ImageIndex;
}
if (ttree.Tag == null ) {
if (ttree.FirstNode != null) treequeue.Enqueue(ttree.FirstNode);
tnn1 = new TreeNode(); tnn1.Text = ttree.Text;
tnn1.Tag = null;
tnn1.BackColor = ttree.BackColor; if (start == 1) { start = 0; newqueue.Enqueue(FinalNode); }
else
{ tnn.Nodes.Add(tnn1);
if (ttree.FirstNode != null) newqueue.Enqueue(tnn1);
}
}
try { ttree = ttree.NextNode; }
catch { ttree = null; }
} while (ttree != null);
}
- We then proceed in a similar manner to delete the Node (or the directory) keys. For this, we shall have to make multiple iterations.
The logic here is we delete All the Node keys that are marked Green and have no Child node. The nodes are deleted from the last level in a single iteration.
We then iterate again deleting more last green marked nodes, and we keep on doing this until there are no more last green nodes to delete. Its done this way:
- The idea here is we create a new Treenode and copy all the nodes but the last empty nodes.
while(anynodesdeleted !=0) {
treequeue.Clear();
newqueue.Clear();start = 1;
treenode.Nodes.Clear();
treenode = (TreeNode) FinalNode.Clone();
FinalNode.Nodes.Clear();
treequeue.Enqueue(treenode);
FinalNode.Text = "--REGISTRY--ROOT--"; FinalNode.BackColor = Color.Green;
FinalNode.Tag = null; newqueue.Enqueue(FinalNode);
anynodesdeleted = 0;
while (treequeue.Count != 0)
{
ttree = treequeue.Dequeue();
tnn = newqueue.Dequeue();
do
{
if (ttree.Tag != null && ttree.BackColor != Color.Green) {
tnn1 = new TreeNode();
tnn1.Text = ttree.Text;
tnn1.BackColor = ttree.BackColor;
tnn.Nodes.Add(tnn1);
tnn1.Tag = 1;
tnn1.ImageIndex = ttree.ImageIndex;
}
if (ttree.Tag == null ) {
if (ttree.FirstNode != null) treequeue.Enqueue(ttree.FirstNode);
tnn1 = new TreeNode(); tnn1.Text = ttree.Text;
tnn1.Tag = null;
tnn1.BackColor = ttree.BackColor; if (start == 1) { start = 0; newqueue.Enqueue(FinalNode); }
else
{
if (ttree.BackColor == Color.Green && ttree.FirstNode == null) { anynodesdeleted++; }
else tnn.Nodes.Add(tnn1); if (ttree.FirstNode != null) newqueue.Enqueue(tnn1);
}
}
try { ttree = ttree.NextNode; }
catch { ttree = null; }
} while (ttree != null);
}
}

